
基于深度学习的在线学习评论情感分析研究
2020-09-21 09:53乔德聪
河南城建学院学报 2020年4期
张 娜,乔德聪
(河南城建学院 计算机与数据科学学院,河南 平顶山 467036)
文本情感分析又称为意见挖掘、倾向性分析等,是对主观性文本进行挖掘、分析和推理的过程。研究来自在线学习平台的文本情感分析可以指导个性化教学。在大数据背景下,应用个性化教学的国内外研究项目日趋增多,如表1所示。
这些经典的研究项目可分为以下3类[1]:个性化学习与教学类数据挖掘技术、学习预测与评估类以及学习互动分析。主要分析方法有5类:(1)统计分析方法:用以分析学习者的成绩达到课程目标的百分比,学习时长及观看知识点情况,以及他们之间的关系;李帅[2]分析了东北大学MOOC平台上的学习行为数据;(2)内容分析法:分析学习者的知识掌握情况,在线互动情况,产生困难的原因;(3)社交网络分析法:分析学习者之间的互动关系,分析其对于学习者情感和认知的影响;(4)话语分析法,用于分析学习者在线学习平台上的语言,进而分析学习者的学习特征和情感态度情况;(5)文本分析法:分析目前网络学习环境中以文本为主的非结构化数据。文本数据挖掘的典型研究如表2所示。这5类方法分别从认知、行为、情感这3个维度,对学习者的具体学习情况进行分析。

表1 社交网络相关的研究

表2 文本数据挖掘技术相关的研究
文章利用统计分析和文本分析两种方法,通过分析MOOC平台课程评论的极性程度,将好评和差评信息及时反馈给授课教师,针对性地帮助教师改善课程内容,提高课程质量;同时,平台也可以从整体观察不同学科的好评比例,在引进和改善师资力量方面提供有效参考。
1 慕课网评论的获取与处理
1.1 评论数据的爬取
1.1.1 软件环境
在设计过程中,需要使用用于爬取数据的PyCharm软件、具有良好稳定性的Chrome浏览器、用于保存信息的数据库Mysql、动态爬取信息用到的Selenium WebDriver库和一些BeautifulSoup、PyQuery、time等常用库。详细信息见表3。

