
非物流数据条件下对物流需求预测的实用性研究
2020-08-11 08:26石川
物流技术 2020年7期
石 川
(成都工业学院 信息与计算科学系,四川 成都 611730)
1 引言
经济全球化和电子商务的飞速发展,对现代物流提出了更高的要求,物流行业的发展也成为我国经济结构转型过程中一个新的经济增长点。在物流行业飞速发展过程中,供需矛盾尤为突出,主要表现在:区域物流发展不均衡导致各地供需不平衡;物流发展的周期性导致供需时间点错位;过度投资物流布局造成社会资源浪费。究其原因,在当今国家大力提倡“大数据”、“人工智能”的背景下,物流公司虽然在数量上不断壮大,但是物流行业对数据采集和分析的能力不足,导致物流公司的质量提升有限。
需求决定供给,根据相关数据对物流需求做出准确的预测能对物流供给提供更合理的指导。目前常用的对物流需求预测的方法有:回归分析、聚类分析、灰色预测、时间序列等。不过,我国现在对物流需求预测更偏向理论方法的研究,很少应用于实际。本文以四川省内一个大型连锁超市企业为背景,计划对其区域物流需求进行预测,并对其下一年的物流配置计划给出合理的建议。该企业在四川省内11个市(州)、32个县(市、区)拥有近30家大型连锁超市和20余家便利店,同时在成都建立了近30 000m2的物流配送中心。
