
基于大数据的城市轨道交通数据处理流程研究
2020-08-10 08:45兰慧峰左旭涛王美霞岳阳周凡
中国新技术新产品 2020年10期
兰慧峰 左旭涛 王美霞 岳阳 周凡

摘 要:该文对线网数据中心进行了简要介绍,从逻辑架构、处理机制和数据存储3个方面,对实时数据处理过程进行了分析。从逻辑架构、数据清洗、配置工作流、任务调度和数据存储5个方面,对离线数据处理过程进行了分析。青岛地铁利用大数据技术,结合地铁运营业务,对有关运营生产数据的实时及离线处理流程进行了研究,实现了线网实时生产数据及离线生产数据的数据处理服务,为运营决策提供数据支撑。
关键词:数据中心;实时数据处理;离线数据处理;工作流
中图分类号:TP311 文献标志码:A
0 引言
随着城市轨道交通线路的不断增加,青岛地铁已步入网络化运营阶段。随着新业务需求的产生,地铁运营管理日益复杂,运营生产数据呈爆炸式增长。因此寻求有效地海量数据处理技术、数据治理方法和手段已经成为非常迫切的需求。青岛地铁是国内首个基于Hadoop大数据技术搭建线网中心的地铁公司[1],其结合实际业务应用,合理选择技术路线,实现了线网实时生产数据及离线生产数据的数据处理服务,为运营指挥系统、应急指挥系统、线网统计分析、线网运营评估、信息服务等上层应用提供了数据支撑。
1 线网数据中心简介
线网数据中心是青岛地铁线网中心的核心[2],基于Hadoop大数据技术搭建[3],是线网上层业务系统的数据来源。线网数据中心主要包括数据采集、数据处理、数据分析和数据输出等功能模块,其中数据处理是数据中心的核心。数据处理根据数据传输的时效性要求可分为实时数据处理和离线数据处理2个部分。实时数据是指对数据时效性要求较高的突发类事件信息、人员定位信息、突发事件处置意见等。同时,时效性在5 min、15 min等的客流类近线数据,在处理中也算作实时数据进行处理。离线数据主要是指时间范围为昨日及昨日以前的结构化数据。每天通过采集层从接口服务器采集离线数据,并把采集数据存储到HDFS临时文件存储区,经数据的清洗、加工和轉换后,存储到数据中心。
2 实时数据处理
城市轨道交通实时数据主要包括线路、车站的客流情况,列车运行情况,设备的工作状态、能耗等现场的信息,数据中心通过对这些数据进行采集和处理,将其反映到线网指挥中心,供指挥中心了解整个线网的运行情况,为列车调度、设备运维、突发事件处理等运营决策提供数据支撑和服务。
大数据的计算模式主要分为批量计算(batch computing)、流式计算(stream computing)、交互计算(interactive computing)、图计算(graph computing)等。基于青岛地铁的线网数据中心建设主要应用了批量计算和流式计算2种。流式计算和批量计算是2种主要的大数据计算模式,分别适用于不同的大数据应用场景。对于处理实时性要求严格的线网实时数据,流式计算具有明显的优势。对于先存储后计算、实时性要求不高并且数据比较全面的线网离线数据,批量计算更适合。
在流式计算中,数据往往是最近时间段的增量数据,如实时客流数据、行车数据及综合监控数据等,数据的延时往往较短,实时性较强,但数据的信息量相对较少,只局限于该时间段内的数据信息,不具有全量信息的特征。
从数据来源方面来讲,其与批量计算相比一个明显的区别是其数据通常来源于“数据预处理服务”的实时供给(如Kafka),而不像批量计算那样从数据存储中获取已存储的数据。
