
基于BERT的不完全数据情感分类
2021-01-21 03:23陈黎飞
计算机应用 2021年1期
罗 俊,陈黎飞
(1.福建师范大学数学与信息学院,福州 350117;2.数字福建环境监测物联网实验室(福建师范大学),福州 350117)
0 引言
人工智能的第三次浪潮正改变着人们的生活方式,给人们的生活和学习带来极大便利的同时,也使得互联网用户的信息呈爆发式增长。其中用户舆论的情感信息备受企业、政府重视,比如微博上对热点事件的评论,互联网电影数据库(Internet Movie Database,IMDb)对电影的评价等。对用户数据进行情感分类挖掘对企业和政府的发展和运营具有重要的应用价值。
早期的自然语言处理任务中词的特征表示方法主要有词袋(Bag-of-Words)模型[1]和独热编码(One-Hot Encoding)技术,其目的旨在将输入的句子转化为稀疏向量。显然,这种特征表示方法没有考虑单词之间的相关性,且其高维性会耗费大量的计算机内存资源[2]。为了避免高维性问题,以Word2Vec[3]为代表的分布式向量表示(Distributed Representation)[4]技术得以发展,通过将输入的句子表示为词嵌入(Word Embedding)形式,就能利用向量之间的点积衡量句子间语义的相似性程度。
传统的机器学习算法如支持向量机(Support Vector Machine,SVM)[5]、决策树(Decision Tree)[5]常用于情感分类挖掘任务,但这些算法仅适用于样本量少的情况并且容易产生过拟合的问题。随着神经网络[6]的发展,情感分类任务中相继出现平移不变特点的卷积神经网络(Convolutional Neural Networks,CNN)[7]、节点按链式连接的循环神经网络(Recurrent Neural Network,RNN)[8]和有选择性记忆信息的长短期记忆(Long Short-Term Memory,LSTM)[9]等模型。还有一些相关变体,比如结合条件随机场(Conditional Random Field,CRF)的双向LSTM模型[10]、CNN与LSTM结合的多通道策略神经网络模型[11],以及添加注意力机制的双向LSTM 模型[12]等,这些模型增强了情感分类任务中语义信息的相关性,有利于情感极性的判断。
然而,现有的方法大多未考虑不完全数据对情感分类性能的影响。不完全数据常产生于人为的书写表达错误等[13],以微博为例,人们希望用简短的句子来传达信息,并不计较句子中的语法错误或单词拼写错误等,而这些错误信息却容易导致机器无法识别其中的重要信息,进而影响情感分类的效果。针对文本中出现的不完全数据问题,文献[14]提出利用栈式降噪自编码器(Stacked Denoising AutoEncoder,SDAE)对加噪的输入数据进行压缩-解压缩训练来重新构建“干净”完整的数据,在含噪数据的情感分类任务中取得了优于随机森林(Random Forest)等传统机器学习模型的性能。也有研究提出将降噪自编码器网络与词向量结合[15],用于提高分类的准确率;本文也将降噪自编码器运用于提出的模型中以达到对不完全数据去噪的效果。
近年来,情感分类模型的性能得以有效提高得益于预训练模型的发展[16]。预训练模型通过在大规模语料库上进行无监督训练来提取下游任务所需的共有信息,然后对下游任务做基于梯度优化的有监督训练。主流的预训练模型BERT(Bidirectional Encoder Representations from Transformers)[17]是一种能够进行并行计算的注意力机制模型,在自然语言处理的多个数据集上都取得了最佳的结果。由于这些数据集都是预先花费大量时间处理好的“干净”完整的数据集,所以在处理不完整数据集的情感分类时的性能有所下降。在现实生活中不完全数据随处可见,而人为处理大量噪声数据费时费力,有必要对模型加以改进以提高其对不完全数据的分类性能。
基于上述分析,本文提出称为栈式降噪BERT(Stacked Denoising AutoEncoder-BERT,SDAE-BERT)的新模型。新模型通过栈式降噪自编码器对经词嵌入后的原始数据进行去噪训练,为不完整的原始数据重构生成相对完整的数据,接着将其输入到预训练的BERT 模型中进一步改进特征的表示,最终完成不完全数据的情感分类任务。
1 相关基础
1.1 栈式降噪自编码器
自编码器(AutoEncoder,AE)是主成分分析(Principal Component Analysis,PCA)在神经网络中的一种拓展,二者都是通过数据降维来提取重要特征,与PCA 不同的是,自编码器具有非线性变换特点,能够有选择性地提取信息,对于有噪声的数据可以使用降噪自编码器(Denoising AutoEncoder,DAE)进行去噪处理。如果高维数据直接从高维度降至低维度只进行一次非线性变换,可能无法提取某些重要特征,于是可以采用文献[14]提出的栈式降噪自编码器来处理高维度噪声数据问题。如图1 所示,其中带有“×”的数据表示噪声数据,对输入的数据每次编码(解码)都做一次非线性变换,相较于直接从高维到低维能提取和重组更深层的关键特征。
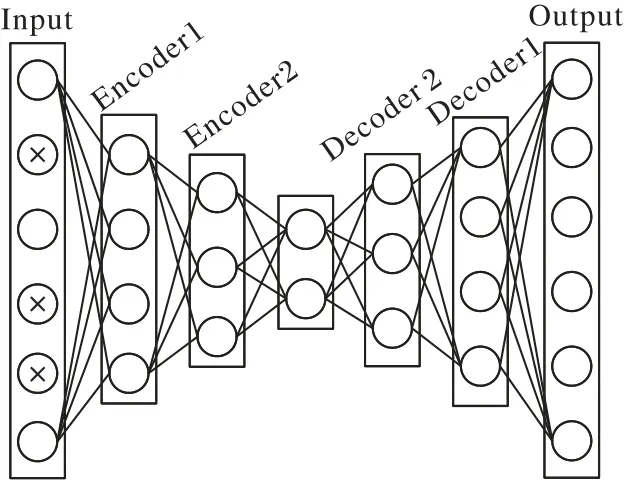
