
基于OpenStack的大规模云负载测试平台研究
2020-10-28 01:44晋文明李昌建
计算机技术与发展 2020年10期
晋文明,李昌建,钱 巨,2
(1.南京航空航天大学 计算机科学与技术学院,江苏 南京 210016;2.江苏省软件新技术与产业协同创新中心,江苏 南京 210023)
0 引 言
随着互联网的普及,以电子商务网站(eBay、亚马逊、淘宝)和典型云服务(如Gmail、OneDrive)为代表的许多大型软件系统承受越来越多的访问流量[1],这给软件系统的服务质量带来了一定的不确定性。负载测试作为软件测试的一种,是为了检测系统在负载方面的相关问题从而对系统进行评估的过程[2]。因而,为了保障大型软件系统服务质量的可靠性,有必要对其进行有效的大规模负载测试[3]。人们研发了LoadRunner[4]、JMeter[5]、httperf[6]等一系列负载测试工具[7],但这些测试工具一般存在两个问题。一是支持的脚本类型过于单一化,二是仅支持采用进程或线程并发方式发起负载,负载生成机制不够丰富,负载生成消耗不够优化,在资源受限的情况下难以生成较大规模的负载。同时,这些测试工具在分布式环境下的部署流程较为复杂,加大了测试的难度。云测试能够降低负载测试的实施难度,在云负载测试服务方面,以阿里云PTS[8]为代表的云测试系统同样存在负载生成不够优化的问题,执行大规模负载测试需要大量云资源作为支撑,增加了测试成本。在云测试工具的相关研究中,文献[9]实现了一个IaaS云平台测试系统,该测试系统的负载生成依赖于Apache JMeter来模拟并发负载,只支持以线程并发方式执行JMeter测试脚本,难以在有限资源下生成较大规模的负载。文献[10]实现了一种自动化云测试平台,基于测试工具Selenium执行测试脚本以实现自动化测试。但Selenium引擎执行开销非常大,导致能够发起的负载规模十分有限,并且该平台主要用于功能测试。文献[11]设计了一个基于云计算的软件测试系统框架,使用动态优先权调度算法实现测试任务的资源分配与执行。其资源分配没有考虑测试任务的资源特征,仅以测试执行时间为优化目标,可能导致测试资源分配不够优化。文献[12]也设计了一个云性能测试工具,支持分布式测试服务器间的同步控制功能,其工作流程为:由控制服务器向测试服务器发送测试执行命令,测试命令保证了所有接收到命令的测试服务器同步执行测试。但是该测试工具只能保证负载测试在初始状态的同步性,无法保证整个测试在不同阶段的同步性。因而,现有研究的测试工具往往存在负载生成机制不够丰富、测试资源分配不够优化等问题,导致大规模负载测试成本过高且不易实施。
为了能够高效地实施大规模负载测试,该文研究了多类型的负载生成、智能化测试资源分配和分布式负载同步控制技术,设计和实现了一种基于OpenStack[13]的大规模云负载测试平台。该平台支持进程、线程和协程负载并发机制,结合多类型测试脚本以生成客户端负载;能够预测负载测试任务的资源需求,并为其确定云测试主机(OpenStack中部署了测试执行引擎的虚拟节点)资源,实现智能化测试资源分配;采用同步控制算法保证不同测试主机间测试进度的同步性。该平台为大规模负载测试提供了一个功能丰富、经济易用的平台,辅助以智能化测试资源分配、分布式负载同步控制等功能保证了负载测试的执行效果,同时可帮助降低大规模负载测试的实施难度。
