
基于Logistic回归与XGBoost构建缺血性卒中院内复发风险预测模型的初步比较研究
2020-07-07 06:06谷鸿秋王春娟李子孝王伊龙王拥军姜勇
中国卒中杂志 2020年6期
谷鸿秋,王春娟,李子孝,王伊龙,王拥军,姜勇,3
中国是卒中终身风险最高的国家,全球疾病负担研究显示,中国卒中终身风险高达39.3%,将近全球平均水平的1.6倍[1]。在国内,卒中在单病种死因顺位排名自2010年后一直位居第一[2-3]。卒中的高患病率、高死亡率及高致残率给中国的医疗保健系统造成了沉重的负担。缺血性卒中是卒中的主要类型,约占80%以上[4]。缺血性卒中的预后不稳定,易复发,且早期复发风险最高。据氯吡格雷用于急性非致残性脑血管事件高危人群的疗效(Clopidogrel in High-Risk Patients with Acute Nondisabling Cerebrovascular Events,CHANCE)研究显示,超过80%的卒中复发发生在14 d内[5]。因此,利用预测模型准确预测卒中早期复发风险,提升患者的精准风险分层与管理、优化医疗资源配置、降低院内卒中复发是卒中二级预防中不可忽视的环节。
关于缺血性卒中院内复发风险的预测,目前缺乏特异性的工具。传统的风险预测模型,主要是基于Logistic回归或者Cox回归模型构建,但机器学习算法在处理高维变量,以及变量间复杂的交互作用、非线性关系上具有独特的优势,尤其是XGBoost[6]。本文利用中国国家卒中登记Ⅱ(China National Stoke Registry Ⅱ,CNSRⅡ)数据[7],分别利用传统的Logistic回归和机器学习算法XGBoost构建缺血性卒中院内复发风险预测模型,并进行初步比较,探讨两种模型的预测价值,以期为后续建立更加完善的缺血性卒中院内复发风险预测模型提供借鉴。
1 研究对象与方法
1.1 研究队列与人群 本研究的研究对象来源于CNSRⅡ项目。CNSRⅡ纳入2012年5月-2013年1月全国219家医院发病7 d内的急性卒中住院患者。本研究患者纳入标准:①年龄>18岁;②缺血性卒中患者;③患者出院方式为医嘱离院(考虑到转院或非医嘱离院的患者可能因为在院时间短暂,院内复发事件难以被观测捕捉到)。排除标准:血液检测指标缺失。
1.2 预测因子与结局 结合急性缺血性卒中早期管理指南[8]、文献报道的相关评分预测模型[9]及CNSRⅡ数据特点,确定备选的预测因子包括人口学特征(性别、年龄、教育程度、家庭月收入、吸烟、饮酒),卒中严重程度(入院NIHSS评分、发病前mRS评分),既往病史(卒中、高血压、糖尿病、血脂异常、心房颤动、周围血管疾病、心肌梗死/冠心病),用药史(抗血小板药、抗凝药、降压药、降脂药、降糖药)以及临床测量指标(TC、TG、LDL-C、HDL-C、收缩压、舒张压)。结局为院内的卒中复发事件,包括缺血性卒中和出血性卒中。
1.3 模型构建方法
1.3.1 Logistic回归 Logistic回归是预测结局变量为二分类变量时最为常用的统计模型,其通用形式为:

