
基于BERT的孪生网络计算句子语义相似度
2021-01-12 11:15李景玉
科技资讯 2021年32期
李景玉


摘 要:孪生网络因自身特点被应用于句子相似度计算,但若模型只关注构成句子本身的词语,是无法获得该词语更多的语义信息的。针对这一问题,该文基于BERT模型,提出基于BERT的孪生网络计算句子语义相似度的方法,该方法通过BERT模型,得到具有丰富语义信息的句子向量,再利用该向量在孪生网络中计算相似度。在公开数据集LCQMC上的实验结果表明,基于BERT的孪生网络计算句子语义相似度方法的Accuracy优于基于卷积孪生网络计算句子语义相似度方法。
关键词:BERT 孪生网络 句子向量 句子相似度
中图分类号: TP312 文献标识码:A
Abstract: The Siamese network is applied to sentence similarity computation due to its characters. However, if observe the words of sentence, it can’t get more semantic information from words. According to this problem, A sentence semantic similarity computation based on BERT in Siamese network. Through BERT model, the sentence vector with more semantic information is get. Then using this vector compute sentence similarity in Siamese network. Experimental results on LCQMC datasets shows that the sentence semantic similarity computation method based on BERT in Siamese network is better than the sentence semantic similarity computation method in Siamese CNN architecture.
Key Words: BERT; Siamese network; Sentence vector; Sentence similarity
1 相关工作
计算句子语义相似度是自然语言处理中的一个重要的基础问题,这项技术被广泛地应用于信息检索、问答系统、机器翻译等方面。比如:在信息检索中,需要计算查询项和数据库中文档的匹配,而问答系统中,需要计算查询问题和候选答案之间的匹配程度。而计算句子语义相似度这项基础技术直接影响着上层应用系统的效能,因此目前仍有众多学者热衷于改进句子语义相似度的计算方法。
传统的句子语义相似度计算方法主要有基于编辑距离的句子相似度计算方法[1]、基于词的句子相似度计算方法[2-3]、基于本体词典的句子相似度计算方法[4]等。而随着机器学习的发展,以及深度学习的广泛应用,越来越多的学者开始利用神经网络构建模型来计算句子语义相似度。常用的人工神经网络结构包括卷积神经网络(CNN,Convolutional Neural Networks)和循环神经网络(RNN,Recurrent Neural Network),学者们会利用卷积神经网络获取句子中的局部和全局语义相关关系,以得到文本的综合语义表示,从而计算句子语义相似度[5],同时也会利用依存句法等语义信息构建网络计算句子语义相似度[6-7]。但是使用一个网络结构来学习两个句子需要分成两步,这有可能会造成不一致的问题,因此能够在同一时间同时学习两个句子的孪生网络,走入研究学者的视野。在计算英文句子的语义相似度时,基于字符级别变长序列的双向长短期记忆(LSTM,Bidirectional Long Short-Term Memory)的孪生网络结构[8]表现良好。最近一项研究将基于CNN的孪生网络结构应用于中文句子语义相似度的计算[9]。
