
异构文本数据转换中XML解析方法对比研究
2020-07-21 14:21何卓桁刘志勇李长明
计算机工程 2020年7期
何卓桁,刘志勇,李 璐,李长明,张 琳
(1.东北师范大学 信息科学与技术学院,长春 130024; 2.同济大学 软件学院,上海 200092;3.长春光华学院 电气信息学院,长春 130033; 4.吉林大学 软件学院,长春 130012)
0 概述
由于异构文本数据具有数据量大、形式多样且来源复杂等特点,在数据预处理工作中,存在查找有效信息困难的问题。为了对数据进行过滤并达到筛选有效信息的目的,需要对数据结构进行转换,保证数据的统一化,从而简化后续文本的处理工作。在异构文本的数据预处理工作中,异构数据的转换是不可或缺的步骤,主要分为直接转换和间接转换。直接转换是利用正则表达式对异构文本进行过滤并建立其对应结构,间接转换是将异构文本转换为半结构化的XML文本,以XML文本为桥梁转换为结构化文本[1]。间接转换已经得到了学者们的普遍认可,其转换过程主要包括2个阶段,第1阶段是通过制定转换规则将异构文本转换为XML文本,第2阶段是通过一定的解析方法将XML文本转换为结构化文本。采用XML文本作为中间转换的标准,优势在于利用XML文本的分层嵌套格式,以及在分层表示的各个元素中均包含属性和值[2],使得语义表达能力突出。另外,XML具有格式规整的特点,XML文档不需要符合特定文档类型定义(Document Type Definition,DTD)或者架构[3],这些特点使得XML文档表达的Web内容能够更好地被用户理解。因此,XML适合存储半结构化的数据。
第1阶段中转换方法的研究相对比较成熟,主要是对超文本标记语言进行去标记、分类,制定XML模板,主要研究工作包括:文献[4]利用DTD或者由一种用于描述和规范XML文档逻辑结构的语言(Schema)制定对应的规则,生成XML Schema。文献[5]通过从XML文件中提取结构信息来创建一个临时的DTD,将XML文件映射为对象数据库。文献[6]通过分析DTD和XML Schema 2种模式的不同之处,参考基于DTD的XML函数依赖的相关研究,提出XML Schema形式化定义和XML的轴元素定义,给出基于XML Schema标准的XML函数依赖定义以及其推理规则集,规范了XML文档。文献[7]通过模板建立Schema并将XML文本结构存入其中后再进行解析。文献[8]对DTD进行深入研究,并讨论XML架构受元素声明一致性(Element Declaration Consistency,EDC)规则的影响。文献[9]针对Web日志中的元素存在属性和值,利用XML文本自身的分层结构与其相关联的优势,使得Web日志内容能够更好地被表达。第2阶段的解析方法主要有DOM、SAX、JDOM和DOM4J等4种,然而这4种方法在什么情况下才会更加有效,目前还缺乏科学的实验论证,尚未形成统一的结论。
综上所述,XML文本在异构文本数据转换过程中起到了至关重要的作用,重点关注在异构数据转换过程的第2阶段,即将XML文本通过解析方法转换为结构化数据。本文结合方法组合的思想,采用多组实验进行比较[10],在同一实验环境下,保证限定条件的统一,以多角度的方式对DOM、SAX、JDOM和DOM4J解析方法进行研究。相较于以往的对比研究[11],本文引入内存占用空间、CPU占用率和解析时间作为评价指标,相比单一的以效率为评价指标的方法,本文的评价指标方法更为全面、客观和准确。以加权和的方式考虑不同指标的影响因素,使解析方法之间的区分度增大,结果更加直观。同时,在统一评价指标上设置多组实验,对4种解析方法在不同的价值取向下,验证其解析方法的优劣性,为后续研究者针对不同的研究目的提供更加直观切实的研究方法。
1 解析方法
