
基于用户属性偏好与时间因子的服装推荐研究
2020-07-24 02:11周静何利力
软件导刊 2020年6期
周静 何利力


摘要:针对服装推荐方法推荐精度不高、覆盖率低,不能充分挖掘用户潜在兴趣的问题,提出一种基于用户图像内容属性偏好与时间因子的服装推荐(UIACF)算法。通过构建深度卷积神经网络,提取服装图像中的服装属性,并据此形成用户属性向量,将基于用户属性偏好的相似度与基于时间因子的用户兴趣偏好相似度融合,构建用户偏好模型。将其与基于用户的协同过滤(UCF)算法、基于项目的协同过滤(ICF)算法及基于项目偏好的协同过滤(UCSVD)算法进行比较,结果显示,UIACF算法准确率提高14%。该算法为基于用户的服装协同过滤个性化推荐提供了一种新思路,用户潜在兴趣挖掘效率更高。
关键词:图像分类;用户偏好;协同过滤;服装推荐;时间因子
DOI:10.11907/rjdk.192085开放科学(资源服务)标识码(OSID):
中图分类号:TP301文献标识码:A 文章编号:1672-7800(2020)006-0023-06
0 引言
随着网络的普及,全民网上购物的电子商务时代已然到来。淘宝、京东等电子商务平台提供越来越多的服装选择,但是信息超载问题也随之而来。现有搜索技术无法满足消费者服装个性化需求。因此既能解决信息超载问题又能提供个性化服务的个性化推荐技术,引起了相关研究者关注。Lin等在既有研究的基础上,提出一种基于用户需求偏好因素之外的需求因素的用户模型;王安琪等结合服装搭配的四季色彩理论与计算机视觉技术,提出一种判断优化模型,但是没有考虑用户之间的关系;周捷等将灰色关联分析法和主观赋权、客观赋权相结合,实现了服装型号准确推荐,但是应用场景比较单一;杨天祺等利用深度学习进行服装图片识别和搭配推荐,但忽略了用户历史偏好,仅考虑了数据库中的搭配。
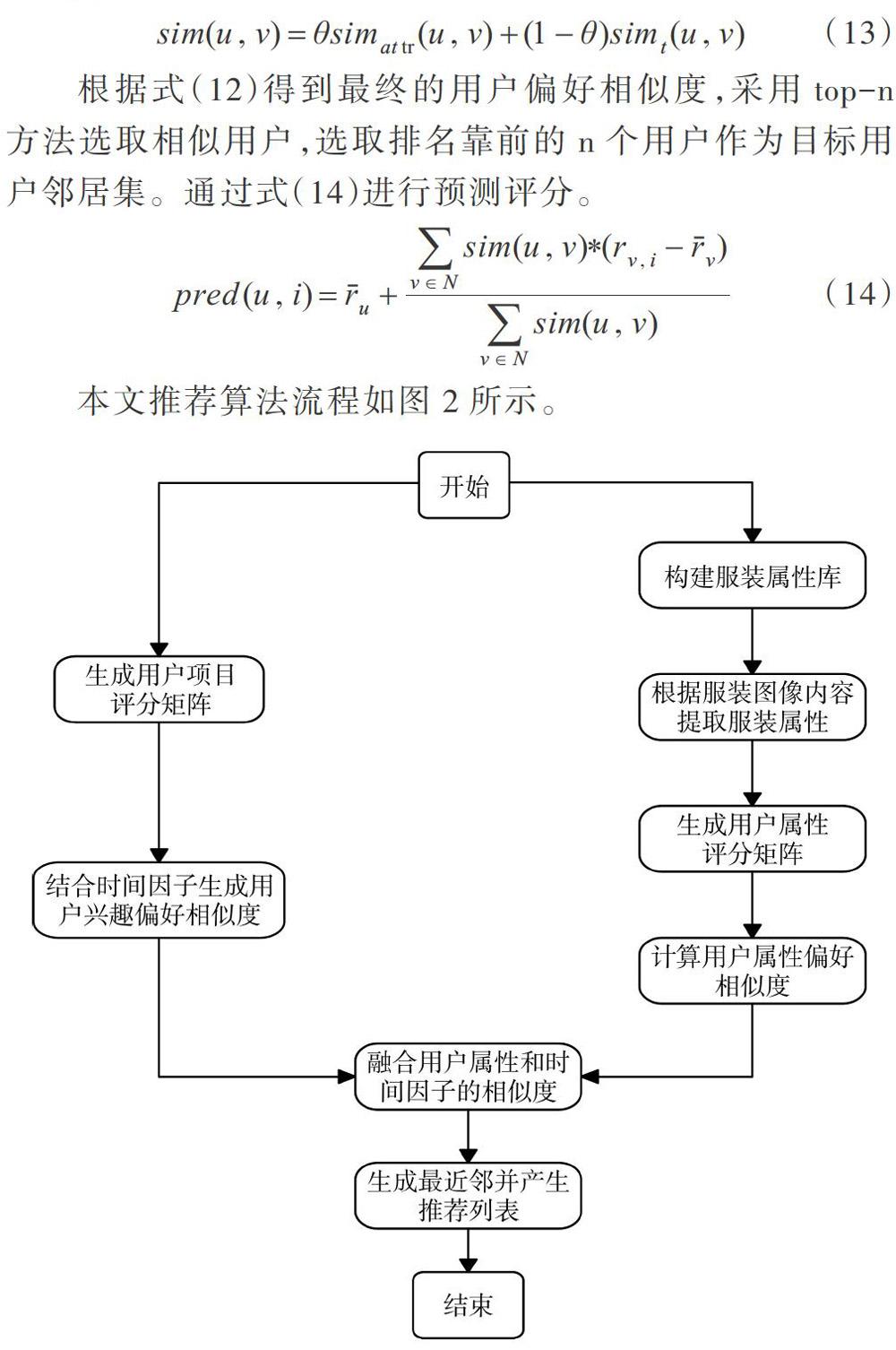
本文在已有研究的基础上,对传统基于用户的协同过滤算法进行改进,将服装图像属性内容与时间因子相结合,提出一种改进的基于用户偏好的服装个性化推荐技术。首先进行基于服装图像内容的属性识别,由于服装属性特殊性,加入三元组网络以满足细粒度识别属性的要求;其次,建立用户服装属性向量,根据用户评分服装与服装属性包含关系,构建用户关于服装图像内容的属性偏好,并计算基于用户属性偏好的用户相似度;然后,融合关于时间因子的兴趣度变化,构建最终的用户偏好模型,实现服装推荐;最后,将本文UIACF算法与传统基于用户的协同过滤(UCF)算法、基于项目的协同过滤(ICF)算法以及基于项目偏好的协同过滤(UCSVD)算法在准确度和挖掘用户兴趣度两个方面进行比较,验证算法有效性。
1 相关工作
1.1 基于用户的协同过滤个性化推荐
经过几十年的研究和发展,个性化推荐方法系统积累了多种不同类型、各具特点的推荐算法。个性化推荐方法主要包括基于内容的推荐方法、基于协同过滤的推荐方法、混合推荐方法、基于知识的推荐方法、基于数据挖掘的推荐方法以及基于人口统计学的推荐方法等。由于基于协同过滤的个性化推荐算法考虑了所有用户和物品的交互信息,且更偏向于挖掘用户潜在需求,所以基于协同过滤的推荐算法应用广泛,其主要思想是根据与相似的邻居对项目历史行为的评分情况,预测目标用户对项目的态度。比较成熟的应用包括预测电影、日用消费品和电子类等方面,服装推荐系统有其特殊性,目前并不成熟,仍处于探索阶段,面临诸多挑战。
