
基于深度学习的Linux远控木马检测
2020-07-17 07:35李明轩杨慧婷
计算机工程 2020年7期
李 峰,舒 斐,李明轩,王 斌,杨慧婷
(国网新疆电力有限公司 电力科学研究院,乌鲁木齐 830011)
0 概述
远控木马是一种恶意软件,攻击者可使用远控木马对目标计算机进行远程控制,访问目标主机文件系统收集信息,并利用目标主机进一步展开攻击行为。高级远控木马通常具有潜伏性和隐藏性,能够长期驻留在目标主机中,并绕过反病毒引擎查杀进行隐蔽运行而不被发现。
针对Linux平台病毒木马的检测问题,反病毒软件的常用方法主要包括静态分析和行为分析2种。静态分析的优势在于分析速度快,但检测结果容易受到代码混淆技术的影响,而行为分析会在文件执行期间收集行为信息并进行分析,其能够有效解决代码混淆问题,但往往需要消耗较长时间,在恶意行为触发之后才能判断出恶意文件。
目前,深度学习技术在图像分类和文本识别领域得到广泛应用[1-2],其通过多层神经网络结构与大量的参数调节,对样本的特征进行逐层抽取。本文结合静态分析和动态检测2种方法,提取Linux样本数据,利用深度学习算法循环神经网络(Recurrent Neural Network,RNN)训练模型,预测输入文件是否为恶意文件。将检测模型的预测结果与常见的机器学习算法,如支持向量机(Support Vector Machine,SVM)[3]、K-近邻(K-Nearest Neighbor,KNN)算法[4]、决策树(Decision Tree,DT)[5]和随机森林(Random Forest,RF)算法[6]相比较,并使用混淆矩阵来分析机器学习算法的性能。
1 相关工作
常见的病毒木马检测方法主要包括静态分析和基于行为分析的动态检测。静态分析通过提取文件特征并与已知特征库进行对比分析,从而判断该文件是否为恶意文件,其分析速度较快,但特征误报率较高,并且很难分析混淆后的文件。文献[7]使用代码特征结合深度前馈神经网络将恶意软件与安全软件进行区分,其真正率达到95.2%。然而,在使用由某个日期之前的样本数据训练出的模型来检测该日期之后的数据时,该方法的真正率下降至67.7%,表明静态分析的方法对于全新且未知的恶意软件的检测效果较差。文献[8]证明了使用静态数据训练的模型的准确率约为95%,但对经过重新打包的恶意样本检测的准确率下降至20%。
基于行为分析的动态检测方法弥补了静态分析方法的不足,其通过监控文件执行时的行为,分析其系统调用、文件操作和网络连接等行为,进而判断文件是否存在恶意行为。文献[9]使用RNN提取5 min内API调用序列特征,将其反馈给卷积神经网络(Convolutional Neural Network,CNN)以获得具有170个样本的数据集,该方法的模型评估指标AUC分值高达0.96。文献[10]采用RF算法,使用API调用和相关元数据作为训练集,其准确率和F1值分别达到97%和98%。动态检测方法在一定程度上提高了病毒木马的检测率,但其分析时间较久,具有滞后性,且在触发恶意行为后才能判断出恶意文件。
本文结合上述2种方法,利用深度学习算法RNN训练分类检测模型,并通过超参数配置来优化模型性能。
2 模型设计
本节将详细介绍检测模型的基本框架与算法结构,给出具体的样本分析方法和所选特征集,并说明超参数配置的选择方法。
2.1 整体设计
Linux远控木马检测模型的整体框架如图1所示。模型首先对样本进行静态分析和行为分析,提取相应的静态数据以及行为数据。在特征学习模块中,采用RNN算法,结合k-折交叉验证并使用随机参数空间配置超参数循环训练模型,在随机超参数中最终选择训练期间效果较优的超参数配置,最后输出模型。

