
基于DTW层次聚类算法的电力负荷数据特征研究
2020-12-17 12:45原野,田园
自动化仪表 2020年12期
原 野,田 园
(云南电网有限责任公司信息中心,云南 昆明 650217)
0 引言
近年来,随着传感器、智能电表、智能变电站等的普及,数据采集与监视控制(supervisory control and data acquisition,SCADA)系统布局的完善,电力工业的信息化进程加速[1]。中国电力企业的信息化建设始于20世纪60年代,最开始是推行电力生产的自动化,接下来是倡导财务的电算化,近年来则是大力推进规模化的信息化建设。特别是随着下一代智能变电站的全面铺开,以物联网大数据为核心的信息技术得到了电力公司的青睐,以能源互联网为总体框架的电力大数据研究开始急剧增长,并形成了一定的规模。电力大数据是中国能源行业变革的关键。这不仅是技术层面的发展,而且是中国电力工业在信息化背景下发展理念、技术架构、管理制度等各方面的重大变革。电力大数据是中国电力工业实现核心价值观塑造以及集约式增长的核心[2]。十二五时期,国家电网在发展部署时指出,全面实施人物财力的集约化使用,推进大建设、大检修、大运行、大营销以及大规划(简称“三集五大”),从而实现国家电力发展的集约式增长。其中:五大体系与电力行业的配、输、传等环节全面呼应,电力大数据的高效利用将在电力行业各环节得到全面体现[3]。
1 电力负荷聚类概述
1.1 用户负荷聚类
目前,按照应用方法,用户负荷聚类可分为直接聚类与间接聚类两大类。直接聚类在用户日负荷曲线的基础上直接聚类,计算复杂,涉及到的数据维度较高[3]。间接聚类则是指对用户日负荷曲线进行预处理后再进行聚类分析,按照处理技术可以分为基于时间序列和基于降维技术两种形式。用户负荷聚类研究如图1所示。

图1 用户负荷聚类研究示意图
由于用户用电数据随时间的变化性较大,与时间成正向关系,呈现海量趋势;另外,由于用户的分散性,导致测量终端具有极强的分散性趋势,因而用户负荷聚类需要对大数据问题进行处理[4]。目前,常用的方法是利用人工智能算法,先对不同区域的用户用电数据进行局部聚类分析;接着利用传统聚类算法构建局部模型对其进行二次聚类,从而得到全局聚类模型;最后,将全局聚类结果反馈到局部数据中心,实现全局聚类最优分析。对用户负荷聚类的研究具有多方面的积极作用:可以对负荷构成进行系统分析,从而对用户的用电习惯进行调节,实现集约用电;还可以对负荷变化趋势进行分析,从而为管理人员提供决策支持,实现电能的高效利用[5]。
1.2 变电站负荷聚类
变电站负荷聚类按照其状态属性,可以分为负荷静态特性聚类与负荷动态特性聚类两大类。静态负荷特性聚类主要用于理论分析,实际应用较少;动态负荷特性聚类则主要用于负荷建模,实际分析较多[6]。负荷静态特性聚类主要应用人工智能算法进行负荷分类,对负荷影响因素及其关联进行分析。而动态负荷特性聚类的关键在于特征向量的选取。特征向量按照其特征,可以分为运行特征向量、动态特征向量、时间特征向量与参数特征向量。运行特征向量主要包括负荷功率、静态负荷与感应电动机的比值等指标。动态特征向量主要是指感应电动机的特征值。时间特征向量包括年份、季度、月份、周数、天数等指标。参数特征向量则是指负荷相应的模型参数[7]。
变电站负荷聚类的应用主要包括两大领域,分别是负荷建模与负荷预测[8]。常规负荷建模主要应用谱系数平均距离聚类算法,实现对全网负荷的精确分类。聚类算法的非线性映射能力较强,可实现大样本数据中相似样本的提取,因此可以通过负荷聚类实现气候、季节、配电环境、装置参数等各因素对负荷变化的分析,实现精确的负荷预测,为电能管理人员提供方法支持。
2 电力负荷数据特征分析模型
2.1 Hadoop平台技术
Hadoop是一种分布式架构集成开发平台,能够对大数据进行高效、精确处理,应用领域非常广泛[9]。Hadoop的主要构成包括Hbase、Hadoop分布式文件系统(Hadoop distributed file system,HDFS)、MapReduce、Hadoop内核、Zookeeper。其中,最为关键的部分是MapReduce以及HDFS。Hadoop的总控制中心位于Hadoop内核。MapReduce为平台的分布式编程框架,主要功能是对大数据进行处理与挖掘工作。作为Hadoop的协调系统,Zookeeper可以实现复杂服务的封装。作为Hadoop存储结构的Hbase,利用分布式数据库,能够实现大数据的存储。Hadoop平台结构如图2所示。

