
科学数据素养能力评价指标体系构建研究
2020-10-20 05:15秦小燕初景利
图书与情报 2020年4期
秦小燕 初景利
摘 要:构建定性描述与定量评价相结合的科学数据素养能力指标体系,为开展全方位、有针对性的科学数据素养能力调查提供科学的评价标准和量化测评工具。基于文献调研与科学数据素养本土化特征研究,初步拟定指标体系;运用德尔菲方法,进行两轮专家咨询,通过评议各项指标的必要性和明确性确定各级指标内容;利用层次分析法通过计算专家评分从而确定指标权重。最终构建了由3个维度、18个一级指标、47个二级指标共同构成的“科学数据素养能力指标体系”,并为各维度和一级指标赋予权重值,从而保证了指标体系的科学性、通用性、前瞻性和可操作性。
关键词:科学数据素养;能力;指标体系;德尔菲法;层次分析
中图分类号:G252.7 文献标识码:A DOI:10.11968/tsyqb.1003-6938.2020062
Research on the Construction of the Evaluation Index System of Scientific Data Literacy
Abstract The scientific data literacy competency index system combining qualitative description and quantitative evaluation were constructed to provide scientific evaluation standards and quantitative evaluation tools for conducting all-round and targeted scientific data literacy survey. Based on the literature research and the study on the localization characteristics of scientific data literacy, the index system was initially constructed, and Delphi method was used to carry out two rounds of expert consultation, and the content of each index was determined by evaluating the necessity and clarity of each index, then AHP was used to determine the index weight by calculating the expert score. Finally, the scientific data literacy competency index system composed of 3 dimensions, 18 first-level indexes and 47 second-level indexes were constructed, and the weight values were given to the dimensions and first-level indicators, so as to ensure the scientificity, universality, foresight and operability of the index system.
Key words scientific data literacy; competency; index system; Delphi method; analytic hierarchy process (AHP)