图1 检测模型整体框架
2.2 样本分析
样本分析技术[11]分为3个部分:文件和元数据分析,静态分析,动态分析。
通过田野作业理解和解读民众生活文化与意义世界,是当代民俗学的学术追求之一。研究者与叙述者(被研究者)共同完成该研究过程。同时,通过学术话语的灵活运用,研究者将叙述者的生活及叙事转译成为民俗志或民族志文本。因此,民俗学的实践主体应由叙述者与研究者共同构成,亦即在民俗研究中,研究者与叙述者是互为主体的平等协商关系,是民俗志或民族志作品的共同制作人,可以说,“我们都是故事生产过程中的一个重要环节”[注]黄盈盈:《作为方法的故事社会学——从性故事的讲述看“叙述”的陷阱与可能》,《开放时代》2018年第5期。。
1)文件和元数据分析。文件和元数据分析侧重于文件本身,提取操作系统运行ELF文件时所需的字段信息。首先,过滤掉与分析无关的文件,例如共享库、核心转储损坏的文件或为其他操作系统设计的可执行文件;其次,利用获取到的文件信息来识别异常文件结构;最后,从VirusTotal中提取每个样本的AV标签并将其提供给AV类工具[12]以获取恶意软件的标准化名称。
2)静态分析。静态分析阶段包含二进制代码分析和打包检测2个部分。二进制代码分析依赖于众多自定义的IDA Pro脚本来提取多个代码指标[13],包括函数数量、环路复杂度、整体覆盖范围以及是否存在重叠指令等;打包检测将从ELF头部提取的信息与二进制代码分析相结合,以识别可能的打包程序。
3)动态分析。动态分析包含2种类型的行为分析:在仿真器中执行5 min以及常规的打包分析和解包尝试。对于仿真,采用2种类型的动态沙箱,即基于KVM的虚拟沙箱以及一组基于QEMU的仿真沙箱。对于监听,主要采用SystemTap[14]来实现内核探测器(kprobes)和用户探测器(uprobes)。在执行结束时,每个沙箱都返回一个文本文件,其中包含系统调用和用户空间函数的完整跟踪,然后立即解析此跟踪以识别沙箱的有用反馈信息。
样本分析具体流程如图2所示。

图2 样本分析具体流程
2.3 数据提取
经过样本分析后得到json文件形式的分析数据,将json文件中的数据进行清理,使用逐步回归方法检查最重要的预测变量,本文最终采用46个变量用于训练机器学习和深度学习模型,并将数据保存至csv文件中形成数据集。所选变量详细信息如表1~表4所示,其中,表1为字节部分特征变量,表2为ELF部分特征变量,表3为Funcover部分特征变量,表4为其他部分特征变量。

