
基于文本挖掘技术的电力企业招投标智能审计探索与实践
2020-09-10 07:52王淼朱宇龙马博刘森黎晚晴
中国管理信息化 2020年14期
王淼 朱宇龙 马博 刘森 黎晚晴

[摘 要]随着信息技术的发展,电力企业招投标业务积累了大量信息数据。如何提升审计监督在数字化环境下发现问题的能力,揭示招投标过程中出现的违规行为,是审计人员必须解决的问题。本文基于文本挖掘技术,通过建立有效模型,识别招投标文件中存在的问题,极大提升了审计作业的智能化。
[关键词]招投标;审计;文本分析;非结构化数据;文本挖掘技术
doi:10.3969/j.issn.1673 - 0194.2020.14.038
[中图分类号]F239.1;TP317.1[文献标识码]A[文章编号]1673-0194(2020)14-00-04
0 引 言
经过多年的信息化建设,电力企业招投标业务基本实现了信息化管理,从招标方案到投标环节已全面实现线上信息化与电子化作业。电力企业每年大量的招标项目产生了海量的非结构化电子数据。对海量电子化数据进行招投标审计,传统的抽样审计与人工核查方法已完全无法适应当前的实际情况,探索新技术、新手段、新作业流程在招投标审计中的应用势在必行。
1 文本挖掘技术概述
文本挖掘指从大量文本数据中抽取事先未知的、可理解的、最终可用的知识的过程,同时运用这些知识更好地组织信息以供将来参考。文本挖掘的主要用途是从原本未经处理的文本中提取未知的知识,但是文本挖掘是一项非常困难的工作,因为必须处理那些本来就模糊且非结构化的文本数据,是一个多学科交叉领域,涵盖了信息技术、文本分析、模式识别、统计学、数据可视化、数据库技术、机器学习以及数据挖掘等技术。文本挖掘是从数据挖掘发展而来,定义与人们熟知的数据挖掘定义相类似。但与传统的数据挖掘相比,文本挖掘有其独特之处,主要表现在:文档本身是半结构化或非结构化的,无确定形式且缺乏机器可理解的语义;而数据挖掘的对象以数据库中的结构化数据为主,并利用关系表等存储结构发现知识。由此可知,有些数据挖掘技术并不适用于文本挖掘,需要建立在对文本集预处理的基础上。文本挖掘技术主要包括歧义消除、词性标注、句法解析、时间推理、指代消解、特征抽取、文本分类、文本聚类、文本比较、情感分析、人物关系网分析、信息抽取和智能检校等。
2 文本挖掘技术在审计中的应用
本文主要探索运用文本挖掘技术将招投标资料中的非结构化数据转换为结构化数据,再运用文本分析算法,进行审计分析,帮助审计人员发现审计疑点。
2.1 围标问题
2.1.1 业务目标
在电力企业招投标过程中,从招标文件获取招标要求,从投标文件获取投标信息,找出不符合资质的投标单位。从投标文件中提取和分析投标项目、投标单位、投标代理人,结合企业信息找出经常在相同项目中一起投标,同时存在关联持股、交换委托代理人的投标单位,找出异常投标企业和股份持有人。
2.1.2 分析流程
(1)通过文本挖掘技术抽取关键信息
利用文本挖掘技术抽取招标文件中的项目名称、投标企业资质要求(注册资金、企业人员规模、企业成立时间)等,形成招标要求关键信息数据,如表1所示。
