
亲缘关系预测系统
2020-07-15 13:31王鑫,李悦,文豪,范虹*,刘京*
生命科学研究 2020年3期
王 鑫,李 悦,文 豪,范 虹*,刘 京*
(1.陕西师范大学计算机科学学院,中国陕西西安710119;2.公安部物证鉴定中心北京市现场物证检验工程技术研究中心现场物证溯源技术国家工程实验室,中国北京100038)
目前,我国亲缘关系鉴定大多使用常染色体短串联重复(short tandem repeat,STR)遗传标记位点[1~3]。在刑事侦查领域,通过对Y-STR进行检验,可以开展家系排查和辅助父系亲缘鉴定,从而为案件侦查提供线索[4]。遗憾的是,Y-STR只能针对父系亲属,无法对母系亲属进行排查[5],而近年来半同胞、舅甥、姑侄等复杂亲缘关系鉴定诉求不断增加,现有的鉴定方法已远远无法满足物证鉴定的需要。随着全基因测序技术的发展,使用全基因单核苷酸多态性(single nucleotide polymorphism,SNP)数据进行亲缘关系预测的技术应运而生并快速发展[6~7],解决了当下遇到的这一难题。该技术旨在通过亲缘关系预测算法,基于全基因SNP测序数据计算某个群体中所有存在的亲缘关系对。
早在2011年这些亲缘关系预测算法就已经有报道[8],且这些软件如Plink/KING均为国外免费开源软件。Plink是一款用于基因组关联分析的开源软件,具有基因组数据格式转换、基础基因组信息统计、LD(linked dimorphisms)计算、共祖片段IBD(identical by descent)距离计算等功能[9],在亲缘关系预测中主要使用该软件进行数据归一化处理,为后续算法软件提供原始输入文件。KING是一款使用全基因SNP数据精确推断任何一对个体亲缘关系等级的软件,可计算高达4级的亲缘关系,支持接受Plink转换后的二进制格式文件[10]。
然而,这一技术的原有预测流程十分繁琐,需要对全基因组数据进行预处理,并使用Plink软件将文件转化为二进制,再使用KING软件计算出亲缘关系等级;如果需要知道其实际亲属关系,还要按照亲缘关系等级判断方法逆向还原。鉴于此,本文提出并开发了一套具有极强交互性的分析系统——亲缘关系预测系统(Kinship Prediction System Version 1.0,KPS v1.0),该系统的处理流程界面化、自动化、简单化,可以自动预处理全基因组数据,并将最终结果自动绘制成家谱图。
KPS v1.0极大地简化了亲缘关系预测的流程,不需要操作人员熟练掌握数据处理脚本语言和生物信息学软件,显著降低了操作难度,提高了分析效率,为物证鉴定工作提供了更好的服务,在人类遗传学、法医遗传学等领域有重要的应用价值。
1 KPS v1.0简介
1.1 系统开发平台和运行环境
软件开发平台为Ubuntu 18.04操作系统,Python语言v3.6版本,运行环境为安装了浏览器的Windows 7及其以上操作系统。
1.2 系统设计思路
