
房价数据抓取与分析系统设计与实现
2020-07-04 02:15孙婷婷丁硕权
电脑知识与技术 2020年15期
孙婷婷 丁硕权

摘要:随着网络时代的到来,越来越多的民众选择通过网络上的房源信息来进行选房、购房,但如何从海量的房源信息中筛选出符合自己需要的商品房是一个难题。因此,该文设计实现房价数据抓取与分析系统,通过对某一地区房价数据的采集、处理、分析得到房价预测模型,同时为了让用户更加方便的选房,实现了前端网页展示地区房源统计信息,此外还提供房源信息的筛选以及地图选房功能。
关键词:房价数据;数据抓取;数据分析;数据可视化
中图分类号:TP39 文献标识码:A
文章编号:1009-3044(2020)15-0024-04
房地产行业在我国属于支柱性产业,在我国社会经济发展中一直扮演着重要角色。房价问题,尤其是大中城市的房价问题,一直是政府、大众和众多研究人员关注的热点。如何科学地预测房价是房价问题的研究方向之一。随着互联网时代的来临,如今越来越多的民众选择通过网络获取房源信息并进行选房购房,如何尽可能多角度的呈现房源信息幫助民众选房成为一个值得深人研究的课题刚。
为此,本文使用爬虫技术获取某一地区的房源信息,然后使用机器学习中的相关算法对房价数据集进行训练,得到与实际拟合度较高的房价模型,从而实现房价的预测。在房价数据抓取阶段使用爬虫技术,该方法获取的房价数据与传统从政府信息网站获取的房价数据相比更加丰富并具有时效性。在房价数据分析时使用机器学习中的算法,这些算法能够高效地进行大数据分析并建立房价模型。在房价数据展示部分利用前端网页技术实现房源统计信息展示、房源信息检索筛选、地图选房、房价预估等功能可以帮助消费者更加高效地选房、购房。
1需求分析
1.1设计目标
考虑到本文系统运行的环境和后续的数据处理,我们将上海房价作为研究对象,通过编写爬虫程序从链家网上爬取相关的二手房和租房信息,并将获取的信息保存到mysql数据库中。在得到房价信息后将对相关数据进行清洗和预处理,为后续的房价建模做准备。在对房价数据进行处理得到房价数据集后,采用机器学习中的多元线性回归和随机森林算法分别对房价数据集进行训练,从而得到房价模型,训练过程中遵循2-8原则,即20%的测试集,80%的训练集。通过比较两种不同算法得到的房价模型与实际房价的拟合度,找到性能更优的模型,并给出模型预测的房价值。为了方便用户进行选房、购房,计划在前端展示上海地区的房价统计信息,包括地区均价、房源数量等,同时设计了检索筛选功能,用户可以通过单关键词或者多关键词从数据库中获取所需房源信息,此外为了更加直观的展示地区房源信息,调用了高德地图API,用户可以通过关键字在地图上检索某一地区的房源,房源信息将在地图上标注,用户点击后可以得到相应的二手房和租房信息。
1.2功能需求
根据前一节的具体设计目标和需求,本文的房价数据抓取与分析系统需要满足以下的功能需求。
(1)房源数据抓取是本系统开发的基础,无论是房价模型的建立还是后续前端数据展示都依托于房源数据,所以房价数据抓取与分析系统的首要需求就是实现房源数据的抓取。该需求要求系统能够自动从目标房源信息网站上抓取有关的房源信息,并进行保存。爬取的数据要尽可能完整,效率不能过低,同时能应对数据爬取过程中出现的意外情况。