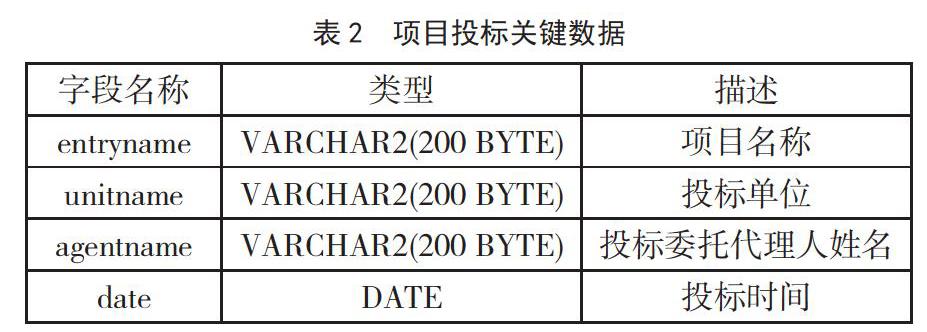
利用文本挖掘技术抽取投标文件中的分析投标项目、投标单位、投标委托代理人姓名等关键数据,形成项目投标关键数据表,如表2所示。
接入外部企业信息数据,外部企业信息数据包括企业名称、注册资金、企业人员规模、企业成立时间、企业股份组成(企业股东信息、企业股东股份比例、企业股东占股金额)等关键信息,如表3、表4所示。
(2)分析关键信息
根据关联招标要求关键信息数据中的投标企业资质要求与外部企业信息数据中的注册资金、企业人员规模、企业成立时间进行比较。将注册资金低于投标企业注册资金、企业人员数量少于投标企业人员规模、企业成立年限晚于投标企业成立年限的信息视为异常,作为审计疑点。运用关系网分析算法分析,找出在相同项目中一起投标,同时存在相互持股情况的异常投标企业和股份持有人,作为审计疑点。利用关联分析算法分析,识别出经常在相同类型的项目中一起投标,同时存在交换委托代理人的投标单位,作为审计疑点。
2.1.3 分析结果
经分析,发现部分项目存在投标单位资质与招标要求不一致、注册资金低于投标企业注册资金、企业人员数量少于投标企业人员规模、企业成立年限晚于投标企业成立年限的情况,下面对部分结果进行列示,如表5所示。发现一些投标单位在相同项目中一起投标,同时存在相互持股的情况,下面对部分结果进行列示,如表6所示。表7是投标公司持股情况。发现一些投标单位经常在相同项目中一起投标,同时存在交换委托代理人的情况,下面对部分结果进行列示,如表8所示。
2.2 技术方案查重
2.2.1 业务目标
依托企业历史招投标的技术文档库,对项目投标方的技术文档进行查重分析,分别从项目情况介绍、服务方案、服务安排、进度控制、质量控制进行相似度分析,大于一定阈值,则认为该技术方案存在严重的雷同情况。
2.2.2 分析流程
技术方案查重分析的流程主要分为3个步骤:文本抽取、分布式分模块相似度计算、文档整体相似度加权平均计算。利用基于编辑距离的文本相似度计算算法和加权平均算法,实现技术方案流程如图1所示。
(1)文本抽取
在对非结构化的技术方案文檔进行查重审计的过程中,选择的文本信息提取方法极大影响后续查重分析的效果。系统采用一种基于抽取模板的文档结构化提取技术抽取原始文档中的待分析内容,将其转换成包含“项目情况,服务方案,服务安排、进度控制、质量管控”的结构化字段数据进行存储,以便重复利用,提高后续查重分析效率。
该方法的实现步骤如下。①定义模板。在读取技术方案文档时,首先需要定义一个模板文件,用来定义待读取文档的结构和需要提取Word的内容,模板文件需要定义的内容包括:采用可扩展标记语言XML定义文档的具体结构,定制文件的树型章节结构内容,通过XML结构实现可配置的定义文档的层级结构,每个层级作为配置文件的一个节点;定制节点的属性,根据各节点的实际业务需求,配置标题节点名称、编号;定义模板节点的存储标识,即读取的数据应该存放到数据库表的哪个字段中。