
语音信号处理中的识别技术
2020-11-06 06:05王雯婕
科学与财富 2020年22期
王雯婕

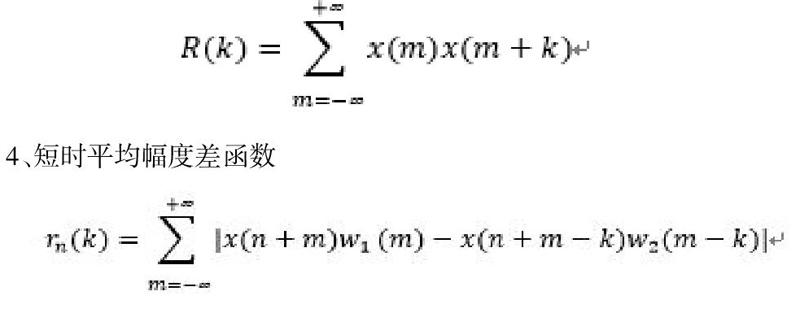
摘要:随着机器学习领域深度学习研究,以及大数据语料的积累,语音识别技术得到突飞猛进的发展,开始从实验室走向市场。语音识别技术已经逐渐进入工业、家电、通信、汽车电子、医疗、家庭服务、消费电子产品等各个领域。本文主要分析和总结了当前几种具有代表性的语音识别方法,介绍了其中关键的语音信号处理和语言模型建立的方法,最后总结了目前语音识别技术领域的研究成果及进展。
关键词:语音识别;信号处理;机器学习;人工智能;概率统计
1研究背景
语音信号处理,主要包括三项技术,即语音识别、语音编码和语音合成。本文所研究的自动语音识别技术,就是让机器通过识别和理解把语音信号转变为相应的文本或命令的高技术。70年代,语音识别技术有了重大突破,动态时间规整技术基本成熟,使语音变得可以等长,另外,矢量量化和隐马尔科夫模型理论也不断完善,为之后语音识别的发展做了铺垫;80年代对语音识别的研究更为彻底,各种语音识别算法被提出,其中的突出成就包括HMM模型人工神经网络;目前许多国内外知名研究机构,如微软、讯飞、Google、IBM都积极开展对深度学习的研究。现在,国内有不少语音识别系统已研制成功。这些系统的性能各具特色——在孤立字大词汇量语音识别方面,最具代表性的要数92年清华大学电子工程系与中国电子器件公司合作研制成功的THED-919特定人语音识别与理解实时系统[4] 。
2语音识别技术
2.1 语音信号采集
语音信号采集是语音信号处理的前提。语音通常通过话筒输入计算机。话筒将声波转换为电压信号,然后通过A/D装置(如声卡)进行采样,从而将连续的电压信号转换为计算机能够处理的数字信号。目前多媒体计算机已经非常普及,声卡、音箱、话筒等已是个人计算机的基本设备。其中声卡是计算机对语音信号进行加工的重要部件,它具有对信号滤波、放大、A/D和D/A转换等功能。而且,现代操作系统都附带录音软件,通过它可以驱动声卡采集语音信号并保存为语音文件。
2.2 语音信号预处理
语音信号号在采集后首先要进行滤波、A/D变换,预加重和端点检测等预处理,然后才能进入识别、合成、增强等实际应用。滤波的目的有两个:一是抑制输入信号中频率超出FS/2的所有分量(FS为采样频率),以防止混叠干扰;二是抑制50Hz的电源工频干扰。因此,滤波器应该是一个带通滤波器。A/D变换是将语音模拟信号转换为数字信号。A/D变换中要对信号进行量化,量化后的信号值与原信号值之间的差值为量化误差,又称为量化噪声。预加重处理的目的是提升高频部分,使信号的频谱变得平坦,保持在低频到高频的整个频带中,能用同样的信噪比求频谱,便于频谱分析。
2.3 语音信号的特征参数提取
1、短时平均能量En和短时平均幅度
短时平均能量和的短时平均幅度主要用途如下:
(1) 可以作为区分清音和浊音的特征参数。
(2) 在信噪比较高的情况下,短时能量还可以作为区分有声和无声的依据。