线网数据中心从技术路线的统一性角度以及功能要求等角度出发,选用了Spark作为分布式计算的框架,选择Spark Streaming技术作为流式计算的基础框架。
2.1 逻辑架构
实时数据处理架构图如图1所示。
系统的逻辑架构主要描述实时数据处理模块建设的关键主体。根据实时数据处理业务的相关主体类别,将系统的逻辑架构分为数据源层、数据采集层和分析层3个层次。
数据源层定义了实时数据的数据来源、数据格式等。
采集层定义了数据采集的清洗规则、转换规则、采集频率、消息格式等。
分析层定义了数据加工算法、实时指标的存储规则等。
2.2 处理机制
数据中心的数据采集层将采集到的实时数据通过Kafka消息的方式传输到Kafka消息队列中,数据消费者需要扫描Kafka MQ消息队列,当消息队列中存在数据时,接收这些数据并对其进行解析,根据业务要求输出到Redis等内存数据库,供上层使用。
Kafka消费者程序的数据处理流程有4步。1)对约定的消息队列(Topic)进行定时扫描。2)当扫描到消息数据时,根据数据标准协议完成数据解析。3)将解析后的数据根据应用场景进行加工处理,并将处理结果输出到Redis内存数据库中。4)继续步骤(1),进行下一个消息队列数据的扫描。
2.3 数据存储
因传统关系库不能满足实时系统快速响应的要求,该系统选择Redis作为实时数据加工、分析结果数据存储的数据库。根据青岛地铁线网中心的业务需求,合理设计实时指标的数据存储方式、数据过期策略等,向上层应用提供高速读写、稳定运行的数据服务。
3 离线数据处理
3.1 逻辑架构
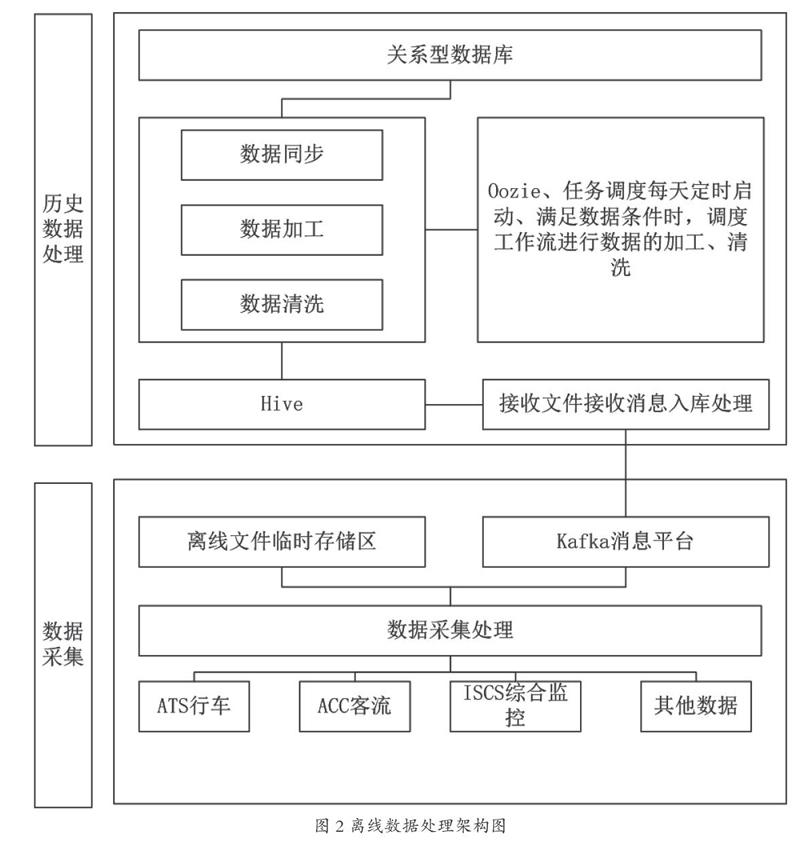
离线数据处理架构如图2所示。
3.2 数据清洗
配置工作流之前,首先要进行数据清洗[4],数据清洗的流程分解为以下3步。
3.2.1 数据清洗、去重、转换
数据处理的数据源头被称为贴源层,贴源层数据是各数据源业务系统的未加处理的数据合集。在未经处理之前,数据质量无法保证,需根据业务规则进行清洗,并去除重复的数据。各数据源业务系统通常由不同的供应商提供,各业务主体之间,甚至同一业务主体之间,都可能存在不同的业务编码,这样就给线网生产数据的融合造成了巨大的麻烦。数据转换的目的是为青岛地铁的各上层应用提供一致的、规范的数据,对不同业务主体的业务数据进行统一的业务编码,经清洗、去重和转换后,写入基础明细层。
3.2.2 加工、分析
加工、分析是数据处理的核心,只有经过加工、分析,原始数据才能转化为有效数据,成为有用的信息。
3.2.3 数据同步
把加工、分析结果同步到应用服务器,给上层应用提供数据服务。
3.3 配置工作流
工作流是对工作流程及其各操作步骤之间的业务规则的抽象、概括描述,是将工作流程中的工作,如何前后组织在一起的逻辑和规则[5]。由工作流的定义可以看出,工作流编制的重点是弄清楚工作的前后逻辑,为了弄清楚组织逻辑,可以按以下4个步骤进行。
3.3.1 业务梳理
如果把数据加工、分析的结果称做指标,那么就可以区分出哪些指标是由基础明细数据生成的,该类指标可称为基础指标。而对于由基础指标生成的新指标,可称为衍生指标。
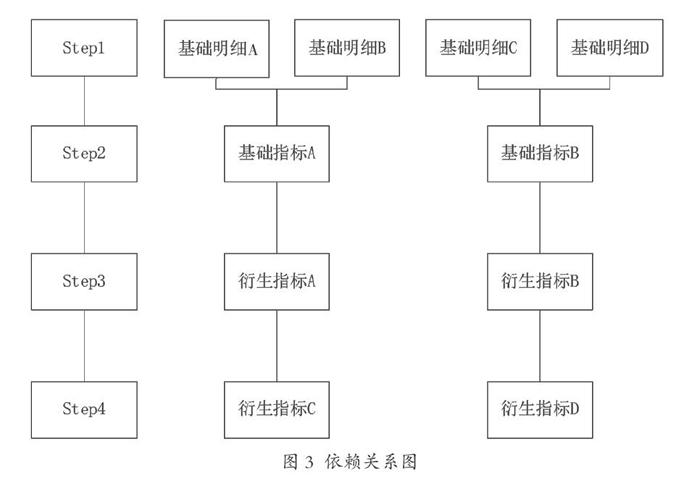
3.3.2 依赖梳理