其中x1,x 2,…,x m即为预测因子,b1,b2,…,bm为m个预测因子的回归系数。①式经过简单变换,可得预测事件的概率P。

1.3.2 XGBoost XGBoost是基于决策树使用梯度提升框架的集成机器学习算法,由华人学者陈天奇博士于2016年提出[6]。XGBoost的思想是先从初始训练集训练出一个基学习器,再根据基学习器的表现对训练样本分布进行调整,使得先前基学习器做错的训练样本在后续受到更多关注,然后基于调整后的样本分布来训练下一个基学习器;如此重复进行,直至基学习器数目达到事先指定的值T,最终将这T个基学习器进行加权结合。XGBoost的基学习器就是一棵树分类器。XGBoost的简要算法的数学描述:假设有k棵树,则模型的表达式为:
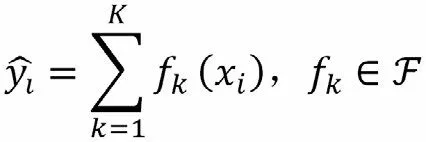
其中F表示回归森林中的所有函数空间。fk(xi)表示第i个样本在第k棵树中落在叶子的权重。目标函数为:

其中,L是损失函数,用来估计预测值ŷɩ与真实值yi的差距,正则项Ω,可以惩罚模型的复杂度,避免过拟合。
1.4 统计学方法 本研究的所有统计分析均在R(3.6.2版)中完成。Logistic回归采用stats包的glm函数,XGBoost采用XGBoost包(1.0.0.1版)的xgb.train函数。超参数的调整优化采用mlr包(2.17.1版),并采用随机搜索算法。符合本研究要求的数据集将按7∶3的比例随机拆分为训练集与测试集,训练集用来拟合预测模型,测试集用来评价模型效果。为防止过拟合,提高模型预测性能,Logistic回归预测模型中,通过赤池信息准则(Akaike information criterion,AIC)筛选训练集中的最优模型。XGBoost预测模型中,采用10折交叉验证法,将训练集进一步细分为10份,循环抽取其中的一份作为验证集,用于调整XGBoost的超参数。Logistic预测模型中预测因子的效应通过回归系数或者OR值及其95%CI体现,XGBoost预测模型中,预测因子的重要性通过SHAP(Shapley Additive Explanation)值体现,SHAP值越高,预测因子越重要[10]。模型的预测性能将从区分度和校准度两个方面进行比较和评价。区分度指标采用受试者工作特征曲线下面积(area under the curve,AUC),AUC值越高,表明模型的区分度越高。校准度指标采用校准截距、校准斜率以及Brier得分[11],并绘制校准度曲线。校准截距和Brier得分越趋近0,校准斜率越趋近1,模型的校准度越好。P<0.05为差异具有统计学意义。
2 结果
2.1 人群基本特征 纳入CNSRⅡ项目中按医嘱离院的急性缺血性卒中患者总计18 142例,剔除了血液检测指标缺失病例915例,17 227例进入最终分析。平均年龄64.72±11.84岁,女性6317例(36.7%),发病前mRS评分为0或1分的病例14 482例(84.1%),入院NIHSS评分4(2~6)分。6095例(35.2%)有卒中病史,伴有高血压、糖尿病及血脂异常病史的患者,分别为13 153例(76.4%)、4493例(26.1%)和6120例(35.5%)。服用抗血小板、降压、降糖及降脂药的患者分别为3338例(19.4%)、7749例(45.0%)、2965例(6.7%)和1156例(15.6%)。总计444例(2.6%)的患者院内复发卒中。各特征在训练集和测试集的数据上非常接近(表1)。
2.2 预测模型构建 Logistic回归预测模型中,最终纳入年龄、家庭月收入、发病前mRS评分、入院NIHSS评分、卒中史、心房颤动、心肌梗死/冠心病、抗血小板、降压药、LDL-C、收缩压及舒张压12个预测因子,具体的回归系数及相对效应见表2。其中,发病前mRS评分、心房颤动及卒中史是前三位强预测因子。XGBoost预测模型,由8棵决策树组合而成,其中第一棵决策树如图1所示。XGBoost构建的预测模型中,前三位强预测因子为发病前mRS评分、心房颤动及TC,具体如图2所示。