表3 软件配置信息
1.1.2 设计总流程
程序初始化后,打开慕课网课程分类页面(http://www.icourse163.org/category/all),构建link_list,观察任意课程页面,将想要捕捉的内容分为课程信息和评论信息。其中,课程信息包括:学科大类、课程名、授课教师和网页地址;评论信息包括:学生的昵称、学习者的评论内容、对课程的评分、发表评论时间、开课班次以及评论点赞数。爬取的过程,当页信息获取完毕后,将自动跳转到下一页,在最后一页时停止。采集到的信息通过insert语句储存到Mysql数据库中。整体的流程如图1所示。
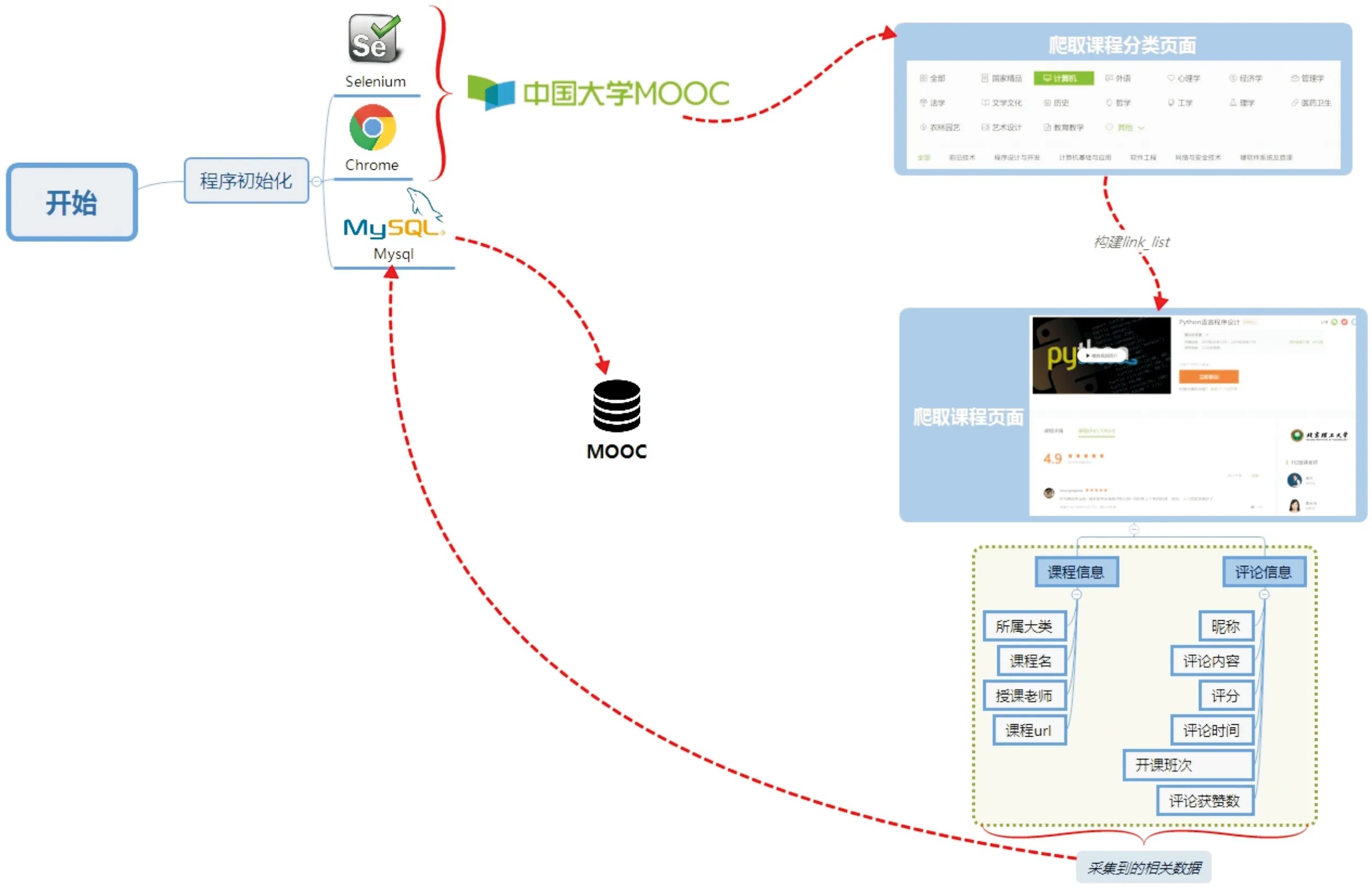
图1 MOOC爬取流程
1.1.3 爬取内容
本次共爬取到有效数据68 367条,包括来自国家精品、计算机、社会科学、生物医学等12种领域的学科课程,数千位讲师、副教授、教授主讲的千余门课程信息和近七万条评价,将爬取到的所有信息,保存在Mysql数据库中,部分数据如图2所示。
图2 数据举例
1.2 数据清洗及预处理
1.2.1 数据清洗
数据清洗是一个重新检查和验证数据的过程,目的在于清除某些错误的数据、不合格的数据以及不合理的数据,即“脏”数据,例如:拼写错误、空值等。数据清洗可以剔除格式错误、不满足要求的数据,从而提高数据分析的效率。
1.2.2 数据预处理过程
首先引入需要用到的基本库,如正则表达式re库,读文件的Pandas库、分词工具jieba库和编码转换codecs库等。具体步骤为:
(1)利用正则表达式。将有意义的字母、数字、汉字输出,命令如下:
leave_valid_pattern = re.compile("[^/u4e00-/u9fa5^a-z^A-Z^0-9]")
(2)调整文本的格式和字符。去除无关符号和特殊字符,保留有价值的中文文本。
(3)去除停用词并分词。停用词是指在检索的过程中,移除某些特定的字或者词,从而使NLP数据、文本变得更有效率,同时也节省了存储空间。预处理的效果如图3所示。