(3) 可以作为辅助的特征参数用于语音识别中。
2、短时平均过零率
短时平均过零率的应用:可以作为区分清音和浊音的特征参数。清音过零率高,浊音过零率低。用两级判决法进行语音端点检测。
短时平均过零率的局限性:浊音和清音重叠区域只根据短时平均过零率不可能明确地判别清、浊音。
3、短时自相关分析
4、短时平均幅度差函数
5、基音周期估值
语音的浊音信号具有准周期性,其自相关函数在基音周期的整数倍处取最大值。计算两相邻最大峰值间的距离,就可以估计出基音周期。为了突出反映基音周期的信息,同时压缩其他无关信息,减小运算量,自相关计算之前需要对语音信号进行适当预处理。
6、线性预测系数
在语音识别中,常用线性预测编码技术抽取语音特征。线性预测编码的基本思想是:语音信号采样点之间存在相关性,可用过去的若干采样点的线性组合预测当前和将来的采样点值。线性预测系数是以通过使预测信号和实际信号之间的均方误差最小来唯一确定。语音线性预测系数作为语音信号的一种特征参数,已经广泛应用于语音处理各个领域。
2.4 语音识别的主要方法
语音识别所采用的方法一般有模板匹配法、随机模型法和概率语法分析法三种。这三种方法都是建立在最大似然决策贝叶斯(Bayes)判决的基础上的。
(1)模板(template)匹配法
在训练阶段,用户将词汇表中的每一个词依次说一遍,并且将其特征向量作为模板存入模板库。在识别阶段,将输入语音的特征向量序列,依次与模板库中的每个模板进行相似度比较,将相似度最高者作为识别结果输出。
(2) 随机模型法
随机模型法是目前语音识别研究的主流。其突出的代表是隐马尔可夫模型。语音信号在足够短的时间段上的信号特征近似于稳定,而总的过程可看成是依次相对稳定的某一特性过渡到另一特性。隐马尔可夫模型则用概率统计的方法来描述这样一种时变的过程。
(3) 概率語法分析法
这种方法是用于大长度范围的连续语音识别。语音学家通过研究不同的语音语谱图及其变化发现,虽然不同的人说同一些语音时,相应的语谱及其变化有种种差异,但是总有一些共同的特点足以使他们区别于其他语音,也即语音学家提出的“区别性特征”。
除了上面的三种语音识别方法外,还有许多其他的语音识别方法。例如,基于人工神经网络的语音识别方法,是目前的一个研究热点。目前用于语音识别研究的神经网络有BP神经网络、Kohcmen特征映射神经网络等,特别是深度学习用于语音识别取得了长足的进步。
3结束语
本文简要介绍了语音识别的主要方法以及语音识别领域的发展与现状,将语音识别的各个过程进行了详细介绍和概括总结,分析了各种语音识别方法的特点和实现方式。语音识别是一门交叉学科,它涉及到信号处理、模式识别、概率论和信息论、发声机理和听觉机理、人工智能等等方面的知识,所以它的发展依赖于各个领域的技术创新进步。相信在不久的将来,语音识别技术一定会在语音交互、语音检索、命令控制、自动客户服务、机器自动翻译等领域得到广阔的应用。
参考文献:
[1] 赵力.语音信号处理[M].北京:机械工业出版社,2011.