1 引言
科学数据是知识发现与科技创新的重要基础。在数据密集型科研时代,对科学数据的管理和利用能力成为科研人员的必备素养,科学数据素养教育的重要性受到日益广泛的关注。科学数据素养能力指标体系,是科学数据素养能力评价的依据,是科学数据素养教育体系的重要组成部分,对于保证大数据时代人才培养的有效性和评估的科学性具有重要意义。
关于数据素养所应该包含的核心能力,国内外不同领域的专家学者,都开展了一定的研究,然而,由于具体应用情境和研究角度的不同,其对数据素养的观点和看法也不尽相同。国外主要从数据管理的角度出发,探讨面向不同领域或群体的数据素养能力评价。J.Carlson等[1]在普渡大学、明尼苏达大学、康奈尔大学和俄勒岡大学图书馆共同开展的数据信息素养项目的基础上,为地理信息学科开展数据信息素养教育,通过对教师的访谈以及对学生学习成绩的评估,构建了由12项核心能力构成的“数据信息素养核心能力集”;弗吉尼亚理工大学图书馆成立了数据素养咨询组,开发了“数据素养技能模型”,包括8个能力维度的初级、中级、高级3个层次的核心技能,为学生、教师和科研人员提供科研和数据相关的制度框架[2];J.C. Prado和M.?魣.Marzal[3]构建了信息素养视域下的数据素养课程核心能力和内容体系,并将其转化为教学主题或单元,旨在促进图书馆以此作为基本参考框架、广泛开展数据素养教育;R.Schneider[4]构建了由8个维度和若干数据管理技能构成的“研究数据素养能力体系”。A.Grillenberger和ROMEIKE[5]围绕计算机科学专业教育,从理论上推导出数据素养的核心内容和过程领域,从而开发了由4个数据主题领域和4个相应的数据处理模块构成的数据素养能力模型;C.Ridsdale等[6]构建的数据素养能力矩阵,包含5大知识领域22个能力指标以及相应的技能要求。Databilities研究团队则从数据的获取、操作和应用3个方面,为15项数据能力划分了6个进阶层级,构建了“数据素养能力框架”[7]。
我国学者近几年也从不同的角度探讨了数据素养的核心能力构成与评价体系。如王维佳等[8]利用因子分析法研究科研人员数据素养能力综合评价方法;刘爱琴等[9]基于MOOC环境下构建了高校大学生数据素养能力评价系统;董薇等[10]基于灰色理论建立数据素养能力评价多层次模型;周兵[11]面向高校教师构建数据素养能力评价指标集合,并通过模糊综合评价法设计数据素养评价数学模型;潘雪和陈雅[12]从教育主体、对象、形式、内容和效果5个角度构建高校数据素养教育评价指标体系等。
纵观已有研究,大多侧重于科学数据素养能力的定性描述,而结合我国科研工作实际的定量化研究较为缺乏。随着数据密集型科学的发展,科研人员亟需一个具备通用性、本土化以及系统性的能力参考框架,用来指导提升数据素养水平、胜任日益复杂的数据领域工作。本文通过大量的文献分析,结合充分的本土化调研,采用德尔菲法和层次分析等方法,构建了一套定性与定量相结合的科学数据素养能力指标体系,为引导科研人员应对数据管理与利用中的严峻挑战、推进我国科学数据素养教育及评估提供参考依据。
2 科学数据素养能力评价指标的拟定与筛选
为了保证指标体系的有效性、合理性,保障评估过程和结果的科学性,本文在广泛研读国内外相关文献的基础上,结合面向我国科研人员的科学数据素养能力特征研究结果,初步拟定了我国科学数据素养能力评价指标,运用德尔菲法,通过问卷调查进行专家意见的征询与整合,从而得到专家对科学数据素养能力评价指标较为一致的意见。
2.1 研究方法与实施步骤
德尔菲法,又名专家意见法,是一种重要的专家评价及预测方法[13]。其本质上是一种利用函询形式进行的集体匿名思想交流过程。即针对所要预测的问题进行多轮专家意见征询,对每一轮收集到的意见进行梳理、汇总和统计,并将集中意见后的修订稿作为参考材料,再匿名反馈给各位专家,以供分析判断,进而提出新的论证意见,直至专家意见趋于一致,得到一个较为一致且可靠的结论或方案。