图3 预处理效果举例
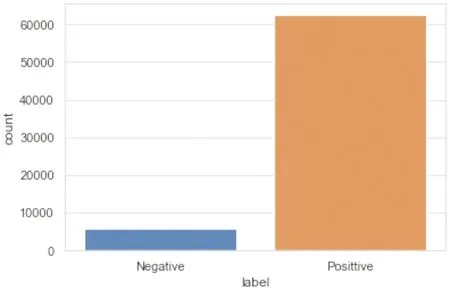
图4 总样本极性比例情况
1.2.3 情感词性标注
词性标注是指在给定句子中分析每个词的语法类别,确定其词性并加以标注的过程。可以使文本在词性标注后,方便进行分类分析和统计,带来更多便利,发挥良好作用。词性标注可以照搬分词的工作,在汉语中,多数词仅一个词性,结果更加准确;不同于英文,相同的单词可能有着积极和消极两种词意,或是多种词性分别表示不同的意思,容易产生歧义。
本文采用Python中的SnowNLP库完成中文情感词性标注任务,阈值设置为threshold=0.5。
1.2.4 样本统计
通过分类上一步词性标注结果,将label值为1的数据定义为积极(positive),不为1的数据定义为消极(negative),同时使用seaborn可视化库输出积极和消极的柱状图,如图4所示。结果显示超过6万的好评数据,大幅超过小于一万的差评数据。
由图4可知,极性比例严重失衡,这会导致训练结果出现较大误差,因此需要调整正、负样本的配比,平衡两种样本。首先将阈值调整为0.6,设置percent(多数类别下采样的数量相对于少数类别样本数量的比例)的值为1.5,使用len()函数从低到高返回一个随机整型数,采取上采样的方法,再次使用seaborn方法输出平衡后的极性比例柱状图,如图5所示。
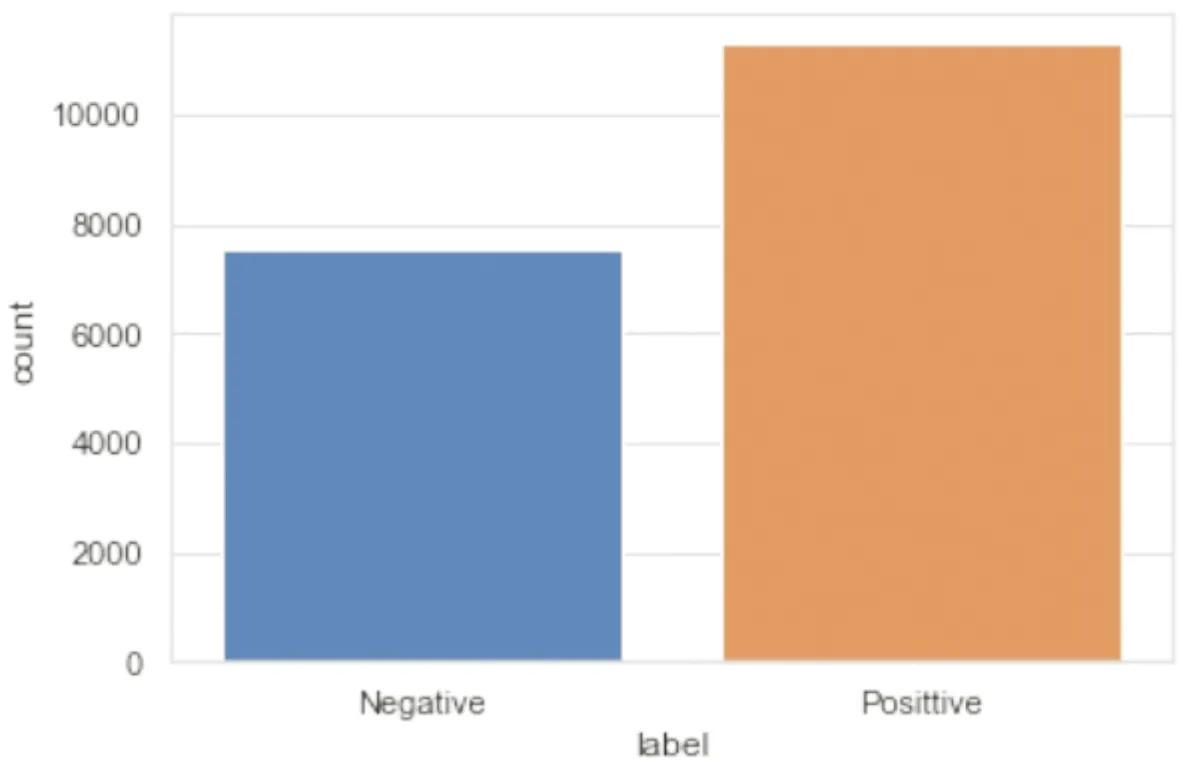
图5 调整阈值后样本极性比例情况

图6 关键词云图
由图5可以看出:消极数据选取接近8 000条,积极数据10 000多条,两者比例适中,可以进行下一步词向量的训练。最后用shape()方法了解到,全部数据为17 125条,每条各有14个属性。
1.2.5 云图制作