KPS v1.0亲缘关系模块主要涉及前端界面和后台计算两大部分。后台计算主要是基于Python语言将4个功能进行模块化串联设计并编程,包括输入数据格式预处理、基于Plink软件的数据二进制转换、基于KING软件的亲缘关系等级计算、亲缘关系等级与实际亲属关系的转换等。前端界面包括了批次名称录入、数据录入、数据类型选择、检测平台选择、亲缘关系结果查看等功能。具体结构如图1所示。后端部分的模块化串联设计可以降低程序的耦合度[11],简化程序设计、调试和维护等操作,前端界面易于用户使用和直观查看结果。
1.3 系统实现
1.3.1 亲缘关系预测方法

图1 亲缘关系模块流程图Fig.1 The kinship module flowchart
亲缘关系预测是通过计算全基因SNP数据的共祖片段大小判断亲缘关系的远近[12]。KPS v1.0系统主要基于KING软件计算亲缘关系等级,并根据亲缘关系等级图推导其实际亲属关系。本系统中亲缘关系分为4级,亲缘关系等级图如图2所示。亲缘关系等级判断方法:父母子女之间的亲缘关系为一级,两两个体亲缘关系等级为每个个体到共祖父母亲缘关系的加和[13]。
1.3.2 亲缘关系等级计算
当系统输入完成后,前端会将输入数据传递给后台,后台只需新建一个Celery[14]任务,并将其放置到Redis[15]任务缓冲队列末尾,此时多核CPU会同时从队列中读取任务并执行,用户提交完任务即可随时在任务列表中查看任务状态。任务处理示意图如图3所示。
每一个Celery任务都会定义一个亲缘关系计算函数,并保存该任务的输入数据。亲缘关系计算函数首先根据批次数据类型的不同调用不同的接口,并基于pandas库[16],将批次文件与相应的检测平台索引文件转化为MAP和PED格式[17]文件,接着自动调用后台脚本(集成了Plink和KING软件),基于数据预处理结果计算得到本批次亲缘关系等级对,并将其写入服务器指定文件。
1.3.3 系统输入与输出
系统输入需要用户填写新建任务的批次名,选择批次文件的数据类型和检测平台,并上传批次压缩包文件。其中检测平台有两种,对应两种SNP索引文件,每个文件保存多个SNP位点信息。数据类型也有两种:个体数据和原始数据。原始数据为个体基于某种检测平台测序直接得到的碱基对序列文本;个体数据为个体基于某种监测平台测序得到的基因型表格文件,直观展示了个体在某个SNP位点处的基因型。上传的批次压缩包文件包含多个个体的测序数据,所有测序数据格式保持一致。

图2 亲缘关系等级图Fig.2 The kinship degree tree
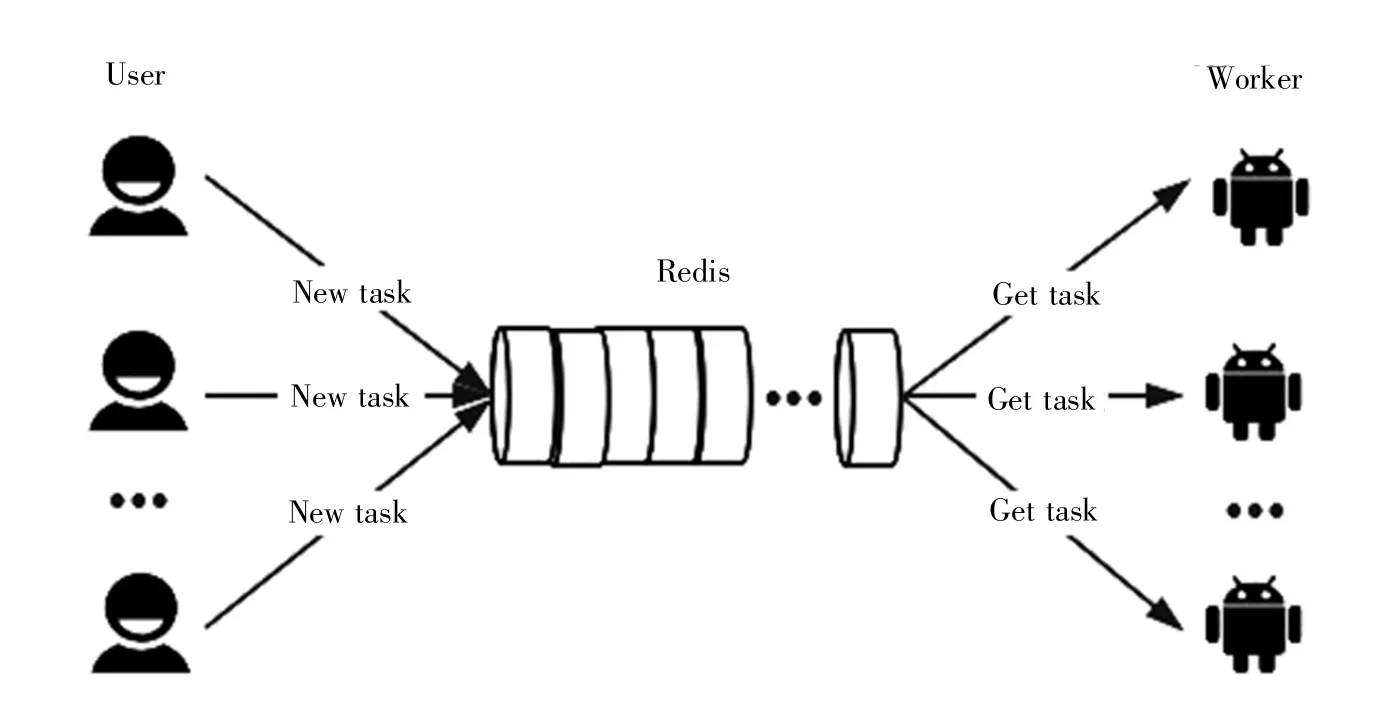
图3 任务处理示意图Fig.3 Task processing diagram
任务计算成功后,用户可在页面查看亲缘关系对列表,列表中显示批次中所有存在的亲缘关系对及其对应的亲缘关系等级,点击某一对亲缘关系,系统会自动基于亲缘关系等级图计算这对样本可能存在的实际亲属关系,并将结果绘制为家谱图供用户直观查看。
1.4 系统特点
KPS v1.0包含以下5个方面的特点:1)支持导入群体原始基因型数据;2)自动识别输入批次内样本个数,若样本个数小于2,则运行失败;3)若计算时发生异常,如用户新建任务时选错数据类型或检测平台,任务直接会显示运行失败;4)可一次性提交多个批次进行计算,自动识别电脑CPU核数,将任务自动分配到单个CPU计算,提升运算效率;5)可基于亲缘关系等级计算结果自动绘制家谱图供用户直观查看。