该文在文献[9]的研究成果基础上,提出一种通过BERT获取词嵌入向量作为输入,采用孪生网络结构计算句子相似度的方法,该文的主要贡献如下:(1)该文引入句子中词语的词向量作为输入,增强了句子的语义表示;(2)该文在改进了向量间距离的计算公式;(3)该文在孪生网络架构的基础上,应用词向量,有效提升了句子相似度计算的性能。
2 基于BERT的孪生网络算法
2.1 BERT
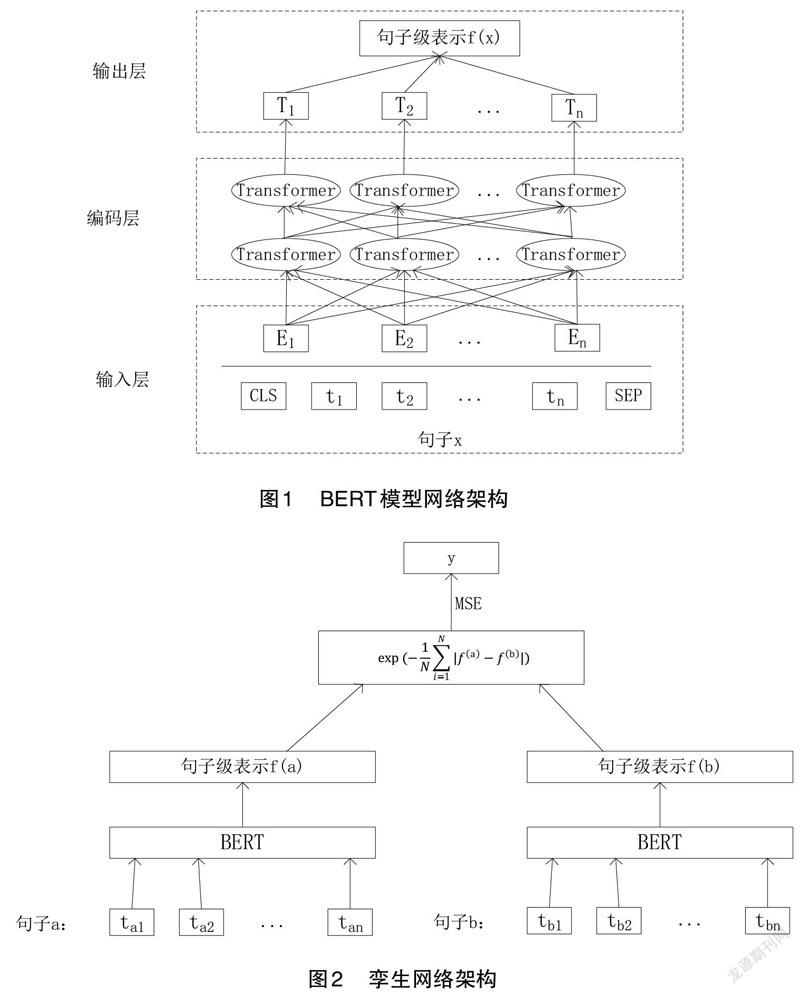
Devlin等人[10]于2018年提出一种基于深层Transformer的预训练语言模型——BERT(Bidirectional Encoder Representation from Transformers)。BERT一经问世,就在多个自然语言处理任务中表现优异,比如信息抽取[11]、文本分类[12]等。而这正是由于BERT能够在大规模无标注文本中挖掘出丰富的语义信息,通过BERT模型可以得到上下文语义表示,再进一步进行后续计算。BERT预训练模型的基本模型结构是由多层Transformer构成,该文在BERT模型结构基础上,结合自身任务设计的网络架構如图1所示。
BERT模型共分为三层:输入层、编码层、输出层。输入层的初始输入为句子和句子开头标识[CLS]、结尾标识[SEP],其中句子根据词表划分后的字符串,记为,由此得到,句子可以表示成字符串的集合。由字嵌入向量、分段嵌入向量、位置编码向量组合而成后,得到BERT输入向量。输入向量经过由多层Transformer构成的编码层后,得到BERT模型的输出向量。该文将若干字符串的输出向量经过计算转换成句子的句子级表示。
2.2 孪生网络架构
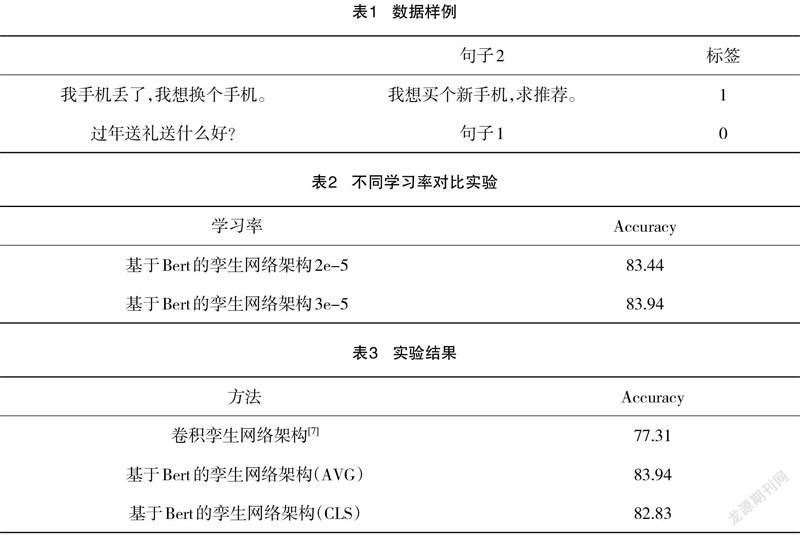
该文构建的孪生网络架构如图2所示。在这个网络架构中,输入数据是通过BERT模型得到句子的句子级表示和句子的句子级表示,通过向量间距离的计算公式得到最终的相似度。
该文在文献[7]采用的距离公式基础上,通过实验比对,得出改进版的曼哈顿距离公式:
其中公式(1)中和是两个句子的句子级表示,设置为BERT模型中超参数隐藏层大小。该文采用文献[7]中公式(1)进行实验时,发现损失率并没有呈现出减小的趋势,故对公式(1)进行了改进,变成对向量差的和求平均值。此时进行实验,发现损失率呈减小的趋势,说明模型学习到了知识,该方法可行。
在向量间相似度计算完成后,使用MSE(mean-square error)作为损失函数,经过计算后得到最终的相似度结果。
3 实验
3.1 实验数据
句子相似度是指两个句子的语义匹配程度,该文将该问题转化为判断两段文本是否相似的二分类任务,即结果采用0和1分别表示句子语义相似和句子语义不相似。该文实验所采用的数据来自哈尔滨工业大学(深圳)[13] LCQMC(A Large-scale Chinese Question Matching Corpus),该数据集由从百度知道不同领域的用户问题中抽取构建,是百度知道领域的中文问题匹配数据集。
数据集中包括238766条训练数据和12500条测试数据,如表1中数据样例所示,标签1表示两个句子为相似文本,标签0表示两个句子为不相似文本。
3.2实验环境
实验计算机硬件配置:Intel Core i9处理器,32GB内存,NVIDIA RTX 2060显卡。
实验计算机软件配置:Windows10 操作系统,Python 3.8,torch 1.9.0,CUDA 11.1。
3.3 评价指标
该文实验用于判断文本的相似度,采用评价指标Accuracy。
3.4 实验结果及分析
该文使用PyTorch版bert-base-chinese构建字符串向量。当设定迭代次数为6次时,分别采用不同的学习率进行对测试集进行预测,得到结果如表1。从表1中我们可以看到,学习率2e-5到3e-5的accuracy的提升并不多,更大的学习率将会使得模型Accuracy降低,故该文模型最终采用学习率3e-5。