词云是词语频率可视化的一种方法,其基于Python的WorldCloud库,同时也用到了matplotlib.pyplot方法来制作。其过程为:根据输入的字符串,对词频进行统计,并用不同的大小显示出来,输出为指定的图片。词云的样式由参数设定,本次设计采用白色底部,楷体字,图片为10×10的矩形,其他参数如最大、最小字体的字号,显示的最大单词量等均为默认设置。最后使用plt.show()方法输出词云,效果如图6所示。
由图6可以看出:出现频次较多的关键词,其在词云图中的位置越靠近中间,且字体越大。因此可以推断出,频次较多的词越多,生成的词云图将会越密集,词与词、文字本身的空隙会越来越少。
2 训练神经网络模型
2.1 文本向量化表示
Word2Vec是Google团队发布的开源词向量工具,主要包含词袋模型和跳字模型两种模型,可以将文本词汇转化成含有一定语义信息的高维实数向量,更好地表达不同词之间的相似和类比关系。
2.2 参数设置
参数的设置作用于结果,这里参考较为常见的参数设置方法以及训练文本的特征,对表4参数进行设置。
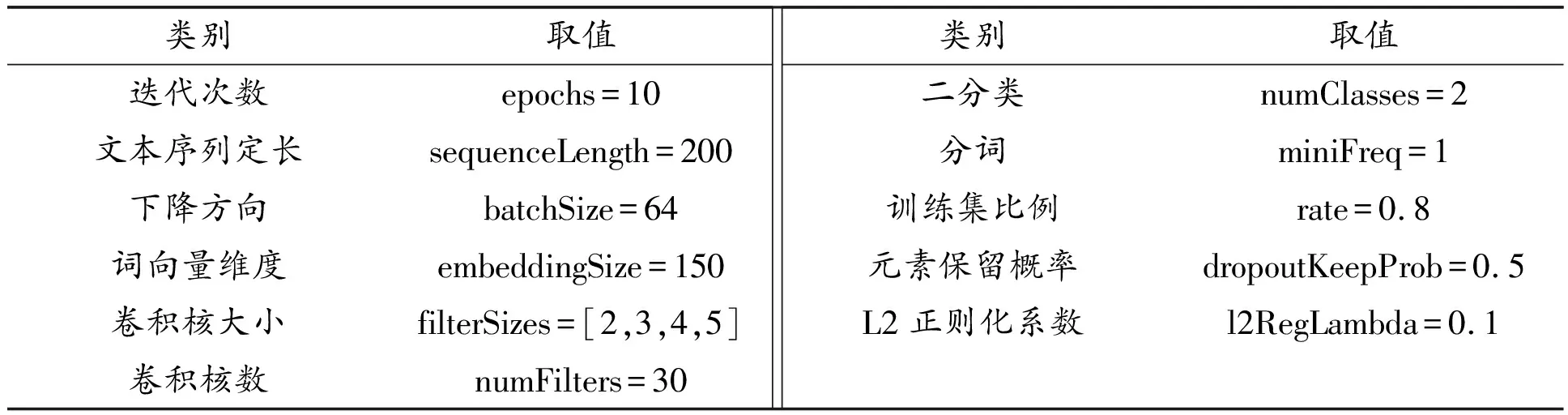
表4 TextCNN超参数
2.3 性能评估指标
文中采用准确率(Accuracy)、精确率(Precision)、召回率(Recall)和F值(F1-Measure)作为评价指标来权衡文本情感分析的结果。四种指标的公式见式(1)~式(4)。其中,TP 指积极预测为积极情感的数量,FP 指消极预测为积极情感的数量,FN指积极预测为消极情感的数量,TN 指消极预测为消极情感的数量。
(1)
(2)
(3)
(4)
3 实验结果分析
3.1 实验数据
在对数据的爬取以及对数据样本标注情感阈值之后,统计得到本次共爬取到有效数据68 367条,包括来自国家精品、计算机、社会科学、生物医学、教学方法、农学、外语、法律、艺术设计等12种领域的学科课程,数千位讲师、副教授、教授带领的千余门课程信息和近七万条的评价,对数据进行清理、标注情感后,保留了有效数据17 125条,其中积极数据有11 294条,占总数据的65.95%;消极数据有5 831条,占总数据的34.05%。其中占比最多的学科为teaching-method,共有11 506条评论数据,占总数据的67.19%;占比最少的学科为agriculture,共有43条数据,占总数据的0.25%。12门课程具体评论数及其所占的比例如图7所示。