1 系统结构
基于OpenStack的大规模云负载测试平台的总体界面如图1所示。平台通过导入测试脚本,对待测Web应用进行负载测试,收集相关指标数据,并据此来分析承载Web应用的被测云服务设施的相关表现情况。该平台支持云负载测试执行、分布式负载同步控制、智能化测试资源分配等主要功能,此外,还支持测试脚本管理、测试结果管理等辅助功能。

图1 平台总体界面
为保证灵活性,云测试平台采用如图2所示的物理结构,整个系统由前端Dashboard、测试控制中心CloudTest、测试执行引擎TestAgent、监控器VMMonitor四大基本模块构成。
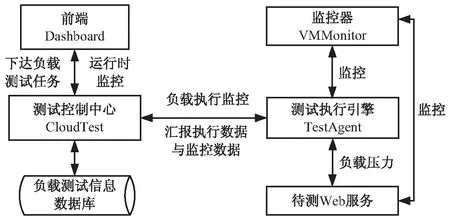
图2 系统物理结构
前端Dashboard是一个Web前端页面,在该页面下,包含测试集群、云应用、云主机、测试脚本、云应用性能测试、测试结果等主页面。测试管理中心CloudTest一方面通过暴露的RESTful接口与Dashboard交互;另一方面与测试执行引擎交互,接收实时负载执行数据;与监控器交互,接收主机的实时监控数据。测试执行引擎是执行负载测试的主要模块,对用户配置的负载测试任务进行解析,按照预设的负载变化策略在指定的时间节点上生成相应规模的负载,发起对被测目标应用的网络调用,并统计每个负载的执行数据,汇报至测试控制中心。监控器周期性地采集宿主机的资源使用信息汇报至测试控制中心。其中,测试控制中心、测试执行引擎、监控器等模块均支持部署在私有云OpenStack上,亦可部署在公有云环境中。
2 支持协程的负载并发机制
由于进程或线程并发是多个子例程通过操作系统时间片轮转来实现,占据资源大、任务切换代价较高,导致进程或线程并发方式下单机的负载执行性能一般。协程是一种程序组件[14],其高性能主要体现在如下几个方面:(1)协程间的切换由用户空间控制,无需操作系统参与,上下文切换的开销极小;(2)协程本身是轻量级的,资源占用小,基本不存在数量限制;(3)协程具有非阻塞异步I/O模型的特性,在IO密集型程序中执行性能非常高。因而,协程可模拟大规模负载。
该云测试平台在支持进程、线程负载并发机制的基础上,引入了协程负载并发机制。Quasar为Java提供了高性能的轻量级线程,使用Quasar Fiber可实现Java协程,平台利用Quasar Fiber和异步Appache Http组件实现并发客户端负载的生成,其主要流程如图3所示。

图3 协程执行流程
如图4所示,平台利用云环境(如,OpenStack)中的测试主机来发起大规模负载测试,通过分布式并发并行调用产生对目标应用的并发客户端负载。测试主机上具体由访问被测目标应用的任务进程、任务进程内的任务线程或任务协程来完成网络访问。不同任务进程、任务线程以及任务协程模拟了不同的虚拟客户端,总的任务进程、任务线程和任务协程的数量大致对应了所生成客户端负载的总体规模。