②文本提取。根据第一步定义的模板文件,加载待读取的Word文档并进行提取。实现过程包含以下步骤:内容遍历,加载模板文件和Word文档,并遍历其中的所有节点;根据XML定义的文档结构(树型结构),采用深度遍历方式加载内容遍历,在遍历过程中,根据当前的节点类型加载不同的内容;提取标题节点,根据模板节点中的标题或编号定位到具体的Word文档位置,如果不能定位则表示在模板中的标题没在文档中,同时根据节点的属性“是否为必须字段”判断是否需要输出错误信息;提取文本节点,读取Word文档中对应的文本内容,并依据模板中的节点定义,把读取的数据保存到对应数据库表的字段中。利用该抽取方法,系统可以快速将技术方案文档库中的海量技术方案文件转换为结构化的各章节文本并存储到关系数据库中,为后续方案查重分析提供数据基础。
(2)分布式分模块相似度计算
技术方案相似度计算主要采用基于编辑距离的文本相似度算法。编辑距离又称为Levenshtein距离,由俄罗斯的数学家Vladimir Levenshtein在1965年提出,指两个字串之间,由一个转成另一个所需的最少编辑操作次数。其中,编辑操作包括将一个字符替换成另一个字符,插入一个字符,删除一个字符。一般来说,两个字符串的编辑距离越小越相似。如果两个字符串相等,则它们的编辑距离为0(不需要任何操作)。两个字符串的编辑距离肯定不超过它们的最大长度。为了支持海量技术方案的查重比对,系统采用并行计算技术,并利用计算机的多核资源,实现多篇文档同时分析。充分高效地利用多核计算资源,降低单个问题的求解时间,节省成本,满足更大规模或更高精度要求的问题求解需求。
文本相似度算法基本步骤如下。①构造行数为m+1,列数为n+1的矩阵,用来保存完成某个转换需要执行的操作的次数,将串s[1…n]转换到串t[1…m]所需要执行的操作次数为matrix[n][m]的值。②初始化matrix第一行为0到n,第一列为0到m;Matrix[0][j]表示第1行第j-1列的值,这个值表示将串s[1…0]转换为t[1…j]所需要执行的操作的次数,很显然将一个空串转换为一个长度为j的串,只需要j次的add操作,所以matrix[0][j]的值应该是j,其他值以此类推。③检查每个从1到n的s[i]字符,检查每个从1到m的s[i]字符;将串s和串t的每一个字符进行两两比较,如果相等,则让cost为0,如果不等,则让cost为1。如果可以在k个操作里面将s[1…i-1]转换为t[1…j],那么就可以将s[i]移除,然后再做这k个操作,所以总共需要k+1个操作;如果可以在k个操作内将s[1…i]转换为t[1…j-1],也就是说d[i,j-1]=k,那么就可以将t[j]加上s[1…i],这样总共就需要k+1个操作;如果可以在k个步骤里面将s[1…i-1]转换为t[1…j-1],那么就可以将s[i]转换为t[j],使得满足s[1…i]=t[1…j],这样总共也需要k+1个操作。因为要取得最小操作的个数,所以最后还需要比较这3种情况的操作个数,取最小值作为d[i,j]的值;然后重复执行,最后的相似度结果就在d[n,m]中。