基于用户近邻的协同过滤算法主要思想是通过寻找与目标用户相近的用户,并利用近邻用户评分信息进行推荐。基于用户近邻的协同过滤算法的目标是寻找到与目标用户偏好相近的用户,即近邻用户。
用户相似度计算主要采用3种方式,分别是余弦相似度、修正余弦相似度和皮尔逊相关相似度。实际生活中用户有不同的评分标准,因此一般采用基于皮尔逊相似度的用户相似性,如式(1)所示。
其中sim(u,v)表示用户u、v相似性,S表示用户u、v共同评分项目集合,ru,i、rv,i表示用户u、v对项目i的评分,ru和rv表示用户u、用户v对各自评分项目的平均评分。
其次是近邻选择,近邻选择会对最终推荐结果产生很大影响,为了不影响推荐效率和推荐结果准确性,通常采用K近邻和闽值过滤。K近邻指选取前k个最相似的近邻用户,阈值过滤则设置了一个固定阈值,选择相似度大于该值的近邻用户。
最后利用确定的近邻用户预测目标用户对物品的评分。常用预测方法是均值中心化。该方法主要考虑用户的不同评分标准,通过评分均值与评分偏移两种方式消除用户因为评分标准造成的偏差,如式(2)所示。
1.2 服装图像属性分类
传统服装属性分類是基于文本分类,利用中文自然语言处理技术并根据商家提供的文本描述提取服装属性,一般包括中文分词(CWS)和停用词去除两个部分。中文分词任务是将一系列的句子划分成一个个词语,停用词去除指去除没有实际意义但又出现次数很多的词语。但是,服装电子商城中的文字描述往往仅包含一部分属性,而且文字描述一般受主观影响,无法完整准确地表达多元化服装图像内容。因此基于图像内容的服装属性分类被提出。
近年来深度学习在计算机视觉领域取得了突破性进展,卷积神经网络(Convolutional Neural Network,CNN)成为图像领域研究热点,在目标检测、图像分类及图像检索等任务中表现优异,所以本文选用卷积神经网络提取服装图像属性分类。卷积神经网络是一种端到端的网络结构,主要由输入层、卷积层、池化层和全连接层组成,优点是局部区域感知与权值共享,常用深度模型有VGG-NET、GooZle-Net和ResNet等。卷积层输人为:
其中,a(l)是第一层卷积核,b(l)为偏置,式(4)中G(·)为激活函数,使用激活函数以避免梯度消失。
池化层主要用于降低特征维数,最大池化和平均池化是较常用的两种方式,全卷积层用于输出。
2 模型构建
面对服装电子商务网站上大量的服装图片信息,用户往往难以选择,如果服装图片内容能够吸引用户注意力,则用户购买可能性也会增大,销量将随之提升。因此,服装图片中的服装属性对用户的影响非常重要。同时,用户对服装的兴趣并不是一成不变的,受季节、潮流改变购物兴趣的行为十分常见,所以本文分别对基于用户服装图像内容属性偏好与基于时间因子的用户兴趣偏好进行研究,最后将两者融合。
2.1 基于图像内容的服装属性提取
卷积神经网络通常处理单任务,但由于本文需要提取服装图像多种分类下的不同属性,且某些属性之间存在关联性,比如风格与颜色、材质有关,如果分解为多个单分类下的属性进行提取,不但会忽略各个分类之间的相关性,而且会增加网络训练复杂度,所以本文采用多任务学习的服装图像属性提取。多任务学習可相互影响,一个任务可以利用另外一个任务的信息得到优化,从而提高整个模型精确性。