图4 负载并发机制
3 基于多类型脚本的负载生成
传统负载测试工具支持的脚本过于单一化,导致无法很好地适用于不同的测试目标和目的。文中的云测试平台支持执行Selenium、JMeter、Java等类型的测试脚本,基于多类型测试脚本来生成客户端负载。脚本间比较如表1所示。
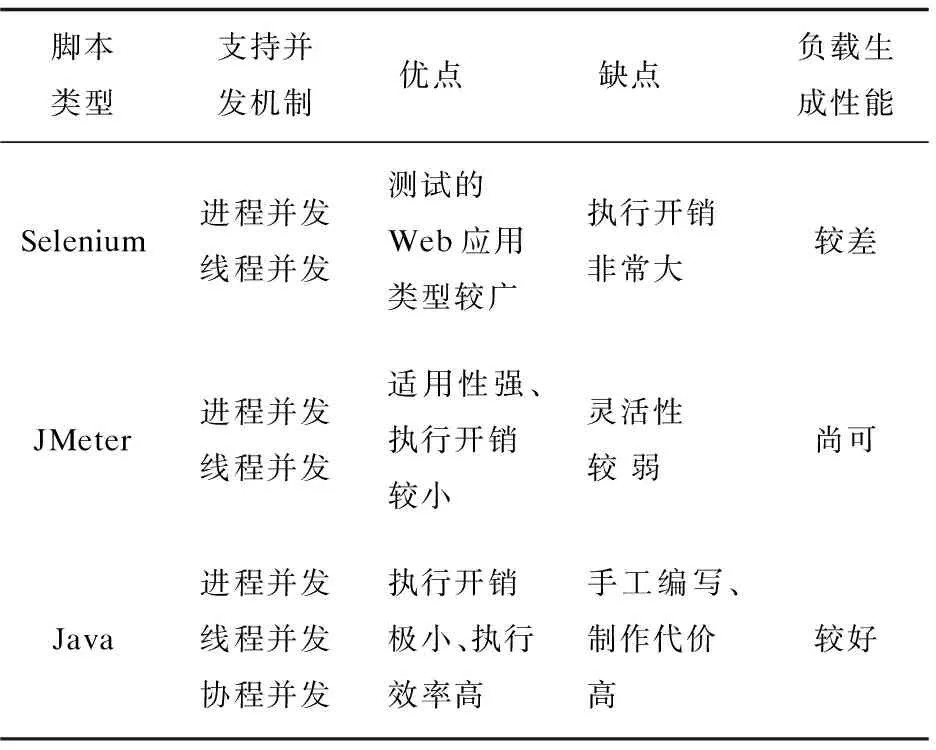
表1 不同类型的测试脚本
如Selenium脚本示例所示的脚本能够描述Web页面的打开、点击等行为,可表达复杂动态页面Web应用上的动作,灵活性最强,能测试的Web应用类型最广。但是脚本的执行开销非常大,并且依赖Python引擎支撑,而当前大部分Python引擎的并发执行性能都较弱。因而,在资源较为一般的测试主机上,很难发起较大规模的负载。
from selenium import webdriver
st=tester();
class Addbook(unittest.TestCase):
def setUp(self):
self.driver=webdriver.Firefox()
self.driver.implicitly_wait(30)
self.base_url="http://192.168.1.130/"
def test_addbook(self):
driver=self.driver
driver.get(self.base_url+"/BookManager?method=list")
driver.find_element_by_link_text(u"添加图书").click()
if __name__ == "__main__":
unittest.main()
如JMeter脚本示例所示的脚本是一段XML配置,描述了一组针对Web应用的网络访问报文。利用JMeter脚本执行引擎可以提取JMeter脚本中所描述的网络报文,对其进行重放。JMeter脚本执行引擎的一个优势是可以直接利用其他工具的脚本。相对Selenium脚本,JMeter脚本的负载生成能力明显更强。然而,JMeter脚本不能像Python脚本那样随意修改,轻松插入新的动作代码,因此,灵活性弱于Selenium脚本。
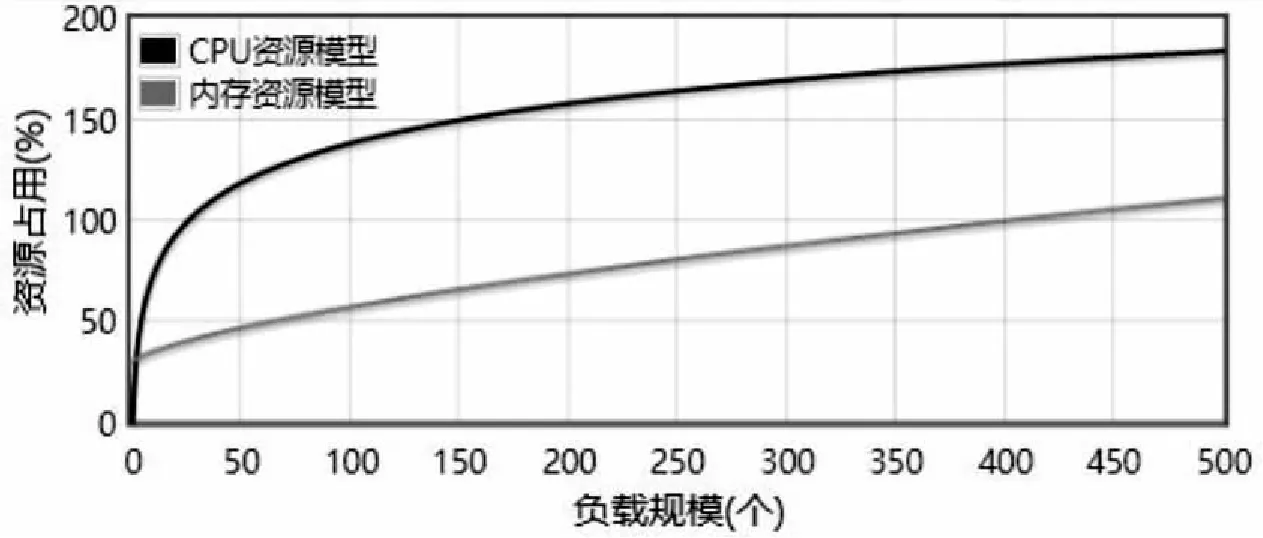
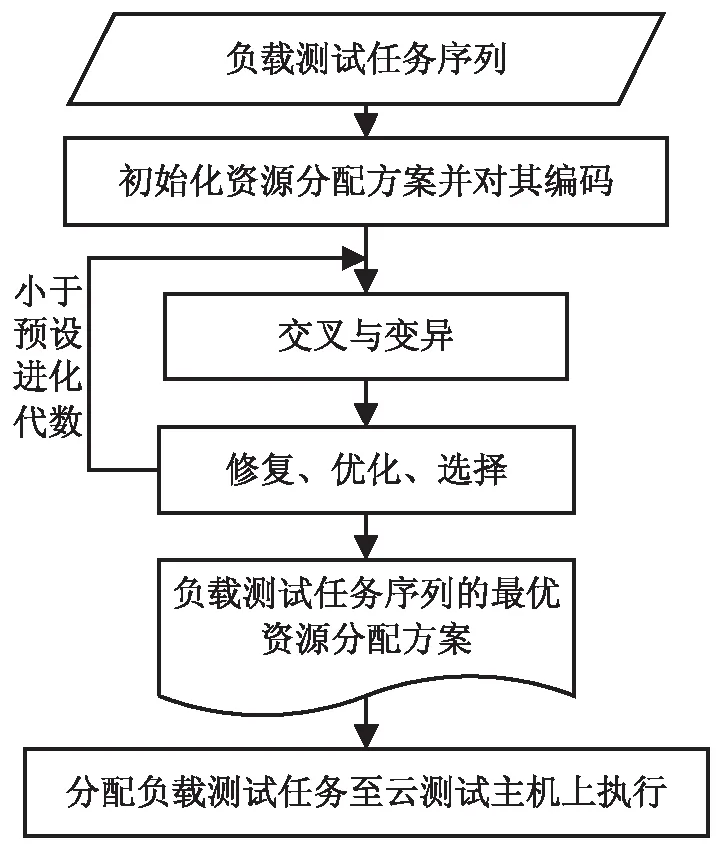
class="HTTPSamplerProxy" testname="Open blazemeter. com"> entType="Arguments"> weibo.com 如Java脚本示例所示的脚本使用Apache HTTP库通信,对网络的访问较为直接,避免JMeter中的脚本解释开销。Java脚本支持协程等高性能机制,依赖于协程并发方式执行脚本,相对于其他测试脚本,其资源开销最低,执行效率最高,在同样的CPU和内存配置下,脚本能够更大规模的并发。