以XML为介质,采用4种目前主流的解析方法DOM、SAX、JDOM和DOM4J对数据进行转换。其中,DOM是目前解析XML文本的基础解析方法,通过树形结构存储,该方法与XML存储方法吻合,使用户能够更好地理解。SAX采用流处理方式,占用内存少,适用于处理文本量大的工作。JDOM结合了DOM与SAX的优点,基于树形结构,提供更加简单的逻辑访问方法。DOM4J是JDOM的一种智能分支,它合并了包括集成XPath支持、XML Schema支持以及用于长文档或流化式文档的基于事件处理的功能。
1.1 DOM解析方法
DOM解析方法是将XML文本转换为对象模型,运用树结构对信息进行存储,通过接口的方式进行访问且可以访问任意节点[12]。关于DOM解析方法的研究,文献[13]利用DOM树中的文本内容和层次结构对Web中的菜单和导航指示器的关键信息进行提取,通过在目标网页中点选元素的方式,自动生成基于DOM路径的抽取模板,从而达到解析并提取信息的目的。文献[14]针对本地存储结构化数据的XML文档,设计一个基于DOM树的轻量级文档解析库。但上述方法也存在一定的缺陷,如将文本转换为树结构时,若需要转换的文件较大,则对树结构的遍历十分耗时,将导致整个解析过程十分缓慢。
1.2 SAX解析方法
SAX解析方法是以时间为驱动的API,采用类似流处理的方式在进行扫描文本的同时自顶向下依次完成解析任务[15]。在解析XML过程中,SAX占用的内存少且速度快。关于SAX解析方法的研究,文献[16]提出基于SAX解析过程,利用列表以及关系指针2种方法相接合的方式来处理XPath查询的QXSList方法,通过层次值计算判断节点的结构关系,利用关系指针链接多个候选节点列表来获取查询结果。虽然SAX在处理关系层次较多以及文本数据量大的情况下表现优异,但是也存在SAX无法随机访问XML节点,也无法对XML文本进行修改,只能对文本进行读取任务的缺点。
1.3 JDOM解析方法
JDOM解析方法是基于树形结构,内置Xerces解析器,使用具体类的文档解析模型,运用树结构对信息进行存储,它所包含的转换器将JDOM表示输出成SAX事件流、DOM模型[17]。关于JDOM解析方法的研究,文献[18]利用其解析XML和Schema文件,完成了异构数据的转换,该解析方法简化了异构数据转换的流程,并且保证了关系数据信息的完整性,但是这需要用户充分地理解XML文本,说明JDOM解析方法缺乏一定的灵活性。
1.4 DOM4J解析方法
DOM4J解析方法是JDOM的分支,集成了DOM和SAX的XML文件解析器,提供大量接口用于对XML文件进行处理,且DOM4J API和标准DOM接口具有并行访问功能[19]。关于DOM4J的研究,文献[20]以XML文本作为数据库存储学生信息,利用DOM4J树结构进行解析,结果表明,其解析时间较DOM解析方法短,这说明DOM4J在理论上较DOM表现良好。
通过对大量文献进行分析,结果发现,间接转换过程中的主要问题在于对目前主流的4种解析方法的优劣存在矛盾的结论。在各自领域中,运用不同的解析方法均能达到其预期效果,并不能体现出解析方法的优劣。因此需要在相同条件下进行比较并通过实验证明目前主流的4种解析方法的优劣。
2 算法分析
在相同条件下,实验利用4种解析方法对相同的数据集进行解析,其解析机制是根据文档内容对其节点和元素进行读取并输出,解析的质量以消耗的时间和空间为评价指标,处理结果的正确性取决于程序是否能够运行至结束。在实验过程中,数据集的数据量和属性个数在理论上对实验结果的精度没有影响,在算法分析过程中主要以解析方法的时间开销来对算法的优劣性进行区分。
4种解析方法的时间开销是实验中对文档进行解析所需要的时间,在本节中主要针对解析文档时处理耗费的运行时间复杂度进行理论计算。其中,对代码的运行次数记为n,每行代码的时间开销记为Cx,x代表程序对应的行,以下是4种解析方法的运行时间复杂度的分析。
DOM解析方法的运行时间复杂度如表1所示,由此可知,由于C8远远大于C1~C7,因此T(n)=C8n3=O(n3)。

