
具有函数型特征的干旱频率分析方法及应用研究
2020-09-15 16:27王轩儒蔡欣宇王立平
现代农业科技 2020年16期
王轩儒 蔡欣宇 王立平


摘要 本文依据降水量距平百分比的游程理论,采用1986-2016年安徽省六大水文站点降雨量数据进行干旱识别,應用函数型数据分析方法拟合修匀干旱历时(D)与干旱烈度(S)的频率分布曲线,并根据重现期研究干旱事件的特征与时间、流域、气候之间的关系。结果表明,干旱平均历时整体趋势由北向南逐步减小,干旱烈度受气候影响明显,温带气候所受干旱更严重;函数型数据分析方法所得到的干旱历时与烈度频率分布曲线与普通方法的拟合函数曲线相比较更加接近样本点,具有较理想的拟合效果;随着重现期的增加,干旱烈度与干旱历时呈减轻趋势,干旱发生的频次越严重,再次发生干旱的可能性越低。
关键词 函数型数据;游程理论;频率分析;重现期
中图分类号 P429 文献标识码 A
文章编号 1007-5739(2020)16-0144-04
Study on a Method of Drought Frequency Analysis with Functional Characteristics and Its Application
WANG Xuan-ru 1 CAI Xin-yu 1 WANG Li-ping 2
(1 School of Mathematics, Hefei University of Technology, Hefei Anhui 230009; 2 School of Mathematics, Hefei University of Technology)
Abstract Based on the run theory and precipitation data of the six major hydrological site in Anhui Province from 1986 to 2016, the drought was identified. Meanwhile, the functional data analysis method was applied to fitting smoothing frequency distribution curve of drought duration (D) and drought intensity (S). According to the recurrence period, the relationship between the characteristics of the drought event and time, basin, and climate was studied. The results showed that the overall trend of average drought duration decreased gradually from north to south, and the drought intensity was significantly affected by climate, while the drought intensity was more serious in temperate climate; the distribution curve of drought duration and intensity frequency obtained by the functional data analysis method was closer to the sample point than the fitting function curve of the ordinary method and also had a better fitting effect; with the increase of the recurrence period, drought intensity and drought duration showed a decreasing trend, and the more severe the frequency of drought, the lower the probability of drought occurring again.
Key words functional data; run theory; frequency analysis; recurrence period