然而,此种脚本需要手工编写,且需要事先编译,制作代价较高。 import java.util.*; public class TestCase implements Runnable{ private static String URL = "http://www.baidu.com"; public void run() { ResultStatus status = ResultStatus.PASSED; try { Response response = Request.Get(URL).execute(); StatusLinestatusLine = response. returnResponse().getStatusLine(); int statusCode = statusLine.getStatusCode(); if(statusCode!=200) { status = ResultStatus.FAILED; } } } } 在实施大规模负载测试的过程中,由于单台机器的硬件资源能力较为有限,难以生成较大规模的负载。为了生成足够规模的负载,往往需要多台测试主机同时提供测试服务。分配的主机资源如果过少,将会导致无法发起相应规模的负载;分配的主机资源如果过多,将会造成测试资源的冗余。因而,如何为负载测试任务分配资源显得十分关键。 文中的云测试平台支持智能化测试资源分配功能。平台以每一处理周期内用户下达的负载测试任务的序列T= 对于目标负载测试任务序列T中的每个测试任务Ti,云测试平台按照如下流程预测得到其资源需求向量R= 首先,从平台的测试脚本池中选择目标负载测试任务(假设目标负载规模为5 000)的测试脚本(如,edit_order.jar脚本)作为训练的对象,平台支持为其自动配置一个较小负载规模(一般为500)的测试活动,并在单台测试主机(一般配置为2 CPU核心和4 GB内存,其资源向量可用CPU核心数和内存大小的二维向量(2, 4)表示)上自动执行该测试活动,完成预热执行工作。 第二步,在预热执行过程中,部署在测试主机上的测试执行引擎收集实时负载执行数据L(t)={(t,load)},监控器实时收集测试主机的资源使用数据R(t)={(t,R)},使用处理函数M(X,Y)将负载执行数据和资源使用数据融合,使其在时间节点上对应,得到负载_资源数据LR,可表示为: LR=M(L(t),R(t))={(load,R)} 第三步,以负载资源数据LR作为训练模型的输入,通过回归学习方法,抽取edit_order.jar脚本的资源模型(可用映射f:load→R表示,其输入为目标负载规模load,输出为负载测试任务所需资源向量R)。如图5所示,其中CPU资源模型为fcpu(x)=0.284lnx+0.07,内存资源模型为fram(x)=0.013x2/3+0.29,从而预测负载测试任务的资源需求为(2.49,4.09),则至少需要3台配置为1核心CPU和2 GB内存的云测试主机提供测试服务。重复上述步骤,预测出目标负载测试任务序列中每个测试任务的资源需求向量。 