
ALEAP模型在WAF场景下的应用研究
2020-09-02 07:00范舒涵王之梁杨家海
网络空间安全 2020年7期
范舒涵 王之梁 杨家海


摘 要:文章探究基于深度学习的事件预测模型ALEAP在WAF场景下的应用情况,通过对校园网WAF系统日志数据的统计分析和事件嵌入分析,发现Web攻击事件分布上的聚集性以及上下文之间的关联性;通过WAF历史日志数据对ALEAP模型进行预训练,利用预训练模型预测下一个可能发生的Web攻击事件,模型最终达到78%的预测准确率,证实了ALEAP模型在该场景下的适用性,为网络管理者实施防御策略提供可靠性参考依据,同时也说明ALEAP模型在具有上下文关联关系的安全日志事件预测方面的普适性。
关键词:安全事件预测;Web应用防火墙;ALEAP
中图分类号: TP309.5 文献标识码:A
Abstract: This paper explores the application of ALEAP, a security event prediction model based on deep learning, in the WAF context. Web Application Firewall, or WAF in short, is a kind of middlebox for protecting Web application security. The WAF system logs of the data center of Tsinghua campus network are analyzed by statistical methods and the ALEAP is used to predict the next web attack event. ALEAP is proved effective in this scenario with as high accuracy as 78%. It also shows the universality of ALEAP in context-sensitive security log prediction.
Key words: security events prediction; Web application firewall; ALEAP
1 引言
隨着网络渗透门槛的不断降低,常规网络攻击事件如SQL注入、跨站脚本攻击、会话劫持等频频发生。在过去,防火墙被视为企业安全保障的第一道防线,能在网络层进行数据包的有效阻断。然而随着越来越丰富多样的Web应用诞生,Web应用成为主要被攻击的目标。传统防火墙在阻止利用应用程序漏洞进攻方面却无能为力。在大型组织中,许多Web应用程序需要不同的安全策略来保护它们免受各种攻击。因此,Web应用防火墙(Web Application Firewall,WAF)[1]应运而生。
WAF通过执行一系列针对HTTP、HTTPS的安全策略,为Web应用程序提供保护。对于网络安全管理人员来说,WAF能够对部分网络协议通信流量进行检测识别,屏蔽常见的Web攻击行为,阻止对Web应用的非法访问,增强Web应用的安全性。不足在于,WAF通过对一系列网络请求的内容进行规则模式匹配检测出异常情况,是一种被动的反应,是在异常行为发生后,对特定攻击模式的反应或者针对观察到的现象进行告警,无法预测可能发生的攻击,进一步为网络安全管理人员提供防御意见和攻击趋势预警。
ALEAP[2]是在2019年提出的基于深度学习的安全事件预测模型,基于安全防护终端日志中的安全事件之间存在上下文关联,通过对历史安全事件的攻击模式学习,预测下一个可能发生的安全事件。
通过对WAF数据观察可知,WAF日志记录中的Web攻击事件之间同样存在上下文关联。因此,使用ALEAP对WAF日志数据进行攻击模式学习,预测下一个可能发生的Web安全事件,使得网络安全管理人员能够提前采取防御措施,避免不必要的伤害是可行的。
本文基于对清华大学WAF防护系统日志数据的分析,探究ALEAP模型在该场景下的应用效果,并对其性能进行评估。
2 ALEAP模型
ALEAP模型是一个基于深度学习[3]的安全事件预测模型,适用于已知多种安全防护设备产生的警报日志,预测下一步可能发生的安全事件类型,在网络管理者实施防御策略时提供可靠性参考依据。
2.1 研究的问题
ALEAP模型公式化描述为:
已知条历史安全事件序列,其中表示输入序列长度,表示安全事件的事件嵌入向量维度,表示时刻的安全事件嵌入向量。
ALEAP旨在通过历史数据的训练,学习历史事件序列到下一个可能产生的安全事件类型的关系映射:
其中,,是需要学习的非线性映射关系。
2.2 ALEAP系统框架
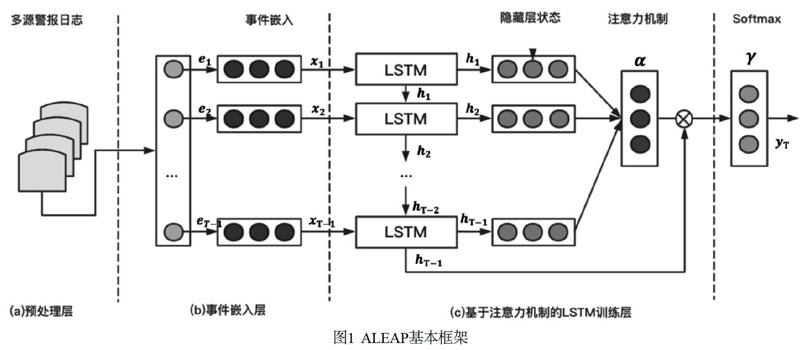
ALEAP模型框架如图1所示,包括数据预处理层、事件嵌入向量构建层、基于注意力机制的LSTM模型学习层和预测层。在数据预处理层中,如图1(a)所示,首先从多源安全警报中提取出数据特征,包括匿名计算机ID、时间戳、安全事件ID、安全事件描述等信息,而后从这些数据特征中提取“攻击者、被攻击者、攻击行为、补充行为”四个特征组成四元组,构建新型安全事件类型。在图1(b)所示的嵌入层中,通过上下文关联学习,将安全事件类型嵌入到高维度的向量空间,用于反映事件之间的相似性和互异性。基于注意力机制[4]的深度学习模型如图1(c)所示,编码序列化的注意力机制能够在所有事件序列中,自动学习增加相关性高的隐藏状态的权重,从而捕获到长期的事件序列依赖,以达到更高的预测准确性。
3 ALEAP在WAF场景下的应用
WAF通过对一系列网络请求的内容进行规则模式匹配、行为分析,检测出恶意行为,并做出相关动作,包括阻断、记录、告警等,为Web应用程序提供保护[5]。
通过对WAF日志的观察可知,WAF日志中记录了跨站脚本(Cross-site Scripting, XSS)、SQL注入攻击、Web服务器漏洞攻击等攻击行为,针对某个攻击,存在一定的攻击链。比如,SQL注入主要攻击步骤包括恶意扫描、在发送给SQL服务器的输入参数中注入恶意可执行代码、SQL注入攻击成功等。同时由于WAF规则设置的不同,对某些检测到的攻击流量采取阻塞的方式,因此这些被阻塞的攻击事件之间存在攻击尝试链,比如存在PUT、OPTIONS、DELETE不同请求方式的连续HTTP访问控制事件。由此可见,Web攻击事件之间也存在着上下文联系,满足符合ALEAP模型的使用前提。
通过对WAF日志的统计分析、事件嵌入式分析和ALEAP模型的应用,进一步挖掘WAF数据的隐藏价值,探究其所在网络环境态势以及攻击规律。
3.1 WAF日志数据统计分析
研究数据采自于清华大学WAF系统安全防护日志2019年11月21日至2019年11月27日时长为一周的日志数据,共计3,214,041条记录,18种安全事件过滤规则。
3.1.1 基础数据特征
(1)日志字段
采集到的WAF日志一共有个18字段,其中关键字段以及说明如表1所示。在对数据进行处理的时候,需要根据站点ID对数据进行分类,根据告警发生的时间排序,并主要关注于告警类型的变化。
(2)攻击事件类型分布
本文研究的WAF日志中一共有18个事件类型,包括SQL注入攻击、Web服务器漏洞攻击等。事件分布情况如表2所示。
由表2可知,在该数据集中,最频繁发生的攻击是SQL注入、Web服务器漏洞攻击以及远程文件包含攻击。不同的事件类型归属于不同的攻击阶段,比如恶意扫描可以是跨站攻击的前期准备阶段,SQL注入攻击可能是服务器信息泄露的后续。不同事件之间存在一定的关联性,也说明了Web应用防火墙产生的数据符合ALEAP模型的应用场景。
3.1.2 日志记录特征
(1)重复性
清华校园网WAF系统日志数据针对一类警报类型,往往出现连续重复的日志记录。通过对数据集的观察可知,这些连续出现的警报类型相同的记录并不完全相同,一般存在URI、Domain Name、HTTP Request Method三个字段的区别。因此,这些字段在区分不同的攻击行为,构建安全事件类型中起到重要作用。同时这也意味着,在发起Web攻击时,攻击者通过改变攻击路径、攻击对象和请求手段等方式进行多种攻击尝试。
(2)关联性
WAF对被检测到的异常事件的处理手段主要包括三种:拦截、记录但不拦截、放过,采用何种处理手段取决于规则对应攻击的危害性。如果是明显攻击,就配置拦截手段,可疑行为配置记录但不拦截处理手段,正常行为采用放过的处理方式。
通过对采集到的日志数据进行观察,发现数据记录中存在拦截、记录但不拦截两种处理手段。记录但不拦截的处理方式可以记录一个多步攻击的攻击链,拦截的处理方式意味着某些数据之间并不存在攻击链行为。如表3所示。
从表中可以很明显发现攻击者在某次请求被拦截之后,还是针对同样的攻击发起了不同攻击路径、不同攻击子对象、不同HTTP请求方式的攻击尝试,这些尝试之间也存在一定的规律。比如攻击路径可能是在原来的路径的基础上添加新的根目录,或者攻击的域名和前一个域名之间享有同样的一级、二级子域名。所以,针对WAF日志的预测模型训练可以学到两类模式:Web攻击链以及Web攻击尝试链。
3.2 事件嵌入分析
这一小节利用事件嵌入(Event Embedding)对WAF日志事件进行深入分析。通过事件嵌入的使用,主要研究两项内容。
