
基于光学和SAR遥感图像融合的洪灾区域检测方法
2020-07-13 02:27王志豪
雷达学报 2020年3期
王志豪 李 刚 蒋 骁
(清华大学电子工程系 北京 100084)
1 引言
遥感技术为地理勘探[1]、建筑测绘[2]、植被监测[3]、水域监测[4]、灾区探测[5]等提供了重要的技术支持。在洪灾区域检测中,光学遥感能够提供丰富的光谱信息和较高的图像分辨率,而雷达遥感则具备全天候的洪灾区域检测能力[6]。异质图像融合已经在复Contourlet域得到了实现[7],因此结合光学遥感数据和雷达遥感数据能实现洪灾区域的全天候、高时效检测[8]。
当前,学者们提出许多基于遥感图像的洪灾区域检测方法。其中,应用人工神经网络和自组织映射网络[9]方法处理洪灾前后的同质SAR图像时能大致区分洪灾区域,但是受到大量相干斑噪声的影响,检测结果仍然存在很高的虚警率。为了结合光学遥感图像和SAR图像的成像优势,一些学者提出了基于异质图像的洪灾区域检测方法,例如像素变换法[10]和特征空间变换法[11]。上述方法对洪灾前的SAR图像和洪灾后的光学图像有良好的检测效果,但是对洪灾前的光学图像和洪灾后的SAR图像的检测效果较差。
针对SAR图像中洪灾区域的检测难点,本文提出了H-FCM算法。该算法的主要贡献如下:
(1) 提出SAR图像的分级聚类模型;
(2) 将洪灾前的近红外波段光学遥感图像中提取出的河流位置融合到洪灾后的SAR图像中,并作为洪灾区域检测的空间约束,进一步提升了检测结果的准确率。
文章结构如下:第2节分析了近年来洪灾区域检测方法的发展和存在的问题。第3节介绍了分级C均值聚类算法Hierarchical Fuzzy C-Means (H-FCM)算法的原理、步骤以及参数设定对算法性能的影响。第4节应用包括H-FCM算法的4种算法对不同类型遥感数据进行洪灾区域检测,并分析了图像降噪处理对4种算法检测性能的影响。第5节系统总结了全文的主要工作和存在的不足。
2 洪灾区域检测方法的发展
2.1 传统的洪灾区域检测方法
目前,学者们提出的基于雷达遥感图像的水体检测方法包括灰度阈值分割法、滤波法、机器学习法和结合辅助信息的提取方法等[12];基于光学遥感图像的提取水体方法包括基于像元分类的阈值法和基于目标分类的分类法等[12]。洪灾是由于大雨、暴雨或者持续降雨造成的,此时无法通过实时获取的光学遥感数据检测地面的洪灾区域。
以2019年8月9日对利奇马台风实时追踪的GF4数据(见图1)为例,光学图像无法显示地表的洪灾区域。但是通过适当的卫星调度方案可以短时间内获取雷达遥感数据。以2019年8月8日对利奇马台风实时追踪的GF3数据(见图2)为例,SAR图像可以清晰地显示地面受灾情况。
应用阈值分割法中的最大类间方差算法[13]对灾后的SAR图像进行洪灾区域检测时,由于受到相干斑噪声的影响,检测精度较低。为克服相干斑噪声的影响,学者们提出了滤波法[14]、边界追踪法[15]、Markov分割法[16]、基于邻域最小生成树的半监督分类法[17]、基于概率转移卷积神经网络的分类法[18]等。但是洪灾区域检测问题的核心在于保证高检测准确率的同时,尽可能缩短检测时间,而上述方法的计算复杂度普遍较高,并不能满足洪灾区域检测的高时效性需求。

图1 利奇马台风的GF4图像(资源卫星中心)Fig.1 The GF4 image of Typhoon Lekima(Resource Satellite Centre)

图2 利奇马台风的GF3图像(资源卫星中心)Fig.2 The GF3 image of Typhoon Lekima(Resource Satellite Centre)
直接利用K-means算法[19]、C均值聚类方法(FCM)算法[20]等无监督聚类算法对洪灾后的SAR图像进行洪灾区域检测可以缩短检测时间,但是检测结果的分类准确率很低。具体原因如下:根据灰度阈值分割法的原理,在SAR图像中,水体的散射值较低,整体呈现为暗区。在没有发生暴雨或者持续降雨的情况下,可以通过分析SAR图像的整体像素值分布,应用FCM算法等聚类算法确定水体的分割阈值。根据分割阈值,将大于阈值的标记为非水体,小于阈值的标记为水体。但是洪水灾害发生时伴随着暴雨或者持续降雨,导致很多未受到洪灾影响的区域在SAR图像中也呈现为暗区。因此,直接通过阈值法获得的检测结果存在较高的虚警率。
2.2 FCM算法原理
FCM算法的步骤总结为表1。以洪灾后的大小为n1×n2像素的SAR图像为例,将其所有像素点的像素值记作二维矩阵X。将X分成c类,则可以得到c个聚类中心。将每一个像素点作为单个样本xj,则xj对于第i类聚类中心的隶属度可记作uij,FCM算法的目标函数、约束条件的定义式分别为式(1)和式(2)

