
基于Hadoop的工业大数据存储分析系统
2020-08-16 13:53范旭辉
科技创新与应用 2020年23期
范旭辉


摘 要:工业大数据具有规模庞大、业务复杂等的特点,为数据存储、查询和分析计算带了难度。为了优化工业大数据存储管理,提高系统存储、查询、分析效率,利用基于Hadoop技术针对业务库和实时监控数据库的存储管理进行优化。系统设计业务库的集群化同步存储架构,基于Maxwell组件将MySQL业务库数据实时同步到HBase,实现业务库的读写分离、提高数据查询和数据分析的效率;其次,基于Kafka和Flink对业务库同步数据进行实时计算处理,实现高并发数据写入场景下的低延迟响应;最后,实验进行了HBase和MySQL的性能对比测试,结果表明本系统在大规模数据场景下具有更好的计算效率表现,能够有效进行工業大数据分析存储。
关键词:工业大数据;Hadoop;Flink;HBase
中图分类号:TP311.13 文献标志码:A 文章编号:2095-2945(2020)23-0018-04
Abstract: Industrial big data has the characteristics such as large scale and complex business, which makes it difficult for data storage, query, analysis and calculation. In order to optimize the storage management of industrial big data and improve the efficiency of system storage, query and analysis, the storage management of business database and real-time monitoring database is optimized based on Hadoop technology. The system designs the clustered synchronous storage architecture of the business library. Based on the Maxwell component, the MySQL business library data is synchronized to HBase in real time to achieve the read-write separation of the business library, improve the efficiency of data query and data analysis. Based on Kafka and Flink, real-time calculation and processing of synchronous data in the business database are carried out to realize low latency response in the scenario of high concurrent data writing. Finally, the experiment conducted a performance comparison test of HBase and MySQL, which shows that the system has better calculation efficiency performance in large-scale data scenarios, and can effectively analyze and store industrial big data.
Keywords: industrial big data; Hadoop; Flink; HBase
引言
工业数据的存储分析是工业信息化应用、推进智能制造的前提和基础[1],然而工业数据的海量性、增量性为其的存储管理带来了难度,同时也对数据存储的可拓展性、高效性提出了高要求[2]。目前,大多工业信息系统[3-4]通过结构化数据库如MySQL等进行数据存储。面对频繁读写的应用服务,有研究[4]通过备份同步业务库,实现读写分离的架构,从而减轻数据库压力。然而,这种存储管理方式对于复杂业务表的数据分析方面并不友好,需要通过垂直切分或者水平切分进行数据查询。
大数据存储系统HBase是一种分布式的列式数据库,针对复杂业务的分析具有天然的优势,被广泛地应用在数据存储和分析过程中[5-8]。然而,HBase的存储应用很难直接切入到现有系统中,或是需要将整套技术方案推翻重来。同时,不同于普通应用系统,工业数据因其特殊的应用场景会产生大量的实时监控数据[2],如设备、仪表、定位等。这些实时增量不断增长的时序数据为数据存储的效率提出了要求。此外,在数万台机器毫秒级监控的场景中,服务器每秒需要处理GB级的数据,传统通过负载均衡进行实时计算的处理方式已经达到瓶颈。