[2] George Dahl、俞栋等.基于预训练的上下文相关深层神经网络的大词汇语音识别.2012
王雯婕

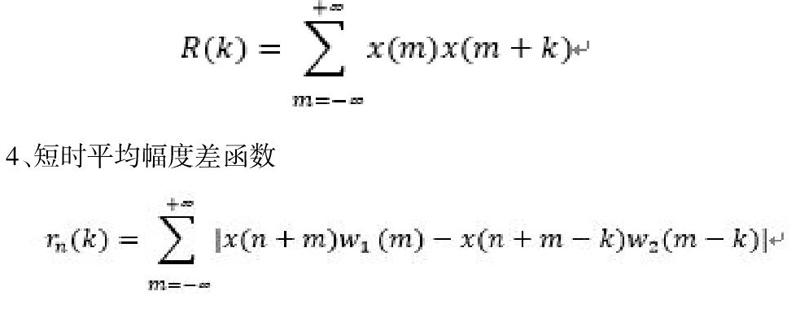
摘要:随着机器学习领域深度学习研究,以及大数据语料的积累,语音识别技术得到突飞猛进的发展,开始从实验室走向市场。语音识别技术已经逐渐进入工业、家电、通信、汽车电子、医疗、家庭服务、消费电子产品等各个领域。本文主要分析和总结了当前几种具有代表性的语音识别方法,介绍了其中关键的语音信号处理和语言模型建立的方法,最后总结了目前语音识别技术领域的研究成果及进展。
关键词:语音识别;信号处理;机器学习;人工智能;概率统计
1研究背景
语音信号处理,主要包括三项技术,即语音识别、语音编码和语音合成。本文所研究的自动语音识别技术,就是让机器通过识别和理解把语音信号转变为相应的文本或命令的高技术。70年代,语音识别技术有了重大突破,动态时间规整技术基本成熟,使语音变得可以等长,另外,矢量量化和隐马尔科夫模型理论也不断完善,为之后语音识别的发展做了铺垫;80年代对语音识别的研究更为彻底,各种语音识别算法被提出,其中的突出成就包括HMM模型人工神经网络;目前许多国内外知名研究机构,如微软、讯飞、Google、IBM都积极开展对深度学习的研究。现在,国内有不少语音识别系统已研制成功。这些系统的性能各具特色——在孤立字大词汇量语音识别方面,最具代表性的要数92年清华大学电子工程系与中国电子器件公司合作研制成功的THED-919特定人语音识别与理解实时系统[4] 。
2语音识别技术
2.1 语音信号采集
语音信号采集是语音信号处理的前提。语音通常通过话筒输入计算机。话筒将声波转换为电压信号,然后通过A/D装置(如声卡)进行采样,从而将连续的电压信号转换为计算机能够处理的数字信号。目前多媒体计算机已经非常普及,声卡、音箱、话筒等已是个人计算机的基本设备。其中声卡是计算机对语音信号进行加工的重要部件,它具有对信号滤波、放大、A/D和D/A转换等功能。而且,现代操作系统都附带录音软件,通过它可以驱动声卡采集语音信号并保存为语音文件。
2.2 语音信号预处理
语音信号号在采集后首先要进行滤波、A/D变换,预加重和端点检测等预处理,然后才能进入识别、合成、增强等实际应用。滤波的目的有两个:一是抑制输入信号中频率超出FS/2的所有分量(FS为采样频率),以防止混叠干扰;二是抑制50Hz的电源工频干扰。因此,滤波器应该是一个带通滤波器。A/D变换是将语音模拟信号转换为数字信号。A/D变换中要对信号进行量化,量化后的信号值与原信号值之间的差值为量化误差,又称为量化噪声。预加重处理的目的是提升高频部分,使信号的频谱变得平坦,保持在低频到高频的整个频带中,能用同样的信噪比求频谱,便于频谱分析。
2.3 语音信号的特征参数提取
1、短时平均能量En和短时平均幅度
短时平均能量和的短时平均幅度主要用途如下:
(1) 可以作为区分清音和浊音的特征参数。
(2) 在信噪比较高的情况下,短时能量还可以作为区分有声和无声的依据。
(3) 可以作为辅助的特征参数用于语音识别中。
2、短时平均过零率
短时平均过零率的应用:可以作为区分清音和浊音的特征参数。清音过零率高,浊音过零率低。用两级判决法进行语音端点检测。
短时平均过零率的局限性:浊音和清音重叠区域只根据短时平均过零率不可能明确地判别清、浊音。