由于现在大多数企业都不太重视物流数据和信息,一些大型企业即使建有自己的物流链,他们对与物流直接相关的数据记录都不详细和完整。所以要从物流数据去对物流需求进行预测不太现实,即使预测出来也会有比较大的偏差。考虑到该企业属于零售业,超市各个门店的销量就决定了他们的需求量,这样可以尝试用销售数据代替物流数据去对各个门店的物流需求进行预测。
2 数据的收集和整理
首先收集了该企业所有超市门店的相关信息(包括代码、位置、性质等)以及2010-2017年每个门店的月销售额数据。由于相同位置区域的门店物流线路大致相同,将各个门店按照地理位置划归五个区域,见表1。
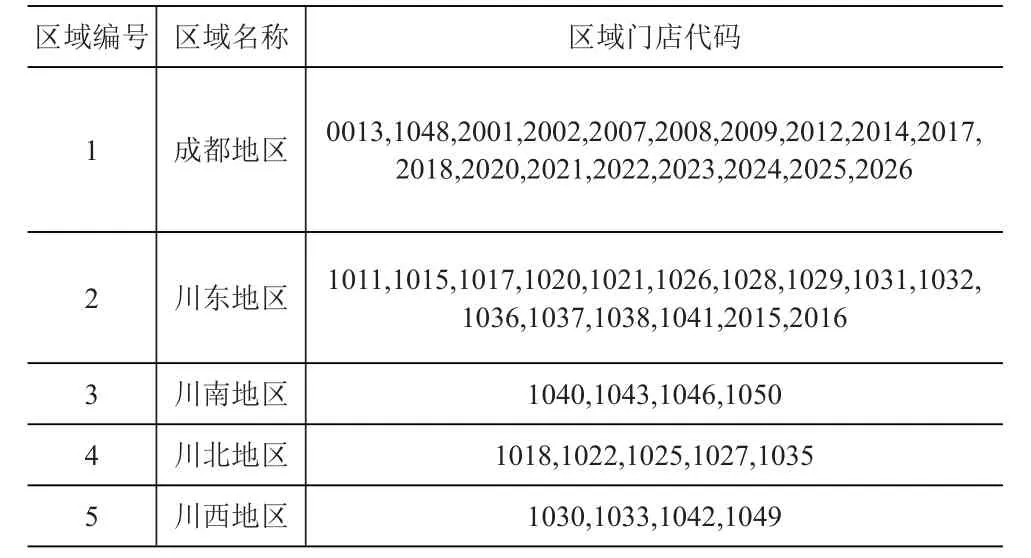
表1 企业门店分区表
对原始销售数据中明显错误的、缺失的数据用三次样条插值法将其补齐后对该企业按月、年度的总销售额及每个门店的月、年度销售额分区域统计汇总。
从基础数据的分析可以看出该企业区域物流的一些基本特征:该企业区域物流以成都为物流中转中心向成都及其他地区配送商品;成都及川东地区门店数量及销售额超过该企业总销售额的70%,而川东地区地处山区且物流配送距离远,是物流资源配置的重心;川南和川西地区是这几年销量增长最快的区域,需做好物流资源需求暴增的预警。