表1 DOM解析方法的运行时间复杂度
SAX解析方法的运行时间复杂度如表2所示,由此可知,由于C3远大于C1~C2,因此T(n)=C3n=O(n)。

表2 SAX解析方法的运行时间复杂度
JDOM解析方法的运行时间复杂度如表3所示,由表3可知,由于C6远大于C1~C5,因此T(n)=C6n2=O(n2)。

表3 JDOM解析方法的运行时间复杂度
DOM4J解析方法的运行时间复杂度如表4所示,由此可知,由于C6远大于C1~C5,因此T(n)=C6n2=O(n2)。

表4 DOM4J解析方法的运行时间复杂度
根据以上4种解析方法运行时间复杂度的分析可知,SAX解析方法的运行时间复杂度相比其他3种解析方法都较小,且DOM解析方法的运行时间复杂度最大。这是因为SAX解析方法采用的是流式处理文件的方法,即用即停,不需要将XML文本存入内存中,理论上适合用于数据量较大的情况。DOM、JDOM以及DOM4J解析方法均需要建立根节点,DOM4J区别于DOM主要是因为对应接口不同,其采用了SAXREADER,因此虽然时间复杂度相同,但是实际开销比DOM小很多,而JDOM是DOM方法在JAVA语言中的API,因此时间开销也比DOM4J大,由此可得出4种解析方法的理论时间开销由大到小排序为CDOM>CJDOM>CDOM4J>CSAX。
3 评价指标
以解析时间与XML文本大小的比值作为效率,目前公认的评价指标是以效率的高低对实验结果进行判定。文献[21]利用解析时间为研究重点,在相同大小的文件下对DOM、SAX解析方法进行比较,得出SAX解析方法比DOM解析方法效率高的结论,但存在SAX解析方法在价值取向上过于单一的缺点。
由于解析时间和XML文本大成正比例关系,对结果的评价区分度不大。针对该问题,本文以解析时间t(ms)、内存堆占用空间d(MB)、CPU占用率c作为评价指标,将时间和空间2个维度划分为分母和分子表示,并分别进行加权,加权和记为T、M。时间加权值指影响值I在时间维度上的加权值,记作β,表示为分子的加权值;空间加权值指对影响值I在空间维度上的加权值,记作α,表示为分母的加权值。为了数据的归一化,将α和β的取值范围设定在0~1之间,并且控制α和β成反比例关系,使结果受正比例关系的影响减小。影响值I的计算方法如下:
I(影响值)=(c×100+d)×α/(t×β)
(1)
β(时间加权值)=1-α(空间加权值)
(2)
在式(1)中,将影响值I作为解析方法优劣的判定依据,主要分为以下3种情况:
1)当时间加权值β和空间加权值α比重一样时,影响值I作为直接影响值。


当不考虑时间和空间为价值取向时,影响值I越小,则解析方法越差;当以缩短解析时间为重点时,对堆内存容量和CPU占用率的要求高,同时对处理时间的缩减要求也高,因此此时影响值I值越小,则该解析方法在此条件下越差;相反,以占用空间为重点时,则对堆内存容量和CPU占用率要求低,对处理时间缩减的要求也降低,此时影响值I越大,则该解析方法越差。以空间占用为重点(缩短解析时间为重点)时,影响值I越大,解析方法越好;以解析时间为重点(占用堆内存空间为重点)时,影响值I越小,解析方法越好。在空间和时间加权和确定情况下,加权值分配对影响值的影响如图1所示。
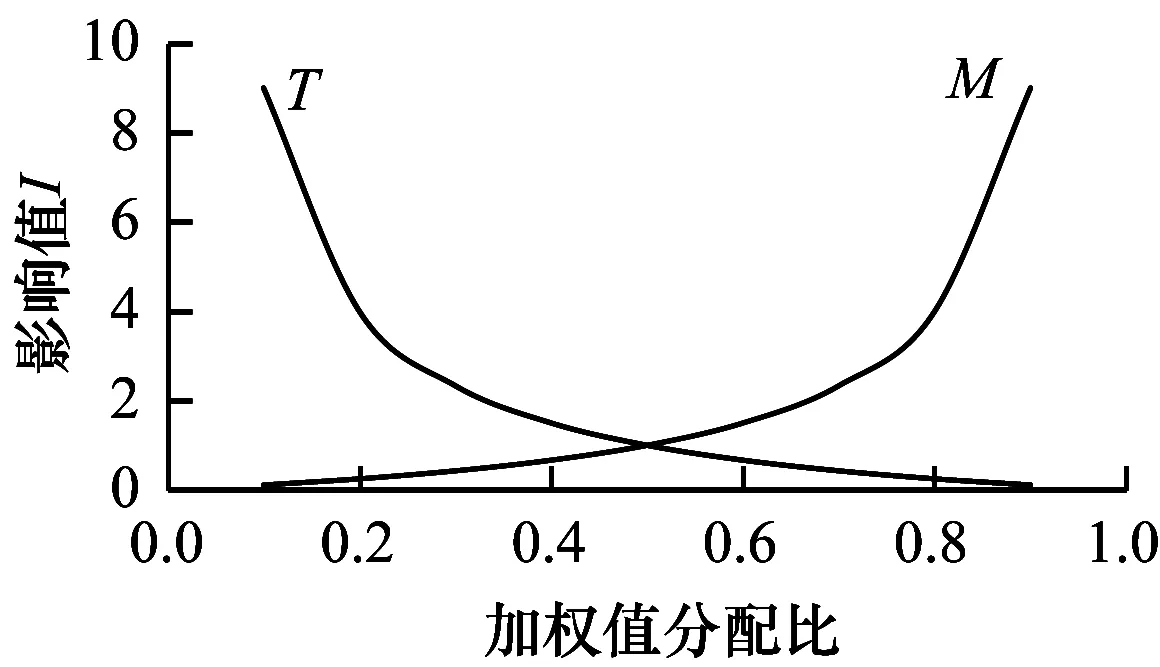
图1 加权值分配比对影响值I的影响
采用上述评价方法具有以下优点:
1)将各个方法采用量值的方式进行比对,尤其在数据量不大以及属性个数不多的情况下,能够将解析方法对异构文本数据的转换结果影响程度划分,评价指标以时间和空间划分的方式更加合理,且计算简单。
2)随着数据量增大,不同解析方法的影响值差I值增大,区分更加明显。
4 实验与结果分析
4.1 数据集
本文实验数据采用八爪鱼V8.0爬虫软件抓取电子商务网站用户ID、名称、登陆地等基本用户标识及行为的日志信息,并利用.txt文件对信息进行存储,在Eclipse环境下将.txt信息转换成XML文件,从而获得Web日志中XML文件资源,该资源主要记录用户访问浏览网站的信息,且具有数据量大、属性简单明确的特点,数据总量为2 207 620条,数据属性总共有7个。采用梯度划分法将数据分为6个梯度数据量的数据集,并根据属性个数不同增加4个不同属性个数的数据集,总共10份数据并按编号1~10进行排列,数据集信息数量(条)的变化范围为14 620~731 000,属性个数(个)变化范围为5~7,命名方式采用“Test_数据量_属性个数”,具体如表5所示。其中,编号8用于实验1、实验4和实验5,编号1、4、5、6、7、8用于实验2,编号1~编号3和编号8~编号10用于实验3。