为此,本文提出了一种工业大数据存储管理与分析系统,基于Hadoop平台构建数据存储平台,通过Maxwell实时读取MySQL的数据日志写入Kafka消息队列,并通过Flink消费处理同步到HBase,在不影响当前系统业务库的同时提高数据查询和存储管理效率。
1 相关工作
1.1 Hadoop平台简介
从狭义上来说,Hadoop[5-8]是一个由Apache基金会所维护的分布式系统基础架构,而从广义上来说,Hadoop通常指的是它所构建的Hadoop生态,包括Hadoop核心技术以及基于Hadoop平台所部署的大数据开源组件和产品。这些组件实现大数据场景下的数据存储、分布式计算、数据分析、实时计算、数据传输等。
Hadoop的核心技术:HDFS、MapReduce、HBase被誉为Hadoop的三驾马车,更为企业生产应用带来了高可靠、高容错和高效率等特性。其中,HBase是一个可伸缩、分布式、面向列的数据库,和传统关系数据库不同,HBase提供了对大规模数据的随机、实时读写访问,同时,HBase中保存的数据可以使用MapReduce来处理,它将数据存储和并行计算完美地结合在一起。
1.2 Flink引擎简介
Flink[9]是一个基于内存计算的分布式计算框架,通过基于流式计算模型对有界和无界数据提供批处理和流处理计算。在实时计算方面,相比于开源方案Storm和Spark Streaming,Flink能够提供准实时的数据计算,并能够将批处理和流处理统一,实现“批流一体”的整体化方案。这种架构使得Flink在执行计算时具有较低的延迟,Flink被誉为继Hadoop、Spark之后的第三代分布式计算引擎。
1.3 Maxwell简介
Maxwell是一个能实时读取MySQL二进制日志binlog、并生成json格式的消息,作为生产者发送给Kafka、RabbitMQ、Redis、文件或其它平台的应用程序。目前,常用的binlog解析工具还有canal、MySQL_streamer,canal由Java开发,性能稳定,但需要自己编写客户端来消费canal解析到的数据;MySQL_streamer由Python开发,但其技术文档比较粗略,对开发过程并不友好。
2 系统总体设计
系统架构设计:为了实现大规模工业数据的高效存储,设计基于Hadoop的工业大数据存储管理系统总体架构,共包括前端集群、后端业务集群和数据计算集群,具体存储系统架构如图2所示。
系统主要采用前端界面和后端业务分离的思想,在前端集群中,由Nginx负责请求的反向代理和负载均衡,分别指向静态文件服务器或Web服务器,实现网页相关界面的显示与交互。前端集群通过远程调用的方式与后端业务集群进行通信,实现相关业务操作、MySQL数据库交互操作、数据计算与结果缓存到Redis等操作。对于后端业务操作中的数据计算环节则由数据计算集群负责,如:实时同步业务库、设备数据实时计算等。
在数据计算集群中部署了Hadoop平台(HDFS、HBase、Yarn)以及Flink、Kafka、Zookeeper等组件。其中HDFS负责进行底层数据的存储,具体由HDFS的DataNode进行文件分片多备份存放,由NameNode进行元数据管理和文件操作管理,同时通过Zookeeper注册两个NameNode并实时监控状态,防止一方故障立即切换到另一个,从而保证NameNode的高可用性。HBase负责对同步业务库和时序数据库进行存储,由HMaster管理多个RegionServer进行数据维护和查询,底层由HDFS进行存储。对于实时计算部分通过Kafka Broker接受Kafka生产者生产的实时消息,再通过Kafka消费者Flink进行处理计算,其中Kafka的生产、消费进度由Zookeeper进行记录。Flink不仅提供实时计算,同时提供离线批量计算,其计算过程通过Yarn申请计算资源,具体由ResourceManager管理资源并分配到NodeManager上进行计算。
3 工业大数据存储管理系统
3.1 基于Maxwell的业务库同步设计
为了缓解基础业务库的读写压力,提高复杂业务表的查询分析效率,系统利用Maxwell实时监听MySQL的binlog日志,然后解析成json格式发到消息队列Kafka,再通过Flink消费Kafka数据存储到HBase,从而供其他后端分析业务进行读取、查询。基于Maxwell的业务库同步设计具体过程如图3所示。
其具体实现步骤如下:
(1)编辑MySQL配置文件my.cnf,开启binlog功能;
(2)创建Maxwell用户并赋权限;