旱灾指因气候严酷或不正常的干旱而形成的气象灾害。其发生极其频繁、历时长短不一、波及范围极广,是对生态、农业工业及人类社会影响最大的自然灾害之一。每年因为干旱造成的粮食减产和经济损失约占气象灾害造成经济总损失的50%左右[1]。世界各地都可能发生干旱,且与洪涝等自然灾害相比,干旱危害的地区范围广泛,涉及受灾人员众多,历时跨度较长,往往会造成难以估计的经济损失。因此,干旱灾害已经成为当代国际社会、学术界普遍关注的自然灾害之一。安徽省具有温带季风与亚热带季风气候的过渡型气候特征,天气多变,地势地形多样,气象灾害种类较多且发生频繁。而各类气象灾害造成的直接经济损失中,干旱灾害给安徽省农业生产和人民生命财产造成的损失最为严重。从干旱发生频次来看,淮河以北的严重干旱灾害2~3年发生1次,淮河以南3~4年发生1次。
关于干旱频率分析的研究,马晓晓等[2]根据随机变量和概率分布定义,运用Copula函数对多个相关的分布函数进行连接形成多变量联合分布函数,最终推算出二维相依概率分布计算公式。梳理研究文献脉络发现,描述干旱历时分布主要有指数分布、几何分布等,而干旱烈度的分布曲线则多采用单参数的指数分布、两参数、三参数的gamma分布和广义Pareto分布等[3-4]。本文采用函数型数据分析方法来描述干旱历时和烈度的分布,其思想是将一个独立区间内一次观测到的所有数据视为整体,以函数型分析方法将其构成曲线、曲面的函数图像。函数型数据分析方法应用广泛。例如:Ferraty等[5]研究非参数分位数核估计并给出渐近属性,将此模型应用于厄尔尼诺现象的时间序列分析与预测。孟银凤等[6]基于函数型主成分分析方法对人口死亡率建立模型,并将模型应用于分析我国1978—2006年财政支出效率。
基于前人研究,本文使用函数型数据分析方法来拟合干旱历时和干旱烈度特征变量,并计算出安徽省严重干旱地区干旱特征变量的频率分布函数,通过函数型多维度分析计算干旱的重现期,在对比现实干旱灾害发生频率与受灾成灾面积的基础上,揭示气候变化与人类活动对干旱灾害的影响,以期为干旱灾害风险的预测与防范提供经验证据和决策参考。
1 资料与方法
1.1 数据来源
本文分别选取淮河流域、安徽中部以及安徽南部的6个主要气象水文站点的月降雨量数据进行统计分析,数据起止时间为1986年1月至2016年12月,数据均来源于中国气象数据网,数据异常值已通过spass-trimmean函数剔除,剔除后的缺失数据通过与相邻气象站的水文序列建立非参数回归进行插补,灾害标准数据来自国标《GB/T 20481—2006气象干旱等级》。
1.2 游程理论
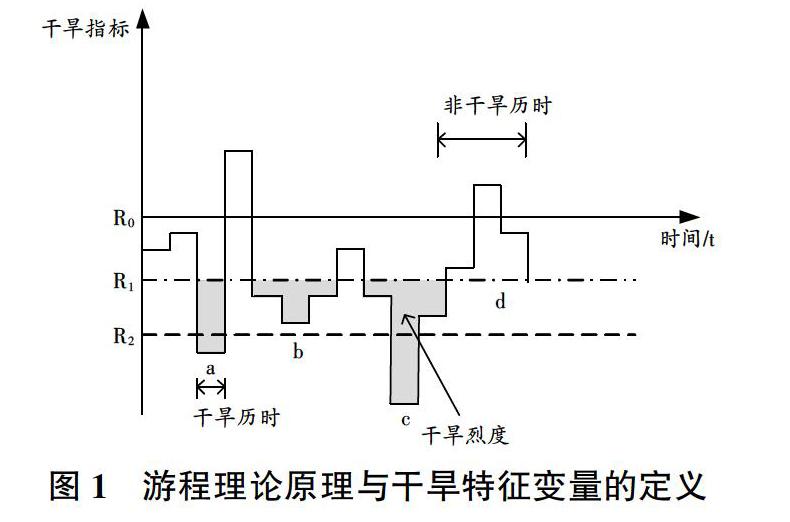
以干旱降水距平百分比为指标,设定阈值R0=0,R1=-40, R2=-60,R3=-80,R4=-95,对于历时为单位时间时,当某月干旱指标值小于R1时,则初步得到此月为干旱的结论,若某月干旱的指标值小于R2时,则确定这个月被确定为干旱(a),反之则不被判断为1次干旱;对于2个月干旱时间间隔为1单位的干旱,若中间间隔的1单位时段的干旱指标低于R0,则3个月的干旱则可记录为1次干旱过程,合并后干旱历时D=db+1+dc,烈度S=sb+1+sc,否则被认定为2次独立干旱过程。使用游程理论进行干旱识别可以简单有效地获得干旱特征变量——干旱历时(D)和干旱烈度(S)。同时本文设置3种干旱程度,分别为轻级干旱(R2)、普通干旱(R3)、严重干旱(R4),当干旱指标越大,表明干旱越严重,游程理论按照图1进行干旱识别,该方法可有效降低小干旱事件对水文干旱划分结果的影响,提高精度。
1.3 函数型数据分析方法计算D与S的频率分布函数
已有研究表明,干旱烈度(S)与干旱历时(D)一般可以使用双参数gamma分布与指数分布进行描述,但当直接使用平板数据来确定干旱特征变量分布函数时,往往具有很多缺点。一是拟合程度不够,会出现不符合实际的情况,造成计算结果的不合理性。二是此方法没有考虑数据的高阶光滑性和连续性特征,面板数据取样点之间也有很多信息缺失。本文使用的函数型数据分析方法是在充分考虑结果合理性的同时,根据分布曲线和样本经验点的拟合程度来优选参数最终确定分布函数的方法。
将干旱识别中所得到的变量数据转化为函数,具体来说,就是利用收集观察的原始干旱变量数据定义出一个频率函数图像来描述干旱事件的频率分布,它在因变量(干旱历时与烈度)区间上所有的干旱变量值都被估算出来。如果获得的离散数据含有观测误差,则干旱变量函数曲线即变为Yi(t)=xi(t)+εi,xi(t)为将原始离散观测值拟合后的函数曲线,εi为观测时的噪声[7-9]。若要把这些观测性误差消除掉,将离散性数据转换为函数时,就需要对所收集数据进行修匀,即进行光化处理。解决这个问题的基本方法是选定一组基函数?准k(t),k=1,…,k,并用基函数的线性组合给出函数x(t)的估计(t),即