图2 Hadoop平台结构图
Hadoop数据处理需要解决的最重要问题是大规模数据的存储,仅靠集中式的物理服务器难以满足现实企业与电力部门的需求[10]。因此,要实现系统大规模数据的管理,需要建立大量的分布式服务节点。Hadoop设计了分布式文件系统HDFS,以实现对节点的控制和管理。分布式文件系统作为Hadoop的重要组成部分,各集群由多DateNode节点以及单NameNode节点构成,是一种主从结构。其中:NameNode为控制中心,对整个文件系统进行管理;DateNode作为数据处理模块,主要对数据存储与输出负责,以其强大的容错性以及开源性而受到广大企事业单位的青睐。为了适应分布式存储,HDFS具有较强容错能力、数据块式的存储模式、并行式的访问模式、顺序式的文件访问、大规模数据存储能力等特点[11]。较强的容错能力则要求HDFS具有自检测硬件故障的功能,使数据在故障发生后能够得到快速的恢复,不存在数据丢失,从而保证平台的稳定运行。为了对大规模数据进行处理,要求该系统具有分布式储存能力,能够对多数据节点进行有效管理,使其存储容量随着数据量的增加而不断提升,最终成为一个大型的分部式数据处理文件系统。数据块式的存储模式对HDFS数据块的大小进行了严格要求,将每个数据块的默认容量设定为64 GB,使得数据块的个数最小。此外,要求该系统能够对节点进行随机选择,实现数据的不同节点存储[12]。并行访问模式则要求HDFS对多节点访问模式进行详细设计,实现同一时间点数据在多节点上的并发访问。HDFS基本组成结构如图3所示。

图3 HDFS基本组成结构图
由图3可知,分布式文件系统在运行时会涉及到多模块的协同运作,每个模块实现不同的功能。分布式文件系统访问的基本过程包括目标文件名发送、数据块地址返回、处理结果提交这三大步骤。在目标文件名的发送过程中,需要HDFS与NameNode的协同合作。数据块地址的返回要求NameNode接收到文件名后,通过HDFS对数据块的DataNode地址进行查找,同时将这些地址反馈给客户。而数据处理结果过程要求客户收到DataNode地址后,就开始对数据进行处理,然后将处理结果提交至NameNode。
MapReduce是针对大数据的分布式编程模型,其计算过程主要分为Map处理、Reduce处理以及Shuffle处理三大部分。在Map处理过程中,大规模数据会进行排序处理,同时生成特殊格式的Key键值;接着在系统框架中对其进行储存,并将其发送给下一阶段。在Shuffle处理过程中,系统自动将具有相似或者相同属性的关键值进行合并处理,即合并大键值对的过程。在Reduce过程中,各数据块依据接收键值对数据进行分析处理,最后将处理结果存放在分布式文件系统(distributed file system,DFS)中,同时将其输出。MapReduce的并行计算模型如图4所示。