其中,Ci表示第i类聚类中心;m表示隶属度因子;n=n1×n2;i=1,2,…,c;j=1,2,…,n。
结合式(2)的约束条件,利用拉格朗日乘数法,将J分别对uij和Ci求导,并令其结果等于0,可得uij和Ci的迭代式分别为式(3)和式(4)

3 H-FCM算法原理
本文提出的H-FCM算法致力于缩短SAR图像洪灾区域的检测时间、降低洪灾区域的错误检测概率以及抑制SAR图像中存在的大量随机分布的相干斑噪声对检测结果的影响。根据河流连续体(River Continuum Concept,RCC)[21]的概念,在已知的河流系统内,自上游到下游的物理变量的梯度变化是连续的[22]。因此发生洪水灾害之后,若地理环境没有发生剧烈变化,洪水的形态仍然符合RCC。并且,根据典型地物的光谱特征曲线图[23](见图3),水体对近红外波段的电磁波吸收能力比大部分地物强。

表1 FCM算法Tab.1 FCM algorithm
H-FCM算法的应用前提为可获得洪灾前的光学图像以及洪灾后的SAR图像。该算法通过对遥感图像的像素强度划分进行分级聚类。以uint8格式的图像数据为例,应用FCM算法获得待测数据像素值的8个聚类中心,并且由低至高排列。根据图3,SAR图像中代表水体的像素点的像素值主要分布在0~64之间,即处于低像素值区间。但是由于发生洪灾时,SAR图像中存在大量随机分布的相干斑噪声以及低洼地区存在的积水,直接用阈值法进行洪灾区域检测的准确率较低。
H-FCM算法采用反向聚类的方法,考虑到在SAR图像中,代表水体的像素点几乎不可能处于高像素值区间。H-FCM算法在聚类过程中将处于最高级的像素值区间的像素点记为1,其余像素点记为0,对所有零像素点进行区域聚类,获得初步的洪灾区域检测结果。又由RCC原理,洪灾发生后,主要受灾区域与洪灾前的河流相连通,利用灾害前的河流位置作为空间约束可以得到近似真实洪灾区域的检测结果。因此,应用H-FCM算法检测洪灾发生后的SAR图像的洪灾区域,可以降低相干斑噪声对检测结果的影响。
H-FCM算法主要分为4步。首先,应用FCM算法获得洪灾后SAR图像的聚类中心,进而设置分类阈值,并确定分级聚类模型;其次,提取灾害前近红外波段光学遥感数据中的河流位置,并将其融合到洪灾后的SAR图像中;再次,以聚类模型为基础进行分级聚类,获得洪灾区域的初步聚类结果;最后,通过空间约束矩阵对初步聚类结果进行约束,进一步提升洪灾区域检测的准确率。

图3 典型地物的光谱特征曲线[23]Fig.3 Spectral characteristic curves of typical features[23]
3.1 建立分级聚类模型
利用FCM算法获得洪灾后SAR图像的八分类的聚类中心矩阵C和阈值矩阵T,并由此获得7个聚类模型
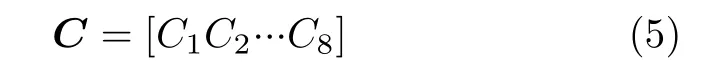
其中,一维矩阵C表示聚类中心矩阵,包含8个按照升序排列的聚类中心

其中,T0=0,q=1,2,…,7。
以1999年英国格洛斯特洪灾后获得的SAR图像Ea[10]为例,其大小为n1×n2(见图4)。遍历Ea中的所有像素点,若其像素值大于Tq–1且小于Tq则在对应位置标记为1,否则标记为0,将所得到的矩阵记作聚类模型Gmq,如式(8)

其中,“(Gmq)m n∈Gmq”在本文中均代表(Gmq)mn是Gmq矩阵中第m行,第n列的元素,下文符号“∈”的含义与此处一致;(Ea)m n∈Ea;q=1,2,…,7。
3.2 灾后SAR图像融合灾前河流空间信息
3.2.1 SAR图像洪灾区域检测的改进方法

