
居民对国产科幻电影的消费舆情分析及票房预测
2020-12-23 09:33周杰梁佳雯何加豪
中国集体经济 2020年34期
周杰 梁佳雯 何加豪


摘要:2019年年初,以《流浪地球》为代表的一股科幻潮流席卷中国。截止2019年3月1日,其票房已达44.50亿。为了研究居民对国产科幻电影的消费情绪,文章选取了电影产地、时长、上映日期、上映首日评分、上映首日评论人次和主演六种影响因素,运用决策树(Decision Tree)和随机森林(Random Forest)算法对国产科幻电影的影响因素进行了深度挖掘。最终以《流浪地球》为例,进行实证分析,从而证明了模型的有效性。
关键词:科幻电影;随机森林;消费舆情;AHP加权平均法
一、文献综述
最早的电影票房影响因素研究可追溯到20世纪中期,为经验性研究。主要有盖洛普对观影观众进行经验性测定,寻找观众感兴趣内容。后期,学者开始建立模型,对电影票房影响因素进行量化研究。如王铮,徐敏基于Logit模型对电影票房影响因素进行研究,得出续集、评分、票价、档期、明星和导演均对票房产生积极影响。在国内学者王丽娟的研究中,电影票房预测可分为“观众研究”、“预测模型”、”更高效的预测模型”三个阶段。然而即便到了预测模型更高效的第三阶段,研究者们仍主要以单一因子进行票房预测,并且采取的数据样本较少。西方电影票房的预测通过分析样本中影响电影票房因素的数据来实现,但其基本以好莱坞电影为样本,以预测美国或北美的票房为目标,很少关注其他国家的情况。
本文以国产科幻电影为研究对象,研究国内居民对国产科幻电影的消费需求,同时在最后给出了相应的票房预测实证分析。
二、研究方法
本研究在前人的基础上,采用了机器学习与大数据分析相结合的方法,将变量深度量化,以获得对国产科幻电影影响显著的因素并预测其票房。
(一)数据获取
在数据获取上,使用python的scrapy爬虫框架、selenium包和fiddle软件分别爬取网页和手机app中的相关资料,并结合分布式网络爬虫技术,高效快捷的从猫眼电影、微博等平台中爬取海量有效资源。
(二)方法选取
1. 决策树CART(Classification And Regression Trees)算法
决策树算法是一类常用的机器学习算法,是基于树形结构来进行决策的。设有数据集D,X、Y分别为输入和输出变量,其中Y是连续变量(回归模型)。包含m个样本的数据集D可以表示为:
找到最优的切分点(j,s)之后,切分点就能将集合切分成总损失最小的两部分。对于切分出來的区域在重复递归这样的划分过程,直到满足条件为止。
2. 随机森林回归算法
随机森林算法是一种重要的基于Bagging的集成学习方法。随机森林可以解释若干自变量(X1,X2,…XK)对因变量Y的作用。如果因变量Y有n 个观测值,有k个自变量与之有关;在构建分类回归树的时候,随机森林会随机的在原数据中重新选择n个观测值,其中有的观测值被选了多次。同时,随机森林随机地从k个自变量选择部分变量进行分类树节点的确定。这样,每次构建的分类树都可能不一样。一般情况下,随机森林会随机的生成几百个至几千个分类树,然后选择重复度最高的树作为最终的结果。