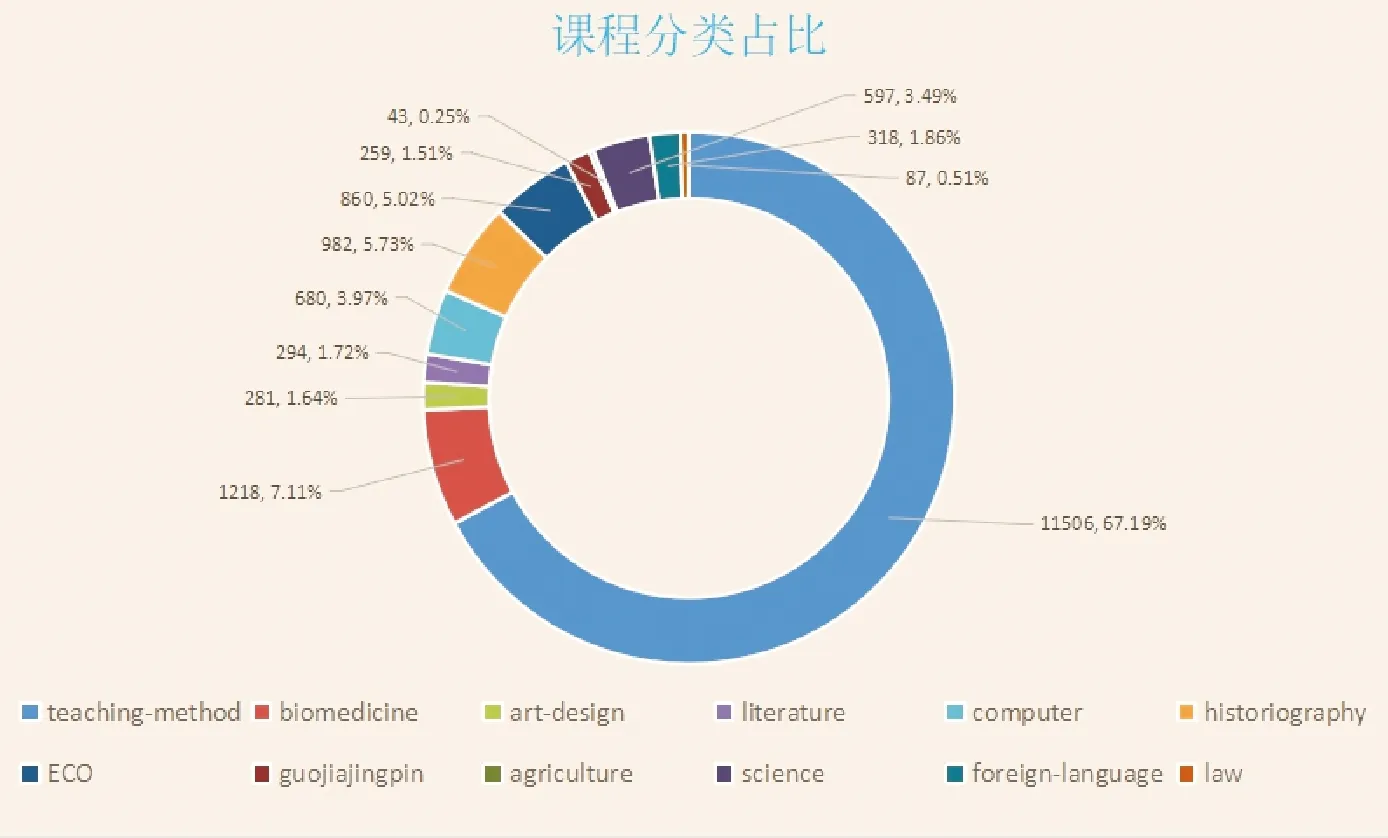
图7 课程分类占比图
3.2 极性分布
在确定使用的数据中,通过划分好的情感极性,对这12种课程大类的极性进行分析,并绘制成柱形图,如图8所示。
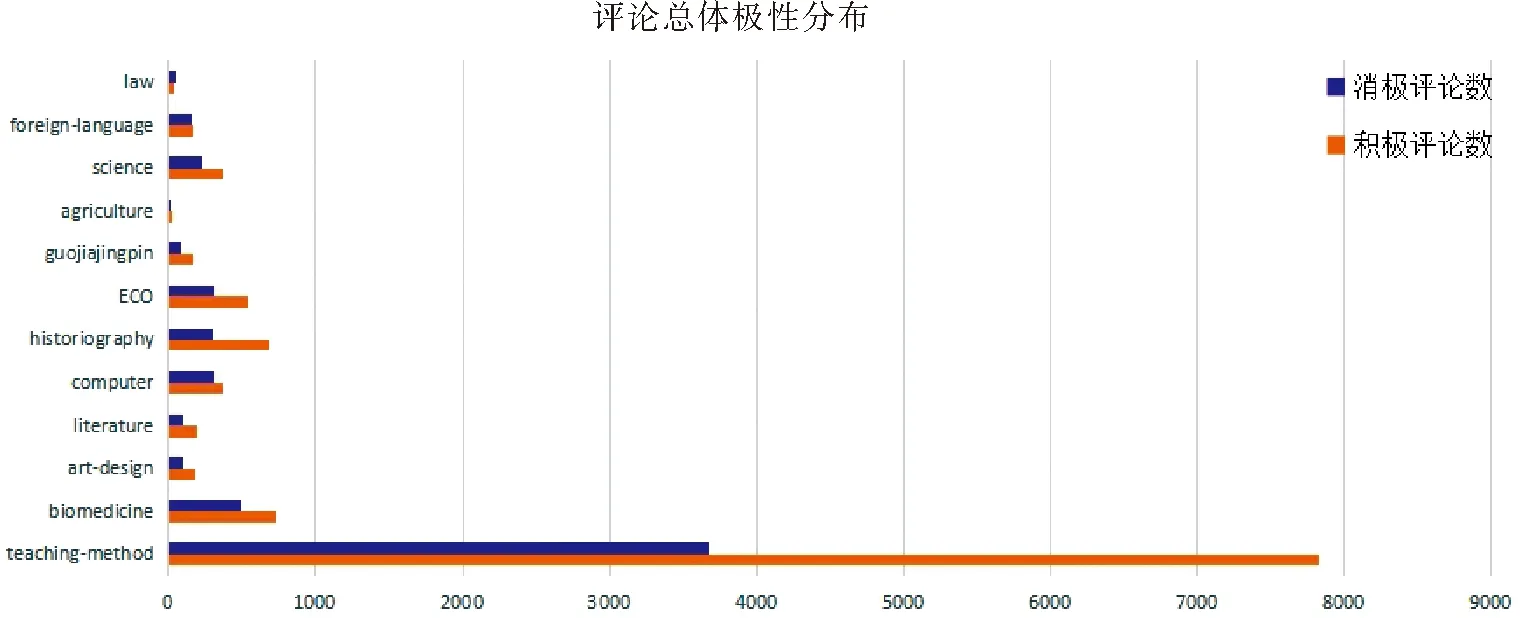
图8 样本总体极性分布
由图8可以看出:绝大部分课程大类中,积极评论数量都高于消极的评论数量,再根据各大类学科积极评论的比例,绘制柱状图如图9所示。
由图9可以看出:historiography大类积极评论的比例最高,达到了68.84%;而law大类积极评论占比最低,仅为47.13%,是12个学科中,唯一占比低于50%的学科。其中有8个学科的积极占比都超过了60%,排除数据数量较小的law学科(87条数据)和agriculture学科(43条数据)外,可以总结出:
(1)慕课网中teaching-method大类的受众学生群体比例最高,也是慕课网中最受欢迎的学科分类,学生十分积极;law和agriculture大类的受众学生群体比例最低,可以推断出这两个专业学生活跃度较低。
(2)根据积极评论的占比可以得出,大部分学生给予了认可;而负面评论的学生部分因为设备无法连接网络、没有声音等技术问题给出了差评,其他意见也将帮助授课教师更好地完善课程内容。
(3)对于17 125条评论中仅出现87条的law学科和43条的agriculture学科,平台可以针对性地分析这两门学科的课程设置,提供多样化学习方案,吸引更多学生加入学习。
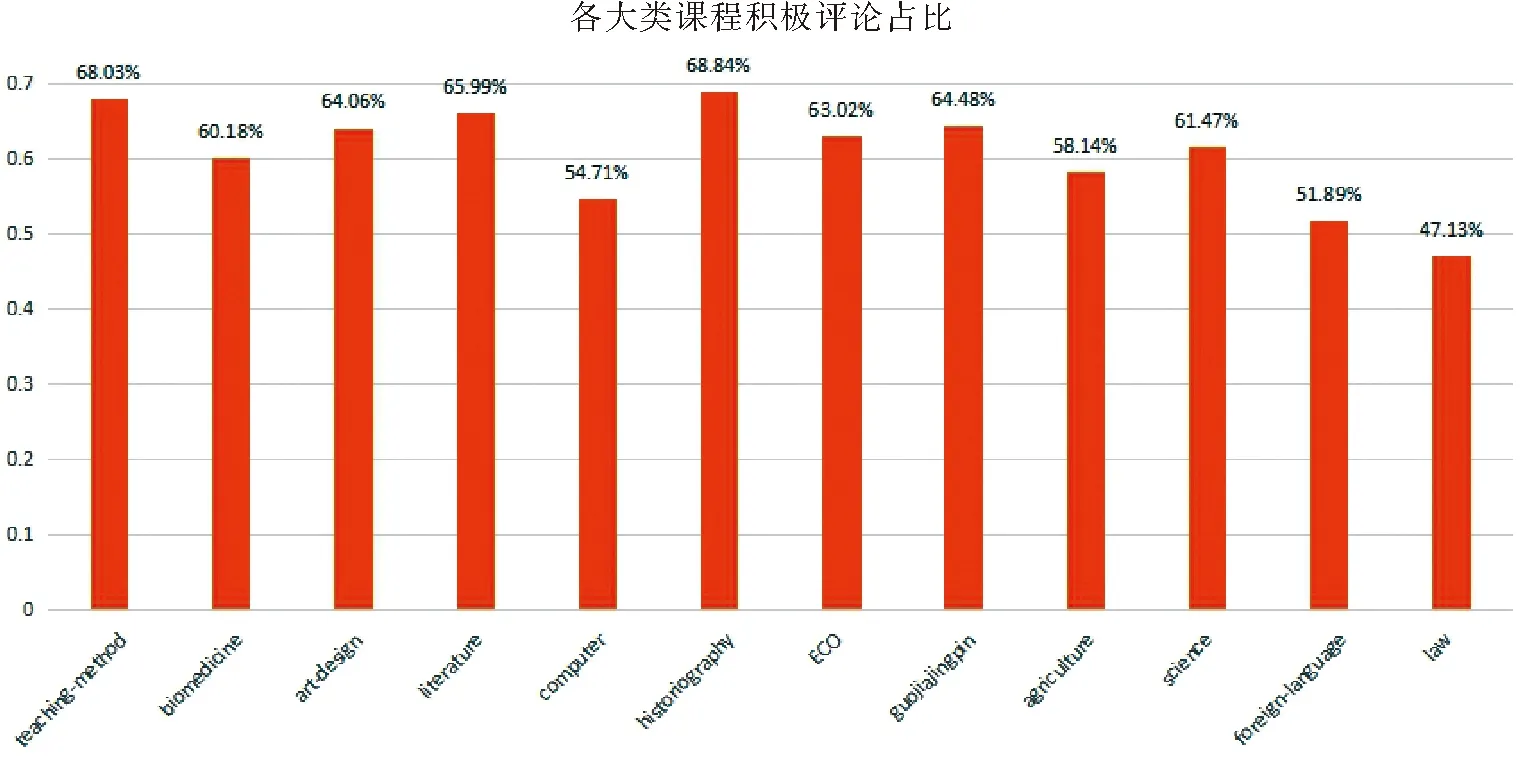
图9 各大类学科积极评论占比图
3.3 网络模型结果