图4 洪灾后的SAR图像Ea[10]Fig.4 SAR imageEa after the flood[10]
由于SAR图像的成像模式一般为宽幅扫描模式,同时受到SAR图像中相干斑噪声的影响,在没有灾害前河流信息的情况下直接采用无监督聚类的方法来检测Ea中的洪灾区域存在较高的虚警率,导致检测结果的准确率较低。H-FCM算法将洪灾前河流的空间信息融合到洪灾后的SAR图像中,通过局部空间约束,可以提高洪灾区域检测的准确率。但是在图4中,Ea的河流位置有一部分被背景地物或者噪声覆盖,另一部分和洪灾区域重合,导致大部分的河流位置已经无法识别。为了获得洪灾前的河流位置信息,H-FCM算法进一步检测洪灾前的光学图像。
以1999年英国格洛斯特洪灾前的SPOT图像中提取的近红外波段图像Ei[10]为例(见图5)。由于不同河段的河流泥沙含量不同,造成不同河段对近红外波段电磁波的吸收能力不同[24],通过阈值法无法直接获得所有河流区域的空间位置。考虑到洪灾前的水体表面近似为平滑面,可以应用区域生长算法[25]提取洪灾前近红外波段遥感图像的河流位置。本文提出的区域生长算法为表2,根据图5中近红外波段的光学遥感图像可以利用该算法获得洪灾前的河流位置。

图5 洪灾前的近红外波段影像Ei[10]Fig.5 Near-infrared imageEi before the flood[10]

表2 区分河流和道路的区域生长算法Tab.2 Region growing algorithm to distinguish rivers and roads
3.2.2 检测河流位置的区域生长算法规则
由于步骤(2)获得的第2类阈值图Pt(见图10)中存在大量的区块噪声的干扰,无法从中直接获得灾害前的具体河流的空间位置。因此,需要筛除大面积区块性的非河流区域。像素点的面积定义为:将像素值为1的像素点的面积记作1,像素值为0的像素点面积记作0。连通区域的面积定义为:将连通区域内所有非零像素点的面积累加得到该区域的面积。4连通区域的定义为目标像素点(红色方块)的上、下、左、右4个像素点位置(见图11)。
为了充分消除区块噪声的影响,并保留河流区域的完整性,步骤(3)的卷积操作分为两步。首先,确定大小为α×α的全1卷积核Wα,将Pt与Wα卷积得到初步消除区块噪声的结果P1,如式(9)和式(10);其次,将P1与Wβ卷积得到基本消除区块噪声的结果P2,如式(11)和式(12)。为保证卷积之后的输出结果的尺寸与原图像大小保持一致,本文所有的卷积模式均采取matlab中conv2函数的‘same’模式进行卷积
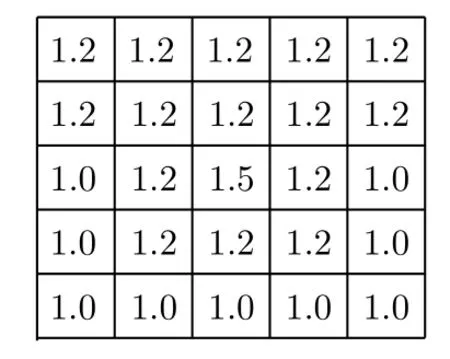
图6 方向矩阵Jd1(向下)Fig.6 Direction matrix Jd1(down)
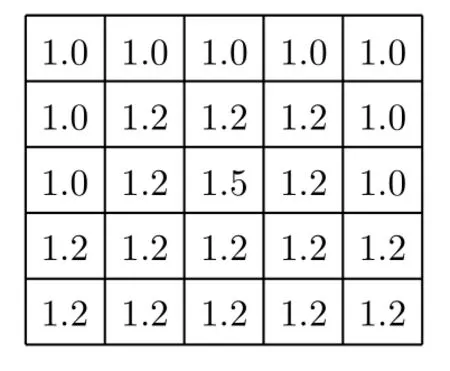
图7 方向矩阵Jd2(向上)Fig.7 Direction matrix Jd2(up)
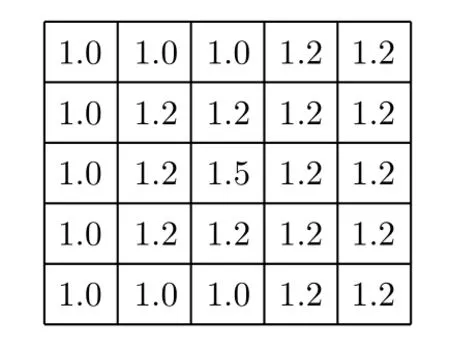
图8 方向矩阵Jd3(向左)Fig.8 Direction matrix Jd3(left)
图9 方向矩阵Jd4(向右)Fig.9 Direction matrix Jd4(right)

3.2.3 区域生长算法的参数选择
参数α一般为固定的大小,当选择的α较大或者较小时,在筛除区块噪声的同时,也筛除了河流。本文固定参数α=18的卷积核Wα初步筛除大面积聚点,获得P1;其次,固定参数β=9的卷积核Wβ进一步筛除小面积聚点,获得P2。利用式(13)至式(15)确定河流区域种子生长点的位置Po,在Po的每一个4连通区域中等间距选择10个像素点作为初始生长点(见图12)。
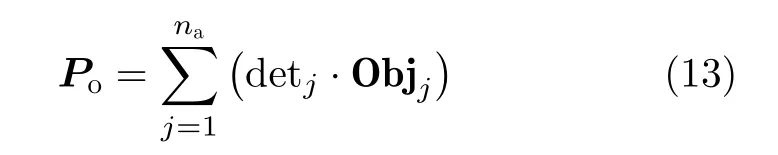