结合多任务学习的卷积神经网络模型,其详细结构如图l所示。服装图像多属性分类任务共享浅层卷积网络和权值参数,全连接层连接各子任务的全连接层和分类器。
由于服装包含如扣型、拉链等诸多细节,其图像具有特殊性,需考虑服装细节位置,由于一些属性特征可能是服装边缘信息决定的,所以为了更好利用服装边缘信息,本文在卷积层之间引入特征金字塔。卷积神经网络低层特征一般是高维特征,高层特征是低维特征。为了使特征维度统一,本文采用反卷积方法,将后一层卷积层进行反卷积操作,使前后两层特征和依次往前叠加,生成整张图片的最终特征表示。
另一方面为了学习到细粒度的服装图像属性分类,实现服装属性精细分类,本文结合Triplet Loss和Softmaxloss两种损失函数以实现细粒度分类。Triplet Loss三元组损失函数需要输入3个样本构成三元组,分别是参考样本(AnchorSample)、正样本(Positive Sample)和负样本(Negative Sample)。Triplet Loss损失函数的目标是使AnchorSample和Positive Sample之间的距离最小,使NegativeSample之间的距离最大。本文Triplet Loss损失函数公式定义为:
其中,p表示样本图像,q+表示正样本图像,q-表示负样本图像,d(p,q+)表示样本和正样本间的欧式距离,d(p,g-)表示样本和负样本间的欧式距离,T表示特定阈值。
结合Softmax损失函数之后,整个网络损失函数表示如式(6)所示。
L=λLtriplet+(1-λ)Lsoftmax(6)
其中Ltriplet表示triplet学习相关损失,Lsoftmax表示Soflmax分类相关损失,又表示比例。
2.2 用户属性偏好模型构建
根据基于图像内容的服装属性分类算法得到服装图像的属性值,将服装测试库中的服装进行编号,每件服装以向量的形式展现,如式(7)所示。
Kn=(x1,x2,x3,x4,x5,…,xi) (7)
其中n表示第n件衣服,xi表示第i个属性。如果某服装商品包含某一服装属性,则设置为1,否则设置为0,由此得到所有服装商品向量表示集合。
本文结合用户对服装商品的评分及服装具有的属性信息,构建每个用户的用户一属性矩阵。表1展示了部分用户一服装评分矩阵。表2展示了服装一属性包含矩阵。
表1、表2显示了不同用户对不同服装的评分和被评价的服装是否包含某一属性,表2中0表示包含该属性,1表示没有该属性。根据上述关系,用户对属性的偏好程度为:
ru,p表示用户u对属性p的偏好程度,Ip表示用户u的评分商品中包含属性p的集合,ip表示项目是否包含属性p,包含为1,不包含为0。得到用户属性的偏好值后,根据式(9)可以计算出用户间的相似度。
2.3 基于时间因子的用户兴趣模型构建
兴趣会随时间发生变化,因此本文使用logistic权重函数作为时间因子函数,对评分实现加权,降低时间过久的数据评分权重,增加近期数据评分权重,logistic权重函数为:
tu,i表示用户u项目i的评分时间和用户u第一次对项目i评分的时间之差。Logistic权重函数随着tu,i的增大而增大。加入时间权重后,用户平均评分为:
2.4 融合用户属性偏好与时间因子的模型构建