3 预测模型的建立
由于采集的数据类型比较单一,不太适用回归分析和因素分析来进行预测,且采集到的数据刚好是标准的时间序列数据,所以考虑采用时间序列分析来建立预测模型。ARIMA(k,d,q)模型是在时间序列分析中最常用的模型。自回归模型(AR)、移动平均模型(MA)和混合模型是ARIMA的三种基本形式,k是自回归项数,q是移动平均项数,d是差分次数。
3.1 数据的平稳性分析
根据企业月份总销量图可以初步判断其为平稳序列。将数据进行一阶差分处理后平稳性更好,如图1所示。
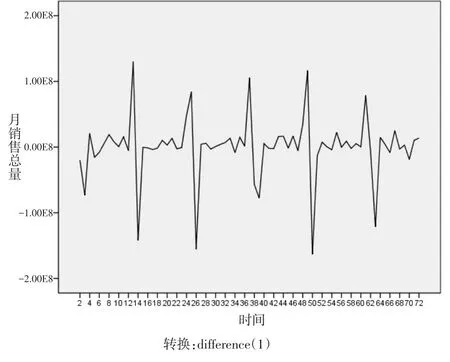
图1 企业月销量一阶差分时序图
为了对数据平稳性进行进一步验证,检验企业月销量一阶差分序列的自相关性和偏自相关性,如图2所示。
3.2 建立预测模型
自相关系数和偏自相关系数在第一、二项之后快速趋近于零,则考虑把k和q在0~2之间取值来拟合相关模型参数。而且自相关系数与偏自相关系数都拖尾,决定建立ARIMA模型来对数据进行预测。
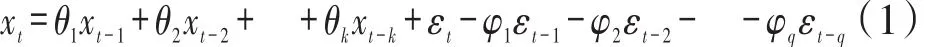
4 区域物流需求预测