图10 第2类阈值图PtFig.10 Threshold graphPt

图11 4连通区域的定义Fig.11 Definition of four-connected regions
其中,Objj表示P2中的第j个4连通区域;P2中4连通区域总数为na;每个连通区域的背景大小均为n1×n2;j=1,2,…,na
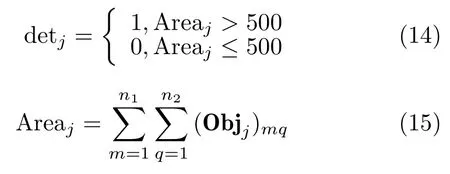
其中,Areaj表示P2中第j个4连通区域Objj的面积。
3.2.4 利用区域生长算法获得河流位置
根据图12中获得初始生长点,按照步骤(5)进行4个方向的区域生长,最后将各个方向的生长结果累加得到初步生长结果(见图13)。但是由于本例中道路和河流交错,当道路和河流宽度相近且没有先验测绘信息时,直接通过机器识别提取并区分河流和道路的空间位置是非常困难的。所以在步骤(7)中利用霍夫变换[26]检测初步生长结果中属于公路的长距离直线段区域,进而识别道路所在区域(见图14)。最后,将初步生长结果去除道路区域后,得到河流位置Eb(见图15)。
3.2.5 灾后SAR图像与灾前河流位置融合

图12 初始生长点位置Fig.12 Initial growth point location

图13 初步生长结果Fig.13 Preliminary growth results
将洪灾前的河流位置Eb和洪灾后的SAR图像Ea融合。融合规则为将Ea中与Eb中灾前河流位置对应的所有像素点的像素值记作T1,其余像素点的像素值保持不变,如式(16),将融合后的灾后SAR图像记作Fu(见图16)
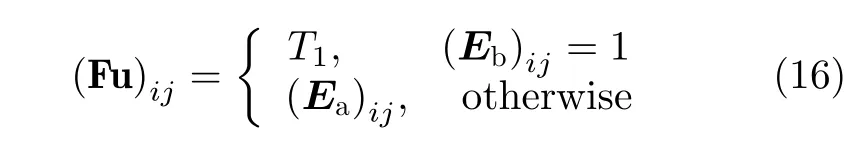
其中,(Fu)ij∈Fu,(Eb)ij∈Eb,(Ea)ij∈Ea。
3.3 分级聚类

图14 道路的识别结果Fig.14 Road recognition results

图15 洪灾前的河流位置EbFig.15 River locationEb before the flood

图16 融合后的灾后SAR图像FuFig.16 Fusion post-disaster SAR image Fu
光学图像的水体和非水体的区分可以通过计算归一化水指数(Normalised Difference Water Index,NDWI)[27]检测,但是SAR图像中不含多通道图像信息,不能直接计算其NDWI来区分水体和非水体。通过观察融合后SAR图像的高像素值区间Gm7(见图17),可以发现真实洪灾区域的像素点在其中几乎全部表现为零像素值。同时,根据RCC原理,真实洪灾区域在整个图像空间呈现较高的区块性的稀疏度。即代表洪灾区域的非零像素值区域是一个连通区域,其余零像素值区域均为非洪灾区域,所以作为洪灾区域检测的聚类模型应当具备较高的稀疏度。Gm7是一个反向模型,洪灾区域基本呈现为零像素区域,非洪灾区域基本呈现为非零像素的散点分布。
在目标检测中,文献[28]定义图像稀疏度为非零像素点个数K1,考虑到洪灾区域检测的目标地物覆盖范围较广,本文进一步引入文献[29]中图像稀疏占比的定义。即模型的稀疏占比为待测图像中非零像素点个数和所有像素点个数的比例,稀疏占比K2的定义式为公式(17)。聚类模型的稀疏度分析,以Gm7聚类模型为例,检测结果如图18。

图17 聚类模型Gm7Fig.17 Clustering model Gm7

图18 聚类模型的稀疏度分析Fig.18 Analysis of sparsity of clustering model

通过分析聚类模型Gm7的稀疏度,得到其稀疏占比为0.10905,可以确认该模型本身具有较高的稀疏度。并且该模型的非零像素点代表最高级像素值的分布,实际洪灾区域在该模型中基本处于零像素值区域。对聚类模型Gm7进行卷积运算后,根据卷积结果得到每一个像素点周围非零像素点的总数,并由此判断该像素点是否为洪灾区域。