(1)探索安全日志事件上下文之间存在的内在联系。确认向量近似度大的事件在语义上是相关的,从而证明事件嵌入被其他模型引入是有价值的。
(2)从全局上查看嵌入向量的空间分布以及聚合关系。
3.2.1 算法原理
事件嵌入來源于自然语言处理(Natural Language Processing, NLP)中适用的词嵌入(Word Embedding)[6]。词嵌入的训练原理就是利用一个深度学习框架将一个词语映射到另一个空间,并且保证相似的词语映射到相似方向,而且低维度、易训练。Word2vec[7]是词嵌入中的一种,也是目前最广泛的词嵌入方法,其训练简单,具有速度快、易扩展、效果好的特点。
在网络安全领域中,安全日志事件之间存在着和自然语言处理领域的单词之间同样的上下文关系。所以,将单词之间的关联关系抽取方法类比到安全事件之间,用事件ID来代表某个安全事件,替换自然语言中的单个词语,采用类似的词嵌入方法对安全事件进行向量表示,这个算法称之为事件嵌入。
因此,本节采用事件嵌入方法对WAF攻击的内部关联进行深入机器学习和分析。
3.2.2 实验
本次实验的事件嵌入算法采用Word2Vec中的Skip-gram[8]模型进行训练,选择2019年11月21日至11月26日的数据,最终产生每个事件的向量嵌入式表示。
主要实验共四个步骤。
(1)首先,对日志数据进行预处理。将发生在同一天同一个目标ID上的事件合并为一段连续事件序列,同时对完全重复的连续日志事件进行合并,即只记录一条数据。
(2)构建新型安全事件ID。新型安全事件类型用以下五元组来表示:
每个安全事件类型对应唯一ID。
(3)依次遍历所有事件ID,以每个事件ID为中心事件,选择其前后固定长度范围内的事件ID作为模型输入,利用Skip-gram模型进行训练,训练拟合得到中心事件。其中,中心事件往前/后的固定长度范围被称作训练窗口。
(4)最后把输出层去除,选择输入权重矩阵作为最终采用的事件向量集合,同时用Numpy格式存储。
通过多次实验,选用以下参数作为最终采纳的预训练向量模型参数:生成向量维度为300,训练窗口为10,迭代次数为40,采用Negative Sample算法。
3.2.3 结果展示
为了进一步研究生成的事件向量,本文通过计算嵌入式向量之间的相关性并利用Google Projector[9]对事件向量进行可视化处理来深入研究内在规律。
(1)事件向量相关性
通过计算安全事件向量之间的余弦相似度,来量化向量之间的相关性。所谓余弦相似度,就是计算两个向量在向量空间夹角的余弦值,如果值越大表示两个向量越相近,如式(1)所示:
表4为通过Skip-gram方法训练生成日志事件向量后,与事件[166.111.7.8, 10.111.7.157, Web服务器漏洞攻击,ap*.sc.tsinghua.edu.cn, POST]通过计算向量间的余弦相似度得到的结果。由表可知,和事件“Web服务器漏洞攻击”相似度最高的前三个事件都拥有同样的攻击者、被攻击对象、被攻击域名和请求方式。同时,通过对原始数据观察可以发现,与事件“Web服务器漏洞攻击”相似度最高的事件“HTTP违背”的攻击序列中,都存在连续地对不同域名的攻击尝试(例如,对www.m*.tsinghua.edu.cn,www.e*.tsinghua.edu.cn,www.c*.tsinghua.edu.cn等域名的连续攻击)。由此可见,嵌入式事件向量表示反映了一部分事件之间的攻击规律和关联性。
(2)向量降维可视化
Google Projector是一个用户交互式的可视化和高维数据分析的系统,可用于探索数据集中的有价值方向。
本文通过将事件向量和事件标签分别上传至Google Projector,生成如图2所示的投影。
图2是利用t-SNE[10]降维技术生成的嵌入式投影。t-SNE是一种流行的非线性降维技术,由Hinton等人提出,基于SNE演变而来。SNE采用仿射变换,通过构建一个高维度对象的概率分布,映射数据点到概率分布上,如果两个对象越相似,被选择的概率就越高。t-SNE使用对称版的SNE,简化梯度公式,同时使用t分布代替高斯分布来表达两点之间的相似度。
由图2可知,事件被分为两个部分。绿色虚线簇主要包含攻击前期准备事件,包括HTTP方式控制事件、远程文件包含、违规下载、恶意扫描等;橙色虚线簇包括各类攻击:SQL注入攻击、跨站攻击、命令注入攻击等。通过对选取的WAF事件向量表示的可视化处理,一方面说明了WAF日志事件主要包括攻击链的两个阶段:前期准备和攻击执行。在这两个阶段中,前期准备的事件规模相对小,分布也相对集中,Web攻击执行阶段中包含各类不同类型、不同模式的攻击类别;另一方面也证实了事件向量可以很好地提取事件特征,表示事件间的关系。