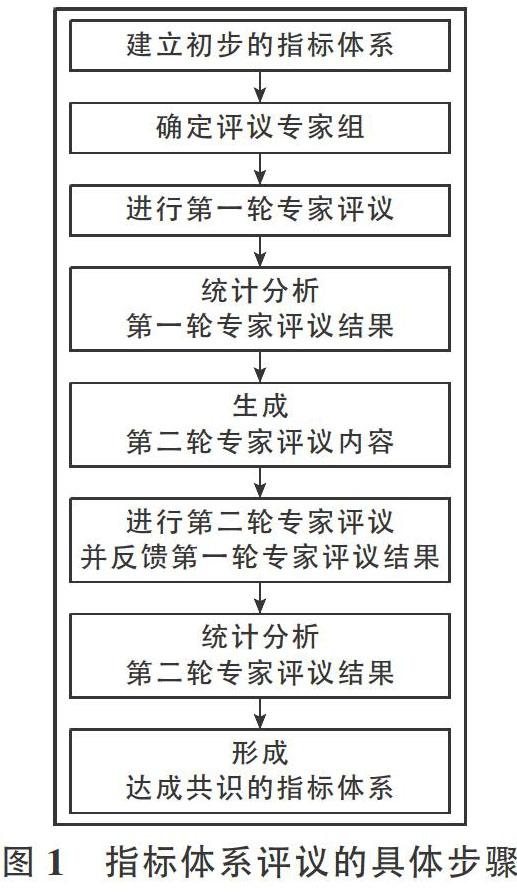
本文采用德尔菲法进行科学数据素养能力指标体系的专家评议(具体步骤见图1)。通过充分吸收不同专家的经验和学识,保证指标预测与评价结论的可靠性、客观性。
2.2 评价指标的初步拟定
建立评价指标体系的目的就是用一种能够获得公众认可的价值标准来衡量和判断事物的价值[14]。科学数据素养能力指标体系是将科研人员从事科学研究过程中应该具备的数据能力科学化、具体化、细化为一系列相互联系的指标集合,从而更为客观和公正地分析和评价科研人员的科学数据素养水平。
在大量阅读国内外相关领域学者对科学数据素养能力研究文献的基础之上,提取关键性能力表征要素,并结合笔者对我国科研人员科学数据素养能力的本土化特征研究结果[15],从“个人”“团队”“数据生态”3个维度出发,以科学数据生命周期和科研生命周期为主线,初步设置了18个一级指标能力域,以及表征每个能力域中具体能力要素的51个二级指标(见表1)。同时,结合教育目标评价理论,从认知、技能、情感三大领域目标入手,对各二级指标进行了详细地描述,最终完成“科学数据素养能力指标体系”的初步拟定[16]。
2.3 专家评议过程
2.3.1 第一轮评议程序与内容
第一轮评议程序为,通过电子邮件或递送纸质版的方式将问卷发放给各位评议专家。为了达到最佳的评议效果,随附一封简要的说明信,针对课题研究背景与主要研究目标,向专家详细介绍了指标体系的构建思路与方法,同时说明了所采取的德尔菲法的具体实施步骤,使专家清楚地了解研究内容,掌握指标体系的评议基础。
“科学数据素养能力指标体系专家评议问卷(第一轮)”的评议内容主要包括5个方面:(1)各项指标的“必要性”;(2)各项指标描述的“明确性”;(3)针对每项指标提出修改意见;(4)补充各个维度中需要补充的指标;(5)采用开放式问题的方式,请专家提出对整个指标体系的意见或建议。
为了方便结果分析与统计,分别对各项指标做了编码,维度分别表示为“个人”(I)、“团队”(T)、“数据生态”(E);一级指标分别表示为“I1、I2……I10,T1……T3,E1……E5”;二级指标由一级指标代码加顺序号构成,如“I11、I12……T11、T12……E11……E51”。
2.3.2 第二轮評议程序与内容
第二轮评议程序为,通过电子邮件或递送纸质版的方式将第二轮评议问卷发放给各位专家,此次的评议专家全部为已经参加过第一轮指标评议的专家,因此对指标研究的内容和方法已基本了解,无需做出特别说明。
除了“科学数据素养能力指标体系专家评议问卷(第二轮)”以外,同时将第一轮指标评议结果反馈给专家,包括“必要性”和“明确性”分析结果。第二轮评议内容主要包括4个方面:(1)指标的“必要性”评议,对第一轮评议中未达成共识的指标以及经合并修改后的指标进行“必要性”评议;(2)指标的“明确性”评议,对第一轮评议中“明确性”未满足要求的指标和其他修改过的指标进行“明确性”评议;(3)请专家对每项指标提出修改意见;(4)请专家提出对整个指标体系的意见或建议。
2.4 数据分析方法
2.4.1 指标“必要性”评议数据的分析方法
(1)李克特五点量表法。将第一轮评议问卷中“必要性”一栏的专家评议选项划分为5个等级,并分别赋值,即:5 非常必要—计5分;4 必要—计4分;3 一般—计3分;2 不太必要—计2分;1 不必要—计1分。
(2)众数法。“众数”是指一组数据中出现次数最多的那个数据。本论文采用众数法判断专家意见的集中趋势,专家意见中出现比例最高的选项,即作为指标的“必要性”等级。对于一组数据,众数可能是唯一,也可能多于一个。在本文“必要性”的评议数据中,21位专家对“科学数据素养能力指标体系”中各项指标的“必要性”等级进行了判定,形成一个由21个数据构成的数据组,众数最少1个,最多4个,因此,专家意见有可能集中在一个或几个选项上。