在本文关于干旱的频率分析中,拟选择Gamma基作为基函数分别对干旱历时与烈度进行拟合,其中指数基所表示函数如下所示:
在函数型数据分析方法中,不仅要关注基函数拟合总体频率分布函数的拟合程度,更要关心拟合函数的光滑程度,为了使拟合程度更高同时保持函数更加平滑,本文使用函数型数据中经典的粗糙惩罚修匀。首先需要对粗糙程度进行测度,即对二阶导数的平方取积分:
调和数据拟合程度与估计结果光滑程度2个目标的综合准则为带惩罚的残差平方和。
而在干旱事件中,通過函数型拟合操作所得到的频率分布函数对于干旱特征变量(历时与烈度)X或Y不超过某一特定值,即计算重现期具有很大的作用,计算式为:
式中,FS(s)与之类似,TD、TS分别为干旱历时与干旱烈度的重现期,E(L)为间隔约期望,为干旱历时与非干旱历时平均值之和,FD(d)、FS(s)为干旱历时与烈度大于d与s的概率[10]。
2 结果与分析
2.1 干旱基本统计特性
由表1可知,在1986年1月至2016年12月共372个月的提取数据中,淮河干流的站点宿州(60 m)、阜阳(64 m)、蚌埠(57 m)会明显大于长江流域站点黄山(41 m),江淮分水岭站点六安(51 m),但与合肥站点(64 m)差距不大,淮河干流至长江支流,干旱平均历时E(D)与平均烈度E(S)随纬度变化极大,由北向南不断减小,其中最大值宿州(D为2.1 m、S为95.9),最小值黄山(D为1.78 m、S为49.8)。
其次发生干旱次数与平均历时在不同气候间差距较大(秦岭淮河一线南北分别为亚热带季风气候和温热带季风气候)。6个站点的最大干旱历时围绕5个月,最大历时发生在六安,历时7个月,站点之间差异不明显且分布无规律,所选取的安徽省站点除六安市与黄山市,D与S的相关性均通过95%的显著性检验,表明长历时的干旱时间导致的干旱烈度大,六安市与黄山市D与S的相关显著性没有其他站点大,淠史杭工程,总设计灌溉面积79.87万hm2,天然湖河与大型水库灌溉计划可以保证在发生干旱时极大地降低其灾害影响,这也是六安市D与S相关性不显著的原因。
为了进一步揭示干旱灾害对安徽农业生产的影响,图2通过计算干旱历时起止时间(由于篇幅限制,僅展示差异较大的合肥、阜阳站点),可以看出干旱呈现出明显的年代分布变化,1986年至21世纪初的是干旱历时与干旱次数最多的时段,通过查阅资料所得到的1990—1995年安徽省严重干旱也在其中展示出来,从月份来看,安徽省统计站点更多发生在1—6月和10—12月,且在此期间发生的干旱时间历时也更长,可以得到一年内干旱事件发生的时间分布。
2.2 干旱特征单变量频率分析研究
根据函数型数据分析方法的特征,为避免使用已知模型代入所带来的数据间隔缺失,根据指数基与gamma基分别对6个站点的干旱历时与烈度进行拟合,并使用分布拟合优度检验方法BIC对所得到函数进行检验,可决系数R2均大于0.94,具有较好的拟合程度。同时,又对所得函数曲线进行粗糙惩罚修匀操作,最终得到函数曲线图(图3)。可以看到,阜阳市、合肥市、黄山市修匀操作后的干旱频率分布曲线与干旱事件点相较于之前更加接近,说明此方法对于干旱时间的拟合具有较好的效果;对于修匀前的拟合曲线,是根据整体数据点进行拟合,而没有很好地根据数据趋势。
在实际干旱防治与规划中,中等及以上干旱是重点研究对象,表2是运用函数型数据分析方法得到的中等干旱(历时D>1)频率分布函数F(D)、F(S)所计算的不同流域各个站点的干旱重现期,安徽省所选取不同纬度站点的干旱程度差异明显。由表2可以看出,在以降水距平百分比为干旱指标,函数型数据修匀曲线所计算出的干旱重现期中,淮河以北站点宿州与阜阳D重现期与S重现期均超过8年;淮河附近站点,合肥与蚌埠的S重现期类似,围绕7.5年,平均小于北方站点,可以得出站点所处位置流域面积越大,干旱烈度随重现期的增加而增加的程度有所平缓;剩余六安站点与黄山站点由于水资源充足,国家灌溉项目扶持,S重现期与D重现期均较长,居中于8.5年附近,干旱烈度较小,且不易发生中等及以上干旱(图4)。