将基于时间因子的用户兴趣相似度与基于服装图像内容用户属性偏好的相似度融合在一起。通过参数θ进行加权,θ的取值根据实际情况发生变化,融合后的相似度表达式为:
sim(u,v)=θsimattr(u,v)+(1-θ)simt(u,v) (13)
根据式(12)得到最终的用户偏好相似度,采用top-n方法选取相似用户,选取排名靠前的.个用户作为目标用户邻居集。通过式(14)进行预测评分。
3 实验及性能分析
3.1 数据采集与处理
服装产业发展到现代,服装种类根据不同标准可划分为多种,比如根据风格可以划分为休闲、复古、性感、优雅、时尚等,根据面料可以划分为纯棉、真丝、麻、化纤等,根据类型可以划分为衬衫、卫衣、外套等,由于服装属性多样化和不确定性,课题组邀请服装行业的专家,根据不同分类共确定了常见的8种分类及480种属性。表3展示了部分属性。
服装图像属性提取实验中用到的服装图像来自于互联网,由于卷积神经网络需要大量图片用于实验,所以共采集30000张服装图片,其中24000张用于训练,剩下的6000张用于测试。数据集中,80%的服装图片来自于电子商务网站,由于是店铺图片,所以这些图片背景一般不复杂,人物服装主体也比较突出,剩下的20%图像是社交网络中有干扰背景和不同光照的图片。由于服装推荐的特殊性,网上并没有比较适合的服装用户属性评价数据集。因此使用爬虫等技术从网上采集了上述服装图像数据集中1000张图片的相应评价,以淘宝网为例,用户在网上购买商品之后,一般会针对商品进行评价,本文以评价数据作为用户对商品的评分。数据集参照MovieLens数据集的形式,每一行包括用户ID、服装ID、用户评价以及提取到的服装属性,由于一些用户可能没有评价,为了避免数据稀疏性,所以本文将没有进行评论的用户筛选清洗出去,清洗后的数据分布如表4所示。本文将服装商品数据集简称为数据集A。
3.2 服装属性分类实验与性能分析
为了对比不同卷积神经网络结构的分类效果,训练了只含有Softmax loss损失函数的S-CNN网络、结合Softmax和Siamese度量学习的SS-CNN网络、结合Softmax和Triplet的ST-CNN网络共3种不同结构的网络,每个网络权重参数初始化为高斯分布产生的较小的数字,偏置为0,训练过程中,学习速率初始值设置为0.01,权重衰减系数设为0.0002。使用分类精确度作为评价指标,分类精确度计算公式定义为分类正确图像总数目k与测试图像总数目n的比值,计算公式为如式(15)所示。
实验结果如表5所示。
从表5中可以看出,只含有Softmax损失函数的S-CNN网络分类精度较低,引入Siamese结构的网络分类精确有小幅度提升,而引入Triplet之后的ST-CNN网络结构分类精度约有4个百分点的提高。
表6显示了使用ST-CNN网络分类进行服装图像属性提取的结果。无论是准确率,还是服装图像属性提取结果展示,本文属性提取网络均能够较好地完成属性提取任务,这也为服装推荐模型提供了较好基础。
3.3 服装推荐实验与性能分析
3.3.1 评价标准
由于推荐系统应用的情况不一,所以至今没有标准的评价指标。大多数推荐系统采用的评价指标是MAE和RSME,但是在实际情况中,用户在意的并不是某个项目给出的评分值,而是系统是否能够推荐用户喜欢的服装,所以本文考虑准确率(precision)和召回率(recall)两种指标。