(2)房价数据处理与分析在获取了目标房源数据后,为了后续的数据分析,需要对获取的原始房源数据进行简单的预处理,预处理根据获取数据的实际特点进行针对性处理。在得到处理后的房源数据集后,采用合适的模型对数据集进行建模分析,得到房价模型,同时通过不同模型的比较得到最符合实际的房价模型,实现房价的预测。
(3)房价数据前端展示是为了让用户更加方便地进行选房、购房,需要在前端展示房源数据以及地区的房源统计信息,并能根据关键词实现房源数据的混合检索,筛选出符合用户需求的房源信息,同时为用户提供房价模型得出的房价参考值。此外满足用户直接在地图上指定区域选房的需求,实现更加高效的获取所需房源数据。
1.3用例分析
使用用例图来对需求涉及的场景进行描述,可以更加清楚地说明系统与用户之间的交互。
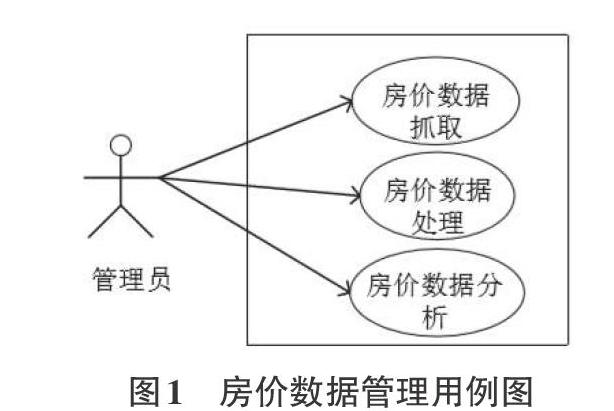
(1)房价数据管理用例
图1展示了管理员管理房价数据的用例图,包括使用爬虫获取原始房源数据,接着是对房源数据的处理,最后对新的房源数据集进行训练,得到房价模型。
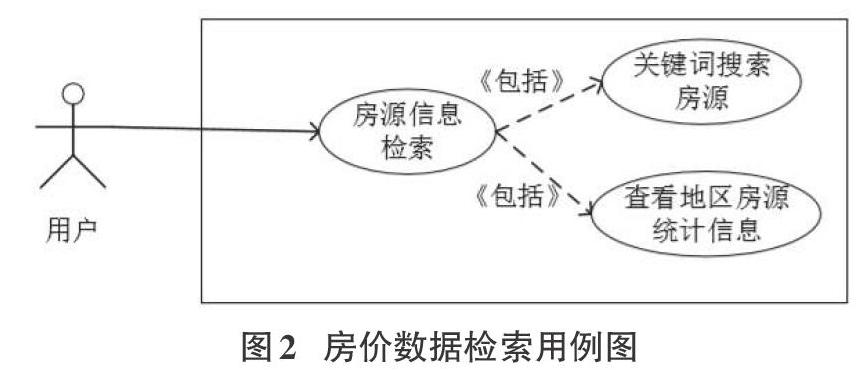
(2)房源数据检索用例
图2展示了用户检索房源数据的用例图,包括通过关键词搜索房源以及查看该地区的房源统计信息。
(3)地图搜索房源用例
图3展示了地图房源信息的用例图,包括通过搜索关键词在地图定位、目的地周边小区显示、小区内房源信息展示。
2系统设计
2.1总体结构设计
好的系统结构设计对于系统的性能起着至关重要的作用。本房价数据抓取与分析系统的结构设计主要体现在第三部分的房价数据展示。第一阶段的房价数据获取以及第二阶段的房价数据处理与分析实际上是取得目标数据的过程。当然爬虫程序也可以看成是一个子系统,但该系统的结构相对较为简单,所以本部分不做过多阐述。房价数据展示部分使用的是较为经典的MVC三层架构,即模型层(model)、视图层(view)和控制器(controller),其中模型层主要负责数据的存储,在该部分对应于房源数据集,视图层负责将数据在前端展示,控制器负责接受用户操作,并根据操作从数据库中获取数据,该部分中对应于响应前端用户发起的数据检索等请求,从数据库中获取数据后再调用视图显示数据。图4展示的是房价数据展示的系统结构图。
2.2功能模块设计
功能模块设计是将程序划分成若干个功能模块,每一个模块分别完成一个子功能,这些功能模块总体构成了系统。在功能模块的设计的过程中需要遵循高内聚、松耦合的原则,所谓高内聚就是要提高模块内各个元素之间的紧密程序,低耦合就是要减少模块间的数据交换,从而降低程序复杂度。结合这些设计原则对房价数据抓取与分析系统进行了划分。
(1)房价数据抓取功能模块
该模块主要实现了房价数据的抓取,首先输入需要爬取的目标房源网址,爬虫程序判断网址信息是否准确,然后从目标网页上获取房源信息,同时将新增的房源网址放到url队列中,程序不断循环直到没有待爬取的房源网址。图5展示了房价数据爬虫程序的流程图。
(2)房价数据处理与分析模块