为了解决深度学习过程中,损失值波动无法达到最小的问题,设计采用ReduceLROnPlateau方法调整学习率,监测损失值的变化,当评价指标趋于稳定时,降低学习率。
同时,防止过拟合是训练模型中的核心任务,为了改善过拟合泛化性能较差的特点,本次设计中采用Early stopping方法,通过切断迭代次数来防止过拟合,即训练停止于迭代收敛之前,无须等到验证集误差最小化。同时,在网络结构的定义中,加入Dropout层,以0.4的概率随机断开输入神经元,起到防止过拟合的作用。
为了保证对比结果的准确性,在调参方面,3种模型采用相同的词向量维度、文本定长、dropout等参数,以及相同的编译模型方式,在网络层的调参和全连接层的激活函数方面存在不同;另一方面,本次设计按照73的比例设置训练集和验证集,在13 700条总数据中,包含9 590个训练样本以及4 110个验证样本,迭代次数epoch设置为10,同时作用于3种模型。
3.3.1 TextCNN训练结果
导入划分好的训练集和验证集,加入降低学习率和防止过拟合方法,使用model.fit()输入训练模型,设置好各项参数,使用print方法输出精确率、准确率、召回率、F1值和损失值。经历了10次迭代之后,该模型的准确率由85.76%提高到了99.22%,并趋于稳定;loss值由最初的1.07降到了0.04;精确值由86.73%提高到了99.59%;召回率由93.72%提高到99.24%;F1值由89.68%提高到99.41%。X轴表示迭代次数,Y轴表示损失值,点表示训练损失,折线代表验证损失,绘制点折图,如图10所示。再以迭代次数为横坐标,准确值为纵坐标,点表示训练F1值,折线代表验证F1值,绘制点折图,如图11所示。
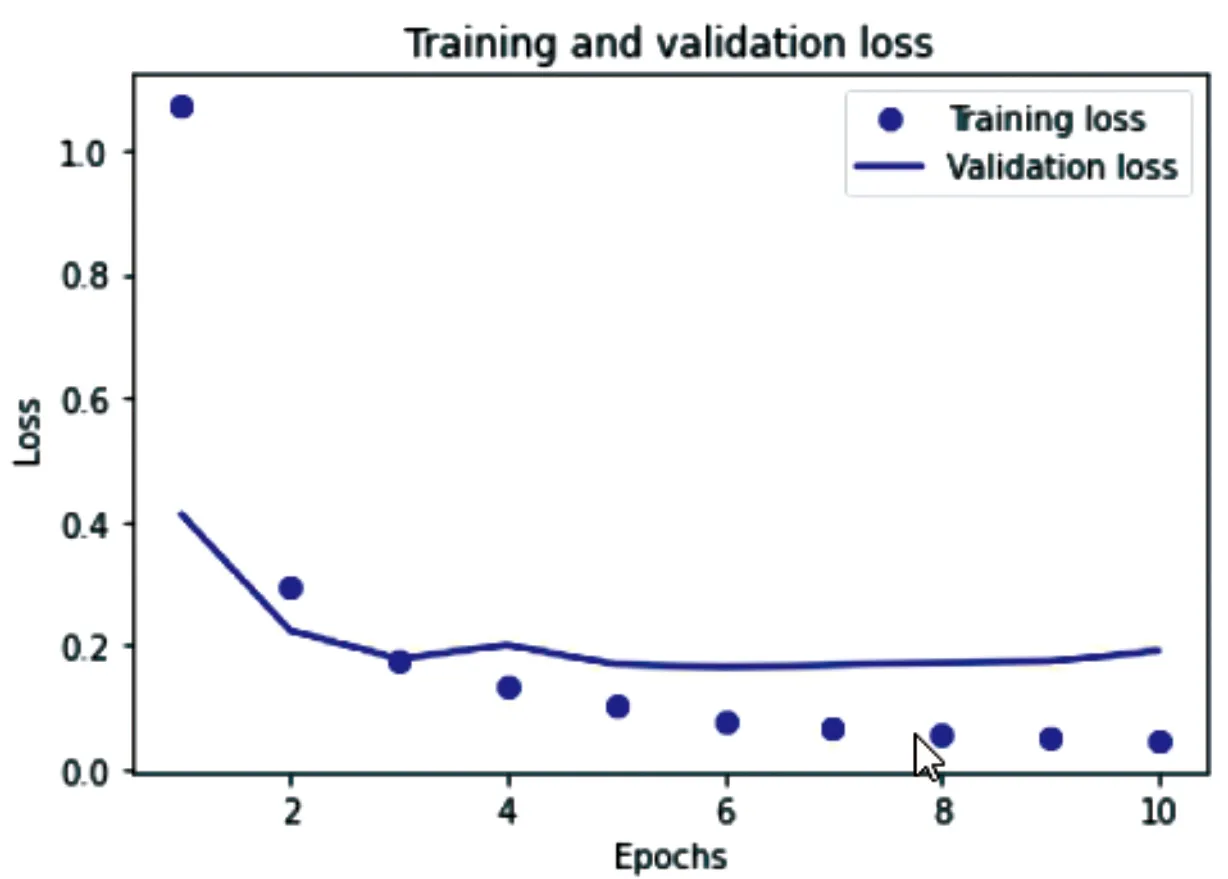
图10 训练集和验证集loss值点折图
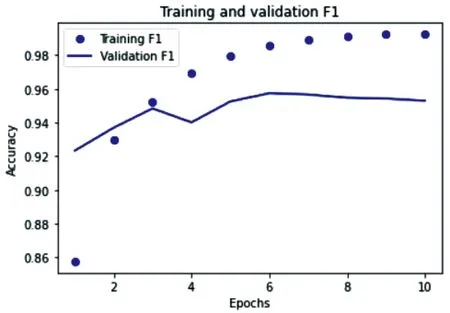
图11 训练集和验证集F1点折图
3.3.2 LSTM训练结果