在通过BERT模型获得句子级表示时,分为两种主要的处理方式,一种叫作CLS,是指取CLS标志的最后一层输出作为句子向量;另一种叫作AVG,是指句子向量通过取序列最后一层的输出求平均获得。该文分别用两种方式对测试集进行了预测,同时与文献[7]的最好结果进行比较,实验结果如表2。实验发现,使用AVG方式得到的句子级表示在进行相似度计算后,得到的Accuracy最高,达到83.94%。
4 结语
句子相似度计算作为自然语言处理的基础任务,一直受到研究学者的关注。该文通过引入BERT词嵌入向量作为输入,再利用孪生网络架构计算句子相似度。实验结果表明,基于BERT的孪生网络计算句子相似度的方法要优于基于卷积孪生网络计算句子相似度的方法,最终Accuracy达到83.94%,提高6.63%。
参考文献
[1] 车万翔,刘挺,秦兵,等.基于改进编辑距离的中文相似句子检索[J].高技术通讯,2004,14(7):15-19.
[2] 吕学强,任飞亮,黄志丹,等.句子相似模型和最相似句子查找算法[J].东北大学学报:自然科学版,2003(6):531-534.
[3] 杨思春.一种改进的句子相似度计算模型[J].电子科技大学学报,2006(6):956-959.
[4] 刘宏哲.一种基于本体的句子相似度计算方法[J].计算机科学,2013,40(1):251-256.
[5] 李霞,刘承标,章友豪,等.基于局部和全局语义融合的跨语言句子语义相似度计算模型 [J].中文信息学报,2019,33(6):18-26.
[6] 杨萌,李培峰,朱巧明.一种基于Tree-LSTM的句子相似度计算方法[J].北京大学学报:自然科学版,2018,54(3):481-486.
[7] 胡艳霞,王成,李弼程,等.基于多头注意力机制Tree-LSTM的句子语义相似度计算[J].中文信息学报,2020,34(3):23-33.
[8] NECULOIU P.VERSTEEGH M,ROTARU M.Learning Text Similarity with Siamese Recurrent Networks[C]//Proceedings of the 1st Workshop on Representation Learning for NLP.2016:148-157.
[9] SHI H X,WANG C,SAKAI T. A Siamese CNN Architecture for Learning Chinese Sentence Similarity[C]//Proceedings of the 1st Conference of the Asia-Pacifific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing: Student Research Workshop.2020:24-29.
[10]DEVLIN J,CHANG M W,LEEK,et al. BERT:Pre-training of Deep Bidirectional Transformer for Language Understanding[C]//Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies.2019:4171-4186.
[11]杜慧祥,楊文忠,石义乐,等.基于BERT和卷积神经网络的人物关系抽取研究[J].东北大学学报:自然科学版,2021,53(3):49-55.
[12]杨文浩,刘广聪,罗可劲.基于BERT和深层等长卷积的新闻标签分类[J].计算机与现代化,2021(8):94-99.
[13]LIU X,CHEN Q C,DENG C,et al.LCQMC:A Large-scale Chinese Question Matching Corpus[C]//Proceedings of the 27th International Conference on Computational Linguistics.2018:1952-1962.
