
基于多视图融合的论文自动分类方法研究
2020-08-03 07:58杨秀璋夏换于小民杨琪汪瑜斌
现代电子技术 2020年8期
杨秀璋 夏换 于小民 杨琪 汪瑜斌

摘 要: 为科研工作者精准推荐所需的学术论文,从而节约检索时间和精力,提高科研效率,并进一步提升论文自动分类的准确度。该文在传统单视图论文分类基础上,提出了一种基于多视图融合的论文自动分类方法,考虑论文标题、关键词、摘要三个视图的互补性和协调性,实现对海量论文的自动分类。文中抓取了中国知网9个主题的1 710篇论文作为实验语料,并构建决策树、K最近邻、随机森林、支持向量机、朴素贝叶斯分类器进行实验。结果表明,基于多视图融合的论文分类方法在准确率、召回率和F值上都有所提升,优于单视图的论文分类方法,且可以为论文自动分类、推荐系统、文本挖掘提供有效支撑,具有一定的应用前景和实用价值。
关键词: 论文自动分类; 多视图融合; 数据处理; 语料获取; 智能推荐; 文本挖掘
中图分类号: TN911?34; TP391 文献标识码: A 文章编号: 1004?373X(2020)08?0120?05
Research on paper automatic classification method based on multi?view fusion
YANG Xiuzhang1, XIA Huan2, YU Xiaomin2, YANG Qi1, WANG Yubin1
(1. School of Information, Guizhou University of Finance and Economics, Guiyang 550025, China;
2. Guizhou Key Laboratory of Economics System Simulation, Guizhou University of Finance and Economics, Guiyang 550025, China)
Abstract: On the basis of the traditional single?view paper classification, an automatic classification method based on multi?view fusion is proposed to accurately recommend the required academic papers for scientific research workers, so as to save the retrieval time and energy, improve the scientific research efficiency, and further increase the accuracy of paper automatic classification. In the method, the complementarity and coordination of the three views of the title, keyword and abstract in the paper are considered to realize the automatic classification of massive papers. The 1710 papers on nine topics on CNKI were grabbed as the experimental corpus, and the decision tree, K nearest neighbor, random forest, support vector machine and naive Bayes classifier were constructed for the experiments. The results show that the paper classification method based on the multi?view fusion can improve the precision, recall rate and F value, which is better than the single?view paper classification method. The algorithm can provide effective support for automatic classification, recommendation system and text mining, which has certain application prospect and practical value.