(3)启动Kafka集群;
(4)修改Maxwell的config.properties文件,配置MySQL数据库连接信息、配置producer类型为Kafka、配置Kafka集群连接信息和topic、配置同步业务库信息;
(5)启动Maxwell,开始监听;
(6)创建Flink消费Kafka任务,对Maxwell产生的数据进行实时处理写入HBase。
3.2 基于Kafka和Flink的实时计算
对于实时同步的MySQL业务库binlog数据,Maxwell首先進行解析传入Kafka消息队列,然后通过Flink对这些实时产生的业务库同步数据进行消费,实现写入HBase中。具体步骤包括:
(1)在Kafka中创建消息订阅主题“maxwell”,定义副本数2个,分区数9个。Maxwell作为生产者对MySQL的binlog文件进行解析成json格式数据,再发送到“maxwell”这个主题下。
(2)服务器端配置连接信息,包括:Flink流式处理环境、Zookeeper的集群信息、Kafka集群信息、消费者组信息、数据格式等。
(3)通过Kafka Flink Connector API创建线程池对接Kafka,将Maxwell的同步数据实时写入HBase。通过Flink的DataStream算子的map过程处理每一条消息,分别调用HBase API执行数据写入操作。
4 系统实现
4.1 集群环境部署
系统在1个主节点、6个计算节点上搭建Hadoop集群,同时部署MySQL主备节点、Kafka、Flink、Maxwell等组件。各节点配置包括:CentOS 7.3 64位操作系统、Intel(R) Xeon CPU 2.4GHz 4Core的CPU、24GB内存、1TB硬盘,Hadoop版本为Hadoop 2.6.0,Flink版本为Flink 1.9.0,MySQL版本为MySQL 5.6。
4.2 性能测试
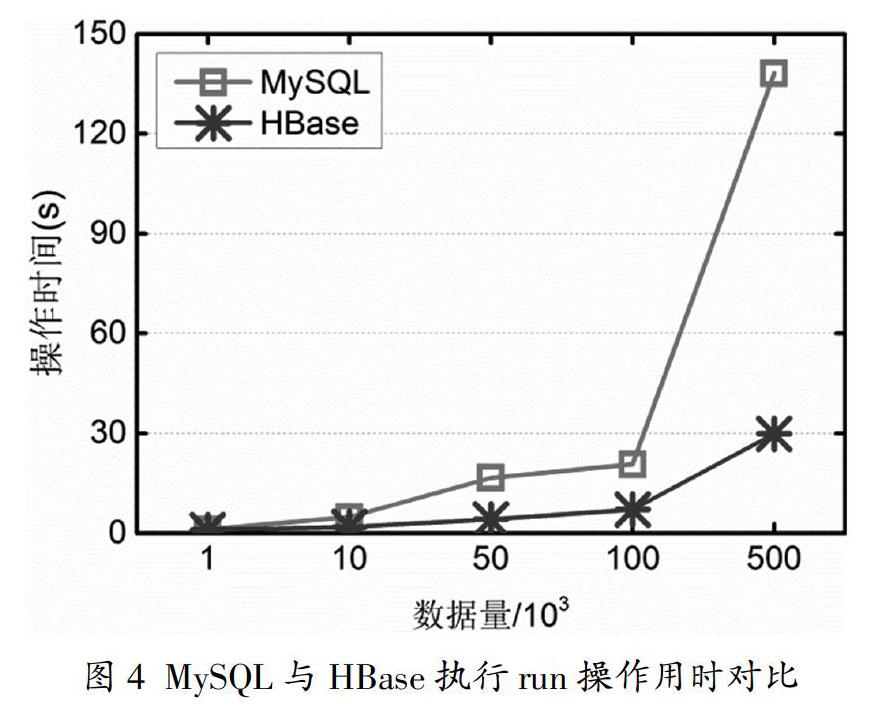
系统采用HBase存储业务同步库面向数据查询和分析,因此,在性能测试方面针对HBase的数据查询性能进行实验。如图4所示为不同数据量情况下执行run操作时MySQL和HBase的耗时对比。
在数据量比较少的情况下,MySQL与HBase所用时间相当,但随着数据量的增长,HBase和MySQL的处理时间产生越来越大的差距,且HBase具有更低的处理延迟。
如图5所示为向HBase与MySQL中插入数据时总吞吐量的对比。当数据量较小,MySQL吞吐量较HBase更大;当数据量较大,HBase的吞吐量相比MySQL更优,且随着插入数据量规模的增大,MySQL的吞吐量逐渐变小并趋于平缓达到瓶颈,而HBase在数据规模增大的同时具有更大的数据吞吐量。因此,在处理大规模数据插入场景中,HBase相较MySQL更具优势。
5 结束语
本文基于Hadoop技术实现对工业大规模数据进行存储管理,对业务库和实时监控数据库的存储管理进行优化。设计业务库的集群化同步存储架构,对存储在MySQL中的业务数据进行实时同步到Kafka;基于Flink对业务库同步数据进行实时计算处理,实现高并发数据写入场景下的低延迟响应;最后,实验进行了HBase和MySQL的性能对比测试,结果表明本系统在大规模数据场景下具有更好的计算效率表现,能够有效进行工业大数据分析存储。
参考文献:
[1]刘祎,王玮.工业大数据时代技术示能性研究综述与未来展望[J].科技进步与对策,2019,36(20):154-160.
[2]何文韬,邵诚.工业大数据分析技术的发展及其面临的挑戰[J].信息与控制,2018,47(04):398-410.
[3]黄新波,张瑜,朱波.智能变电设备监控与决策辅助系统数据库的设计与实现[J].高压电器,2016,52(03):15-22.
[4]王瀚哲,杨超宇,梁胤程.煤矿作业规程管理系统设计及关键技术研究[J].中国煤炭,2014,40(12):71-74+95.
[5]张华伟,陈勇,李海斌,等.基于HBase的工业大数据时序数据存储实现[J].电信科学,2017,33(S1):21-27.
[6]孟祥曦,张凌,郭皓明,等.一种面向工业互联网的云存储方法[J].北京航空航天大学学报,2019,45(01):130-140.
[7]赵亚楠,李朝奎,肖克炎,等.基于Hadoop的地质矿产大数据分布式存储方法[J].地质通报,2019,38(Z1):462-470.
[8]郑柏恒,孟文,易东,等.在Hadoop集群下的智能电网数据云仓库设计[J].制造业自动化,2014,36(19):134-138.
[9]代明竹,高嵩峰.基于Hadoop、Spark及Flink大规模数据分析的性能评价[J].中国电子科学研究院学报,2018,13(02):149-155.