该模块主要实现对爬取房价数据的预处理并使用机器学习算法构建房价模型,在数据预处理部分根据获取房价数据的特征进行针对性处理,比如获取的数据的类型是字符串,需要转化为数值类型才能进行后续建模。在数据分析部分选取机器学习中的常见算法对房价数据集进行训练,通过比较选取与实际房价拟合度高的模型,同时尝试调整模型中的参数。
(3)房价数据前端展示模块
该模块主要提供房源信息检索和地图搜索房源这两个功能,在房源信息检索中用户可以根据自己的需求选择房源信息关键词,系统根据关键词返回符合条件的房源,用户可以点击每一条房源查看详细信息,同时用户也可以查看地区的房源统计信息。在地图搜索房源部分,用户可以输入目的地关键词,系统在地图上定位目的地,同时查找目的地周围的所有小區,小区在侧栏分页显示,通过点击每一个小区用户可以查看该小区内房源信息。图6是房价数据前端展示部分的程序流程图。
3系统实现
3.1房价数据抓取实现
本文系统选取了链家网上海二手房源的以下信息进行爬取,包括小区名称、所在区域、房屋户型、建筑面积、单价、总价、房屋朝向、所在楼层、装修情况、该房源信息所在网址等信息。
在房源数据爬虫程序中主要采用的是宽度优先遍历策略,首先将每一页上的所有二手房源记录的网址信息爬取,用list数据结构存储这些网址信息,该list相当于ud管理器,接着从url列表中逐次取出每套二手房详细信息所在的网址,接着访问该网址,爬取其中所需的房源信息。详细的步骤如下:
第一步:获取分页信息。通过检查网页可以定位到分页标签所在位置,从中我们可以看到当前所在的页数(curPage)以及总共页数(totalPage),通过观察发现每页的结构是固定的,ud结构https://sh.1ianjia.com/ershoufang/pg{page}/,{page}代表当前的页数。为此编写获取所有二手房源记录所在页url函数,获取的url存储在list中。
第二步:获取当前页中二手房源详细信息所在网页url。在获取了所有的分页信息后,下一步需要获取每一页上二手房源详细信息所在的网页ud。通过检查网页定位到每条二手房源记录所在位置,从网页结构中可以看到每条二手房源信息所在ud位于类名为title的div标签下的超链接标签中,为此编写获取url的函数。首先是向目标地址服务器发送请求,获取服务器响应的内容,然后为网页信息创建对象,将会将网页信息转化成一个树形结构,通过调用对象中的各种函数可以筛选元素,通过标签名、类名、id名等方式实现元素筛选,这里需要查找的是类名为title的div标签。最后在筛选的div标签中找到超链接网址并存储到列表中。
第三步:获取每套二手房详细信息。获取二手房信息的方式与第二步中获取二手房详细信息url类似,同样是通过创建对象进行解析,不过由于标签结构的复杂度提高,筛选元素的过程也相应复杂些,为此编写getHouseInfo函数(节选了部分信息的获取),如图7所示。
每一条二手房源的信息存储在了houseinfo字典中,房源信息中的每个属性对应字典中的key,而属性值对应字典中的val-ue。最后将每一条二手房的房源信息存储到本地数据库中名为sechouse的表中。
3.2房价数据处理与分析实现