表5 数据集的具体参数
根据DTD[22]规则,XML文本的具体参数如表6所示。

表6 XML文本的具体参数
4.2 实验环境
系统环境为64位Win 10操作系统,8GB内存,Intel(R)Core(TM)i7@2.40GHZ。程序语言为Java8.0,XML。实验工具为Eclipse Java 4.9.0,Navicat10.7。数据库为Mysql5.6.41。
4.3 实验过程
首先,进行“参数确定”的实验,其次,分别进行数据量、属性个数发生变化情况下的对比实验,以此确定其影响大小,最后,从占用空间和缩短时间角度分别进行实验,完成4种解析方法的对比。为了减少随机数据集带来的误差,所有实验均重复进行10次,并将所得的平均值作为最终结果。
4.3.1 参数确定
为了选取合理的时间和空间加权值,将10份异构数据分别转换为XML文本的半结构化数据,每份数据均采用4种解析方法对其解析并计算影响值I。实验通过区间分配权值的方法,取各种解析方法在6种不同数据量情况下影响值I的算数平均值,然后分别在5个不同区间下进行计算,对比在不同的α和β组合情况下,影响值I的变化范围,实验结果如图2~图4所示。由图2可知,以时间占用为重点,0.8≤β≤0.9时,影响值I的变化情况最为明显。由图3可知,以空间占用为重点,0.8≤α≤0.9时,影响值I的变化情况最为明显。由图4可知,以数据量较大的Test_70w_6数据集为例,随着权值比例的降低,时间与空间之间的影响值I差值越来越小。根据文件大小及解析时间的差值分析,权重过大会导致结果不稳定。

图2 以时间占用为重点时的影响值I

图3 以空间占用为重点时的影响值I

图4 在数据集Test_70w_6上影响值I的变化
经过多次比对,以空间为重点时,本文选取α=0.85,β=0.15进行后续实验,以时间为重点时,本文选取α=0.15,β=0.85进行后续实验。
4.3.2 数据量对解析方法的影响
当数据量n从1.4万条逐渐变化至70万条时,在不考虑时间以及空间关系的情况下,实验比较了4种解析方法的影响值I,结果如图5、图6所示,图6为图5中影响值I的局部放大。