其中,Wk表示大小为k×k的全1卷积核。
H-FCM算法对聚类系数φ和卷积系数k的选择较为敏感。当选择的φ过大时,聚类结果包含较多的非洪灾区域;当选择的φ较小时,聚类结果舍弃了较多真实洪灾区域。相应地,当选择的k过大或者过小时,聚类结果都将包含较多的非洪灾区域。为使这两类参数选择达到最优检测性能,应当在选择最佳聚类模型的同时,依据模型的稀疏度来确定相应的聚类系数和卷积系数。考虑到SAR图中大量随机分布的相干斑噪声,为减弱噪声对检测性能的影响,φ,k的选择要比实际的稀疏占比更小,φ,k与K2的关系定义为式(19)。


图19 初步聚类结果Gr7Fig.19 Preliminary clustering results Gr7
3.4 洪灾区域检测的空间约束
H-FCM算法在对洪灾区域的空间约束上提出了一种参数自适应的空间约束方法,有效地筛除疑似洪灾区域,并提升检测性能。由于洪灾区域的水体满足RCC原理,定义洪灾区域主要范围为Rt。Rt表示初步聚类结果Gr7的4连通区域面积最大的连通区域。
由于真实洪灾区域在整个图像空间存在较高的稀疏度,即非洪灾区域处于零像素值区域,洪灾区域呈现为非零像素值的连通区域。此时,等间距增大空间约束范围会增加计算复杂度。引入约束矩阵CSβp作为初步聚类结果的空间约束,当约束系数βp不断减少时,整体的空间约束范围按照e指数级不断增大。由于真实洪灾区域在全局上具备较高的稀疏度,约束系数βp按照等间隔减小的过程,对应约束范围呈e指数级的扩大。因此,式(21)的搜索规则符合洪灾区域的区块稀疏分布特点,既能保证获得适应待检测图像的约束系数,又不增加额外的运算量。
约束系数βp的自适应选择方法,主要是依据两个因素:
(1) 根据RCC原理,洪灾发生时,洪灾区域在遥感图像上满足4连通区域的连通性;
(2) 远离洪灾前河流位置的低洼地区在洪灾发生时与洪灾区域相邻接的概率较低。

其中,e为自然常数,p=1,2,…,100

本文采用曼哈顿距离来表示像素点之间的空间距离,可以在保证检测性能的基础上,降低算法的运算量。洪灾区域的空间约束式exp(-dij/dmax)的取值范围为(0.367,1](见图20)。并且当dij越小时,exp(-dij/dmax)的值越接近1,当d ij越大时,exp(-dij/dmax)的值越接近0.367,确保距离灾害前河流位置越近的像素点被检测为洪灾区域的概率越大。

图20 洪灾区域空间约束曲线Fig.20 Spatial constraint curve of flooded area
将洪灾区域主要范围Rt加上空间约束CSβp,可以进一步提升洪灾区域检测结果的准确率。由式(23)可以获得约束系数为βp时的洪灾区域检测结果Outβp。
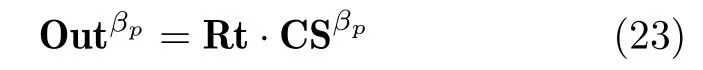
其中,“A·B”表示矩阵A与矩阵B的点乘运算,即矩阵A和矩阵B对应点相乘。
约束系数βp自适应选择的目的是判定疑似灾区S是否为真正灾区,以获得洪灾区域的最终检测结果。所以在βp的搜索过程中,若对应的疑似灾区的面积增长比率远小于聚类模型本身的稀疏度时,则判定疑似灾区为未受灾区域

其中,“–”表示矩阵对应点像素值作差
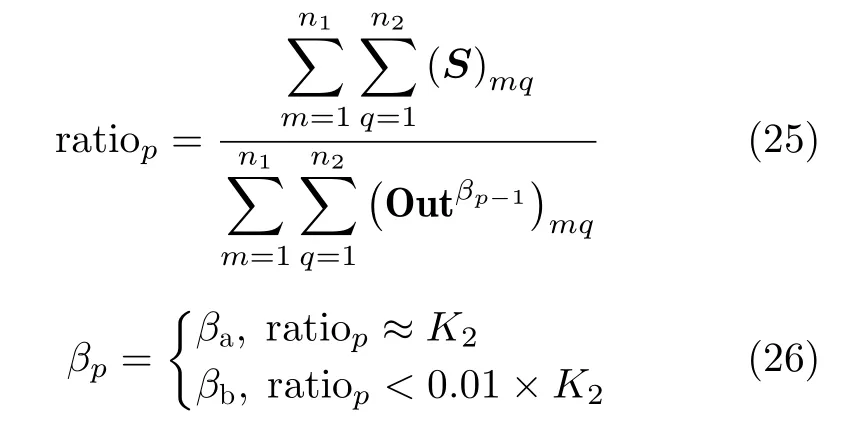
其中,“≈”近似的误差为±0.001;p=1,2,…,100