表1 研究对象基本特征
2.3 预测模型性能比较 在训练集中,Logistic回归预测模型的AUC低于XGBoo s t预测模型(0.67,95%CI0.64~0.70vs0.72,95%CI0.69~0.76,P=0.0176);在测试集中,与XGBoost预测模型差异无统计学意义(0.63,95%CI0.58~0.68vs0.64,95%CI0.59~0.68,P=0.9229)(图3)。
Logistic预测模型在训练集中的校准截距、校准斜率以及Brier得分分别为0.00、1.00、0.02;在测试集中,分别为-0.81、0.76、0.03。XGBoost预测模型在训练集中校准截距、校准斜率及Brier得分分别为3.31、3.90、0.35;在测试集中分别为-1.37、1.20、0.38。Logistic预测模型的校准度要好于XGBoost预测模型,尤其是在训练集数据中(图4)。
3 讨论
本研究基于CNSRⅡ项目中按医嘱离院的缺血性卒中病例,分别采用了传统的Logistic回归和机器学习方法XGBoost构建缺血性卒中院内复发的预测模型。结果显示,Logistic回归与XGBoost方法在预测性能上非常接近,XGBoost方法在训练集上AUC更高,而Logistic回归的校准度更高,尤其是在训练集数据上。
相较于传统Logistic回归或者Cox比例风险回归模型,机器学习算法在处理高维变量,以及变量间复杂的交互作用、非线性关系上具有独特的优势。XGBoost是机器学习中的一种梯度提升算法,其软件包有其独特的优点,比如:支持并行计算,可调用计算机的所有内核同时运算;支持正则化,可防止模型过拟合;自带交叉验证及缺失值处理机制;灵活支持个性化目标函数和评估指标。因此,XGBoost在预测模型中,受到越来越多的关注和研究,例如,基于国际多中心注册研究的急性心肌梗死预测研究[12],基于医院电子健康档案的卒中后肺炎预测[13],基于患者病史和分诊时收集的信息预测住院患者人数[14]以及癌症患者化疗后的短期死亡预测等[15]。由于各研究中具体的研究问题、研究设计及数据不同,XGBoost预测模型的表现也不尽相同,和传统Logistic回归预测模型相比,有些情形下两者相当,有些情形下XGBoost更优。

表2 基于Logistic回归的预测模型
本研究个案结果显示,相比Logistic回归,XGBoost预测模型并未显示出特别的优越性。这可能与研究的数据有较大的关系。研究数据的维度(变量的个数,变量的种类)、性质(是否包含了真正有预测作用的变量)、数据量(样本量)均有可能影响预测模型的效能。本研究中,预测变量维度和数量有限,这可能在一定程度上限制了机器学习算法的优势。一些强预测因子,比如氧化低密度脂蛋白、中性粒细胞计数、应激性高血糖等血液指标[16-20],梗死模式、狭窄程度等影像指标均未采集[21],无法纳入预测模型中。