图5 4种解析方法在数据集Test_1.4w_6~Test_70w_6下的影响值I

图6 4种解析方法在数据集Test_28w_6 ~ Test_70w_6下的影响值I
从图5和图6可得出以下结论:
1)随着数据量n的增大,4种解析方法所花费的时间均增加,并且数据量n越大,4种解析方法的差距越小,因此本文主要针对数据量n增大的情况进行后续实验。
2)当数据量n低于35万条时,DOM解析方法的影响值I比DOM4J解析方法高,数据量继续增大至高于35万条时,DOM4J解析方法的影响值I逐渐高于DOM解析方法,且始终比DOM解析方法的影响值I高。在时间和空间加权值比重相同时,DOM4J解析方法在35万条~70万条数据量时最优。
3)在数据集Test_42w_6与Test_56w_6之间,SAX解析方法的影响值I逐渐高于JDOM解析方法,且与DOM4J、DOM解析方法的差值逐渐缩小,当时间和空间加权值比重相同时,SAX解析方法可能会随着数据量n的增大,影响值I逐渐升高。
实验结果表明,时间和空间加权值分配一致即不考虑时间空间影响时,当数据量n较小时,DOM解析方法具有很高的效率,继续增大数据量n时,该解析方法的效率反而降低,这是因为DOM解析方法采用的是树节点遍历全文的方式对文档解析,当数据量n较大时,建立树节点的时间会大幅增加,会造成效率变差,影响值I降低。
当数据量n较小时,从影响值I大小的角度分析,SAX解析方法的时间占用相对空间占用比其他3种解析方法多,且效果最差,当数据量n增大时,效率逐渐升高,且幅度较大。这是因为SAX解析方法采用的是流式处理文件的方式,逐行解析可以随时停止,不耗费空间资源,因此当数据量n增大时,影响值I会相对其他解析方法升高。
JDOM解析方法的影响值I随着数据量n的增大呈降低趋势,这是因为当数据量n增大时,在空间资源相差不大的情况下,JDOM解析方法耗费的时间远大于其他3种解析方法。
DOM4J解析方法的影响值I随着数据量n的增大呈升高趋势,这是因为虽然DOM4J解析方法采用获取根节点的方式遍历其子节点和属性,但是处理过程中可以根据接口选择SAX读取器,因此相对其他3种解析方法,其处理方式更快。
4.3.3 属性个数对解析方法的影响
实验对算法的时间复杂度进行分析,为了比较属性个数对解析结果的影响程度,在不考虑空间的影响因素下,以分子不变的影响值I作为判定依据。本文实验利用Test_1.4w_6和Test_70w_6数据集对属性加减,得到Test_1.4w_7、Test_1.4w_5、Test_70w_7和Test_70w_5这4个不同属性个数的数据集,比较6个数据集的影响值I,实验结果如图7和图8所示。
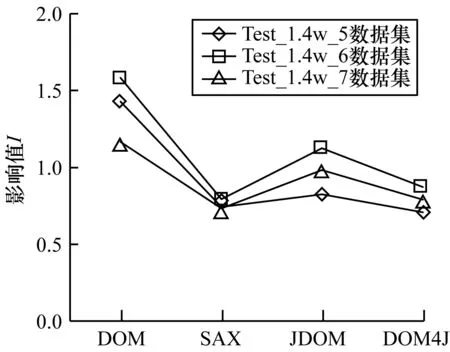
图7 4种解析方法在数据集Test_1.4w_6中的影响值I

图8 4种解析方法在数据集Test_70w_6中的影响值I
从图7和图8可以得出以下结论:
1)在数据集Test_1.4w_6属性加减后的3个数据集上,当属性个数减少时,DOM解析方法的影响值I比原数据集小;当属性个数增大或者减少时,JDOM和DOM4J解析方法的影响值都比原数据集小。
2)在6个数据集上,属性个数的增加或者减少对SAX解析方法的影响值I影响不大,且影响值差值均低于其他3种解析方法。
3)在Test_70w_6属性加减后的3个数据集上,4种解析方法的影响值I变化情况基本一致,当属性个数减少时,4种解析方法的影响值I最高,而当属性个数增加时,4种解析方法的影响值I最低。
实验结果表明,当数据量n不大时,属性个数的变化对结果的影响是非稳定性因素;当数据量n增大时,属性的变化对结果的影响是稳定性因素。因为在数据量n较小时,无论是解析空间还是解析时间,受实验环境的影响,限制条件被忽略,干扰性增强,当数据量n增大后,实验环境的影响对处理事件所耗费的时间干扰性减弱。由此表明,在不考虑时间和空间为重点并且数据量n较大的条件下,当属性个数增加时,影响值I降低,当属性个数减少时,影响值I升高。
4.3.4 缩短时间为重点时不同解析方法对比
本文实验将以α=0.15,β=0.85分别赋予空间和时间加权值。当考虑缩短时间为重点时,在数据集Test_70w_6上,对比4种解析方法影响值I的变化情况,并表示出该权重比与权重比为1时的差值,此差值表示为函数以时间为重点价值取向时的突出程度,结果如图9和图10所示。