图4 并行计算模型图
2.2 基于R语言的数据挖掘技术
R语言常用于统计分析、制图等过程。因此,R语言具有统计学的技术,例如线性建模与非线性建模、基于时间序列的统计分析、聚类、景点统计学测试等。同时,R语言具有处理结果可视化的功能。由于其开源性和较强的可用性,因而其应用领域较为宽泛。R语言的实质是一个免费数据解决方案,能够进行全面的统计学习分析,几乎包括了所有的数据分析技术;同时,R语言具有可视化处理功能,能够以图表的形式较直观地展示统计分析结果。此外,R语言可以实现人机交互功能,任何分析操作都具有较强的交互性;其支持处理的数据格式多样,既包括文本文件,又包括数据仓库、数据库等软件数据类型;其兼容性也较高,几乎可在市面上所有的操作系统上运行。
数据挖掘的前提是数据的真实和正确。但是很多时候,采集的数据都不是完整、准确的,因此需要对数据进行预处理,包括统一数据形式、消除数据冗余、填补数据缺失等[13]。电力大数据的采集方式主要为终端装置读数采集,即从变电站、智能表、母线段上获取数据信息,并将这些信息存储至数据库中。常见的电力大数据异常情况包含连续时区某用户用电负荷缺失一个值、某用户用电负荷缺失多个值(用户负荷值大面积缺失以及电力数据出现多个孤立点等)[14]。
电力数据中出现数据缺失情况最常见的思路是用可能值代替缺失值。本次研究采用缺失前三天的负荷数据弥补缺失数据。从源数据库中得到的用户负荷数据属性为时间以及负荷。根据智能表采集规则对数据进行采集,采集频率为20 min/次。若采集数据中出现缺失,研究中利用R语言实现所有用户负荷文件的遍历查询,以与缺失值同时间点的前三天的数据进行填充[15]。
2.3 基于动态时间规整层次聚类算法
聚类算法中常采用欧氏聚类作为计量标准,对聚类对象临近度进行计算。欧氏距离在对数据集合点距离相似度进行计算时具有较强的有效性,但是在涉及时间序列计算时则会出现较大的判断误差。例如,对于时间序列A{1,1,10,2,3,1}、B{1,1,2,10,3,1},若用欧氏距离进行判断会出现较大的不一致性。但实际上这两个时间序列的形状相似度极高。动态时间规整(dynamic time warping,DTW)通过对非线性时间序列距离值的计算,从而找出序列间的最短距离。DTW算法基于动态规划理论。其通过组建一个时间序列点矩阵,以两条时间序列点间的距离为矩阵元素,应用动态规划理论对最短路径进行判定。假设两个时间序列,分别为T=t1,t2,...,tn、D=d1,d2,...dn。首先,构建一个n阶邻接矩阵,邻接矩阵中i、j间的距离就是ti与dj间的欧式距离;通过矩阵邻接矩阵对最小距离路径进行累积;对时间序列间的距离w进行比较。假设w=w1,w2,...,wk,则距离公式为:
wk=(ti-dj)2
(1)
式中:wk为ti到dj的距离。
距离的最小路径如式(2)所示:
(2)
定义累积距离γ(i,j)从时间序列的第一个点开始,每到一个点就进行累加,直至时间序列的最后一个点。其得到的累积距离则为两时间序列之间的相似距离。
γ(i,j)=d(ti,dj)+min{γ(i-1,j-1),γ(i-1,j),γ(i,j-1)}
(3)
以动态转移方程递归的时间序列距离进行累加计算,最终得到最优距离。基于DTW的层次聚类方法准确性较高。但该方法在进行执行时需要生成邻近矩阵,时间复杂度为0。因此,如果直接采用DTW层级聚类算法对电力大数据进行处理,时间复杂度相对较高。这是许多平台不能处理的。对此,提出了基于Hadoop的DTW层次聚类算法。DTW的Hadoop其实现如图5所示。
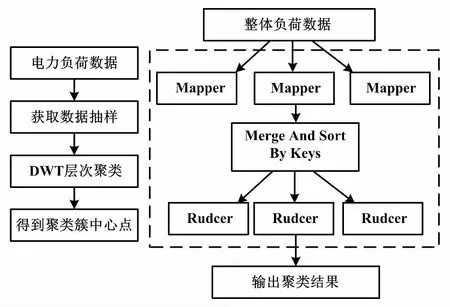
图5 DTW的Hadoop实现
DTW算法需要对时间序列点与点间的距离矩阵进行构建,大规模数据要求较高的时间复杂度,难以对速度和时间进行保证。因此,为了解决此类问题,首先需对电力数据进行抽样,以实现聚类分析。对部分数据的提取基于DTW层次聚类分析法,从而得到数据聚类中心点。接下来,将所有的电力负荷数据全部部署至HDFS中,通过MapReduce程序实现所有负荷数据到聚类中心的DTW距离计算,同时将每个负荷数据进行最近划分,并以此为原则对所有数据进行排序与分类。最后,得到基于所有电力负荷数据的聚类分析结果。基于Hadoop的层次聚类分析法能够克服大规模数据进行聚类分析时的不足,同时,通过Hadoop集群技术可以实现大规模电力负荷数据计算的高效率。
3 试验结果及分析
3.1 试验环境搭建
此次试验的Hadoop集群使用一台主机和三台阿里云服务器进行搭建,同时使用Hadoop2.0版对生产环境进行部署。接下来,对HDFS的HA进行配置。主备NameNode的配置方法有多种。本次试验使用JournalNode方式。利用三个节点作为JournalNode的节点。因为机器数量限制,这三个节点还用作其他服务的节点。为了防止试验运行过程中出现宕机等情况,需要将主、备节点NameNode分别在不同节点上进行部署。主、备节点切换方式可以分为手动和自动两种。其中,自动切换需要对Zookeeper进行部署。本次试验主要运用手动切换模式。接下来对HDFS2.0集群进行部署,以Active NameNode作为NameNode的节点,备份节点采用StandByNameNode,实现主节点出现宕机后的及时替换。利用Journal Node节点实现数据的同步。主备节点主分别在NN1与NN2上进行部署,节点切换利用手动切换模式。
集成R和Hadoop技术主要有三种方法,分别是RHIPE、Hadoop streaming以及RHadoop。本次研究使用RHadoop技术进行整合。RHadoop是一种开源包集合,包含rhdfs、rhbase以及rmr,主要功能是基于R语言环境进行大数据处理。Rhdfs可以在R语言中提供HDFS的接口,从而使得其能够通过HDFS API实现HDFS运行结果的迅速调用。而rmr会在R语言内部提供HDFS的功能接口。在R语言中,将程序分为Map与Reduce两阶段,然后通过rmr包提交试验任务。Rhbase可以通过Thrift服务器对Hadoop Hbase数据源的R语言接口进行操作,从而实现数据的初始化以及读写等功能。RHadoop的环境配置分为两个步骤,分别为在Linux环境下对R语言进行安装、安装RHadoopde 三个开源包。在Linux环境下安装R比较简单,这里不再详细解释。接下来,主要对安装RHadoop的三个包进行详细说明。安装rmr需先安装包digest、itertools以及RJSONIO,因为这些包之间具有相互依赖关系。因为rhdfs对rJAVA的依赖性较强,安装rhdfs则需要安装包rJAVA,最后安装rhbase。安装rhbase需要配置R CMD INSTALL ‘rhbase_1.2.1.tar.gz。完成上述R与Hadoop的包对接以后,在R语言控制台即可对MapReduce进行调用,实现对数据的分析工作。
3.2 试验结果可视化及其分析
选取X省某电网某地区大用户正常工作日的日负荷曲线数据,通过基于Hadoopde平台技术和DTW层次聚类算法对其进行聚类分析,得到了五种类型的用户负荷数据特征。通过R语言实现结果的可视化。五类用户的负荷曲线分别如图6~图10所示。