(3)小结
通过上述研究,得到两点结论。
1)清华校园网WAF系统日志事件主要可以分为2个团簇,包括攻击前期准备阶段和攻击实施阶段。同时,攻击前期准备事件的类型数目小于攻击实施事件类型数,并且聚集性更大。
2)采用Word2Vec方式可以很好地反映安全事件之间的上下文关联性和相似性,有利于后续预测算法的构建。
3.3 ALEAP模型应用
基于对WAF数据的基础数据统计和分析观察,发现WAF日志数据存在上下文关联,适合ALEAP模型的使用场景。同时,对于WAF日志数据的预警,可以揭露特定网络环境中的Web攻击规律,对网络管理员的提前防御起到很好的参考作用。因此,将对安全预测模型ALEAP在清华校园网WAF日志数据中的应用做进一步分析。
3.3.1 数据预处理
在3.1.2小节中提到WAF数据的特有规律,因此在ALEAP模型预处理的基础上,需要针对其数据特征做出以下變种。
在构建新的安全事件类型时,由于在Web攻击中,被攻击的域名和HTTP请求方式是一个攻击手段的重要特征,可以更好地区别不同的攻击行为。因此,原模型的四元组[subject, object, action, other]中,需要用[domain, request_method]来具体表示other字段,也就是新的安全事件类型用五元组来表示:
最终生成86类新型日志事件。同时,该安全事件类型与3.2.2小节安全事件向量构建实验中输入的事件类型保持一致。
3.3.2 实验结果
本文使用Python 3.6.6实现了所提出的方法,并采用了Skip-gram进行安全事件嵌入向量生成。选择2019年11月21日至2019年11月26日数据进行训练,2019年11月27日至2019年11月28日数据进行预测,训练集和预测集比例大约为4:1。
通过多次对比实验,本文选择以下参数作为最佳解决方案:批大小为128,嵌入维数为300,隐藏维数为600,隐藏层数为2,初始学习率为0.001,学习率衰减为0.01,间隔大小为15,Dropout值为0,训练轮数上限为500,模型最终取得了78.25%的预测准确率。
(1)输入序列长度对实验结果的影响
在实验中,本文主要针对不同的序列长度大小做了对比实验,结果如图3所示。
可以看出,当训练序列长度小于15时,随着序列长度的增大,预测结果越准确,说明越长的训练数据可以提供更多的攻击相关的信息,对模型拟合起到促进作用。当序列长度大于25时,精确度呈下降趋势,说明当训练窗口大于25时,引入了不相关的数据。同时随着训练序列增长,训练时长也增大。综合训练准确率和训练代价,本文选择20为最佳训练序列长度。
(2)预测结果分析
该模型在WAF数据中取得了78.25%的预测准确率。通过对预测结果的观察,发现两点情况。
1)在预测正确时,主要分为两种情况。第一种是攻击链预测成功。攻击链预测成功示例如表5案例1所示。案例1通过历史安全日志事件中恶意扫描、服务器信息泄露、远程文件包含等恶意行为成功预测出将要发生的XSS攻击,此时可联系网站开发者对网站进行“查缺补漏”,过滤恶意代码,对HTML进行充分转义。
预测正确的另一种情况是攻击尝试链预测成功,如表5案例2所示。通过对域名a*.tsinghua.edu.cn和zlsh.a*.tsinghua.edu.cn等的HTTP访问控制事件的尝试,ALEAP模型成功预测出了将对www.a*.singhua.edu.cn域名的HTTP访问控制事件的发生。攻击尝试链路的预测成功能够有效描绘攻击链路和剖析攻击意图,更好地服务于网络管理者对网络态势的直观了解。
2)在预测错误的情况下,有部分错误情况虽然预测与实际不符,但是仍存在一定的关联性。如表5案例3所示,预测事件是对域名www.m*.tsinghua.edu.cn发起的服务器信息泄露事件,而实际发生的事件是针对irb.m*.tsinghua.edu.cn的服务器信息泄漏事件。虽然受害域名预测错误,但是攻击事件类型预测成功,并且两个域名只有第五级子域名的细微差别。说明该预测模型即使在预测错误的情况下,也能在某种程度上提供有效信息。
由上可知,ALEAP模型在WAF日志数据场景中,能够学到一定的攻击模式或者攻击尝试模式,可以很好地在WAF攻击场景下进行安全事件预测。说明ALEAP适用于Web攻击场景。
4 结束语
本文通过ALEAP模型在清华校园网WAF场景下的应用,发现WAF数据本身存在的关联性和聚集性,同时,ALEAP在该场景下能到78%的预测准确率,体现了ALEAP模型在具有上下文关联关系的日志预测方面的普适性。