(3)文档整体相似度加权平均
加权平均法指标综合的基本方法,又称为“综合加权平均法”,指对经过同度量处理的数值通过加权平均进行综合,形成一个总值,从而达到综合评价目的的方法。该方法有两种形式,分别为加法规则与乘法规则,本系统采用加法规则实现加权平均,分别对项目情况、服务方案、服务安排、进度控制、质量管控设置权重,将各部分权重乘以各部分相似度,相加得到该文档的相似度。
2.2.3 分析结果
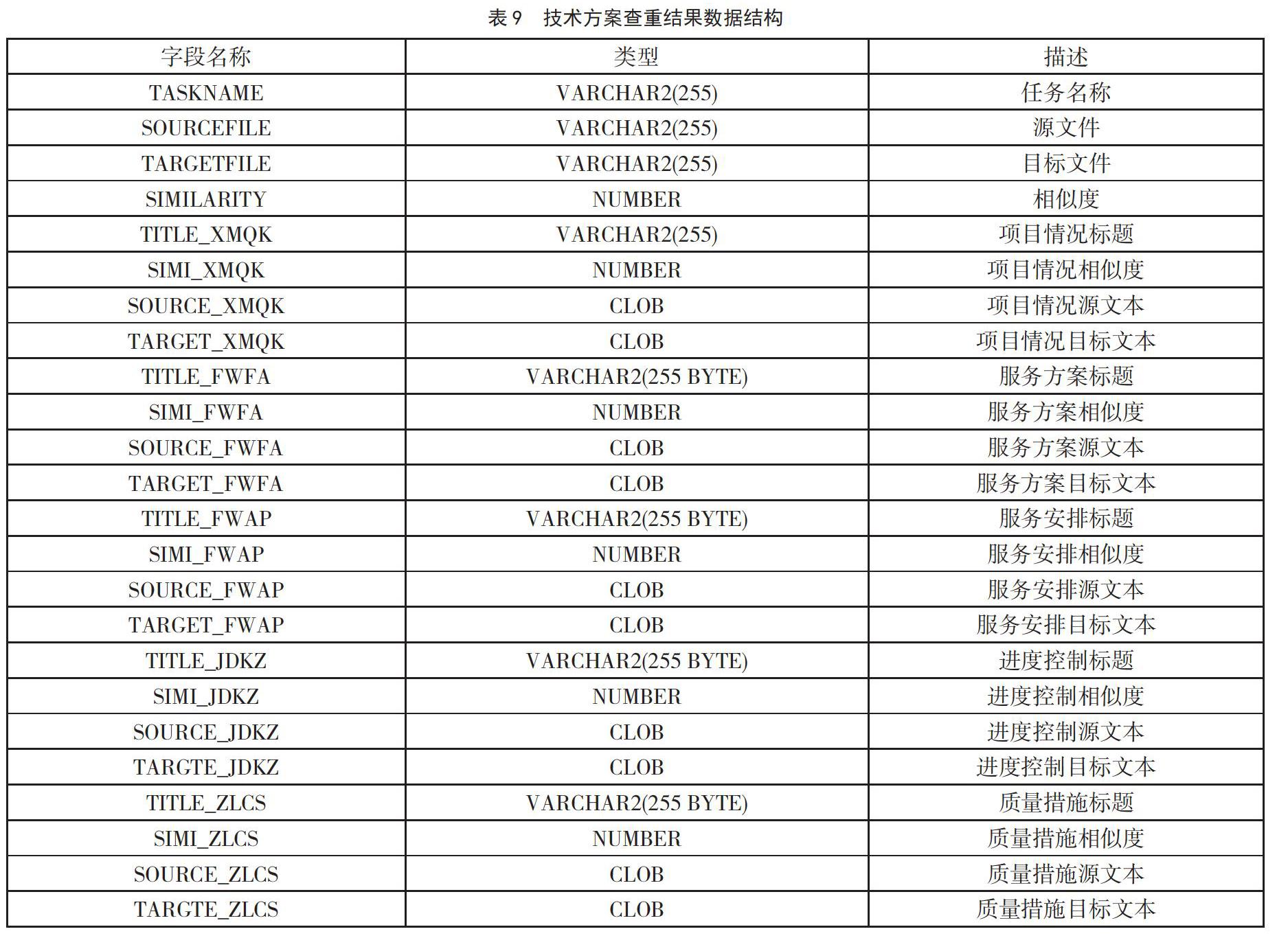
查重计算结果存储在数据库中,存储信息包括源文件和目标文件整体的相似度以及各部分信息的相似度,并标注源文本和目标文本的不同之处。技术方案查重结果数据结构如表9所示。
3 结 语
本文探索了招投标智能审计的应用,利用人工智能技术开展审核投标资质,分析围标、投标风险等繁杂的工作,大幅提高了审计工作的效率和准确率,使审计人员能够集中力量开展分析性工作。
主要参考文献
[1]蒋耀亮.自动光学识别OCR在票据自动识别系统中的应用研究[J].通讯世界,2019(5):288-289.
[2]陳琳娣.机器人流程自动化在内部审计中的应用实践[J].中国内部审计,2019(4):43-45.
[3]邹云峰,何维民,赵洪莹,等.文本挖掘技术在电力工单数据分析中的应用[J].现代电子技术,2016(17):149-152.
[4]陈朵玲,胡肖锋.基于Web文本挖掘技术的企业竞争情报系统研究[J].情报杂志,2005(6):22-24.
[5]李立,蔡峰,梁非,等.基于文本挖掘技术探索中医治疗胆结石药证对应规律研究[J].辽宁中医杂志,2013(4):664-666.
[6]梁浩波.基于文本挖掘的用电客户诉求智能聚类研究[J].广东电力,2016(8):45-50,66.
[7]汤宁.基于文本挖掘的电力工单分析[C]//2018智能电网新技术发展与应用研讨会论文集,2018.
[8]许保勋.基于文本挖掘技术的证券智能监管项目[J].金融电子化,2018(8):47-48.
[9]曹晋彰,赵少东,庞宁,等.基于文本挖掘技术的电网企业客户抱怨分析应用研究[J].大科技,2016(3):266.
[10]张博宇,周成轩.基于信息化条件下的供电企业市县一体化审计管理探究[J].消费导刊,2018(4):253-254.
猜你喜欢
商业经济(2016年11期)2016-12-20
戏剧之家(2016年22期)2016-11-30
价值工程(2016年30期)2016-11-24
中国集体经济(2016年27期)2016-11-19
中国市场(2016年38期)2016-11-15
企业导报(2016年20期)2016-11-05
商(2016年27期)2016-10-17
考试周刊(2016年45期)2016-06-24
企业导报(2016年10期)2016-06-04
企业导报(2016年5期)2016-04-05