图2 XGBoost构建的预测模型中预测因子SHAP值

图3 Logistic与XGBoost构建的预测模型的ROC曲线
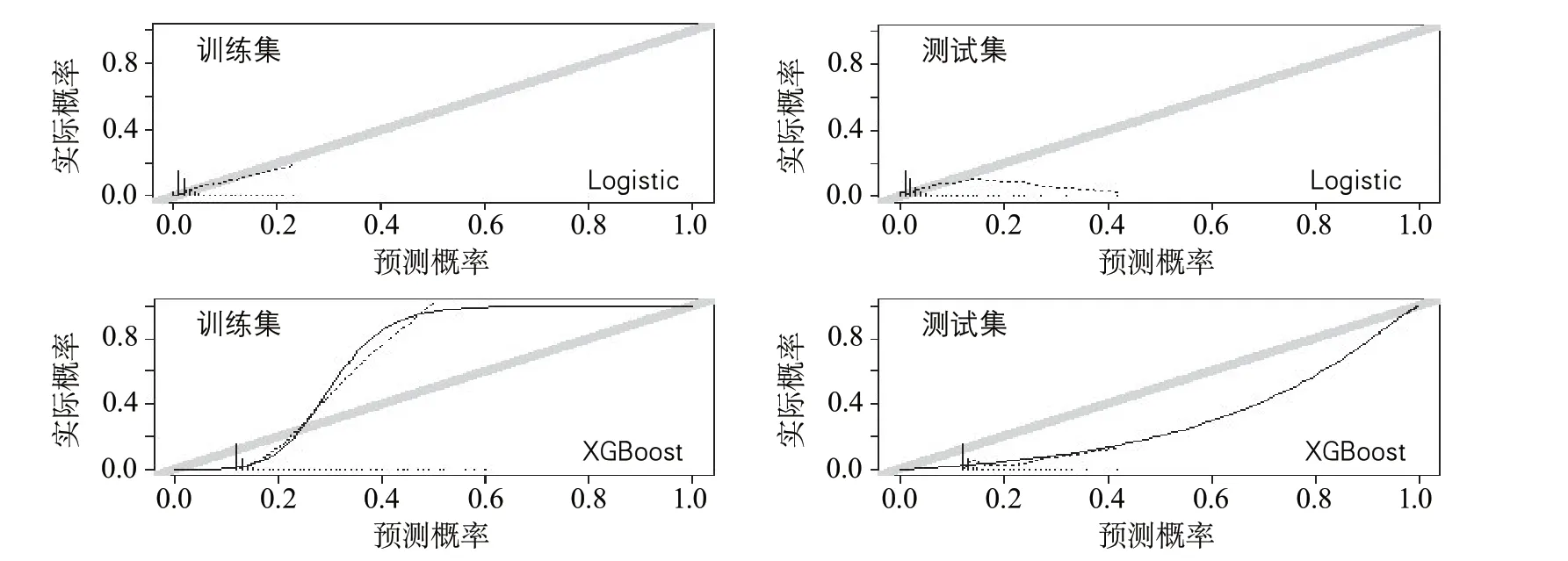
图4 Logistic与XGBoost构建的预测模型的校准度
考察预测模型的好坏,不仅需要评估其预测性能,还需考虑数据采集的成本、开发的难易度以及应用的便利性。一个预测性能良好的预测模型,只有真正普及应用到临床,才能对患者实现精准风险分层管理,优化资源配置、改善患者结局,提高医疗质量。传统的Logistic回归旨在尽可能用最少的预测变量获得最佳的预测效能,因此,一般来说数据采集成本较低,且其原理清晰易理解,开发方便,后期也便于制作评分系统、列线图或者颜色打分卡等不需要电子设备支持即可应用于临床的实用工具[22]。机器学习算法XGBoost原理较为复杂,开发过程长(比如数据需要转换为稀疏矩阵、需要对超参数进行调整等),在预测变量多、关系复杂、数据量大时,旨在尽可能用当下所有的预测变量获得最佳的预测效能,若能将其嵌于临床诊疗系统中,整合在在临床实践中,则数据收集和应用将更为方便,如此方能体现其优势。
传统的Logistic回归与XGBoost方法,在预测模型的构建中,各有优劣。研究者可依据具体的研究问题、研究数据,并考虑到后续的推广使用的成本和便利性,综合决定。随着大数据相关的基础设施和技术的普及,机器学习算法构建的预测模型,将会有广阔的应用前景。
猜你喜欢
基层中医药(2022年7期)2022-11-17
西北林学院学报(2022年5期)2022-10-04
西北林学院学报(2022年4期)2022-08-02
健康体检与管理(2022年4期)2022-05-13
小学生学习指导(高年级)(2021年4期)2021-04-29
医学新知(2019年4期)2020-01-02
华人时刊(2018年17期)2018-11-19
药学研究(2015年11期)2015-12-19
都市丽人(2015年4期)2015-03-20
新高考·高二数学(2014年7期)2014-09-18
