
面向医院网络舆情分析的情感文本挖掘
2020-12-25 03:16杨雪寒焦玮张倩孟洁
微型电脑应用 2020年12期
杨雪寒, 焦玮, 张倩, 孟洁
(河北医科大学第三医院, 河北 石家庄 050051)
0 引言
互联网中许多社交平台和评论社区为公众提供了大量自由表达意见的平台,这导致与医院相关的公众意见或评论的数据集十分庞大,通过研究这些公众意见,可以分析公众对医患关系、医疗事故争议等与医院相关事件的主观态度和情感取向,从而为取得舆论导向主动权提供科学的数据支撑[1-3]。因此,开展针对医院舆论的文本挖掘和情感分析具有重要的现实意义。为此,本文提出了附加特征、奇异值分解(SVD)[4]和主成分分析(PCA)[5]的情感文本挖掘方法,实现提高分析准确性并减少文本挖掘的时间,并基于词干设计了五个具有不同功能的模块实验,以比较性能并探索哪些因素会影响性能分类精度。本研究的目标如下:1)提出一种基于附加特征方法的情感文本挖掘方法,以提高情感评论大数据分析的分类准确性;2)提出一种特征提取算法,以提高情感分类的准确性;3)利用有效的SVD和PCA文本挖掘方法来减少数据维数,提高情感分类效率。
1 情感文本挖掘方法
情感分类的目标是将文档、文本或评论分类为已标记的情感类别(例如正面、负面、快乐、悲伤等)。情感分类中最具挑战性的工作是如何提高分类结果的准确性。许多因素会影响分析,例如不同的数据预处理方法、情感分类(文档或句子)的级别、所提取各种文本特征、特征词典以及不同的机器学习方法。已有研究表明不同的特征选择方法,例如词语组合、双字、词性(POS)标记[6]、带有POS标记的n-gram序列[7]和词语频率-反向文档频率(TF-IDF)[8]等,会导致情感分类结果的不同。为此,本文将实验扩展到其他特征上以提高准确性,并结合SVD和PCA方法来减小特征维度、缩短文本分类的时间。此外,本研究利用词干设计了五个具有不同功能的模块实验,以比较其性能并发现影响分类器准确性的因素。
本研究所提出的情感文本挖掘方法的过程,如图1所示。
首先,将收集的数据集用于情感分类;然后,采用R统计的标记化,去除的停用词和POS标记的预处理步骤;随后,定义和提取特征,包括TF-IDF、每个文档的情感分数、正负频率以及形容词和副词的数量,之后,应用分类算法训练和预测数据;最后,评估分类结果。

图1 情感文本分类方法
下面结合所收集的数据集对上述方法中五个主要步骤展开阐述以展示该方法的详细过程。
步骤1,数据集收集。所搜集的一个数据集是基于使用Python程序从微博平台中所爬取的数据组成了针对疫苗的用户评论数据集。该数据集由WEB文档组成,包括1 000条正面评论和1 000条负面评论。本研究使用Excel VBA(Microsoft)程序对所爬取的WEB文档进行导入处理,形成带有标签的Excel格式的情感文档。
步骤2,数据预处理。通常从网络收集的数据包含噪声。在实施各种机器学习方法之前,始终需要通过以下五个步骤来处理所收集的数据:标记化、停用词删除、词干与词性标记(POS标记)、特征提取和表现[9-10]。标记化的目的是删除文本中的标点符号。这些标记对分类算法的准确性没有帮助。停用词是在文章中经常使用的词,即“在”、“也”、“的”、“它”、“为”等。这些词会降低分类结果的准确性。词干将单词还原为词根形式,而忽略单词的POS。POS标记是用于识别文本中单个文字的词性不同部分的过程。由于爬取数据经常涉及噪声,因此需要进行特征提取以帮助获得相关信息。此步骤使用了两个称为RTextTools和openNLP的R语言包来处理POS[11]。特征提取将在下面详细讨论。除了特征提取之外,特征选择也是影响分析结果重要的一步。

表1 特征说明
此步骤将所有文档转换为TF-IDF矩阵权重,同时让正负频率形成另一个特征集。接下来,利用POS标记对形容词和副词的数量进行计数,并添加附加特征。TF-IDF参数,如表2所示。特征提取算法,如表3所示。
步骤4,缩减TF-IDF矩阵维度。由于TF-IDF矩阵是具有许多零元素的大型稀疏矩阵,因此分析该矩阵需要耗费大量计算时间。因此,本研究采用SVD和PCA相结合的方法缩减矩阵维度。特征提取后,将预处理的矩阵用作SVD输入。将SVD技术用于分解TF-IDF矩阵,使得接近零的值转

表2 TF-IDF算法参数说明

表3 特征提取算法
换为零。然后,应用PCA技术处理缩小后的矩阵,以进一步缩小矩阵维度。PCA的输出,如表4所示。

表4 PCA降维算法的输出
以本研究从微博等社交平台所收集的疫苗评论数据集为例,经过降维处理后,TF-IDF矩阵维度从2 000×46 467缩减至2 000×2 000。
步骤5,应用四个分类算法训练处理后的数据集以实现对文本的分类,对数据集进行分类。所使用的四个分类算法包括朴素贝叶斯分类算法(NB)[12]、最大熵分类算法(ME)[13]、SVM[14]和随机森林(RF)[15]分类算法。在本研究中,四个分类器的所有参数设置为默认值,并使用10次随机采样和10倍交叉验证来验证准确性。详细说明和参数设置,如表5所示。
步骤6,准确度评估分类算法的性能。使用分类混淆矩阵计算准确度,如表6所示。
以对带有正负标签的文档级情感进行分类。因为本研究所涉及的实验数据集具有明显的正面和负面情绪评论,所以本研究基于混淆矩阵使用来计算分类结果的准确度,如式(1)。