三、影响因素的指标性选择
对于影响因素的选择,本文采用逐步回归法,将变量逐个引入模型,每引入一个变量都进行F检验和该解释变量的t检验,当后面引入的变量使得原先的变量不显著时,删除该变量,以此确保每次引入的变量都是最优的。在研究前人的结论后得出,相关因素可能有电影时长、电影评分、评分人次、电影是产自中国、美国、日本、还是俄罗斯、上映时间是在春节期间(S1)、黄金周(S2)、还是暑假(S3)。经过逐步回归后,我们筛选出显著性水平较高的相关影响因素。
四、科幻电影票房预测
(一)科幻电影影响因素量化
1. 对上映日期的量化
根据电影上映的档期不同将其分为三个档期:贺岁档、黄金周(五一、十一黄金周)、暑期档。分别用S1,S2,S3三个虚拟变量来量化电影上映的档期。
S1=1,贺岁档上映0,其他;S2=1,黄金周上映0,其他;
S3=1,暑期档上映0,其他
2. 对时长、上映首日评分、上映首日评论人次的量化
以分钟为单位,从猫眼电影平台上爬取近五年国产电影的上映首日的评分,并将评分化成十分制。从猫眼电影平台上爬取近五年国产电影上映首日的评论人次,并将该数字转化为以万为单位。
3. 对主演的量化:AHP加权平均法
层次分析法简称AHP,在20世纪70年代中期由美国运筹学家托马斯·塞蒂正式提出。本论文在对主演进行量化时,搜集了该演员近两年来出演电影的票房并加以平均,以此作为衡量该演员的指标。在分析中,若演员个数大于5,则选择能力值前5的演员;若小于等于5,则包含全部演员。定义演员阵容的影响如下:
演员阵容=∑演员综合票房×权重
构造成对比较矩阵,根据演员能力值的大小确定,按能力值从大到小,影响程度设为9,7,5,…。假设演员为两名时,权重分别为0.6和0.4。建立的权重结果如表1所示。
(二)建立决策树与随机森林模型
1. 建立决策树模型
(1)特征选择。特征选择的目的是使得分类后的数据集比较纯,这里就需要引入数据纯度函数。此处我们选取基尼系数作为衡量数据集纯度的指标,其公式为:
在模型初步建立时,我们选取“时长”、“类型”、“评分”、“评论人次”、“上映时间段”、“主演”作为特征,计算数据集的基尼系数增益值。
(2)随机森林回归模型。在机器学习中,随机森林是一个包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数而定。本文基于前文提到的特征,建立出电影票房预测模型。
2. 参数分类
调参的目标就是为了达到整体模型的偏差和方差最优化。进一步,这些参数又可分为两类:过程影响类、子模型影响类。在子模型不变的前提下,某些参数可以通过改变训练的过程,从而影响模型的性能,诸如:“子模型数(n_estimators)”、“学习率(learning_rate)”等。另外,我們还可以通过改变子模型性能来影响整体模型的性能,诸如:“最大树深度(max_depth)”、“分裂条件(criterion)”等。