表1 字节部分变量描述

表2 ELF部分变量描述

表3 Funcover部分变量描述

表4 其他部分变量描述
2.4 交叉验证
为了提高检测模型的泛化能力,同时更准确地评估模型的性能,本文对数据集采用k-折交叉验证[15]方法构造训练集。k-折交叉验证指将样本数据集随机划分为k个相同大小的子集,在每次模型训练迭代过程中,按顺序选取其中的一个子集作为测试集,剩下的k-1个子集作为训练集。本文取k=10,即将数据集分为10份,每次取其中9份进行训练,根据损失函数(用来评估预测值与实际值的差距)进行优化后执行下一次迭代。
2.5 循环神经网络
典型的RNN结构如图3所示,RNN会结合每一个时刻的输入与当前模型的状态从而给出一个输出,从图3可以看出,RNN主体结构A的输入除了来自输入层的xt,还会接收前一时刻的状态,同时A的状态也会从当前步传递到下一步。
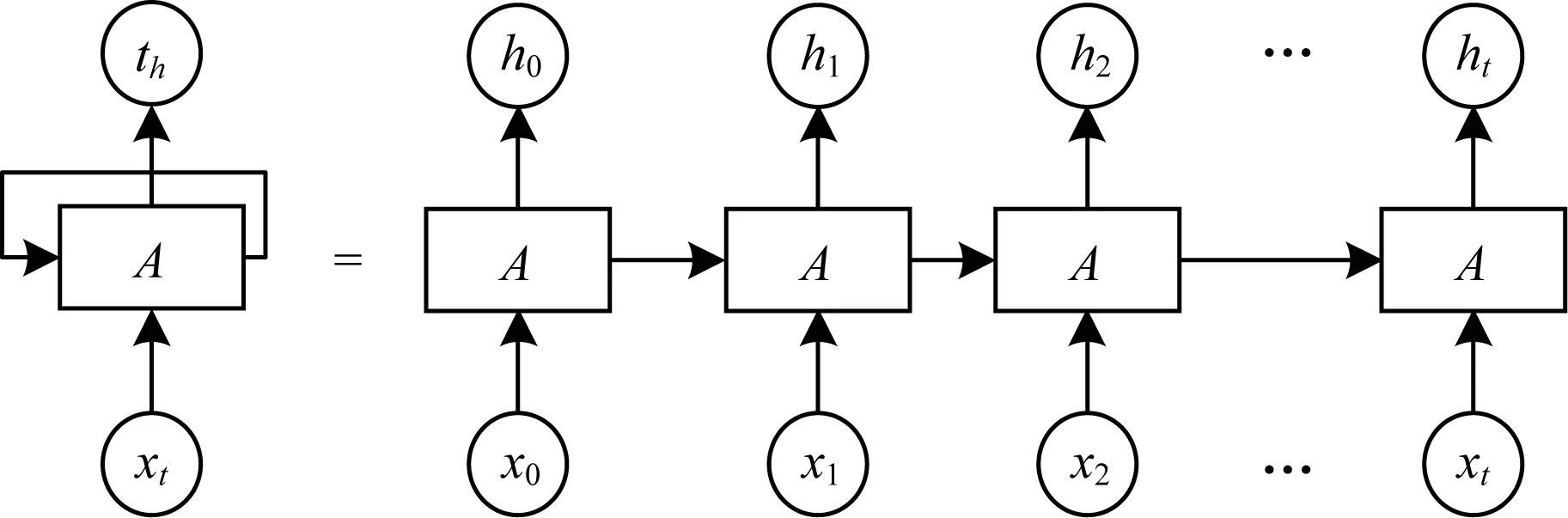
图3 RNN的典型结构
RNN能有效处理序列数据,为了深层挖掘静态数据以及行为数据前后依赖关系的特征,本文模型采用RNN中的门控循环单元(Gated Recurrent Unit,GRU)神经网络[17]。GRU通过“门”结构使信息有选择性地影响RNN中每个时刻的状态。“门”结构使用sigmoid(激活函数)的神经网络和一个按位做乘法的操作,如图4所示,GRU有更新门与重置门2个门,上述结构使得GRU神经网络能够解决序列数据中存在的长期依赖问题,且具有参数少、收敛快的优势。

图4 GRU结构
2.6 超参数配置
本文采用随机搜索参数的方法进行超参数配置,随机搜索从可能的参数组合中随机选择配置,通过使用相对权重值的字典对偏置参数进行选择。随机搜索将一直循环运行,默认选择轮数为100轮,超参数配置随机搜索空间如表5所示。

表5 超参数配置随机搜索空间表
3 实验结果与分析
3.1 数据集
本文所使用的数据集来自文献[18],该数据集从Padawan[19]多架构ELF分析在线平台中获取,并将得到的Linux样本分析数据清理成多个重要值,最终将数据保存至csv文件中。
利用Padawan平台可通过Linux样本哈希值的URL访问到json格式的分析报告,哈希值列表可在平台上获取。平台提供的数据集[11]除了包含僵尸网络中的Linux恶意攻击样本,还包含数千个属于其他类别的样本,例如远控木马、后门、勒索软件、传统文件感染、权限提升工具、Rootkit、蠕虫、APT活动中使用的RAT程序以及基于CGI的二进制文件webshells等。
文献[18]在Padawan平台上获得了10 548个json格式的样本数据,并将json文件中的数据进行清理整合,过滤NA值过大的数据,将json文件转换成csv格式的文件。在此基础上,本文将几款开源Linux远控工具生成的有效负载上传至Padawan平台中进行分析,包括Meterpreter生成编码混淆的Payload、Stitch Payload、TheFatRat Payload、Pupy Payload和PyIris Backdoor Payload等,获取其静态以及行为数据,并将数据添加到数据集中。最终数据集共包含5 518个样本,其中,3 983个是恶意样本,1 535个是安全样本。
3.2 评估指标
为了对检测模型进行分析,本文选取准确率(ACC)和F1值[20]2个评估指标,如式(1)和式(2)所示:
(1)
(2)
其中,F1值是综合考虑查准率和查全率的指标,TP是将正类预测为正类的数量,TN是将负类预测为负类的数量,FP是将负类预测为正类的数量,FN是将正类预测为负类的数量。
3.3 参数选择
本文在随机搜索空间中循环训练检测模型,随机选择100种参数配置,经过训练对比,最终选择评估指标结果最好的超参数配置,如表6所示。