(3)四分位差法。“四分位数”是指在统计学中把所有数值由小到大排列成一个数列,并分成四等份,处于三个分割点位置的数值。四分位数共有3个,第1个四分位数称为下四分位数,通常用Q1表示,表示位于数列中第25%位置的数字,第2个四分位数称为中位数,用Q2表示,表示位于数列中第50%的数字,第3个四分位数称为上四分位数,用Q3表示,表示位于数列中第75%的数字。
“四分位差”表示第3个四分位数(Q3)与第1个四分位数(Q1)的差距,用Q.D.表示。计算公式为:
Q.D.=Q3-Q1 (式1)
针对本文的“必要性”评议数据,Q.D.的取值区间为{0,0.5,1,1.5,2,2.5,3,3.5,4}。经分析,可以认为当Q.D.=0或者Q.D.=0.5时,该项指标的专家评议意见基本达成共识。
(4)“必要性”判定。针对某项指标“必要性”的专家评议结果,共有5个选项,即:“5 非常必要;4 必要;3 一般;2 不太必要;1 不必要”;通过计算某个选项的专家数在专家总数中所占的百分数,可以看出该项指标专家意见的分布情况。将“5 非常必要”和“4 必要”两个选项的专家百分数相加,即得出该项指标的“必要性”百分数。按照本文的研究要求,当“必要性”百分数<60%,则认为该指标不必要,可以从指标体系中剔除。
综合采用李克特五点量表、众数法、四分位差和“必要性”判定法,进行“必要性”评议数据的分析。对于任一项指标而言:当指标只有1个众数的时候,则采用四分位差判断该众数是否是专家组達成的共识意见;当指标有2个、3个或4个众数的时候,说明专家组意见未达成共识。
根据以上分析结果,结合专家评议的“必要性”比重,判断指标的取舍;并且按照专家意见修改指标内容,在下一轮调查问卷中请专家再次评议该指标的“必要性”。
2.4.2 指标“明确性”评议数据的分析方法
采用李克特五点量表、算数平均值分析方法来判断指标的“明确性”。
(1)李克特五点量表法。将第一轮评议问卷中“明确性”一栏的专家评议选项划分为5个等级,并分别赋值,即:5 非常明确—计5分;4 明确—计4分;3 一般—计3分;2 模糊—计2分;1 非常模糊—计1分。
(2)算术平均值。算术平均值可以用来表征一组数据的集中趋势。本文以“明确性”评议数据组的平均值作为全体专家对该项指标“明确性”的集中意见。计算公式为:
(式2)
其中,n=21,xi∈{1,2,3,4,5}
当■>4时,则认为该项指标的“明确性”达到本论文的研究要求[17]。
2.5 结果分析
2.5.1 专家评议结果概况
(1)专家评议的基本情况。选择专家是德尔菲法成败的关键。德尔菲法所选取的专家应该是对研究问题有一定的了解程度、并能够从同一个角度去理解项目分类和有关定义的人。专家的权威程度要高,具备较高的理论水平和丰富的实践经验,能够提出独到见解和有价值的判断。专家人数需根据研究项目涉及的知识范围、专家意见表的回收率等综合确定,既要保证专家所属学科的代表性、又要有利于评议组织和实施、数据分析与处理的顺利进行。根据有关文献报道,因研究课题的规模大小以及涉及面的宽窄,专家人数一般以15-50人为宜[18]。
本文评议的内容是科研人员的科学数据素养能力指标体系,所需要的评议人员由从事数据素养教育的专家以及科研第一线的专家学者共同组成。通过与所邀请专家的沟通联络,确定参加项目评议的专家有足够的热情与时间进行评议。第一轮共邀请了23位专家构成评议专家组。在所有参加评议的专家成员中,表示对项目主题很熟悉的有15位,占65.2%;表示熟悉的有8位,占34.8%,没有人员表示不熟悉(评议专家组的基本情况见表2)。