4.1 预测模型的求解
我们考虑用2010-2015年的数据来拟合模型参数,用2016-2017年的数据来对模型进行检验。同时因为年度数据太少,如果用年度数据来求解预测模型可能会有较大误差,所以决定用月销量来求解模型。用SPSS对k,q,d在0~2之间的不同取值求解。下面给出效果最好的ARIMA(0,0,0)(1,1,1)的一些分析结果。R方的值达到0.954,拟合优度很好。AR的系数为-0.468,MA的系数为0.969,显著性水平均低于0.02,模型的系数显著不为零。
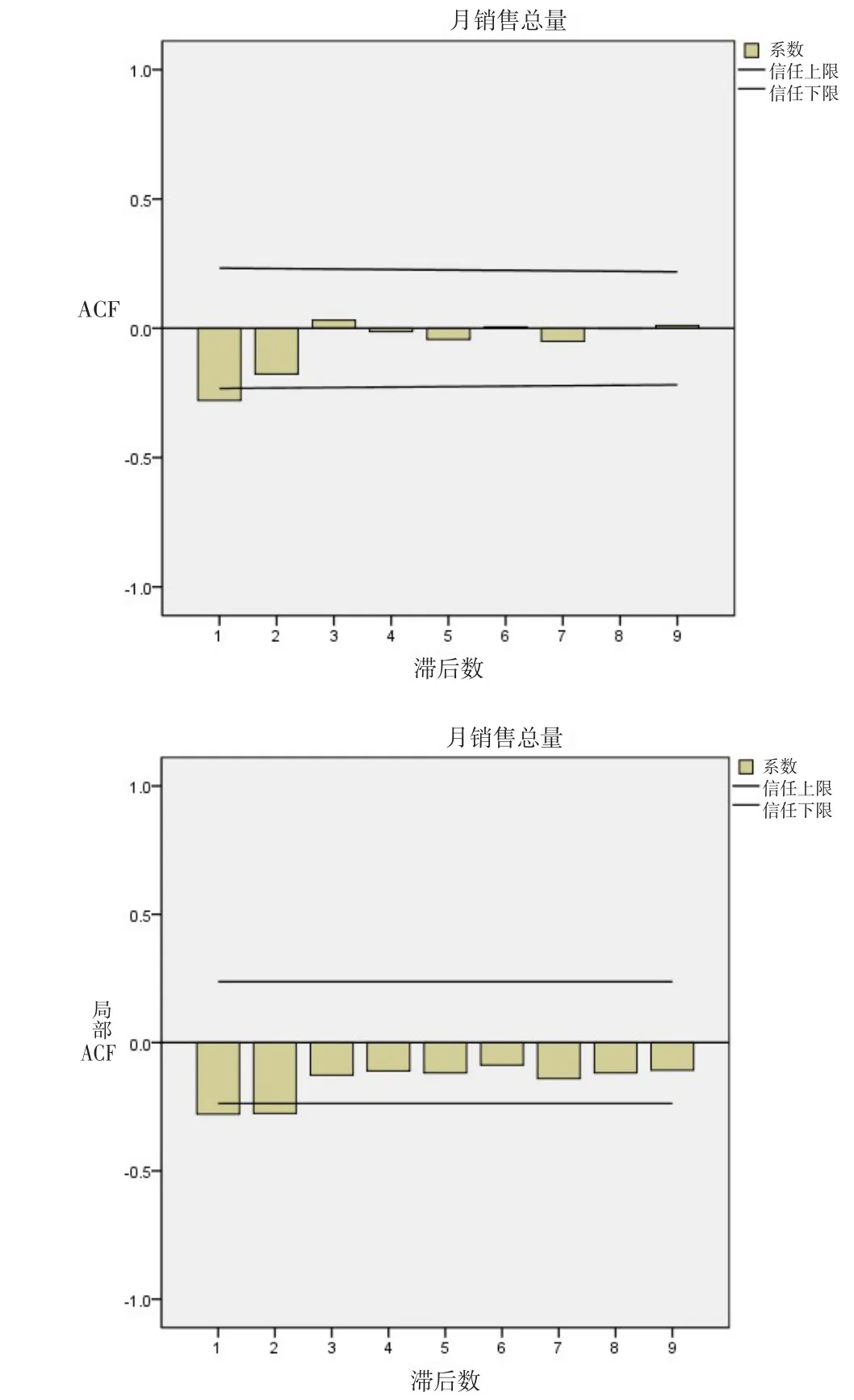
图2 企业月销量一阶差分序列自相关性与偏自相关性图
残差ACF图和残差PACF图(如图3所示)很稳定。由此建立该企业月份总销量的ARIMA预测模型为:
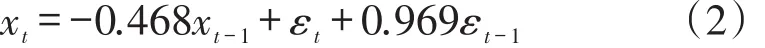
4.2 销量预测
利用预测模型预测出2016和2017年的各月销售量见表2、图4。
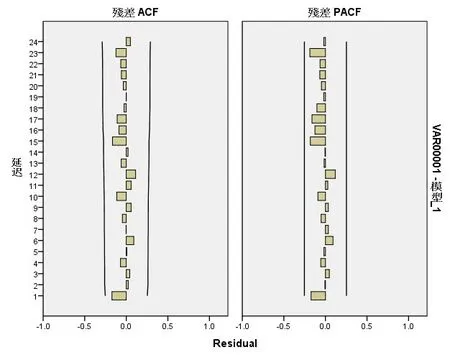
图3 企业月销量残差图
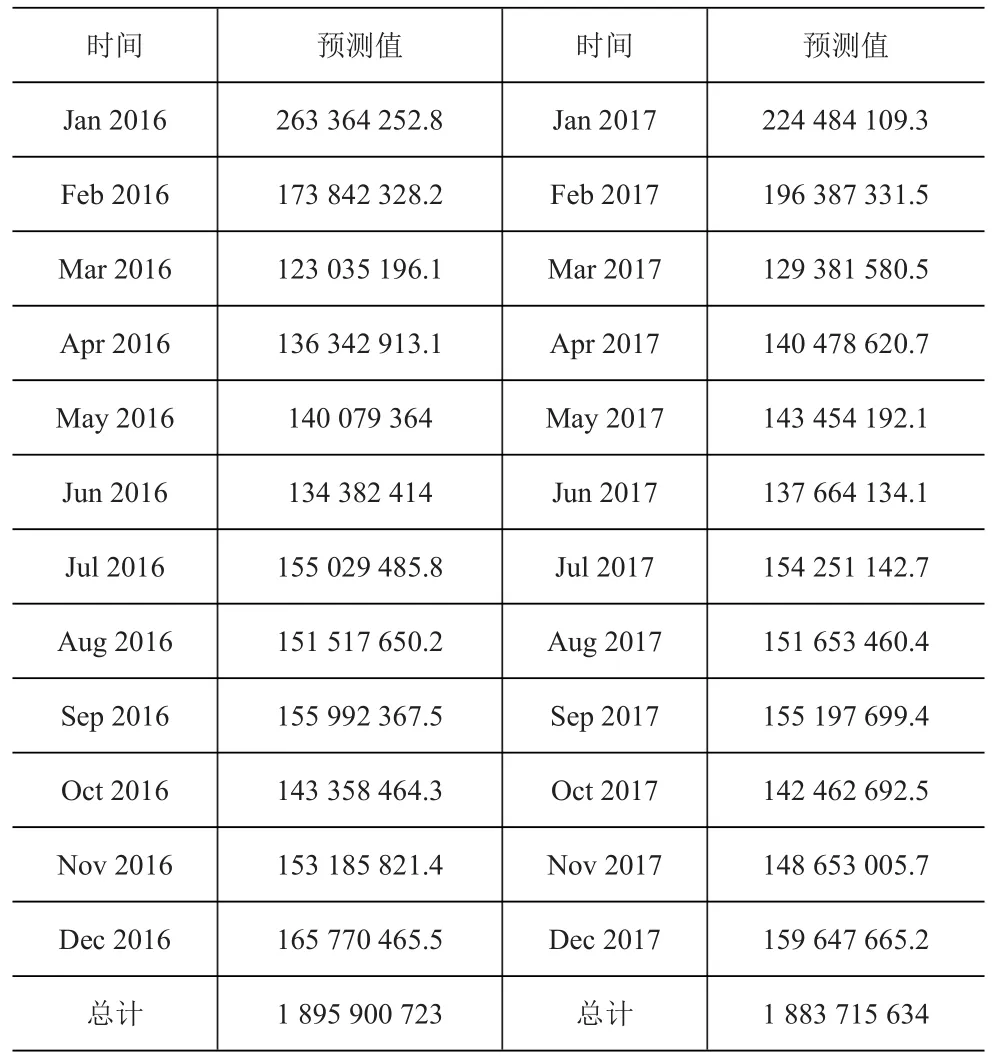