3. 参数调整
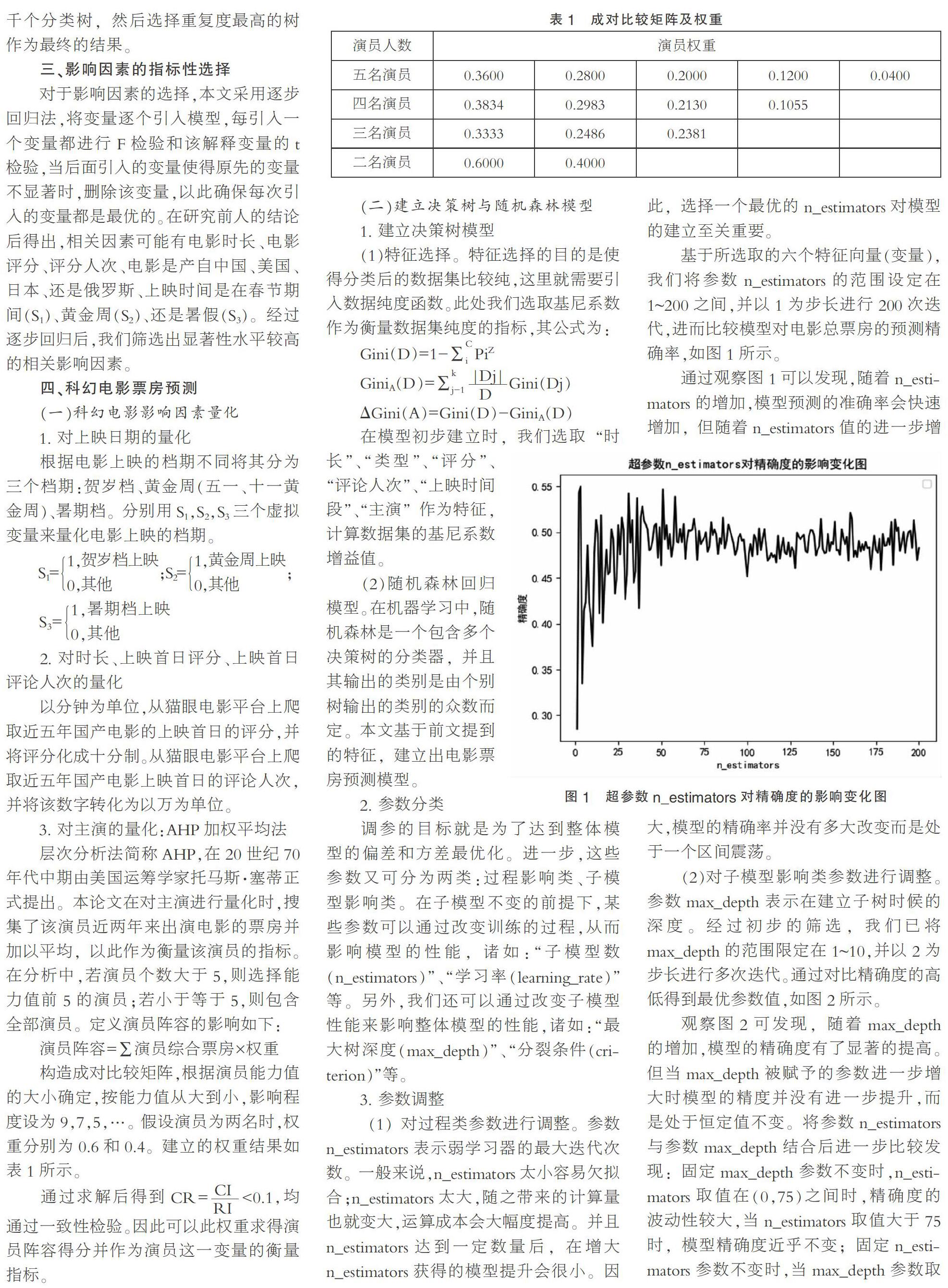
(1)对过程类参数进行调整。参数n_estimators表示弱学习器的最大迭代次数。一般来说,n_estimators太小容易欠拟合;n_estimators太大,随之带来的计算量也就变大,运算成本会大幅度提高。并且n_estimators达到一定数量后,在增大n_estimators获得的模型提升会很小。因此,选择一个最优的n_estimators对模型的建立至关重要。
基于所选取的六个特征向量(变量),我们将参数n_estimators的范围设定在1~200之间,并以1为步长进行200次迭代,进而比较模型对电影总票房的预测精确率,如图1所示。
通过观察图1可以发现,随着n_estimators的增加,模型预测的准确率会快速增加,但随着n_estimators值的进一步增大,模型的精确率并没有多大改变而是处于一个区间震荡。
(2)对子模型影响类参数进行调整。参数max_depth表示在建立子树时候的深度。经过初步的筛选,我们已将max_depth的范围限定在1~10,并以2为步长进行多次迭代。通过对比精确度的高低得到最优参数值,如图2所示。
观察图2可发现,随着max_depth的增加,模型的精确度有了显著的提高。但当max_depth被赋予的参数进一步增大时模型的精度并没有进一步提升,而是处于恒定值不变。将参数n_estimators与参数max_depth结合后进一步比较发现:固定max_depth参数不变时,n_estimators取值在(0,75)之间时,精确度的波动性较大,当n_estimators取值大于75时,模型精确度近乎不变;固定n_estimators参数不变时,当max_depth参数取值从1过度到3时,模型的精确度有了显著提升,但当max_depth取值在(3,10)之间时,模型精确度并没有太大提升。出于降低计算量考虑,通过图2可将这两个参数值分别设置为n_estimators=175、max_depth=7。
4. 参数可行性检验
调参的最终目的是使模型精度的方差最优化,即得到一组方差最小的参数组合。由于方差的比较会受到数据量级的影响,因此,此处我们选取精确度的变异系数作为参数优劣的指标。
通过观察图3容易发现,变异系数会随着n_estimators的增大而减小,最终趋向于某一个值;变异系数同样会随着max_depth的增大而减小,并且同样趋向于某一个值。因而,前文所选取的参数值满足参数调优的要求,并且在现有变量条件下可以认为是最优参数值。
从近五年国产影片的可用数据中随机筛选25条数据作为测试集对建立的模型进行预测。观察图4发现,电影票房的预测值与真实值之间拟合较好,并且计算机反馈出的模型精确率达到86.1%左右,已经处于一个很高的水平。进一步证明了所建模型具有很高的可用性。