2 系统应用
2.1 样本来源
测试样本共计37份,来自实验室4名志愿者家系,涵盖1~4级亲缘关系。所有样本提供者均签署知情同意书且实际亲缘关系均基于样本来源者自述。
2.2 系统准确性评估
将4名志愿者家族的实际亲缘关系分别绘制家谱图,与系统预测结果进行对比,比较结果如图4所示。系统对A、B、C、D 4个志愿者家族的163对亲缘关系进行了计算,预测准确率分别为92.73%、93.94%、100%、90.48%,平均准确率达到94.29%,其中一级亲缘关系和四级亲缘关系的预测准确率均为100%。虽然将8对二级亲缘关系预测为三级亲缘关系,2对三级亲缘关系预测为四级亲缘关系,但对总预测的163对亲缘关系而言,错误率仅为6.13%,表明亲缘关系预测系统具有可观的准确性。
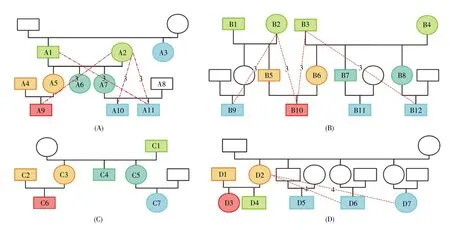
图4 实际亲缘关系与预测亲缘关系对比图(A)志愿者A;(B)志愿者B;(C)志愿者C;(D)志愿者D。图中方框和圆圈分别代表家族中的男性和女性,检测的个体已为其编号,未检测的个体未编号。不同颜色代表不同的亲缘关系等级(参考图2的亲缘关系等级图),红色标注的个体代表本人,未用颜色标注的个体为未检测的或与本人无实际亲缘关系的个体。虚线表示实际亲缘关系与系统预测亲缘关系不相符的亲缘关系对,其上面的数字代表系统预测的亲缘关系等级。Fig.4 The comparison between actual kinship and predicted kinship(A)Volunteer A;(B)Volunteer B;(C)Volunteer C;(D)Volunteer D.The boxes and circles represent the males and females,respectively.The individuals with numbers are tested,and the ones without numbers are not tested.Different colors represent different kinship degrees which are consistent with Fig.2.The individuals in red mark represent themselves,and the unmarked ones are undetected or have no actual kinship with the red-marked individual.The dotted line indicates the kinship pair whose actual kinship doesn’t match the kinship predicted by the system,and the number above it represents the kinship degree predicted by the system.