Keywords: paper automatic classification; multi?view fusion; data processing; corpus obtaining; intelligent recommendation; text mining
0 引 言
随着机器学习和知识图谱的迅速发展,自动推荐系统越来越普遍,论文自动分类就是其应用之一。然而,由于学术科研成果种类繁多、学科呈交叉式分布、实时性强,并蕴含着深层次语义知识,这一定程度上妨碍了科研工作者快速精准地从海量文献中获取自己所需的信息。论文自动分类旨在准确地划分论文学科类别,再通过推荐系统或知识图谱实现关联性推荐,从而节约科研工作者的检索时间和精力,提高科研效率。
传统的论文自动分類算法仅从单一角度或仅依赖论文摘要去实现自动分类的,没有考虑多个视图角度的互补性和协调性,如何从多个视图角度并同时利用论文标题、关键词和摘要三个视图去解决论文自动分类问题,正是本文所研究的出发点。针对这些问题,本文提出一种基于多视图融合的论文自动分类方法,构建决策树、K最近邻、随机森林、支持向量机、朴素贝叶斯分类器,再对基于标题视图、关键词视图、摘要视图和本文提出的多视图融合的论文自动分类方法进行比较,进而论证多视图融合方法。
1 相关研究
近年来,国内外学者对论文自动分类和关联推荐做了大量研究,常用的方法是使用机器学习和自然语言处理中的文本分类算法实现,包括朴素贝叶斯、K最近邻、支持向量机、决策树、最大熵等。
刘浏等结合论文的跨学科度和KNN算法,实现了社科类论文的自动分类[1];颜端武等通过HDP模型研究主题文献并实现自动推荐[2];周庆平等提出了基于聚类改进的KNN文本分类算法[3];杨晓花等通过多父突变和交叉操作估计概率项改进贝叶斯分类算法,并用于书目自动分类[4];冯志刚等从引用和被引用两个角度分析图书情报学文献的跨学科性[5]。同时,随着深度学习和语义网的兴起,利用LDA模型[6]、Word2Vec、卷积神经网络的文本分类方法也得到了一些尝试。王婷婷等通过LDA模型和Word2Vec算法获取科技文献的主题词概率,并构建词义相关的T?WV矩阵识别主题[7];商宪丽基于LDA模型研究交叉学科潜在主题[8];Shi等通过LDA主题建模量化企业在产品、市场和科技空间中的位置,分析企业非结构化业务数据[9];陈波利用卷积神经网络实现文本分类,提升了准确率、召回率和F值[10];李洋等提出了基于CNN和BiLSTM网络特征融合的文本情感分析方法[11]。
从相关研究可以看出,现有的论文分类采用的方法是基于机器学习、LDA模型、神经网络实现的,可以有效地实现论文自动分类,预测论文所属的学科或主题。但这些方法均是从单一视图角度实现的,没有引入基于多视图融合的思想,也没有从多个角度考虑论文的互补性和协调性,因此本文提出了一种基于多视图融合的论文自动分类方法。
从多视图融合的角度看,现代科学研究中,学科、主题间的合作越来越普遍和密切[12],通过多种视图角度解决问题已成为现代科学发展的重要内容。Zhang等提出了一种多视图融合的实体对齐方法[13];孙启蕴采用一种多视图tri?training的方法实现用户性别判断[14]。
本文选择中国知网9个主题的学术论文作为语料,提出一种基于多视图融合的论文自动分类方法,并与单视图的论文自动分类算法进行对比实验,通过准确率、召回率和F值进行算法评价。
2 基于多视图融合的论文自动分类方法
2.1 算法总体流程
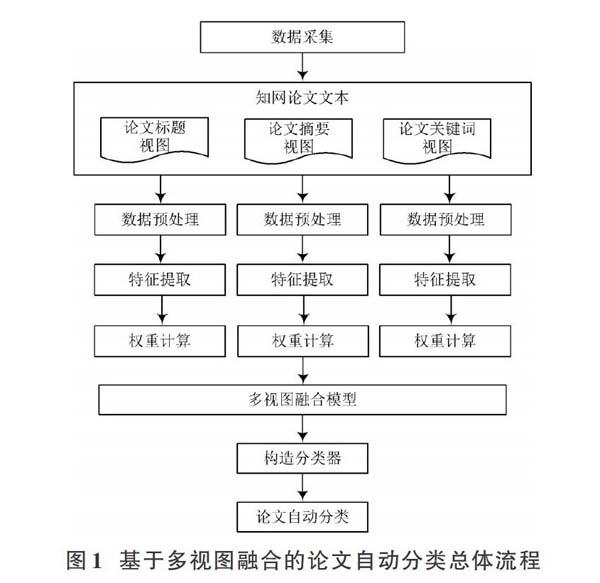
本文方法的总体流程如图1所示。
首先调用Selenium和XPath等技术自动抓取中国知网“数据挖掘”“数据分析”“大数据”“Python”“民族”“数学”“文学”“数据科学”“机器学习”九个主题的1 710篇学术论文;接着从论文标题、关键词、摘要三个视图分别对所抓取的文本进行数据预处理,包括中文分词、数据清洗、数据集成等操作,并通过特征提取及权重计算技术将预处理后的文本转换为特征词矩阵;利用多视图融合模型对论文标题视图、关键词视图和摘要视图的特征词向量进行融合,并构造决策树(Decision Tree)算法、K最近邻(K?Nearest Neighbor)算法、随机森林(Random Forest)算法、支持向量机(Support Vector Machine)算法、朴素贝叶斯(Naive Bayes)算法的分类器实现论文自动分类。
2.2 数据预处理