准确率表示推荐的商品中用户喜欢的服装所占比例,召回率表示推荐的服装中用户喜欢的服装占用户所有喜欢服装的比例,这两种方式更能展现推荐的效果。本文主要考虑准确率,具体公式见式(16)、(17),表7表示公式中参数的含义。
虽然准确率和召回率越高越好,但是在特定的情况下,两者是相互矛盾的。因此,本文采用综合指标C进行评估,G是准确率和召回率的加权结合,其表达式为:
3.3.2 实验设计与结果分析
(1)实验1:θ调整因子对算法的影响。为验证θ的大小对准确率预测的影响,设步长为0.1,选出性能最好的θ作为本文算法调整因子。将本文算法UIACF按照不同的θ取值进行实验后的RSME值如图3所示。
从实验结果可以看出,随着θ的增大,RSME先减小后增大,当θ为0.1时,RSME的值最大;当θ为0.6时,RSME的值最小。这是由于当θ趋向于0.1时,时间因子产生的兴趣变化基本不起作用,只依赖于用户属性偏好不能很好表明用户偏好,随着θ的增大,时间因子占得比重越来越大,使得RSME的值逐渐减小。当。趋向于1时,完全忽略了时间因子的影响,从而使RSME又逐渐增大。合理分配。值有利于提高最终预测结果的准确性,本文θ为0.6时,RSME值最小,说明综合考虑基于服装图像属性偏好的与基于时间因子的兴趣度变化的偏好结果最好。实际情况可根据需要调整。
(2)实验2:不同算法准确率对比。为了进一步验证本文算法准确性和有效性,利用采集的服装数据,将传统基于用户的协同过滤算法UCF、基于项目的协同过滤算法ICF和基于项目偏好的协同过滤算法UCSVD作为对比进行实验,本文提出的UIACF算法准确率根据公式(16)计算得到,其它3种算法的准确率由实验室其他研究人员共同实验得到,不同算法的准确率对比如图4所示。
如图4所示,随着用户近邻集的增大,准确率也在升高,当N为30时准确率达到最高,但是如果用户近邻数继续增大,准确率却会下降,这是因为当邻居数很多时,邻居集中的用户相似度不高导致对结果产生负面影响。对比其它算法,本文提出的UIACF算法准确率最多提高14%。
(3)实验3:不同近邻数对算法的稳定性影响。考虑到推荐系统需要的稳定性和持久性,需排除偶然性因素。将近邻数N取值不同情况下得到的准确率、召回率通过公式(16)-(18)计算得到准确率和召回率加权G的值,G值随着N的变化情况如图5所示。
随着近邻数的增加,评价指标值一直在0.4-0.6之间,波动很小,说明本文算法具有良好的稳定性。
4 结语
本文提出了一种融合用户图像内容属性偏好、基于时间因子与用户兴趣偏好的服装推荐算法,以用户评价和用户评价服装的属性偏好作为用户属性偏好的体现,充分挖掘用户潜在兴趣,使用深度卷积神经网络提取用户评价服装图片内容的属性,避免了人工标注属性的主观性,且实现了细粒度属性提取,还考虑了用户兴趣度随时间的变化,加大了最近时间的评分权重,充分考虑用户需求,体现了用户服装推荐个性化,也提高了个性化推荐准确率。下一步工作将优化服装图像内容提取网络结构,使网络加入更多的属性分类,考虑更多可影响用户服装购买行为的个性化因素,进一步探索服装個性化推荐技术。
猜你喜欢
现代电子技术(2017年3期)2017-03-04
现代电子技术(2017年1期)2017-02-16
中国新通信(2016年22期)2017-01-13
现代电子技术(2016年22期)2016-12-26