采用与TextCNN相同的训练模型过程,经过迭代后,得到该模型的准确率稳定在65.81%;loss值由最初的0.648降到了0.643;精确值由65.38%提高到了65.81%;召回率稳定在1.0;F1值由78.72%提高到79.23%。训练集和验证集损失值的点折图如图12所示,其F1点折图如图13所示。
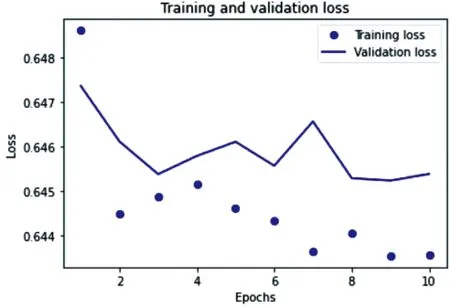
图12 训练集和验证集loss值点折图

图13 训练集和验证集F1点折图
3.3.3 BiLSTM-Self-Attention训练结果
经历了10次迭代之后,该模型的准确率由78.70%提高到94.97%;loss值由最初的0.445降到了0.127;精确值由80.94%提高到了96.10%;召回率由90.51%提高到了96.28%;F1值由84.87%提高到96.14%。训练集和验证集的损失值如图14所示,训练集合验证集的F1点折图如图15所示。
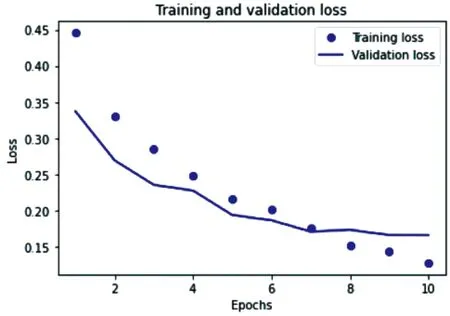
图14 训练集和验证集loss值点折图
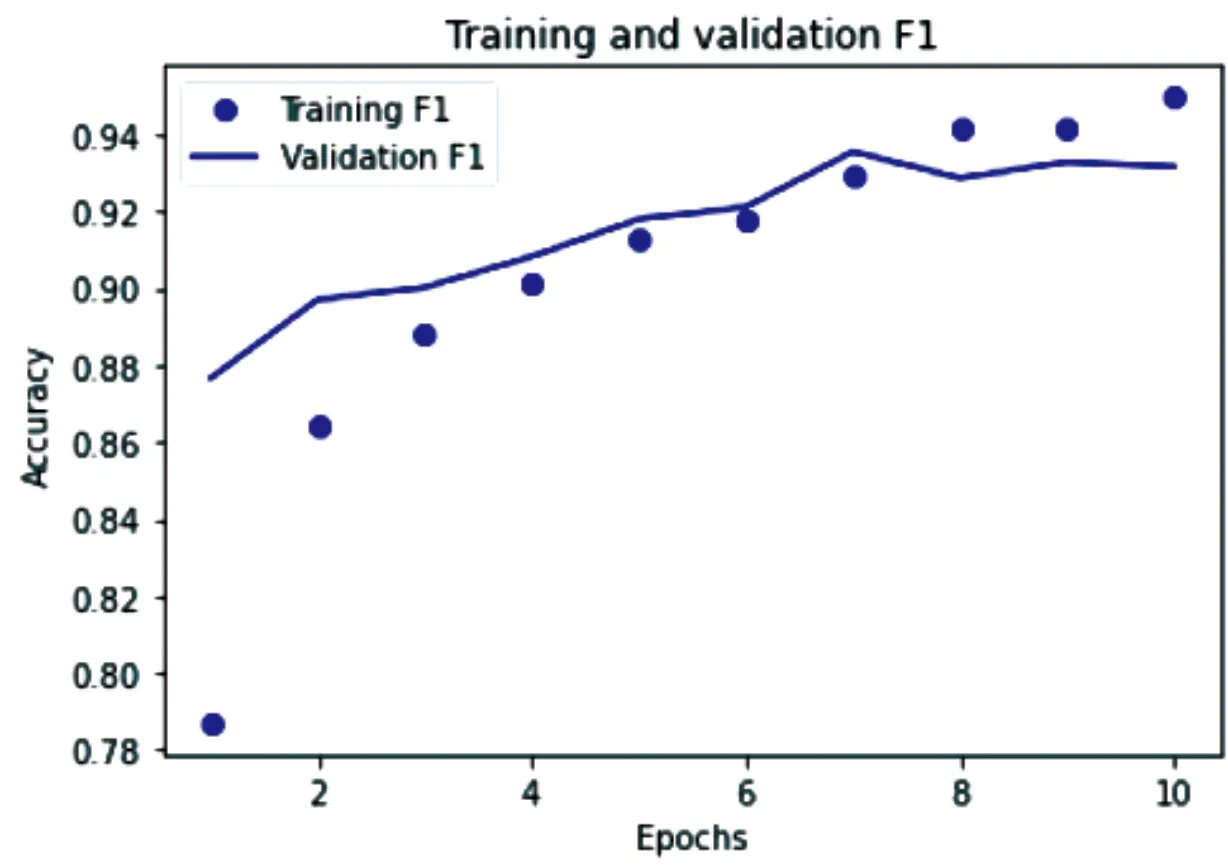
图15 训练集和验证集F1点折图
4 综合比较
将3个模型的各项数据结果绘制成表格,综合对比,结果如表5所示。

表5 实验结果对比
在训练时间方面,TextCNN和LSTM所用时间较短,平均40 s可以完成一次epoch,而BiLSTM完成一次epoch平均需要95 s。结合表5的信息,可以得出:
(1)TextCNN充分发挥其提取文本局部特征的特点,利用不同大小的卷积核来获取句子中的核心信息,以及较强的特征抽取能力[14],在本次实验中,有着较短的训练时间、较高的准确率和较低的损失值,有效地处理空间信息,是本次实验中的最优模型。
(2)LSTM实验结果没有达到预期,映射出调参中存在问题,作为损失函数的BinaryCrosse-ntropy在这里似乎并不合适;另一方面,由于LSTM自身只能学习当前词的上文信息,无法利用文本的下文信息,然而一个词的语义同时连接着上下文的内容,与下文信息也密不可分[15],所以这个特点也将影响最终的准确率。