其中,Sj表示S中的第j个4连通区域,其背景大小为n1×n2

其中,Aj为Sj的面积,α1,α2为判定系数

其中,lj表示重合边界长度;(CHj)mq∈CHj; CHj为Sj与Outβa的重合边界,其宽度为2个像素单元。
将得到的约束系数βa,βb带入到式(24),获得待定的疑似灾区S。根据RCC原理,若疑似的4连通区域为真实洪灾区域,则其像素面积Aj与Sj和Outβa邻接的边长lj的比值应处于(α1,α2)区间内。当面积边长比过大时,说明疑似灾区与真实洪灾区域相邻接的边界较短,可判定为非灾区;当面积边长比过小时,说明疑似灾区面积较小,属于区块噪声的可能性比较大。最后,根据每一个疑似区域的判定结果dtj确定该区域是否为洪灾区域,并将判定结果与Outβa累加得到最终的洪灾区域检测结果FF。
4 实验结果与分析
4.1 检测结果的评价指标
(1) 正确检测概率。Righta表示所有像素点被正确检测为变化的概率与被正确检测为未变化的概率之和

其中,Nr_c表示正确检测为变化的像素点总数,Nr_uc表示正确检测为未变化的像素点总数,Nt表示像素点总数。
(2) 遗漏检测概率。Missa表示所有实际发生变化的像素点没有被检测为发生变化的概率

其中,Nc表示实际发生变化的像素点总数;Nm表示实际变化的像素点未被检测为变化的像素点总数。
(3) 错误检测概率。Wra表示所有像素点被错误检测的概率,即实际未发生变化的像素点被错误检测为发生变化的概率与实际发生变化的像素点被检测为未变化的概率之和
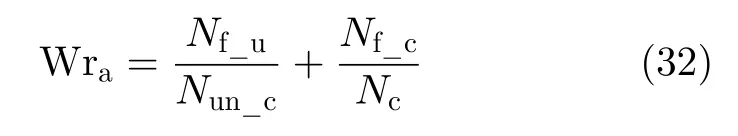
其中,Nf_u表示实际发生变化的像素点被检测为未变化的总数;Nun_c表示实际未发生变化的像素点总数,Nf_c表示实际未发生变化像素点被检测为变化的总数。
(4) 卡帕系数

其中,po表示总体分类精度。

Nd_c表示检测为发生变化的像素点总数,Nd_uc表示检测为未变化的像素点总数。
(5) 计算时间。以计算时间衡量算法的时间复杂度,计算时间定义为Time,其单位为“s”(秒)。
(6) 迭代次数。以运算的迭代次数体现算法的运算复杂度。迭代次数定义为Iter,其单位为“次”,表示对应算法获得聚类中心的迭代次数。
4.2 实验数据的预处理和参数选择
本文的实验数据是在确定目标灾害区域地理坐标的基础上,获得洪灾前遥感图像和洪灾后遥感图像的历史数据。实验数据的预处理过程主要分为4步。首先,利用ENVI5.3软件的Orthorectification模块对洪灾前后的遥感数据分别进行正射矫正;其次,利用ENVI5.3软件Registration模块中的Image to Image方式,以洪灾前的光学图像为基准,选择关键角点为控制点对同地区的其它遥感数据进行配准;再次,裁剪相同大小配准后遥感数据作为实验数据;最后,利用ENVI软件获得洪灾后光学图像的NDVI图像,通过人工标注的方法确定真实洪灾区域,作为各类算法检测结果性能指标评定的参照对象。
H-FCM算法的参数选择,只需要确定判定系数α1,α2。卷积系数k、聚类系数φ可以通过分析聚类模型的稀疏度获得,约束系数βa,βb可以通过自适应选择获得。判定系数的范围是通过统计英国格洛斯特的历史洪灾数据的贝叶斯更新结果[30]获得的最优区间,在H-FCM算法中被设置为固定的区间。并且该区间定义在4.3节中实验1和实验2的结果中均获得了较好的检测性能。
为了验证H-FCM算法在洪灾检测领域的普适性,本文通过收集案例中的河流历史洪灾信息,利用历史实测数据来确定不同河段发生洪灾的空间约束系数。基于该河流的历史灾害数据进行贝叶斯更新[30],可以发现某一河段附近地区受洪灾影响的范围与该河段的河流宽度、河床高度、河道转角系数密切相关。参考英国格洛斯特的历史灾害数据[31],可以得到洪灾区域的约束系数βa,βb与河流平均宽度lm的近似对应关系