(2)专家评议表的回收情况。专家评议表的回收率(回收率=完成咨询的专家数/全部专家数),也称为专家积极系数,通常用来反映评议专家对研究问题的关心程度。本研究共进行了两轮德尔菲专家咨询,第一轮发放问卷23份,收回21份,第二轮发放21份,收回21份,且均为有效问卷,其积极系数分别为91.3%、100%(见表3),这表明专家对本研究的主题非常关心,参与程度很高。
2.5.2 第一轮专家评议结果分析
(1)“必要性”和“明确性”评议结果。经分析第一轮各指标的“必要性”和“明确性”评议结果数据可知:
在第一轮“必要性”专家评议中,“科学数据素养能力指标体系(初稿)”中的51项二级指标,共有39项指标达成共识,成为必要的指标;另有12项指标未达成共识,需要根据专家意见进行相应修改,然后进入下一轮“必要性”评议;其中有2项指标的“必要性”百分比小于60%,分别为:“了解所有数据保存都有成本”“认识到元数据遵循一定标准,并按照学科规范将其应用于数据集,解读外部数据源的元数据”。
因此,可将这2项指标从指标体系中剔除,根据专家意见,将相关内容合并到其他指标中去。
在第一轮“明确性”专家评议的51项指标中,共有33项的“明确性”达到本文研究的要求,另外19项指标的“明确性”还有待提高;即使在39项达成共识的指标中,也有9项指标“明确性”未达标。需要结合指标的“必要性”判定,对“明确性”未达标的指标进行相应修改,然后进入下一轮“明确性”专家评议。
(2)第一轮专家修改意见。专家组对指标体系的整体框架表示认可,对“维度”和“一级指标”的设置均未提出任何异议,认为整个指标体系设计的较为系统而且全面,内容也很详实。有专家指出其中部分指标所涉及的内容专业性较强,如“数据管理”部分的相关术语,非专业人士理解起来会存在一定困难,将影响到评价结果的可靠性;还有专家表示不同学科领域的科学数据素养能力侧重点不同,期望能够按照学科特性设计出更有针对性的指标体系;有专家建议在定性评估的基础上,增加定量评估的指标,使评估更加科学有效;有专家指出如果针对指标体系拟定一些潜在的应用者,实施评价和考核会具有更强的指导意义。另外,专家对每项指标给出了详细的修改意见,限于篇幅,此处不做详述。
(3)第一轮修改后的指标体系。根据第一轮专家评议的结果,综合考虑专家对指标“必要性”和“明确性”的判定,以及专家的修改建议,我们对初步设计的“科学数据素养能力指标体系”进行了相应的修改,形成第二轮专家评议问卷。
2.5.3 第二轮专家评议结果分析
(1)数据分析方法。第二轮专家评议的数据分析方法与第一轮相同。
(2)数据分析结果。①“必要性”和“明确性”评议结果。经分析第二轮各指标的“必要性”和“明确性”评议结果数据可知:在第二轮“必要性”专家评议中,对第一轮评议中未达成共识的12项指标,专家意见已全部达成共识,且“必要性”百分比均大于80%。第一轮评议中“明确性”未满足要求的指标和其他修改过的指标共计35条,在第二轮的专家评议中,“明确性”均已达标,而且大多数指标的“明确性”比第一轮指标描述有明显提升;②第二轮专家修改意见。专家普遍认为与第一轮指标体系相比,经修改后的指标体系,其指标设置更为清晰合理,而且重要性和可操作性都有所增强。此外,专家对各二级指标的逻辑性提出了一些改进建议,如I12与I14,I23与I25,I33与I35,建议互换排列顺序,以使指标更好地反映数据操作的流程。
经过两轮德尔菲专家评议,充分综合了各学科领域专家的智慧和经验,对指标体系进行了全面细致的修改。经指标删减、增加、合并、顺序调整、以及指标表述方式的修改,最终形成由3个维度、18个一级指标、47个二级指标共同构成的“科学数据素养能力指标体系”[19],保证了指标体系的科学性、通用性、前瞻性和可操作性。
3 科学数据素养能力指标权重的确定