表2 企业销售总量预测表(单位:元)
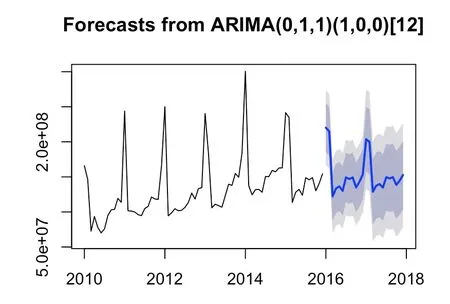
图4 企业销售总量预测图
预测效果还是比较好的。接下来利用模型对省内不同区域的销量做出预测,并绘制出不同区域销量预测图,如图5所示。
5 模型的分析与检验
在确定了模型的参数估计值之后,可以继续对模型的合理性进行检验。对建立的ARIMA模型进行白噪声检验。由图3可知,残差序列是纯随机序列,可以用该模型进行预测。同样分区域的总量预测的残差自相关系数和偏自相关系数也都满足条件。还可以对企业2016-2017年的相关数据汇总,并与模型在这些年份的预测值进行比较,见表3。
以2016年为例,可以看出预测模型对企业在该年份销售额的预测效果是很好的,月预测数据与实际的相对误差都低于8%,而2016年总销售量的预测相对误差仅为1.93%。预测效果让人比较满意,说明该模型在预测上具有一定的实用价值。同样分析出不同区域预测值与实际值也相差不大,有着比较好的预测效果。
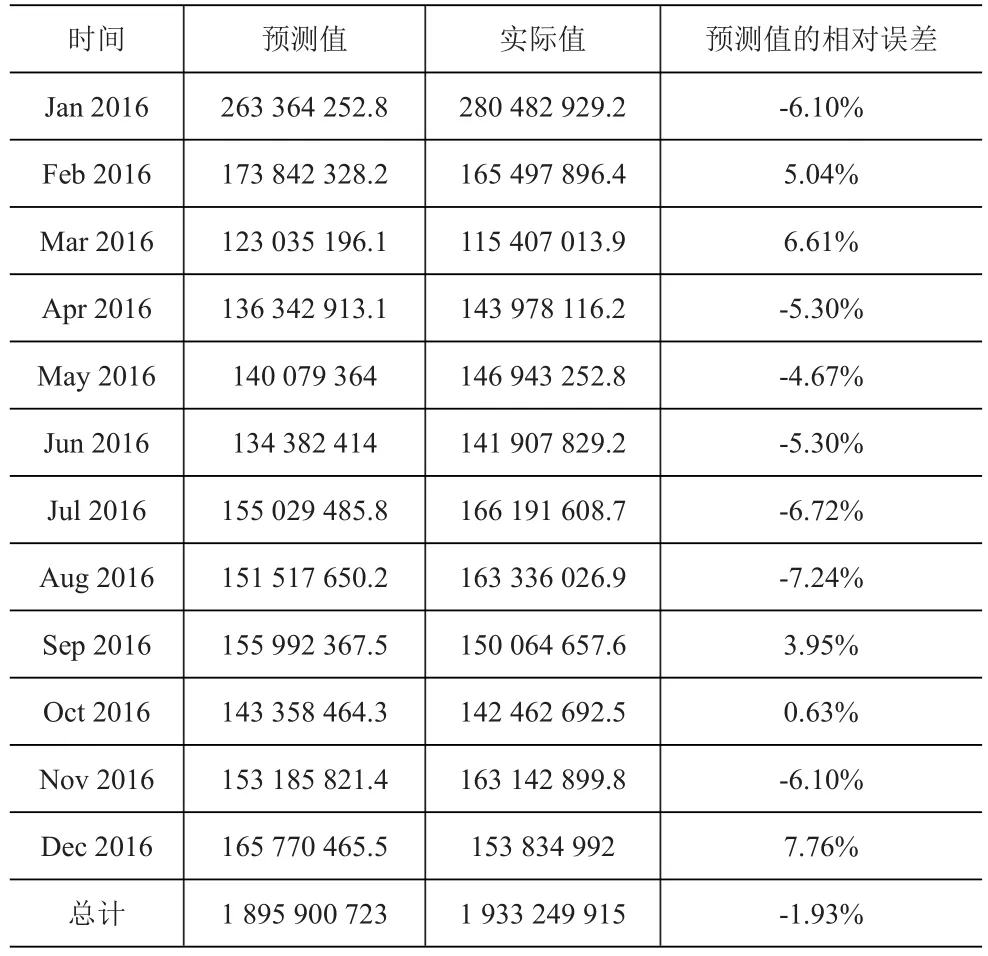
表3 企业2016年月总销量预测值与实际值对比表
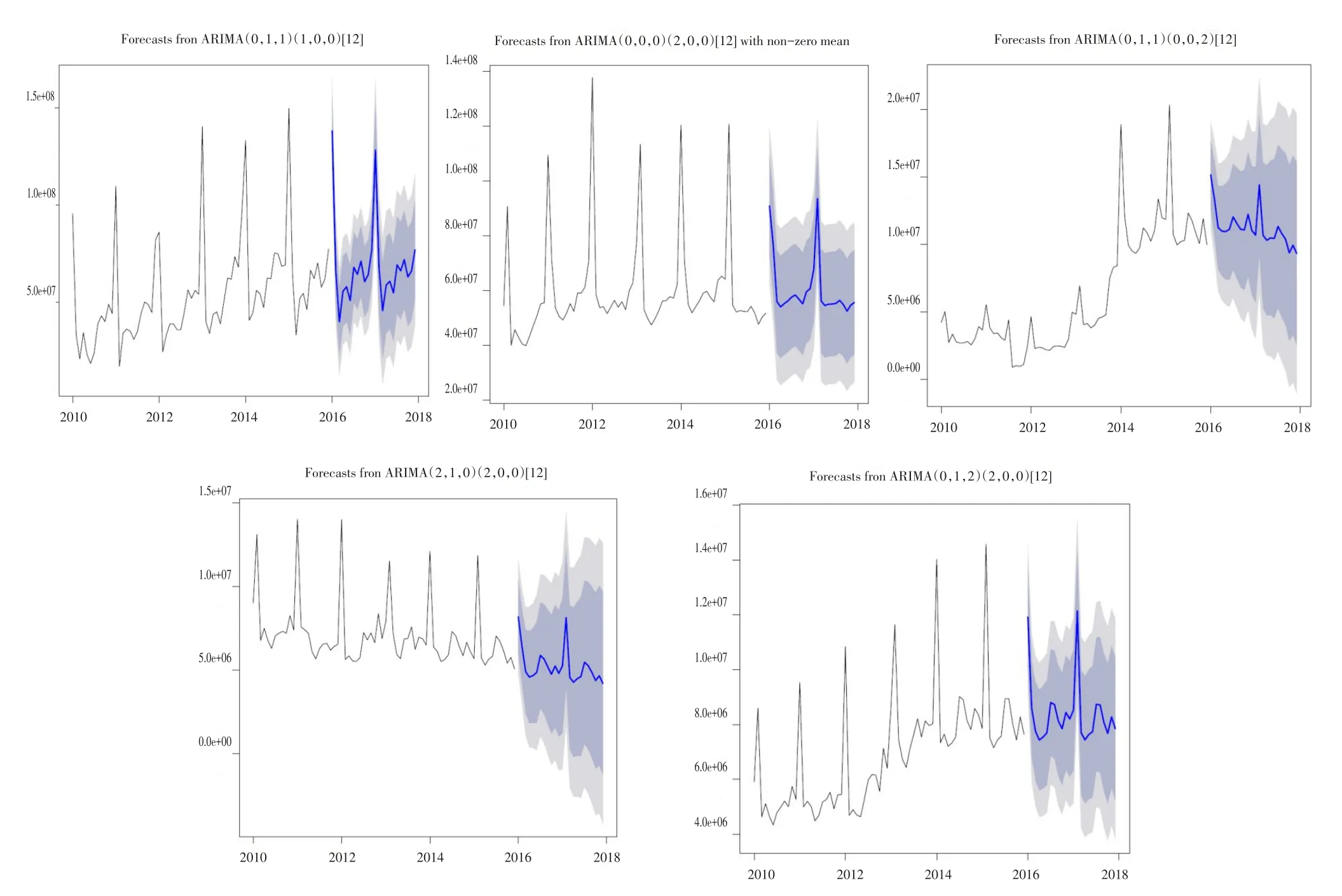