图9 在数据集Test_70w_6中以时间为重点的4种解析方法的比较

图10 4种解析方法的权重比差值比较
从图9和图10可以得出以下结论:
1)DOM和DOM4J解析方法在该条件下的影响值I均比JDOM和SAX解析方法高,且在10组实验中,DOM4J解析方法的平均值大于DOM解析方法,说明以时间为重点时,DOM4J解析方法的解析效果最好。
2)在差值对比分析过程中,JDOM解析方法的差值最高(-0.017 67),说明在缩短数据解析时间上,JDOM解析方法的时间开销最大。
实验结果表明,DOM4J解析方法适用于以缩短解析时间为重点的实验环境。在实际的XML文本解析中,在实验条件较好且数据量n较大的情况下,DOM4J解析方法的性价比最高,且实用性很强。
4.3.5 占用空间为重点时不同解析方法对比
本实验将以α=0.85,β=0.15分别赋予空间和时间加权值。在考虑占用空间重点时,同样在数据集Test_70w_6上,对比4种解析方法影响值I的变化情况,并表示出该权重比与权重比为1时的差值,此差值为函数以空间为重点时的突出程度。由于DOM4J和JDOM解析方法均是根据DOM解析方法中的数据存储方式来构建根节点树,需要把文档存至内存中,因此以空间为重点价值取向时,主要比较了DOM树结构和SAX流式处理文件结构,实验结果如图11所示。

图11 以空间为重点时的SAX和DOM解析方法的比较
从图11可以得出以下结论:
1)以占用空间为重点时,以DOM解析方法的树形结构方式空间占用比大于用SAX解析方法的流式处理文件结构,且在数据量n为70万条时,平均堆内存空间占用差值为126 MB。
2)以树结构的存储数据的方式堆空间占用是流式文件处理方式的堆空间占用的1.52倍。
实验结果表明,当数据量n增大时,若考虑以空间占用为重点的实验环境,则采用SAX解析方法效果最好。
5 结束语
针对异构文本数据转换中,DOM、SAX、JDOM、DOM4J解析方法在不同情况下选择哪种方法更加有效,还存在缺乏科学实验论证的问题,本文提出对异构文本数据转换中XML解析方法进行对比研究,以3种不同评价指标来判定4种解析方法的优劣,得出了以解析时间为重点价值取向时,采用DOM4J解析方法最优,以空间占用为重点价值取向时,采用SAX解析方法最优的结论。但是本文也存在不足之处,如在进行不同梯度数据量的实验时,未针对数据量极大的情况进行实验,同时在CPU利用和空间占用的硬件利用问题上,也未尝试负载运行实验。在下一步研究中,拟选取数据量在100万条~500万条的XML数据集,调整数据梯度的纵向深度,对比观察数据量梯度变化与影响值的比例关系,推算解析算法的极限算力。而对于实验环境的硬件选择,拟采用集群式机群,采用分布式原理调整实验过程中的最大吞吐量,尝试负载运行机器,对比观察数据的处理时长,以期能够利用数据结果直观说明解析方法的内部处理方式。
猜你喜欢
云南教育·小学教师(2022年4期)2022-05-17
中学生数理化·高一版(2021年4期)2021-07-19
北京大学学报(自然科学版)(2021年3期)2021-07-16
电脑爱好者(2020年19期)2020-10-20
艺术评论(2020年3期)2020-02-06
电子制作(2019年13期)2020-01-14
制造技术与机床(2019年10期)2019-10-26
电子制作(2018年18期)2018-11-14
语文世界(小学版)(2018年3期)2018-03-22
商周刊(2017年12期)2017-06-22