采用德尔菲方法对科学数据素养指标体系进行了两轮专家评议与分析研究,形成了针对科研人员科学数据素养的较为全面的能力指标体系。然而,作为一个完整的评价指标体系,除了需要具备定性指标之外,还需要通过定量评价来反映被研究群体的科学数据素养水平,即确定各项指标在科学数据素养能力评价指标体系中的权重。
权重是能力指标体系的重要组成部分,科学合理地确定各级指标的权重,是量化评价质量的根本保证。目前计算指标权重较为有效的量化方法中最常用的是層次分析法(The Analytical Hierarchy Process,AHP),是将价值和判断结合为一个逻辑整体,依赖于想象、经验和知识去构造问题所处的递阶层次,并根据逻辑、直觉和经验去给出判断[20]。本文采用层次分析法确定指标体系中各级指标权重的基本步骤如下:
3.1 建立层次结构
基于“科学数据素养能力指标体系”,建立递阶层次结构(见图2)。将指标体系分为四个层次,最上层为“科学数据素养能力评估”目标层,以下依次为维度层、一、二级指标层。
3.2 构造判断矩阵
判断矩阵表示针对上一层次某元素,本层次与之有关元素之间相互重要性的比较。在图2中,目标层与维度层有关联,可以构造判断矩阵(见表4),其中,Cit表示对于目标层而言,I与T两元素之间的相对重要性比较数值标度(两两比较矩阵中使用的重要性标度及其含义参见表5)。
在专家评议问卷中,设计了“目标—维度层(W—维度)”“个人维度—一级指标层(I—I)”“团队维度—一级指标层(T—T)”“数据生态维度—一级指标层(E—E)”4个判断矩阵表,请专家对 “一级指标”和“指标维度”的重要性等级进行评定。
3.3 单层次排序及一致性检验
3.3.1 原始数据分析
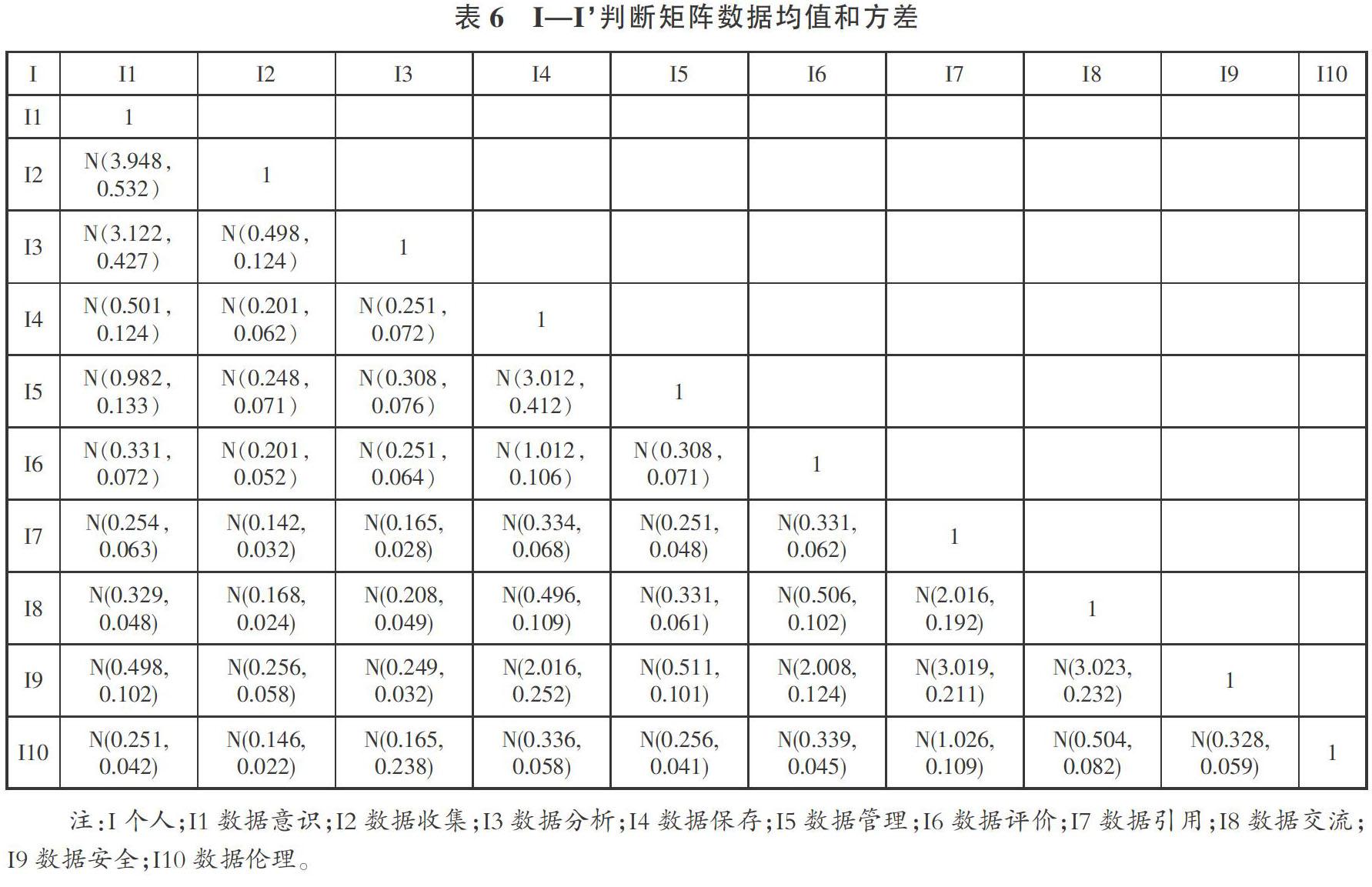
共21位专家参与了评议,对判断矩阵中的数据进行统计分析(具体均值和方差见表6、表7、表8、表9)。
3.3.2 单层次权重计算
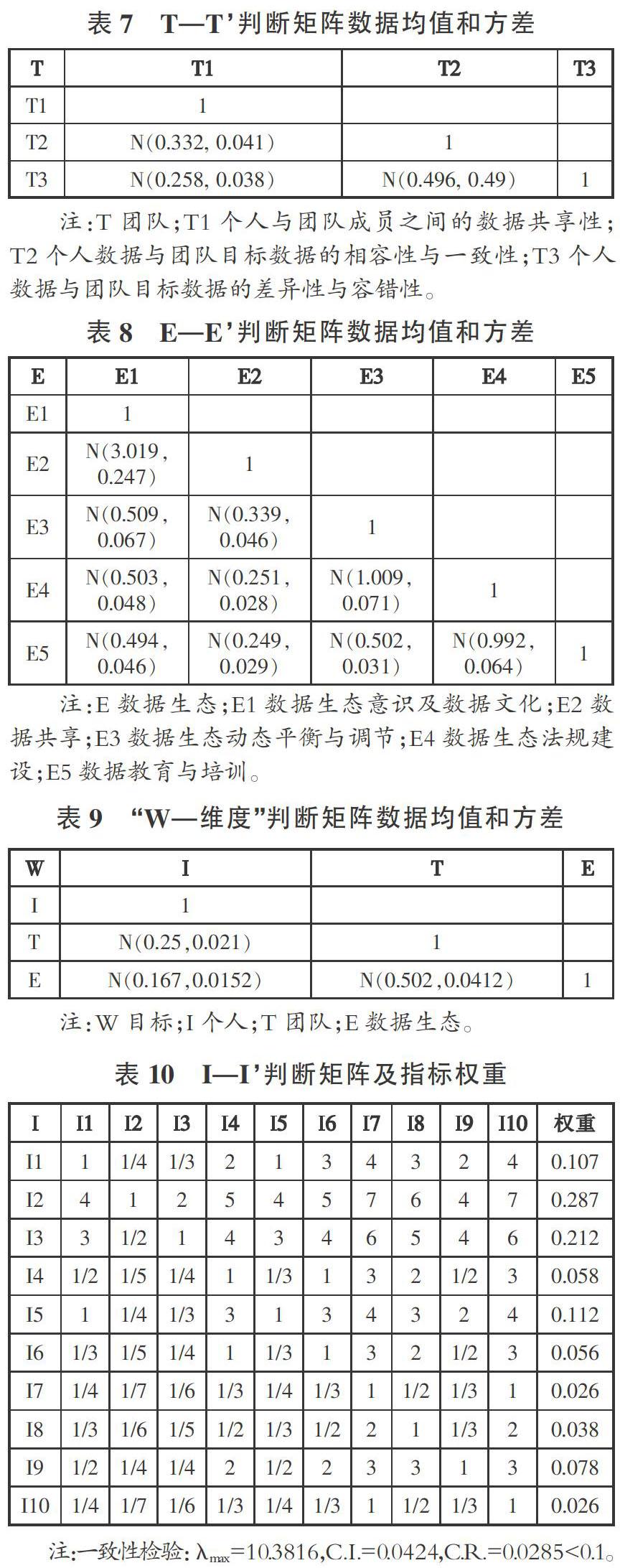
以上数据是对21位专家评议数据的统计,使用层次分析法需要量值为1,3,5,7,9(中间值为2,4,6,8),与之对称矩阵的量值是1/3,1/5,1/7,1/9(1/2,1/4,1/6,1/8)。因此将上面表格中的数据圆整到与层次分析法相对应的量值(见表10、表11、表12、表13)。
按照权重的计算方法,计算各指标权重,并进行一致性检验。
由以上分析可见,“目标—维度层(W—维度)”“个人维度—一级指标层(I—I)”“团队维度—一级指标层(T—T)”“数据生态维度—一级指标层(E—E)”4个判断矩阵都具有满意的一致性。
3.4 层次总排序
确定出上述各项具体指标的排序权重后,乘以100再圆整,即得出指标体系中各项评价指标的初始加权值(见表14)。
由于二级指标是根据一级指标的内涵要求而进行的能力细分,而且每个二级指标在整个指标体系中所占的绝对比重不大,因此,在本研究中,未对二级指标进行层次分析法权重分配,将在以后的研究中进一步探讨。
4 讨论
4.1 指标筛选的严谨性
本研究在指标筛选时采用了德尔菲法,所咨询的专家不仅有从事数据素养教育的教师,还有在科研一线工作的学者。为了保证指标体系的科学性与导向性、超前性与可持续性,特选取了副教授职称以上的专家,他们对调查内容的熟悉程度和权威性较高,确保了本次德尔菲专家咨询的可信度。考虑到调查的普遍性和学科的综合性,专家的学科背景既有理科、工科、又有人文、经管、社会科学等,保证了最终评议产生的科学数据素养能力指标体系是通用层次的。在分析评议结果时,除了对各指标的“必要性”和“明确性”进行了科学计算,同时在指标的表述和筛选中充分参考了专家反馈的修改意见,以及在访谈中提到的实际情况,避免了片面依靠评分的弊端。
4.2 指标体系的初步建立