其中,lm通过计算图15的平均河宽得到。
计算实际数据得到dmax=1338,lm=4.5,其单位均为像素单元。依据真实灾害数据统计的近似对应关系得到的βa=0.8997,βb=0.7719。对比自适应选择的约束系数,βa的选择结果与洪灾的统计历史数据较为吻合,但是βb的选择结果与洪灾的统计历史数据有一部分偏差。这是由于该流域的历史洪灾规模不同,本例所体现的洪灾区域要大于历史平均水平,所以本例的βb的自适应选择结果要小于根据历史统计得出的结果,对应实际更大的洪灾区域。
4.3 4种检测方法的比较
为充分论证H-FCM算法对洪灾前光学图像和洪灾后SAR图像的变化检测性能,在对比实验中加入了图像分割算法—分水岭算法(Watershed Algorithm,WA)[32],边缘检测算法(Snake)[33],H-Kmeans算法等3种方法作为对比实验方法。此外,将1999年英国格洛斯特洪灾数据、2019年中国南昌附近洪灾的洪灾数据等两个场景作为实验数据。
4.3.1 实验1
以1999年英国格洛斯特洪灾前的近红外波段图像和洪灾后的SAR图像[10]为例,检验H-FCM算法的有效性。将融合后的SAR图像(见图16)记作Fu,其大小为2359×1318像素,采用的聚类模型为Gm7。设定判定系数α1=120,α2=160,计算获得其卷积系数k=85,聚类系数φ=0.054。通过自适应选择得到的约束系数βa=0.9199,βb=0.7199,最终的检测结果为图21。
首先,将实验1中洪灾后的NDVI图[10](见图22)进行人工标注获得洪灾区域的真值图(见图23)。WA算法的洪灾区域检测方法是根据整体像素值分布(见图24),将所有像素点进行二值化,然后求出零值与最近非零值的距离,画出分水岭,进而对图像进行二分类。Snake算法获得Ea的边缘轮廓(见图25),按照式(18)和式(20)对边缘轮廓检测结果进行卷积运算得到最终洪灾区域检测结果。H-Kmeans算法是在Kmeans聚类(八分类)的基础上,进行分级聚类,从而得到洪灾区域的检测结果。
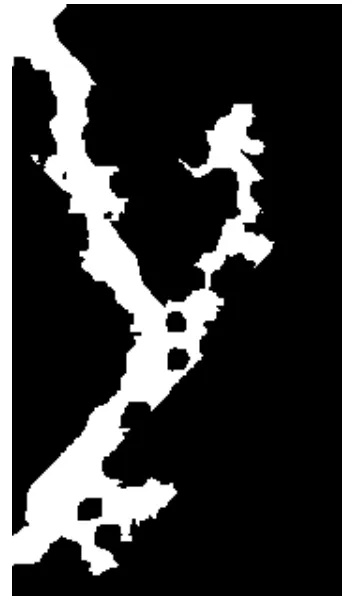
图21 最终检测结果FFFig.21 Final experimental result FF
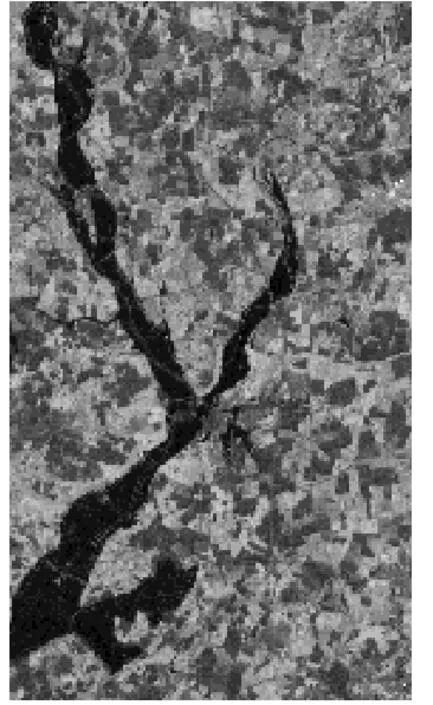
图22 洪灾后的NDVI图像[10]Fig.22 NDVI images after the flood[10]