对比研究1986—2016年安徽省干旱受灾与成灾面积,可知,1986—2001年因旱灾引起的农业受灾面积呈上升趋势,其中1994年与2000年最为突出,受灾面积接近300万hm2,受灾严重,这也与干旱识别所得到的结果相统一,在这2个时段,安徽除黄山之外,各地均出现不同程度受灾,其中阜阳受灾最为严重,1994年与2001年2年内共有8次干旱,干旱历时均值大于3个月,烈度均值为94.4,远大于均值烈度平均值。而在2003年后干旱受灾与成灾面积越来越少,这也与安徽省抗旱能力增加及农作物计划种植有关。
3 结论
本文选用基于降水量距平百分比的游程理论进行干旱识别,分别计算出1986—2016年安徽省6个水文站点的干旱事件历时与烈度,使用函数型数据分析方法与粗糙惩罚的修匀方法对具有函数型性质的干旱特征变量进行拟合修匀最终得到干旱特征频率分布曲线,得到安徽省6个站点30年的基本干旱频率分布,并最终根据频率曲线计算出特征重现期,通过对比干旱频率分析结果与往期干旱规律与受灾情况,得到规律与结论如下:
(1)同一流域内的站点干旱事件分布类似,干旱平均历时整体趋势由北向南不断减小;干旱烈度受气候影响明显(秦岭淮河),温带气候所受干旱更严重;同时,干旱烈度受人为因素影响,如六安站点附近的淠史杭工程等大型水库灌溉计划对干旱灾害有着很好的缓解效果[11-12]。
(2)运用函数型数据分析方法所得到的干旱历时与烈度频率分布曲线与普通的拟合函数曲线相比更加接近样本点,且具有更好的拟合效果,通过求导消去参数的方法非常适合频率分布函数的拟合。
(3)随着重现期的增加,干旱烈度与干旱历时呈现减轻状态,即更加严重的干旱发生频次以及再次发生可能性越低,这也符合一般规律。
4 参考文献
[1] 黄荣辉,周连童.我国重大气候灾害特征形成机理和预测研究[J].自然灾害学报,2002(1):1-9.
[2] 马晓晓,宋松柏.基于Copula函数的不完全降水序列频率计算方法研究[J].水力发电学报,2017,36(2):9-17.
[3] 慎东方,商崇菊,方小宇,等.贵州省干旱历时和干旱烈度的时空特征分析[J].干旱区资源与环境,2016,30(7):138-143.
[4] Germ?魨?親n Aneiros-P?魨?鬁rez,Herv?魨?鬁 Cardot,Graciela Est?魨?鬁vez-P?魨?鬁rez,et al.Maximum ozone concentration forecasting by functional nonparame-tric approaches[J].Environmetrics,2004,15(7):675-685.
[5] FRéDéRIC FERRATY,ABBES RABHI,PHILIPPE VIEU.Conditional quantiles for dependent functional data with application to the climatic El nino phenomenon[J].Sankhyā the Indian Journal of Statistics,2005,67(2):378-398.
[6] 孟银凤,梁吉业,原曦曦.函数性数据分析中的主成分分析[J].山西大学学报(自然科学版),2011(1):27-31.
[7] 柏培鑫,凌能祥,金菊良.基于函数型非参数方法的气温数据预测分析[J].大学数学,2017,33(3):46-51.
[8] DALZELL J O R J.Some tools for functional data analysis[J].Journal of the Royal Statistical Society,1991,53(3):539-572.
[9] Germ?魨?親n Aneiros-P?魨?鬁rez,Herv?魨?鬁 Cardot,Graciela Est?魨?鬁vez-P?魨?鬁rez,et al.Maximum ozone concentration forecasting by functional nonpara-metric approaches[J].Environmetrics,2004,15(7):675-685.
[10] 周玉良,袁潇晨,金菊良,等.基于Copula的区域水文干旱频率分析[J].地理科学,2011,31(11):1383-1388.
[11] 袁潇晨.区域水文干旱多变量频率分析[D].合肥:合肥工业大学,2012.
[12] 谢五三,田红.安徽省近50年干旱时空特征分析[J].灾害学,2011,26(1):94-98.
基金项目 合肥工业大学2019年国家(省)级大学生创新创业训练计划项目(S201910359243)。
收稿日期 2020-04-28