本文依据指标体系的构建原则,经过两轮德尔菲专家评议,最终形成由3个维度,18个一级指标和47个二级指标共同构成的“科学数据素养能力指标体系”。同时,采用简洁实用而且系统性较强的层次分析法进行指标权重的确定,基于21位学科领域专家对指标体系中3个维度和18个一级指标进行了重要性标度,经数据统计与分析,分别计算出指标层次单排序和总排序的权重值,从而完成了定性描述与定量评价相结合的科学数据素养能力指标体系,为开展全方位、针对性的科学数据素养能力评价与教育方案设计提供了科学的评价标准和量化测评工具。此外,在指标体系构建过程中,请专家对每个指标的知识、技能和态度层面进行了相对重要性判定,形成集众专家判断意见的“科学数据素养指标体系‘知识-技能-态度重要性测度表”[16],可供科学数据素养教学内容设计时做参考,以利于在整个教育过程中有重点有步骤、循序渐进地实现能力培养。
4.3 指标体系的可操作性
科学数据素养能力培养的实践和成效都需要一定的标准进行指导和衡量。本文所构建的科学数据素养能力指标体系,正是从数据密集型科研时代个体所应该具备的数据能力出发,通过多维度的指标表征,对每个指标进行了知识、技能和态度层面的细致描述,包括能力说明、行为方式、情境示例等,综合反映具体能力要求与行为结果,具有良好的可测性,为科学数据素养教育内容设计提供了切实的指导。利用科学数据素养能力指标体系,首先,学生可以评估自身的科学数据素养能力,了解自己在科学数据领域所缺乏的知识或技能,并按照指标体系的具体要求有针对性地提高相应的能力;其次,院系教师和图书馆员能够根据科学数据素养指标体系,开发和设计适合不同层级学习者的科学数据素养教育项目;第三,学校教学管理部门通过了解学生的科学数据素养能力和教育需求,从而协调各方资源,支持图书馆等相关机构制定科学数据素养培养方案、开设课程或培训。
4.4 指标体系的适用性
本文设计科学数据素养能力指标体系的出发点是学科通用型,而对于不同的学科,其数据的范围、类型、格式和标准各不相同,即使在宏观范围内的同一领域,或者在单个科研团队或实验室小组的微观领域内,不同的研究目的和研究类型所创建或利用的數据集属性也各不相同。因此,为了更有针对性地评价具体学科领域的科学数据素养能力水平,需要进一步加强针对特定学科属性的科学数据素养指标体系构建。另外,随着数据环境与信息技术的发展,指标内容及其在教育评价工作中的应用效果还需在后期研究中继续完善。
5 结语
科学数据素养能力指标体系反映了数据密集型科研时代下,从事科学研究的相关人员所应该具备的数据利用与管理能力。调研结果显示,我国科研人员在科学数据利用与管理的过程中所表现的科学数据素养核心能力基本与国外保持一致,但也存在一定差异,如在数据管理计划制定与实施、数据共享平台应用等方面与国外相比仍有较大差距,对数据意识、数据安全、数据交流等方面的能力给予了特别关注[15],这些都为构建符合我国国情的科学数据素养能力指标体系提供了基础。随着现代科研的团队合作与协作特征日益明显,数据和学术更加密不可分,共存于知识基础设施的复杂生态系统中。在架构指标体系维度时,不仅要考虑以个人数据管理和利用为核心的能力,同时要将个人在科研团队与数据生态中的能力构成纳入其中,以全面反映大数据时代个体的科学数据素养能力。构建过程中进行了广泛的学科专家评议与论证,保证了指标体系的科学性,这种定性描述与定量评价相结合的指标体系,使其在指导科学数据素养能力评价、相关课程开发与教育实践等方面具有很强的实用性和可操作性,为科研人员数据素养能力评价提供了理论框架与行为指导。
参考文献:
[1] CARLSON J,FOSMIRE M,MILLER C C,et al.Determining data information literacy needs:A study of students and research faculty[J].portal:Libraries and the Academy,2011,11(2):629-657.