图23 人工标注的真值图Fig.23 Manually labeled truth map

图24 像素值分布三维图Fig.24 3-D map of the distribution of pixel values

图25Ea的边缘轮廓Fig.25 Edge profile ofEa
其次,将H-FCM算法、WA算法、Snake算法以及H-Kmeans算法获得的洪灾区域检测结果与真值图(图23)比较,得到4种算法的检测结果与真实灾区的比较结果(见图26)。在图26中,白色部分表示实际洪灾区域被检测为洪灾区域;绿色部分表示实际洪灾区域被检测为非洪灾区域;红色区域表示实际非洪灾区域被检测为洪灾区域;黑色部分表示实际非洪灾区域被检测为非洪灾区域。本文后续实验的检测比较结果与图26的表示方法一致。
根据4.1节中对6项评价指标的规定,按照4种算法分别用matlab进行计算分析,得到每一种算法检测结果对应的性能指标(见表3)。观察表3的各项评价指标可以发现H-FCM算法有最高的正确检测概率、最低的错误检测概率以及最高的Kappa系数。H-Kmean算法虽然有着与H-FCM算法接近一致的检测性能,但是其计算成本较高。综合考虑洪灾区域检测的高准确检测率和高时效性的要求,H-FCM算法具有相对最优的检测性能。
4.3.2 实验2
实验2的数据来源于欧洲航天局的开源数据,分别为哨兵1号和哨兵2号卫星在2019年6月对中国南昌附近的观测数据(见图28)。按照H-FCM算法,首先,将图28(a)中提取的的洪灾前河流空间位置与图28(d)中洪灾后的SAR图像融合;其次,对融合图像进行分级聚类;最后,对聚类结果加以空间约束并获得检测结果。根据图28(c)的洪灾后的光学数据,人工标注真实洪灾区域范围(见图27)。比较4种检测方法对融合后SAR图像的洪灾区域检测结果(见图29)和性能指标(见表4),可以得出H-FCM算法具有相对最优的检测性能。
实验2的参数设定如下,将融合后的SAR图像记作NCa,其大小为1025×1025像素,采用的聚类模型为Gm7;设定判定系数α1=120,α2=160;卷积系数k,聚类系数φ和约束系数βa,βb均基于NCa由式(19)和式(26)获得。
4.4 图像降噪处理对算法检测性能的影响
Refined Lee filter(RL)[34]在滤除相干斑噪声的同时能较好地保持SAR图像的边缘特征。为分析图像降噪处理对上述算法检测性能的影响,首先对实验1中洪灾后的SAR图像进行RL滤波降噪,再利用上述4种方法对降噪处理后的图片进行洪灾区域检测。定义新的检测方法分别为RL_H-FCM算法、RL_WA算法、RL_Snake算法、RL_H-Kmeans算法,其检测结果如图30所示,检测性能评价指标如表5所示。

表3 融合后SAR图像洪灾区域的检测结果Tab.3 Detection results of flooded area in fusioned SAR image

图27 人工标注的洪灾区域Fig.27 Manually labeled flooded areas
比较表3和表5中上述4种算法对应的性能指标,可以发现RL_Snake算法的检测性能提升最为明显。这是由于Snake算法是先获得图像的边缘特征,再对边缘轮廓的内外进行区分。通过RL滤波可以减少相干斑噪声的影响,使得图像整体像素值的均值和方差更稳定,有利于提取图像的边缘特征。但是通过RL滤波对H-FCM算法、WA算法和H-Kmeans算法的性能提升有限,反而极大地增加了算法的计算复杂度。总体而言,利用H-FCM算法直接对洪灾前的光学图像和洪灾后的SAR图像进行洪灾区域检测时,其检测性能与降噪处理后的图像检测性能几乎一致,而直接检测的运算时间大幅度减少。所以应用H-FCM算法直接处理配准后的光学和SAR图像,既可以缩短洪灾区域的检测时间又可以保证相对较高的检测准确率。
5 结束语

图28 洪灾前后哨兵1,哨兵2数据Fig.28 Sentinel 1,2 data before and after flood

图29 4种算法的洪灾区域检测结果Fig.29 Detection results of flooded area based on four algorithms

表4 融合后SAR图像洪灾区域的检测结果Tab.4 Detection results of flooded area in the fusioned SAR image

图30 RL滤波后4种算法的洪灾区域检测结果Fig.30 Detection results of flooded area based on four algorithms after RL filtering

表5 RL滤波后SAR图像的洪灾区域检测结果Tab.5 Detection results of flooded area in the SAR image after RL filtering
本文提出的H-FCM算法综合考虑洪灾区域检测的高准确率和高时效性的需求,既提升了SAR图像的洪灾区域检测精度又缩短了检测时间。H-FCM算法区别于传统的无监督聚类算法,没有直接对待处理的图像进行无监督聚类,而是提出了一种反向聚类的方法。首先,H-FCM算法将洪灾前光学图像的河流位置检测结果与洪灾后的SAR图像融合;其次,在融合图像的最高级像素值区间对零像素值点进行分级聚类;最后,H-FCM算法在对融合图像的洪灾区域进行分级聚类的基础上,将洪灾前的河流位置作为空间约束,进一步筛除疑似洪灾区域以提升检测性能。
H-FCM算法将洪灾前的光学图像和洪灾后的SAR图像融合后进行洪灾区域检测,实现了全天侯、高准确率、高时效的洪灾区域检测要求。虽然H-FCM算法在一定程度上解决了SAR图像相干斑噪声给洪灾区域检测造成的问题,但是还有部分灾区的细节没有精确检测到,这有待在未来的工作中解决。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
锦绣·上旬刊(2022年2期)2022-05-16
疯狂英语·新阅版(2021年10期)2021-12-08
疯狂英语·新悦读(2021年10期)2021-11-23
计算机应用与软件(2021年7期)2021-07-16
中国传媒大学学报(自然科学版)(2021年5期)2021-02-24
现代电子技术(2021年1期)2021-01-17
现代电子技术(2018年18期)2018-09-12
电脑知识与技术(2018年35期)2018-02-27
科学家(2017年12期)2017-08-10