参考文献
[1] Clincy V, Shahriar H. Web application firewall: Network security models and configuration[C]//2018 IEEE 42nd Annual Computer Software and Applications Conference (COMPSAC): volume 01. 2018: 835-836.
[2] Fan S, Wu S, Wang Z, et al. Aleap: Attention-based lstm with event embedding for attack projection[C]//2019 IEEE 38th International Performance Computing and Communications Conference(IPCCC). IEEE, 2019: 1-8.
[3] Deng L, Yu D, et al. Deep learning: methods and applications[J]. Foundations and Trends? in Signal Processing, 2014, 7(3–4):197-387.
[4] Bahdanau D, Cho K, Bengio Y. Neural machine translation by jointly learning to align and translate[J]. arXiv preprint arXiv:1409.0473, 2014.
[5] Ghanbari Z, Rahmani Y, Ghaffarian H, et al. Comparative approach to web application firewalls[C]//2015 2nd International Conference on Knowledge-Based Engineering and Innovation(KBEI). IEEE, 2015: 808-812.
[6] Bengio Y, Schwenk H, Senécal J S, et al. Neural probabilistic language models[M/OL].https://doi.org/10.1007/3-540-33486-6_6. Berlin, Heidelberg: Springer Berlin Heidelberg, 2006: 137-186.
[7] Goldberg Y, Levy O. word2vec explained: deriving mikolov et al.s negative-sampling word embedding method[J]. arXiv preprint arXiv:1402.3722, 2014.
[8] Mikolov T, Sutskever I, Chen K, et al. Distributed representations of words and phrases and their compositionality[C]//Advances in neural information processing systems. 2013: 3111-3119.
[9] Smilkov D, Thorat N, Nicholson C, et al. Embedding projector: Interactive visualization and interpretation of embeddings[J]. arXiv preprint arXiv:1611.05469, 2016.
[10] Maaten L v d, Hinton G. Visualizing data using t-sne[J]. Journal of machine learning research,2008, 9(Nov):2579-2605.
作者簡介:
范舒涵(1995-),女,汉族,福建建瓯人,清华大学,在读硕士;主要研究方向和关注领域:网络安全、深度学习。
王之梁(1978-),男,汉族,辽宁大连人,清华大学,博士,清华大学网络科学与网络空间研究院,副教授;主要研究方向和关注领域:互联网体系结构与协议、软件定义网络、网络测量与安全。
杨家海(1966-),男,汉族,浙江云和人,清华大学,博士,清华大学网络科学与网络空间研究院,教授;主要研究方向和关注领域:互联网体系结构与协议、网络管理、网络测量与安全。