图5 企业分区域销售总量预测图
6 对企业下一年各月物流配置计划的建议
从某种意义上来说销售量是物流量的决定性因素,对销售量的准确预测也能在一定程度上对物流需求做出准确预判,下面根据预测的销售量来对该企业下一年的物流配置计划提出建议。
6.1 企业物流总量配置建议
从2016年全年销售额预测总量来看,比前一年稍有降低,考虑到误差的影响,全年物流配置计划应大致与去年物流总量相当。而具体到每个月的销售量预测值来看,一般会与实际值有8%以内的误差,为了保险起见,在每月还应做好与预测值误差在10%以内的额外物流预案。
6.2 各区域月物流量配置建议
不同区域的物流配置比重取决于该区域的销售额和该区域与物流中心的距离。首先根据各区域月销售额预测数据在企业月销售总额中所占比重来初步计划每月各区域物流配置比重。不同区域物流配置初始比重见表4。
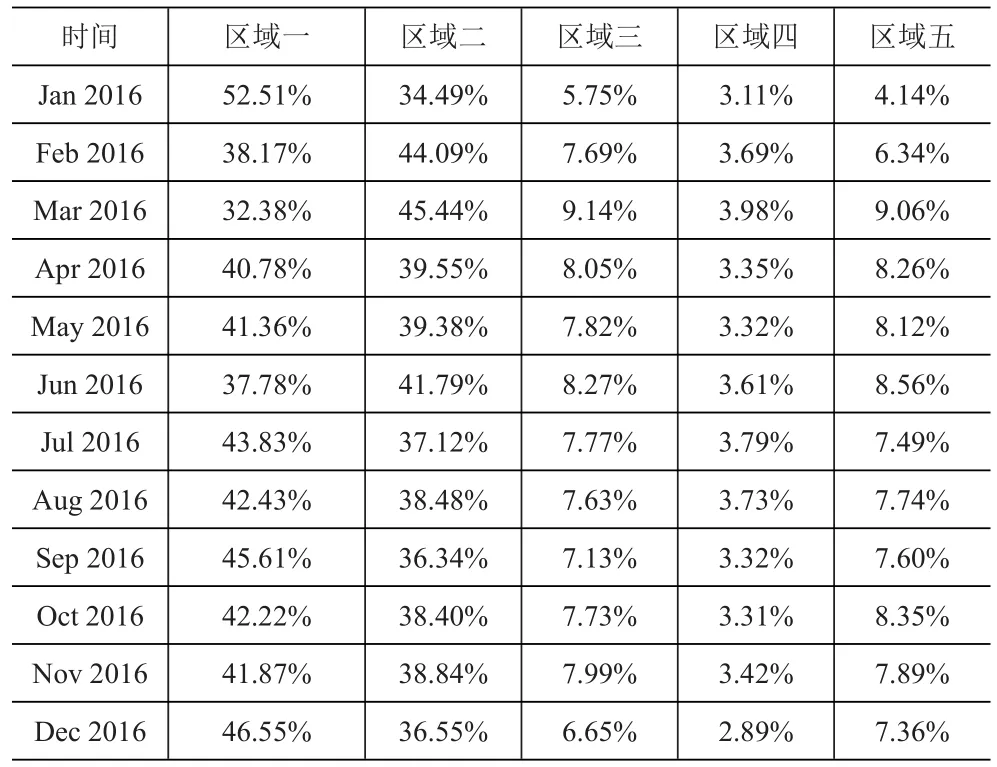
表4 企业分区域2016年月物流配置初始比重表
考虑运输距离对物流成本的影响,由于该企业物流中心设在成都,设各个区域与成都地区之间距离对物流成本的影响因子为δi,i=1,2,...,5,其中δ1=1为成都对成都的影响