3、短时自相关分析
4、短时平均幅度差函数
5、基音周期估值
语音的浊音信号具有准周期性,其自相关函数在基音周期的整数倍处取最大值。计算两相邻最大峰值间的距离,就可以估计出基音周期。为了突出反映基音周期的信息,同时压缩其他无关信息,减小运算量,自相关计算之前需要对语音信号进行适当预处理。
6、线性预测系数
在语音识别中,常用线性预测编码技术抽取语音特征。线性预测编码的基本思想是:语音信号采样点之间存在相关性,可用过去的若干采样点的线性组合预测当前和将来的采样点值。线性预测系数是以通过使预测信号和实际信号之间的均方误差最小来唯一确定。语音线性预测系数作为语音信号的一种特征参数,已经广泛应用于语音处理各个领域。
2.4 语音识别的主要方法
语音识别所采用的方法一般有模板匹配法、随机模型法和概率语法分析法三种。这三种方法都是建立在最大似然决策贝叶斯(Bayes)判决的基础上的。
(1)模板(template)匹配法
在训练阶段,用户将词汇表中的每一个词依次说一遍,并且将其特征向量作为模板存入模板库。在识别阶段,将输入语音的特征向量序列,依次与模板库中的每个模板进行相似度比较,将相似度最高者作为识别结果输出。
(2) 随机模型法
随机模型法是目前语音识别研究的主流。其突出的代表是隐马尔可夫模型。语音信号在足够短的时间段上的信号特征近似于稳定,而总的过程可看成是依次相对稳定的某一特性过渡到另一特性。隐马尔可夫模型则用概率统计的方法来描述这样一种时变的过程。
(3) 概率語法分析法
这种方法是用于大长度范围的连续语音识别。语音学家通过研究不同的语音语谱图及其变化发现,虽然不同的人说同一些语音时,相应的语谱及其变化有种种差异,但是总有一些共同的特点足以使他们区别于其他语音,也即语音学家提出的“区别性特征”。
除了上面的三种语音识别方法外,还有许多其他的语音识别方法。例如,基于人工神经网络的语音识别方法,是目前的一个研究热点。目前用于语音识别研究的神经网络有BP神经网络、Kohcmen特征映射神经网络等,特别是深度学习用于语音识别取得了长足的进步。
3结束语
本文简要介绍了语音识别的主要方法以及语音识别领域的发展与现状,将语音识别的各个过程进行了详细介绍和概括总结,分析了各种语音识别方法的特点和实现方式。语音识别是一门交叉学科,它涉及到信号处理、模式识别、概率论和信息论、发声机理和听觉机理、人工智能等等方面的知识,所以它的发展依赖于各个领域的技术创新进步。相信在不久的将来,语音识别技术一定会在语音交互、语音检索、命令控制、自动客户服务、机器自动翻译等领域得到广阔的应用。
参考文献:
[1] 赵力.语音信号处理[M].北京:机械工业出版社,2011.
[2] George Dahl、俞栋等.基于预训练的上下文相关深层神经网络的大词汇语音识别.2012
猜你喜欢
中国新通信(2016年21期)2017-01-06
亚太教育(2016年31期)2016-12-12
时代金融(2016年27期)2016-11-25
数学学习与研究(2016年19期)2016-11-22
大学教育(2016年11期)2016-11-16
科教导刊(2016年26期)2016-11-15
考试周刊(2016年79期)2016-10-13
电脑知识与技术(2016年12期)2016-06-14
物联网技术(2015年9期)2015-09-22
物联网技术(2015年3期)2015-03-31