图6 第一类用户负荷曲线

图7 第二类用户负荷图

图8 第三类用户负荷图

图9 第四类用户负荷图

图10 第五类用户负荷图
由图6可知,第一类用户负荷曲线显示出的平均负荷值较大,可以判断其用户均为大宗用户中的大功率用户。其主要工作时间较长,一般从凌晨持续到早上;同时,其电力负荷波动幅度较大,可以得知其用户属于晚上工作类型。
由图7可知,第二类用户负荷曲线显示出的平均负荷值适中,可以判断其用户属于大宗用户中的中小功率用户。一天时间内出现波峰3次,分别是10~12点、15~17点、19~21点;同时,其电力负荷波动幅度一般,可以得知其用户属于间歇性工作类型。
由图8可知,第三类用户负荷曲线显示出的平均负荷值较大,可以判断其用户属于大宗用户中的中等功率用户。每天除了12~15点有波谷现象出现外,其余时间均保持较高功率,可知其为全天工作类型。
由图9可知,第四类用户负荷曲线显示出的平均负荷值中等偏上,可以判断其用户属于大宗用户中的小功率用户。每天除了7~12点以及15~19点有波峰现象出现外,其余时间均保持较低功率,可知其为集中性工作类型。
由图10可知,第五类用户负荷曲线显示出的平均负荷值中等偏上,同样可以判断其用户属于大宗用户中的小功率用户。较第四类用户不同的是,第五类用户的波峰出现时间为8~18点,可知其为正常工作类型。
4 结论
在对电力负荷数据特征的研究中,关键在于对信息技术的充分利用。本次研究在选取智能算法以及平台技术的基础上,采用基于Hadoop的DTW层次聚类方法对电力负荷数据的特征属性进行研究。研究中,选取X省某电网某地区的大宗用户正常工作日的日负荷数据进行试验。试验结果表明,该地区的大宗用户电力负荷数据可分为长时间大功率用户、间歇性中小功率用户、全天候中等功率用户、集中工作型小功率用户以及正常工作类型的小功率用户五大类。这五个类型的用户用电时间均有较大的差别,一般用电时间长、负荷均值大的用户都属于大功率用户,也符合基本常识;其余用电时间较短的用户,其用电负荷曲线均值较为适中,属于小功率用户。根据上述的分类结果可知,DTW层次聚类算法能够根据用户用电的特征对用户进行分类,不过研究过程中的数据略微偏少,精度仍然稍有欠缺。今后研究的方向在于进一步提高精度,增强用户识别的准确度。
猜你喜欢
纺织标准与质量(2022年2期)2022-07-12
煤气与热力(2022年4期)2022-05-23
长江大学学报(自科版)(2021年6期)2021-02-16
铁道通信信号(2019年6期)2019-10-08
小学生导刊(2018年34期)2018-12-18
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
现代计算机(2016年17期)2016-02-28
山东青年(2016年3期)2016-02-28
母子健康(2015年1期)2015-02-28