在完成第一部分的上海房源数据获取工作后,第二部分中我们将对获取的上海房价数据进行相应的处理,并通过机器学习中的相关算法对上海二手房价数据集进行训练,得到二手房价的模型,并比较不同算法得到模型的性能,通过二手房价的模型我们可以对现有的二手房房价进行预估,并判断其预测值与市场值之间的大小关系,从而给购房者一定的参考,同时也可以为新出现的二手房进行预估。
(1)数据处理
通过对数据集的观察可以初步从以下几个角度来处理数据,一是房屋户型现在是以字符串形式存储,例如,房屋户型为2室2厅1厨2卫,这样的数据显然是无法进行数据分析的,所以我们要将户型根据室、厅、厨、卫分开,并且只保留1、2、3这样的数字,同时为了后续的数值计算,需要将原本字符串类型的数值转化成float类型。二是单价、总价、建筑面积后的单位需要删除,其数值类型也需要转化成float类型。三是房屋朝向中存在着冗余信息,房屋朝向主要参考的是主立面所对方向,像“南北”这样的数据显然指的是坐北朝南,所以要将其中的干扰和冗余信息去除,此外将所在楼层中括号中的总楼层去除,方便后续的数据集训练。
(2)模型建立与房价预测
在获取数据以及对数据的预处理后,期望发掘出这些数据的价值,所以这一部分的研究重点聚焦于房价建模,以实现上海二手房房价的预测。在房价预测过程中主要使用的是多元线性回归和随机森林两种机器学习模型,首先使用获取的数据集对模型进行训练,然后使用训练好的模型进行预测分析。在进行数据集训练前,对数据集中的字符数值化,并且将数据集按照训练集和测试集划分。通过两者比较得出:随机森林模型与多元线性回归相比训练得到的二手房价模型与实际拟合度更高,多元线性回归训练的模型中会存在异常值,而在随机森林模型中则并未出现这些异常值,准确率更高。
(3)前端展示
①数据检索
为了让用户可以方便快速的筛选出符合自己条件的二手房源信息,在前端设计了检索工具,用户可以通过选取条件或者自己设置条件从数据库中获取所需的房源信息,从而简化选房的过程,此处筛选条件是灵活的,用户可以通过单关键字或者多关键字混合查询所需的房源信息,如图8所示。
②房源统计信息展示
除了设计二手房的检索功能,还考虑将二手房的相关统计信息在前端展示,主要通过ECharts动态构建图表展示上海地区二手房的地区分布,各地区均价等信息。下图9是前端展示的上海二手房地区分布饼图以及各地区均价柱状图。
⑧地图选房
在前端展示部分还设计了地图选房功能,通过用户指定一区域,地图可以直观显示该区域的二手房源和租房数量,同时在地图上标识这些房源所在的小区,用户可以点击相应的小区查看该小区下房源和租房信息。加入地图选房这一模块是为了让用户对所选房屋在地理上有直观的认识,从而更加方便进行选房和租房,如图10所示。
4结束语
本文将上海房源数据作为研究对象,实现了房价数据的获取、处理、分析、展示。首先,爬取了链家网上的上海房源数据,然后对房源数据进行了预处理,接着使用机器学习中相关算法对房价数据集进行训练,通过比较得到与实际房价拟合度较高的房价预测模型。最后在前端使用ECharts中的图表展示上海地区的房源统计信息,并设计了房源信息检索功能和房价预测功能,此外还调用高德API构建地图实现目标区域内房源信息查询功能。
猜你喜欢
艺术与设计·理论(2016年4期)2017-01-16
科技传播(2016年19期)2016-12-27
商场现代化(2016年22期)2016-10-18