(3)为了改善LSTM结构特点的不足,特引入BiLSTM,其由正向 LSTM 和反向 LSTM 组成,两者上下叠加,前者用于学习过去的信息,后者用于学习未来的信息,在某一时刻t,同时存在两个方向相反的门,既能够利用t-1时刻的信息,又能够利用到t+1时刻的信息[16]。算法实现上采用merge层融合,解决了LSTM不能学习后续文本的问题。同时,自注意力机制的加入,可以直接计算依赖关系,忽略词间距,学习一个句子的内部结构,增加计算的并行性,提高训练效率[17]。基于这两点的改进,BiLSTM-self-Attention在本次实验中充分发挥其提取文本全局特征的特点,获得了较高的准确率,结果优于LSTM模型,在实际应用中,具有较大的使用价值。
5 结论
文章从教育大数据挖掘视角出发,研究基于深度学习的在线学习评论情感分析。对MOOC平台进行评论数据爬取,并对文本数据做去除停用词等预处理,采用SnowNLP库完成中文情感词性标注,用TextCNN、LSTM和BiLSTM-self-Attention分布等算法对深度学习模型进行训练。实验结果表明,改进后的包含自注意力机制的BiLSTM模型优于LSTM模型,不仅能获得较高的准确率,而且使得语言模型更加完整。
猜你喜欢
云南教育·小学教师(2022年4期)2022-05-17
民用飞机设计与研究(2020年4期)2021-01-21
中国生殖健康(2020年5期)2021-01-18
艺术评论(2020年3期)2020-02-06
小太阳画报(2019年10期)2019-11-04
中华诗词(2018年9期)2019-01-19
电子制作(2018年18期)2018-11-14
电子制作(2018年18期)2018-11-14
小资CHIC!ELEGANCE(2018年20期)2018-07-06
山东工业技术(2016年15期)2016-12-01