图5 资源模型 对于待分配资源的负载测试任务序列T,基于4.1节所述的方法可预测其资源需求向量为R。云测试平台采用一种基于遗传演化的多目标资源分配算法为T分配云测试资源,其总体执行流程如图6所示。在资源分配的过程中,为了减少资源的浪费,降低测试的成本开销,并保证测试的执行效率,算法以最小资源冗余、最低测试执行成本为一组优化目标,关于目标函数的定义这里不再赘述。 图6 算法执行流程 首先,平台支持获取当前云测试环境OpenStack的网络拓扑结构图(物理节点、虚拟节点以及路由节点间的网络通信结构)。依据网络拓扑结构以及虚拟节点可用资源等信息生成负载测试任务序列T的一组初始化资源分配方案,并按照向量S所示编码方式对资源分配方案进行编码。 然后,对编码后的资源分配方案进行交叉、变异操作,形成初步子代种群。对初步子代种群中的资源分配方案进行修复并优化,确保分配方案的可行性与优越性;父子种群合并,将合并后的种群中的优良分配方案选择进入新的种群,使得分配方案的最小资源冗余、最低测试执行成本等目标朝着更优的方向进化,从而完成一次进化。重复上述过程直至预设进化代数,最终得到目标负载测试任务序列的最优资源分配方案。 最后,平台依据最优资源分配方案,将负载测试任务序列中的各测试任务分配到对应的OpenStack云测试主机上,并由平台对云测试主机进行统一化管理。分配完成后,即可开始目标负载测试任务的执行,平台收集实时负载执行数据以对测试进行运行时监控,从而形成对各负载测试执行的性能评估。 给定如图7所示的云测试环境G和一组资源需求已知的负载测试任务T= 图7 实验环境与实验结果 随着测试的执行,不同测试主机上的测试进度可能差别越来越大,最终导致不同机器上对待测Web应用的访问可能不是按预期来并发的,所产生的负载压力与预期设定不符。 文中的云测试平台支持分布式负载同步控制功能。对每个负载测试配置,测试平台支持为其设定一组同步集合点,典型的同步策略包括按比例同步,即当一定比例的任务进入同步点后,已经进入同步点的任务即可继续向下执行;以及按绝对数量同步,即当某指定数量的任务进入同步点后,已经进入同步点的任务即可继续向下执行。 在为负载测试配置设定了同步集合点后,可以在测试脚本中添加同步集合点进入原语,如含同步集合点的测试脚本示例中的st.rendezvous("dosearch")。测试脚本执行到该同步集合点语句时,会进入等待状态,直到退出同步集合点的条件得到满足。该同步集合点可以使得该集合点后的语句都尽可能在同一时刻得到执行。 st=tester(); class Baidu(unittest.TestCase): def setUp(self): self.driver=webdriver.Firefox() self.base_url="https://www.baidu.com/" def test_baidu(self): driver=self.driver driver.get(self.base_url + "/") st.rendezvous("dosearch") driver.find_element_by_id("su").click() if __name__ == "__main__": unittest.main() 同步集合点仅对负载变化策略中同一时刻点上发起的负载有效。