本文抓取了中国知网九个主题的若干期刊论文的相关信息作为实验语料,并将其导入数据库形成结构化数据,抽取的信息主要包括论文标题、关键词、摘要和类别4个字段。实验之前需要对数据进行预处理操作,包括中文分词、缺失值填充、异常值处理、去除停用词、去除标点符号、数据集成等步骤,其目标是为了得到高标准、高质量的数据,从而提升分析结果,过程如图2所示。
2.3 特征提取和权重计算
向量空间模型(Vector Space Model)表示通过向量的形式来表征一个文本,它将中文文本转换为数值特征。一个文档(Document)或文本语料经过特征提取后被描述为一系列的特征词(Term)向量,如下:
式中:文档d共包含n个特征词和n个权重;ti为一系列互相不同的特征词,i=1,2,…,n;wi(d)为特征词ti在文档d中的权重,它通常可以被表达为ti在d中呈现的频率。
本文权重计算的方法是采用TF?IDF算法来实现的。
TF?IDF(Term Frequency?Invers Document Frequency)是一种常用于信息处理和数据挖掘的加权技术。该技术采用一种统计方法,根据特征词在文本中出现的次数和在整个语料中出现的文档频率来计算一个特征词在整个语料中的重要程度。它的优点是能过滤掉一些常见的却无关紧要本的词语,同时保留影响整个文本的重要特征词。计算方法如下:
式中,tfidfi,j表示词频tfi,j和倒文本词频idfi,j的乘积,权重与特征项在文档中出现的频率成正比,与在整个语料中出现该特征项的文档数成反比。TF?IDF值越大表示该特征词对文本的重要性越大。
2.4 多视图模型
多视图模型是从多个角度解决论文分类问题,考虑了多种视图的互补性和协调性。本文结合论文标题、关键词、摘要三种视图进行实验,其融合过程如图3所示。
由于不同视图的文本会存在獨有特征词和共有特征词的情况,本文将三个视图F1,F2,F3划分为7个数据集U1,U2,U3,U4,U5,U6,U7,其划分过程如下:
多视图模型的计算公式如下:
式中:[V]表示多视图融合后的向量空间模型;V1表示F1视图独有的特征词向量,对应的权重参数w1;V2表示F2视图独有的特征词向量,参数w2表示F2视图独有部分的权重;V3表示F3视图独有的特征词向量,对应的权重参数w3;V4,V5,V6表示F1,F2,F3视图两两共有特征词且不含有三个视图共有的特征词的向量,对应的权重为w4,w5,w6;V7表示标题、关键词、摘要视图共有的特征词向量,参数w7表示对应的权重。
3 实验结果与分析
3.1 语料获取和预处理
本文使用Python自定义爬虫采集中国知网1 710篇学术论文信息(包括标题、关键词和摘要),涉及9个主题,并将数据集按照一定比例划分训练集与测试集,详细信息如表1所示。
接着采用Jieba工具对文本语料进行中文分词处理,并去除停用词、标点符号,再进行特征提取和权重计算。
3.2 评价指标
本文采用准确率(Precision)、召回率(Recall)和F值(F?measure)评估实验结果,最终结果为10次实验结果的平均值。计算公式定义如下:
式中:ni表示类别为i的文本数目;nj表示类标j的文本数目;nij表示文本类标j中属于i的数目;F值是准确率和召回率的加权调和平均值,常用于评价分类、聚类模型的好坏。
3.3 论文自动分类实验
采用支持向量机算法分别对各数据集进行论文自动分类实验,比较基于标题视图、关键词视图、摘要视图以及本文提出的基于多视图融合的论文自动方法,实验结果的F值如表2所示。由表可知,本文方法的F值最高为1.00,最低为0.83,F值较其他三种方法都有一定提高,其中“数据分析”主题提升最多,比基于标题视图的方法提升了0.07,比基于关键词视图的方法提升了0.07,比基于摘要视图的方法提升了0.05。
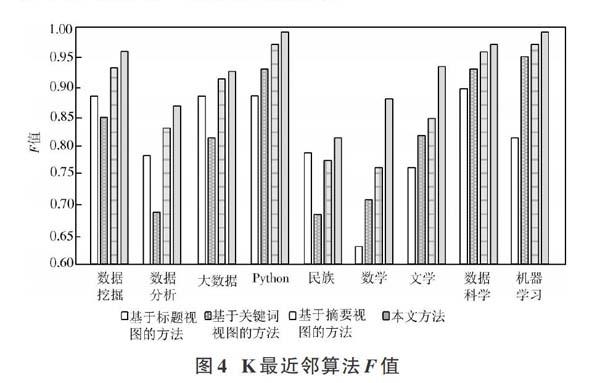
采用K最近邻算法的实验结果F值如图4所示,从图中可以看出,本文方法在所有主题的论文自动分类比较中,F值都有一定程度的提升。
从表3可以看出,基于随机森林的多视图融合论文自动分类方法的F值优于其他方法,其中相比于基于标题视图方法的F值提升最为明显。“数据挖掘”主题提升了0.09,“数据分析”主题提升了0.12,“大数据”主题提升了0.19,“Python”主题提升了0.11,“民族”主题提升了0.02,“数学”主题提升了0.28,“文学”主题提升了0.04,“数据科学”主题提升了0.09,“机器学习”主题提升了0.21。