表6 随机搜索空间中最优超参数配置
3.4 实验环境
本文实验计算机配置为双核8 GB内存,Intel Core i5处理器,计算机型号为Macbook Pro 2015版,操作系统为macOS 10.14.2版本。在模型搭建阶段,采用TensorFlow作为神经网络框架,python使用2.7.15版本,R语言采用3.5.3版本。在参数设置方面,使用随机搜索空间中100种超参数配置,并使用k-折交叉验证,k值取10,每种参数配置训练轮数为10轮。此外,为了提升训练速度并防止过拟合现象,模型采用dropout方法,丢弃率使用[0.1,0.2,0.3,0.4,0.5]中的随机值[21]。在随机搜索空间中选择评价指标结果最优的超参数配置重新进行模型训练,训练轮数为30轮。
3.5 结果分析
在100轮不同超参数配置的模型训练过程中,若某一轮次采用的参数配置评估指标未超过在此之前的轮次结果,则放弃此轮参数直接进行下一轮参数配置训练。最终挑选出其中最优的参数配置(表6),使用此超参数配置再次进行模型训练,ACC和F1值最高分别达到92.64%和95.20%。图5所示为本文模型在表6参数配置下的ACC值和F1值。

图5 最优超参数配置下的评估结果
为了验证RNN算法训练出的检测模型的整体性能,将RNN训练出的模型与不同的机器学习算法进行比较,其中,机器学习算法包括决策树中的CART算法、RF算法、SVM算法和KNN算法。所有机器学习算法的训练和测试数据都相同,以便准确地进行比较,采用ACC和F1值2个评价指标来对比算法,表7所示为RNN与机器学习算法的性能比较结果。
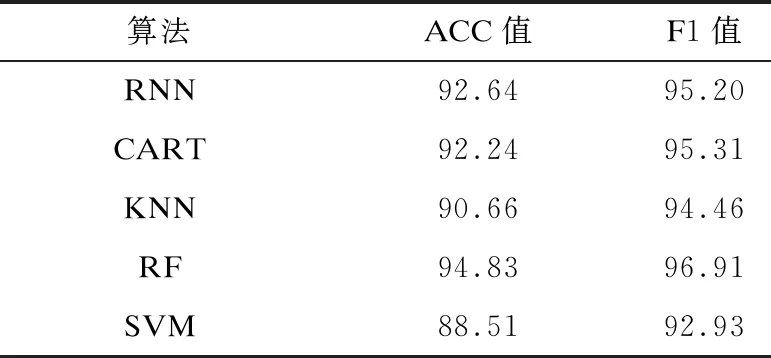
表7 RNN与机器学习算法的性能比较结果
在表7中,RNN为100种随机超参数配置中的最优选择,可以看出,其准确率和F1值略优于CART和SVM,但是整体表现不如RF算法。RNN-BP为在Linux数据集上执行更多轮次随机搜索得到的全局超参数最优配置,该配置下RNN的准确率为95.72%,F1值为97.41,相比100种随机超参数配置下的结果提高了2个~3个百分点,且检测性能优于RF算法。
4 结束语
混淆编码技术可绕过大部分反病毒系统的静态恶意软件检测,动态分析方法虽然能克服静态分析的不足,但其会耗费较多时间。本文使用Linux样本静态与动态分析中所提取的大量数据,通过深度学习算法RNN训练检测模型。该模型可以用于预测Linux恶意攻击(包括Linux远控木马、Linux后门、Rootkit等),准确率为92.64%,F1值为95.20%。下一步将针对Linux远控木马检测问题,寻找更优的深度学习神经网络结构(如LSTM等),丰富训练数据并提高模型的泛化能力,以加快训练速度并降低过拟合的可能性。
猜你喜欢
云南画报(2021年8期)2021-11-13
北京航空航天大学学报(2021年6期)2021-07-20
中学生数理化·高一版(2021年2期)2021-03-19
成都信息工程大学学报(2019年4期)2019-11-04
阅读与作文(英语初中版)(2019年8期)2019-08-27
小学生学习指导(低年级)(2018年11期)2018-12-03
知识经济·中国直销(2018年8期)2018-08-23
数学学习与研究(2017年3期)2017-03-09
现代防御技术(2016年1期)2016-06-01
中国老区建设(2016年1期)2016-02-28