对于原定测试计划中理论上应发生于同一时刻的客户端负载,平台采用同步控制算法以确保同步集合点能够有效发挥作用,保证不同测试主机间测试进度的同步性。同步控制算法的总体流程如下: input:待执行的负载测试活动 output:每个步骤上的有效负载规模的集合∅(load) begin 获取负载变化策略,测试集群的主机数量testClusterSize和负载变化步骤数steps; while step 读取当前步骤上预设的负载规模loadScale; whiletrue 为每个负载启动一个负载执行器; 在负载执行器内执行测试脚本; 脚本进入renderzvous语句后,向测试主机发出enterRendezvous消息; 当前等待执行的脚本数actualLoad++; if actualLoad==loadScale(测试主机满足退出同步集合点的条件) then 测试主机向测试控制中心发出enterRendezvous的消息; 等待执行的测试主机数agentCount++; actualLoad→∅(load); while agentCount 阻塞等待执行的测试主机上进入同步集合点的脚本; end while 测试控制中心向测试集群中各测试主机发出exitRendezvous; 测试主机将同步退出消息转发给各个正在等待的脚本; 脚本收到消息后,继续向下执行测试脚本中的后续语句; end end while end while return ∅(load); end 研究了多类型负载生成、智能化测试资源分配和分布式负载同步控制技术,实现了一种基于OpenStack的大规模云负载测试平台。该平台具有如下特性:支持进程、线程和协程负载并发机制,结合多类型测试脚本生成客户端负载,相较于已有测试工具,客户端负载生成更为高效;支持智能化测试资源分配功能,实现面向云负载测试任务的资源优化分配;支持分布式负载同步控制功能,保证不同测试主机上网络活动的并行性。该测试平台为测试人员实施大规模负载测试提供了一个功能丰富、经济易用的平台,能够降低大规模负载测试的难度。4 智能化测试资源分配
4.1 测试资源预测
4.2 测试资源分配

5 分布式负载同步控制
6 结束语
猜你喜欢
计算机应用与软件(2022年9期)2022-10-10现代电子技术(2022年8期)2022-04-13体育科技文献通报(2022年1期)2022-01-15英语文摘(2020年10期)2020-11-26智富时代(2018年3期)2018-06-11智富时代(2018年3期)2018-06-11电脑爱好者(2018年6期)2018-04-23计算机应用(2016年10期)2017-05-12作文与考试·小学低年级版(2014年9期)2014-12-02作文与考试·小学低年级版(2014年3期)2014-03-21