五、实证分析
为了检验模型的可行性,本文对用最新上映的国产科幻电影《流浪地球》为例,从票房的预测面进行实证分析。
(一)数据的获取与量化
利用python网络爬虫分别从猫眼电影、微博、艺恩网上爬取所需要的数据并进行量化,量化结果如下。
1.片长
从猫眼电影平台上获取该电影片长为128分钟。
2.上映日期
该电影上映的日期为2019年2月5日,属于春节贺岁档类型。
3.首日评分
猫眼平台反馈的评分信息为9.3。
4.首日评论数
以猫眼电影提供的数据为准。
5.演员
该电影的主演分别是吴京、屈楚萧、李光洁、吴孟达、赵今麦。
(二)模型建立与预测
利用本文建立的随机森林模型,调整参数max_depth=7,n_estimators=175至最优,得到《流浪地球》电影票房的预测值为43.11亿。参照猫眼电影给出的估计值47.52亿作为真实值进行比较。误差在7%左右,处于可以接受的范围内。
(三)预测结果分析
通过上述结果可知《流浪地球》是一部新年贺岁档,且依据上映首日的相关数据,可以推测这是一部极具吸引力的影片,具有很大的市场。因此,影院可以加大对《流浪地球》的排片场次,加大宣传力度。
参考文献:
[1]苏·奥默尔,苏纹.测定愿望:盖洛普和好莱坞的观众研究[J].世界电影1992(04):81-119.
[2]王铮,许敏.电影票房的影响因素分析——基于Logit模型的研究[J].经济问题探索,2013(11):96-102.
[3]Li Zhuang, Feng Jing, Xiao-Yan Zhu. Movie Review Mining and Summarization[C]//Proceedings of the ACM 15th Conference on Information and Knowledge Management.ACM,2006.
[4]方匡南,吴见彬,朱建平,et al.随机森林方法研究综述[J].统计与信息论坛,2011,26(03):32-38.
[5]周元娇.筛选逐步回归方法的改进研究[D].扬州:扬州大学,2011.
*本文为江苏省大学生创新创业训练计划国家级立项——“基于NPL的A股市场舆情监控及其量化投资策略研究”(项目编号:SZDG2019039)成果之一。
(作者单位:南京邮电大学)
猜你喜欢
课堂内外(小学版)(2021年2期)2021-05-18
意林彩版(2019年9期)2019-11-22
科研成果与传播(2019年3期)2019-09-10
安徽农学通报(2017年1期)2017-02-15
软件(2016年7期)2017-02-07
南水北调与水利科技(2016年6期)2017-01-06
电脑知识与技术(2016年23期)2016-11-02
知识就是力量(2016年5期)2016-06-01
现代电子技术(2015年15期)2015-08-14
现代电子技术(2015年8期)2015-07-09