(1)
2 实验验证
基于提出的算法,本研究收集了针对疫苗的公众评论数据集,并利用不同的实验模块进行了实验,并将结果与列表方法进行了比较。数据集从微博等社交平台收集的评论文本。实验数据集的详细属性,如表7所示。
对医院来说,人才是立院之本、发展之基。齐鲁医院副院长陈玉国表示,通过三年住培,培养出了基本功扎实、达到主治医师水平的临床医师,为医院提供了真正“好用”的临床医师,缩短了用人单位与医师的“磨合期”,充实与壮大了医院医疗力量,为医院的人才梯队建设和学科发展提供了优良储备,也为医疗服务质量提供了根本和长远保障。“作为承担住培任务的基地医院,教学相长使其保有优良的教学氛围,提升医院带教医师的能力水平,获得可持续发展、追求卓越的强劲动力。”
2.1 数据集特征
基于TF-IDF的不同参数设置和是否进行词干提取,设计了五个实验模块,并采用列表方法对实验结果进行比较,讨论了哪些因素会影响分类算法的准确性,如表8所示。

表5 分类算法的参数设置
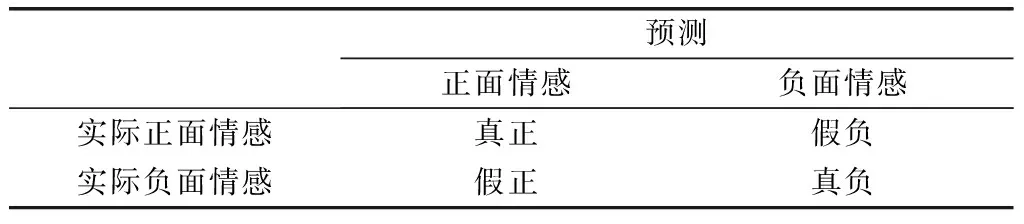
表6 情感分类的混淆矩阵

表7 实验数据集的属性

表8 实验模块
实验在提出的算法的第2步和第3步之后,从特征集中一共提取了46 467个特征。为了测试不同设置的效果,将SVD和 PCA相结合方法与列出的方法进行比较。实验采用十次随机采样和十倍交叉测试方法以验证算法性能,如表9、表10所示。

表9 不降维的实验结果

表10 降维的实验结果
如表9显示,就五个分类算法的平均准确性而言,所建议的具有附加特征的方法要比不具有附加特征的方法更好。在准确性方面,SVM和最大熵分类算法优于其他分类算法。表10显示了在没有词干的情况下,模块1和模块4在缩小和不缩小矩阵大小之间的比较结果。总体而言,在带有和不带有矩阵大小缩减的情况,所提出的具有附加特征的方法要比没有附加特征的方法性能更好。在大多数设置中,SVM和最大熵分类算法更为准确。
5个分类算法的总实现时间,在五个模块中,除了模块5以外,4个模块可以减少运行时间。因此,为该方法中添加附加特征和矩阵降维是可行的,如表11所示。

表11 五个分类算法的运行时间
基于上述实验结果可以发现。
1) 从表9可以看出,在特征提取方面,所提出的方法在模块1和模块4上表现最优。模块4在所有实验中均获得最高的准确度,并且特征数量减少到9.4%(4 366/46 467否)。表11的数据表明,在本实验中的词干特征的分类效果不明显。
2) 从表9和图2可以看出,将附加特征组合到特征集中后,可以提高分类性能,尤其是使用带有径向基函数的SVM算法时。
3) 从表10可以看出,采用附加特征和SVD、PCA相结合的矩阵降维方法可以增强情感分类的性能。此外基于表11的数据可知,采用附加特征和SVD、PCA相结合的矩阵降维方法后算法的运行效率较好,因此该方法具有良好的可行性,如图2所示。

图2 附加特征对不同模块的影响
3 总结
随着互联网在全球范围内的普及,互联网人口覆盖率越来越高,互联网已经成为人们生活,工作和学习的不可或缺的组成部分。因此通过对网络评论进行情感分析,把握公众对医院焦点事件的心里态度和行动趋势,对医院相关部门了解舆论动态和政府相关部门控制舆论导向都具有现实意义。为此本研究提出了一种通过附加特征方法来提高网络文本情感趋向分类准确性,并采用SVD和PCA结合的方法则缩短情感文本挖掘中的实现时间。附加特征包括正面和负面形容词和副词的频率。针对两个实验数据集的测试结果表明,所提出的方法比其他方法具有更高的精度,并且添加附加特征可以提高分类精度。此外,实验数据表明,相对于本实验中的其他算法,SVM和最大熵分类算法被证明是实现情感文本分类的更好选择。将来,本研究从以下两个方面继续进行深入探讨:1)从使用特定于领域的词典来查找或过滤特征、为特征分配不同的权重、考虑文字和文档之间的关系三个方面优化特征选择,以提高分类准确性;2)将该方法应用于医院声誉监控和患者情感检测等不同的应用领域。
猜你喜欢
中国典型病例大全(2022年12期)2022-05-13
建材发展导向(2021年10期)2021-07-16
数学小灵通(1-2年级)(2021年4期)2021-06-09
新世纪智能(语文备考)(2021年11期)2021-03-08
读与写·教育教学版(2017年10期)2017-11-10
初中生世界·七年级(2017年9期)2017-10-13
少儿科学周刊·儿童版(2017年3期)2017-06-29
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
南都周刊(2015年1期)2015-09-10