因子,λ为单位商品基础货运费,Lj,j=1,2,...,12为该企业每月物流计划总费用,θij,i=1,2,...,5,j=1,2,...,12为不同区域每月物流配置初始比重。经过调整之后物流配置比重计算公式如下:
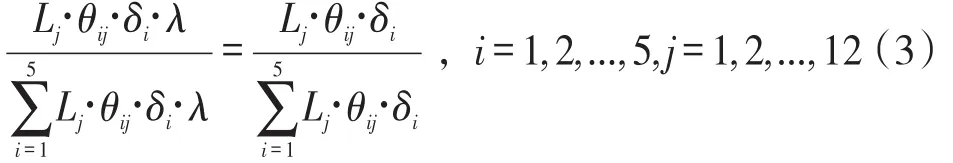
由于影响δi(i=1,2,...,5)的因素众多,又缺少相应的物流数据,仅从距离和门店数量等因素出发初步测算取δ2=δ3=δ4=δ5=3,代入上式求得调整之后的物流配置比重,见表5。
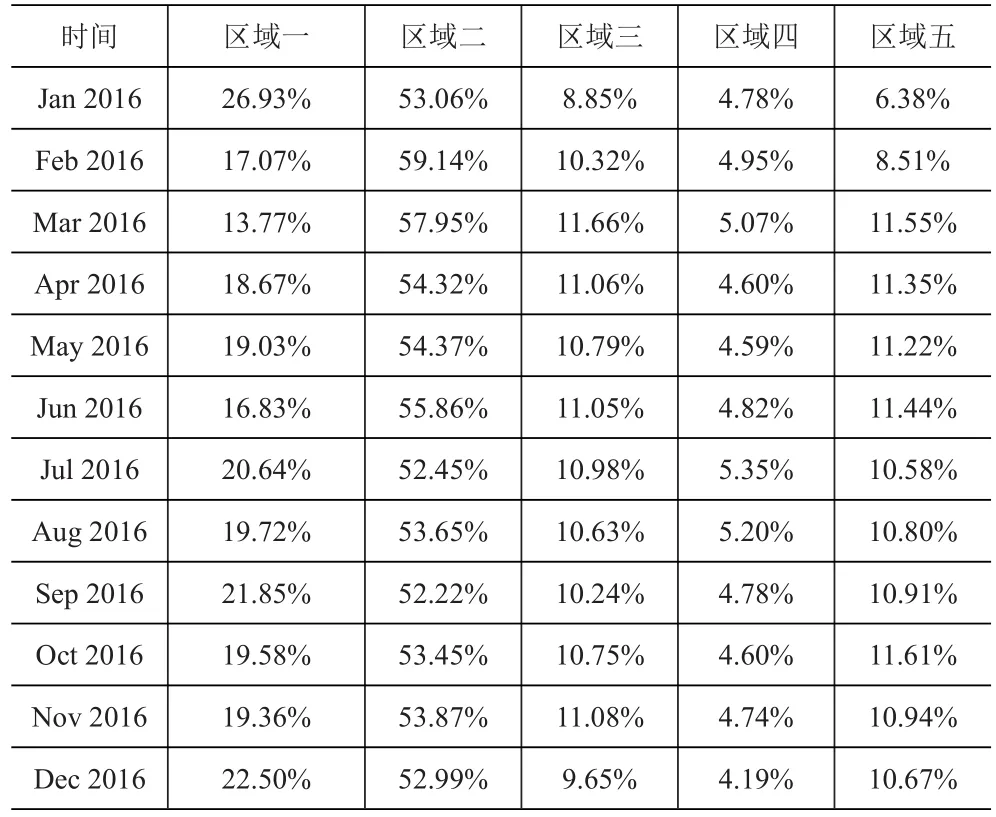
表5 企业分区域2016年月物流配置比重调整表
表5只是各月物流配置比重的初步预估表,它需要随着每月不同区域的实际销售额与预测值之间的误差进行调整。
7 研究展望
利用时间序列建立的ARIMA模型简单易懂,易于推广,只需了解简单的统计知识和相关统计软件的基本操作就能在不同企业内部对各项时间性质的数据进行分析。本文从销售额的历史数据出发,研究销售额与时间之间的变化规律,并进一步对和销售额直接相关的物流需求进行预测,这样就省去了分析诸多影响物流需求因素的麻烦。在该模型的基础之上,我们还可以做很多后续的研究工作。
(1)本文研究企业的物流业务仅针对企业内部的商品货物,而对于市场上大部分为不同企业居民服务的纯物流公司也可以找到其他数据代替物流数据来进行预测,如各区域派单数量等。
(2)如果能找到商品的相关信息等数据,可以将商品类别再细分,如将商品连同包装的大小和价格换算成商品的平均密度,即单位体积商品的价格,这样能对区域物流需求进行更准确的预测。
(3)条件允许的话可以在时间和空间上对物流需求进一步细分。像文中这类仅在省内小区域范围内进行物流配送的企业,在物流配置计划上可以制定周计划甚至日计划。也可以在大区域范围再进行更小区域的划分去制定物流配置计划,这样能让这类企业的物流工作更有效率。
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化·高二版(2022年4期)2022-05-09
家庭影院技术(2021年6期)2021-07-28
汽车维修与保养(2021年8期)2021-02-16
玩具世界(2020年1期)2020-08-26
销售与市场·管理版(2020年8期)2020-08-25
房地产导刊(2020年5期)2020-06-24
汽车维修与保养(2020年11期)2020-06-09