[2] OGIER A L,LENER E,MILLER R K.The data literacy advisory team at virginia tech:Developing a content model for data literacy instruction[EB/OL].[2019-01-19].http://docs.lib.purdue.edu/cgi/viewcontent.cgi?article=1054&context=dilsymposium.
[3] PRADO J C,MARZAL M?魣.Incorporating data literacy into information literacy programs:Core competencies and contents[J].Libri,2013,63(2):123-134.
[4] SCHNEIDER R.Research data literacy[C].European conference on information literacy.Springer International Publishing,2013,397:134-140.
[5] GRILLENBERGER A,ROMEIKE R.Developing a theoretically founded data literacy competency model[C/OL].WIPSCE '18:Proceedings of the 13th Workshop in Primary and Secondary Computing Education,2018,9:1-10.[2019-02-24].https://doi.org/10.1145/3265757.3265766.
[6] RIDSDALE C,ROTHWELL J,SMIT M,et al.Strategies and best practices for data literacy education knowledge synthesis report[J].Journal De Physique IV,2015,105(3):11-18.
[7] Databilities:a data literacy competency framework[R/OL].[2019-03-17].https://docs.wixstatic.com/ugd/1ff4ae_14805e0c8e
f14b54bdafd38e44d5de23.pdf.
[8] 王維佳,曹树金,廖昀赟.数据素养能力评价与大学图书馆数据素养教育的思考[J].图书馆杂志,2016,35(8):96-102.
[9] 刘爱琴,刘蕾蕾,尚珊.MOOC环境下数据素养能力评价模型构建与度量[J].图书馆理论与实践,2018(3):104-109.
[10] 董薇,姜宇飞,张明昊.基于灰色多层次评价模型的数据素养能力评价研究[J].图书馆学刊,2017,39(11):22-29.
[11] 周兵.大数据时代高校教师数据素养的内涵及评价体系探析[J].图书馆研究与工作,2018(1):51-54.
[12] 潘雪,陈雅.我国高校数据素养教育评价指标体系探析[J].新世纪图书馆,2018(7):31-34.
[13] GRAHAM B,REGEHR G,WRIGHT J G,et al.Delphi as a method to establish consensus for diagnostic criteria[J].Journal of Clinical Epidemiology,2003,56(12):1150-1156.
[14] 邱璇,丁韧.高校学生信息素养评价指标体系构建及启示[J].图书情报知识,2009(6):75-80.
[15] 秦小燕,初景利.面向我国科研人员的科学数据素养能力评价研究[J/OL].[2019-09-17].https://kns-cnki-net.e.buaa.edu.cn/kcms/detail/11.1762.G3.20190917.0923.002.html.
[16] 秦小燕.科学数据素养能力指标体系构建与实证研究[D].北京:中国科学院大学,2018.
[17] 宋化民,肖佑恩.科学技术统计学[M].北京:中国石化出版社,1990:117-176.
[18] 孙振球,徐勇勇.医学统计学[M].北京:人民卫生出版社,2002.
[19] 秦小燕,初景利.基于ITE-KSA结构的科学数据素养能力指标体系研究[J].图书与情报,2019(1):115-124.
[20] 孙建军.定量分析方法[M].南京:南京大学出版社,2005.
[21] 杨良斌.信息分析方法与实践[M].长春:东北师范大学出版社,2017:23-35.
作者简介:秦小燕,北京航空航天大学图书馆馆员,博士;初景利,中国科学院文献情报中心期刊出版运营总监,中国科学院大学图书情报与档案管理系教授,博士生导师。
收稿日期:2020-01-20;责任编辑:魏志鹏;通讯作者:初景利(chujl@mail.las.ac.cn)
猜你喜欢
第一财经(2022年6期)2022-06-15
新世纪图书馆(2022年4期)2022-05-31
职业技术教育(2022年8期)2022-05-06
中国水运(2022年4期)2022-04-27
现代商贸工业(2016年24期)2017-01-13
中国科技纵横(2016年20期)2016-12-28
商场现代化(2016年26期)2016-11-21
科技视界(2016年7期)2016-04-01
中国石油大学学报(社会科学版)(2015年5期)2015-11-03