在梳理好业务,把加工指标区分为基础指标、衍生指标后,画出指标的依赖关系图,如图3所示。
根据依赖关系图,我们可以定义工作流的Step1、Step2、Step3...StepN。
3.3.3 工作流粒度划分
工作流粒度划分可以分为纵向粒度划分和横向粒度划分2种。纵向粒度划分参照数据的依赖关系即可,如果所有工作流都按纵向划分去设置,则存在数量大、配置麻烦、集群资源利用率不高等问题,而Oozie任务调度平台既支持纵向依赖配置,也支持横向并行配置。横向粒度划分在满足纵向依赖的前提下,要考虑工作流的整体执行时长,不能因为其中一个任务的执行时间过长,导致所有工作流执行时间变长,因此选择依赖相同、执行时长相似的任务是工作流横向划分的依据。
3.3.4 依赖条件检查
在工作流的编制中,除了需要重点关注数据加工、分析的依赖关系外,还需要注意数据是否具备数据加工、分析的依赖条件,历史数据的采集是按T+1(昨天)方式,按天增量采集,指标的加工、分析同样是按照按天增量的方式加工、分析,在采集数据的过程中,存在很多不可控因素,导致数据不能按时采集到位,为了保证数据的正确性、完整性,在每个工作流开始执行之前,必须进行数据是否满足依赖条件的检查。
3.4 任务调度
在编制好数据加工、分析的工作流后,为了满足数据中心7×24 h稳定运行的要求,需要按时对编制好的工作流任务进行调度。
3.5 数据存储
Hive是基于Hadoop的数据仓库工具,青岛地铁数据中心采用Hive作为数据仓库,DB2作为集市层数据存储媒介,为上层应用提供数据服务。按照业内广泛采用的分层设计方式,核心区域划分为基础明细层、汇总层和集市层[6]。其在整个青岛地铁数据中心数据架构中处于数据服务层。分层设计的示意图如图4所示。
3.5.1 数据源层
数据源层定义了离线数据的数据来源和数据格式。
3.5.2 贴源层
贴源层实现了从采集到的文件数据到Hive表的关系映射,为基础明细层数据的加工做好准备。
数据中心通过源系统的数据传输接口获取源数据,根据不同的传输周期完成数据加载,加载方式包括实时加载、准实时加载和定时加载3种。为了保证数据能够在短时间内完成数据入库,同时降低对前端应用访问数据仓库数据的影响,在数据仓库内设置了临时数据区,即贴源层。在此基础上,完成数据从贴源层到基础明细层的数据转换工作。
贴源层主要用于保存ACC、ATS和综合监控等源系统的接口数据,尚未对数据进行加工和转换,是基础明细层的数据来源。与源系统不同的是,贴源层中包含了从不同线路、多个源系统中加载进来的接口数据,是源系统的未加处理的数据合集,实现了源系统数据的融合和可跨系统的查询分析功能。
3.5.3 基础明细层
基础明细层是数据服务层中最重要的一个区域,其是按照地铁数据标准的要求,对缓冲层数据进行统一加工和整合,是存储明细粒度的历史数据区域,可以为青岛地铁各个业务部门的不同业务需求提供一致的、规范的数据。同时,基础明细层数据可作为汇总层和集市层的数据源,并可以直接向高级数据分析人员开放,进行深度地指标查询、统计分析和数据挖掘。
基础明细层需要结合各线路ATS、综合监控和ACC等源系统的数据特征,切实考虑线网级城市轨道交通数据融合以及业务应用场景和发展需要,根据城市轨道交通行业的经验,开发具有先进性、高可靠性、高可扩展性和高效性的数据模型,有效融合和存储城市轨道交通的业务信息资源,支撑数据中心目前和未来各种运营管理和数据分析等应用场景。