为了进一步研究论文自动分类算法,分别对比了基于多视图融合和单视图的随机森林、K最近邻、支持向量机、朴素贝叶斯、决策树分类算法。图5~图7分别显示了各分类算法对比实验的平均准确率、平均召回率和平均F值,实验结果整体呈现出本文方法优于基于摘要视图方法、基于关键词视图方法、基于标题视图方法的趋势,本文方法的论文自动分类效果更好。
4 结 语
针对传统的论文自动分类算法仅从单个视图的角度去实现分类,没有考虑多种视图的互补性和协调性,本文提出了一种基于多视图融合的论文自动分类方法,结合论文标题、关键词、摘要三种视图来实现自动分类。仿真实验首先抓取了中国知网九大主题的论文数据,再分别对比了基于多视图融合和单视图的随机森林、K最近邻、支持向量机、朴素贝叶斯、决策树分类算法。
实验结果表明,本文提出的基于多视图融合的论文自动分类方法优于其他三种单视图的论文自动分类方法,本文的方法在准确率、召回率和F值上都有所提升,为下一步自动分类、引文分析、文献知识图谱构建提供有效支撑,具有较好的准确率和实用性。
注:本文通讯作者为夏换。
参考文献
[1] 刘浏,王东波.基于论文自动分类的社科类学科跨学科性研究[J].数据分析与知识发现,2018(3):30?38.
[2] 颜端武,陶志恒,李兰彬.一种基于HDP模型的主题文献自动推荐方法及应用研究[J].情报理论与实践,2016,39(1):128?132.
[3] 周庆平,谭长庚,王宏君,等.基于聚类改进的KNN文本分类算法[J].计算机应用研究,2016,33(11):3374?3377.
[4] 杨晓花,高海云.基于改进贝叶斯的书目自动分类算法[J].计算机科学,2018,45(8):203?207.
[5] 冯志刚,李长玲,刘小慧,等.基于引用与被引用文献信息的图书情报学跨学科性分析[J].情报科学,2018,36(3):105?111.
[6] BLEI D M, NG A Y, JORDAN M I. Latent dirichlet allocation [J]. Journal of machine learning research, 2003, 3: 993?1022.
[7] 王婷婷,韩满,王宇.LDA模型的优化及其主题数量选择研究:以科技文献为例[J].数据分析与知识发现,2018(1):29?39.
[8] 商宪丽.基于LDA的交叉学科潜在主题识别研究:以数字图书馆为例[J].情报科学,2018,36(9):27?31.
[9] SHI Z M, LEE G, WHINSTON A B. Toward a better measure of business proximity: topic modeling for industry intelligence [J]. MIS quarterly, 2016, 40(4): 1035?1056.
[10] 陈波.基于循环结构的卷积神经网络文本分类方法[J].重庆邮电大学学报(自然科学版),2018,30(5):705?710.
[11] 李洋,董红斌.基于CNN和BiLSTM网络特征融合的文本情感分析[J].计算机应用,2018,38(11):3075?3080.
[12] BRONSTEIN L R. A model for interdisciplinary collaboration [J]. Social work, 2003, 48(3): 297?306.
[13] ZHANG Chunxia, YANG Xiuzhang, WANG Shuliang, et al. A multi?view fusion approach for entity alignment [C]// 2017 IEEE 16th International Conference on Cognitive Informatics & Cognitive Computing. Porto: IEEE, 2017: 388?393.
[14] 孙启蕴.基于多视图Tri?Training的微博用户性别判断[J].计算机系统应用,2018,27(2):240?244.
猜你喜欢
心理学报(2022年4期)2022-04-12
水泵技术(2021年3期)2021-08-14
软件导刊(2016年12期)2017-01-21
电子技术与软件工程(2016年22期)2016-12-26
商(2016年34期)2016-11-24
中国远程教育(2016年9期)2016-11-19
语文教学之友(2016年5期)2016-06-15
电脑知识与技术(2016年5期)2016-04-14
当代化工研究(2016年9期)2016-03-20
西华师范大学学报(自然科学版)(2015年3期)2015-02-27