表1 系统与人工预测所需时间的比较Table 1 Time comparison between system and manual prediction
2.3 系统效率评估
在不同样本数下,对系统的计算时间和原始人工预测方法所需时间进行了统计,结果见表1。从预测所需时间来看,系统将预测效率提升了200多倍。同时由表中数据可知,系统运行时间与一个批次内的样本数和亲缘关系对数正相关,并且更易受批次内样本数的影响,因为系统需要计算所有样本的两两亲缘关系,最终输出有亲缘关系的样本对,但人工预测所用时间主要受批次内亲缘关系对数的影响,因为大多数时间主要用在最终亲缘关系结果的统计与家谱图的绘制。总之,系统的开发节省了大量人力物力资源,极大提高了亲缘关系预测的效率,为物证鉴定工作提供了更好的工具。
3 讨论
KPS v1.0是一个完整的Web系统,需要部署在服务器上,用户使用只需通过浏览器访问即可。系统支持多用户使用、人脸识别登录、个人信息管理、用户管理、任务管理及亲缘关系查看等功能。同时,系统开发完毕已打包为完整的Docker镜像,只需在服务器上安装Docker容器即可实现一键部署[18],解决了以往项目部署难的问题。目前,系统在测试完成后就部署在线上投入使用,各个功能都得到了物证鉴定部门工作人员的认可,为物证鉴定工作带来了方便,同时也极大地提高了亲缘关系预测效率,实现了系统的开发意义。
本文仅着重介绍了系统亲缘关系的预测模块。需要指出的是,KPS v1.0后台是基于Plink和KING软件计算的,系统最终计算得到的亲缘关系对与KING软件计算结果一致,目的是将以前人工预处理数据的流程和人工绘制家谱图的流程交由计算机来完成,这样不仅节省了人力物力资源,而且大大地提升了分析效率。同时,以往每台计算机每次仅执行一个批次计算,一直要等到计算完毕才可进行下一批次的计算,这样大大浪费了多核CPU的资源,而KPS v1.0使用异步任务处理机制妥善解决了这一难题,保证每台计算机可以并行处理多个批次计算,达到CPU最高利用率,用户提交完批次无需等待,不仅可随时查看批次计算状态,还可直接计算下一批次,这样使计算效率得到了质的提升,并且也方便了用户使用。
值得注意的是,目前国内对亲缘关系这一方向的研究甚少[13],而KPS v1.0的亲缘关系计算软件也大都来源于国外,在部分国内人群中的应用可能具有一定的局限性;同时,KPS v1.0系统只是针对本项目组前期采集的四大志愿者家族的37份测试样本进行了测试,结果虽然很可观,但无法直接用来推断实际案件,直接确定嫌疑人,只能作为参考,辅助物证鉴定工作。
总之,KPS v1.0使用简单,界面直观,显著降低了使用门槛,而且将多种流程实现了程序自动化,帮助物证鉴定工作人员提高了计算效率,在人类遗传学、法医遗传学中为更多研究人员/分析人员提供了方便。
猜你喜欢
作物学报(2022年2期)2022-11-06
中国生殖健康(2020年4期)2021-01-18
中华戏曲(2020年1期)2020-02-12
中国现代中药(2019年5期)2019-07-03
科海故事博览·下旬刊(2019年6期)2019-04-16
天然产物研究与开发(2018年10期)2018-11-06
中国生殖健康(2018年4期)2018-11-06
消费导刊(2018年10期)2018-08-20
广东农业科学(2017年5期)2017-08-29
童话王国·文学大师班(2017年4期)2017-07-07