从设计上来看,基础明细层是数据中心的核心,需要支撑数据中心所有业务主题的数据存储,同时支持主题域、实体和数据模型的扩展。城市轨道交通行业的数据模型是构建数据基础明细层的核心,其需要能够全面覆盖交通行业的数据内容,有效支撑城市轨道交通行业的分析业务场景,满足数据中心长期的业务发展需求,因此,基础明细层数据模型要具有良好的开放性、可扩展性、易操作性。
从实现上来看,基础明细层的建设要集合城市轨道交通业务及行业经验,物理表结构设计参照交通行业的数据模型,考虑行业业务规则及扩展性要求,严格遵循第三范式(3NF)[7],减少数据冗余,提高访问效率。
3.5.4 汇总层
汇总层是从城市轨道交通业务需求的视角出发,提炼出对数据处理具有共性的数据访问和统计分析的需求,从而构建出的一个面向上层应用、提供共性数据访问服务的公共数据。其数据流向是从基础明细层抽取数据,经过有针对性的汇总加工后,满足上层业务的数据需求。
3.5.5 集市层
集市层是利用汇总层的公共数据,根据上层应用的需求,组合形成面向不同主题域的集市层。向上层应用提供有针对性的数据服务。集市层是从数据仓库中抽取出来的为某类特定业务系统服务的数据集合,是数据仓库与应用层之间的接口。
数据中心的集市层中主要包括面向生产管理的指标统计分析、運营评估、运营信息报送及发布、地理信息展示与应急指挥系统的集市层。从数据聚合的粒度考虑,数据中心的集市层是根据业务需要,而汇总的重度汇总数据,并根据具体需要实现在多个维度和多粒度层次上的汇总。集市层中的数据模型根据上层应用的需求特点,适当考虑增加数据冗余设计,以提高数据分析查询的效率。
4 结语
随着大数据技术的普及,未来线网中心的建设越来越有取代传统数据仓库的趋势,青岛地铁作为国内首个基于大数据技术搭建线网中心的地铁公司,在大数据技术应用的基础上,实现了实时数据处理及离线数据处理流程,为未来城市轨道交通行业的相关应用提供技术路线和指导帮助。
参考文献
[1]罗情平,左旭涛,舒军.青岛地铁线网管理与指挥中心系统的需求分析[J].城市轨道交通研究,2017,20(12):5-9.
[2]石述红.信息时代的数据中心[J].数字通信世界,2018(11):136.
[3]郭建伟,杜丽萍,李瑛,等.Hadoop平台的分布式数据平台系统研究[J].中国科技信息,2013(10):97-98.
[4]Megan Squire.干净的数据:数据清洗入门与实践[M].北京:人民邮电出版社,2016.
[5]赵文,胡文蕙,张世琨,等.工作流元模型的研究与应用[J].软件学报,2003,14(6):1052-1059.
[6]冯晓云,陆建峰.基于Hive的分布式K_means算法设计与研究[J].计算机光盘软件与应用,2013(21):62-64.
[7]苏选良.管理信息系统[M].北京:电子工业出版社,2003.
猜你喜欢
机械研究与应用(2022年4期)2022-09-15
电子测试(2018年11期)2018-06-26
电子测试(2018年11期)2018-06-26
中国教育信息化·基础教育(2016年11期)2016-12-27
山东工业技术(2016年23期)2016-12-23
中国交通信息化(2015年3期)2015-06-05
河南科技(2014年11期)2014-02-27