图1 栈式降噪自编码器Fig.1 Stacked denoising autoencoder
1.2 BERT模型
文献[18]提出利用Word2Vec构建神经网络语言模型,使得深度学习在自然语言处理领域变得可行。然而静态的Word2Vec无法解决一词多义问题[19],动态的词向量模型便应运而生,如循环神经网络[8]、长短期记忆网络[9]等。循环神经网络(RNN)的链式结构使得其擅长处理时间序列问题。但实验证明,RNN 长距离记忆能力差,不适合处理长文本的分类问题,同时还存在误差反向传播时的梯度消失和梯度爆炸等问题。为了处理RNN 的短记忆问题,文献[9]提出利用门控方法来解决记忆丢失问题的LSTM 模型。为了提取更深层次的特征表示,文献[17]提出具有双向Transformer 的预训练模型BERT,并且该模型预先编码了大量的语言信息。本文提出的模型将围绕预训练模型BERT 做进一步改进以处理不完全数据的情感分类问题。
1.2.1 输入表示
BERT 模型的输入特征表示由标记词嵌入(Token Embedding)、片段词嵌入(Segment Embedding)、位置词嵌入(Position Embedding)三部分组成,最终输入模型的向量表示由它们的对应位置相加,其中:Token Embedding 是固定维度大小的词向量表示,它的第一个位置[CLS]编码全句的信息可用于分类;Segment Embedding 用0 和1 编码来区分一段话中不同的两个句子;Position Embedding 编码相应词的位置信息。
1.2.2 Transformer编码层
该层是对输入的词向量进行特征提取,使用的是Transformer[20]的编码器端,如图2 所示,其核心部分是多头自注意力模块。注意力机制能计算每一词与句子中的其他词的相关性程度,计算过程中每个词不依赖于前面词的输出,因此注意力机制模型能并行运算。“多头”允许模型在不同的表示子空间学到相关的信息,可以防止过拟合。对注意力模块的输出进行残差连接可避免当前网络层学习的较差,接着进行归一化来提高算法的收敛速度。最后,将多头注意力模块的输出经过全连接后再进行残差连接和归一化。BERT 模型由12 个相同的Transformer 编码层串接而成,以增强网络学习的深度。
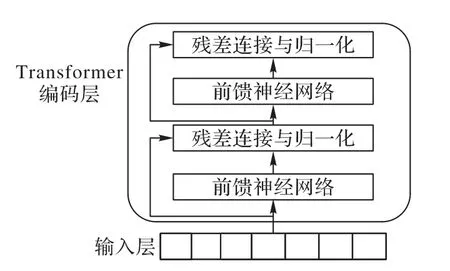
图2 Transformer编码层Fig.2 Transformer coding layer
1.2.3 掩盖语言模型
常见的语言模型如ELMo(Embeddings from Language Models)[21]是基于马尔可夫假设对单词组成的句子做概率乘积,选择概率最大的句子作为模型的输出。而BERT 模型是在两个无监督预测任务上对模型训练,分别是掩盖语言模型(Masked Language Model,MLM)和下一句预测(Next Sentence Prediction,NSP)。MLM 类似于英语中的完形填空任务,给出词的上下文来预测被遮挡的单词;NSP 是一个简单的二分类训练任务,用于判断前后两个句子是否连续。
掩盖语言模型用特殊标记随机替换掉句子中15%的单词,被替换的15%单词中有80%的几率用[MASK]代替,10%的几率用随机的单词替换,10%的几率保持不变。从理论上讲掩盖模型引入了噪声,模型对掩盖的单词重新编码再来预测被掩盖的单词,因此,掩盖语言模型本质上也是一种降噪的自编码语言模型[22]。但是这种自编码语言模型仅仅用于预训练阶段,而本文所使用的栈式降噪自编码器用于下游任务中特定的数据集以实现对不完全数据去噪。
2 SDAE-BERT模型
不完全数据是相对于完全数据而言的,也称不完整数据。不完整数据的句子中通常有单词的拼写、句子的语法等错误,从而导致句子的语义或语法出现结构混乱。表1 列举了第3.1 节所用数据集中的常见错误类型,其中括号内为正确表示。在大多数非正式场合,人们为了方便交流,往往忽视句子结构的完整性,导致机器无法和人一样识别某些重要信息,从而影响情感极性的判断。

表1 两种数据集常见错误类型Tab.1 Common error types of two datasets
2.1 栈式降噪BERT模型(SDAE-BERT)情感分类
在大语料库中训练的模型BERT,可以加入目标数据微调后进行情感分类。在此之前,还可以对原始数据的输入特征向量表示进行栈式降噪自编码训练得到目标数据的特征表示,接着再用预训练模型BERT 对目标数据进行情感分类。SDAE-BERT 的情感分类过程如图3 所示。其中原始数据表示不完全数据,目标数据表示经栈式降噪自编码器训练后的相对“干净”完整的数据。

图3 SDAE-BERT的情感分类流程Fig.3 Sentiment classification flowchart of SADE-BERT
与BERT 模型后串接降噪BERT 的不完全数据情感分类[23]不同的是,本文提出栈式降噪BERT(SDAE-BERT)模型,用栈式降噪自编码器直接对经词嵌入后的原始数据训练,再使用预训练模型BERT 进行情感分类。模型的结构如图4 所示,由4 层结构组成:输入层、栈式降噪自编码器(SDAE)层、BERT 层、分类层。在2.2 节将介绍SDAE-BERT 模型的4 个层次。
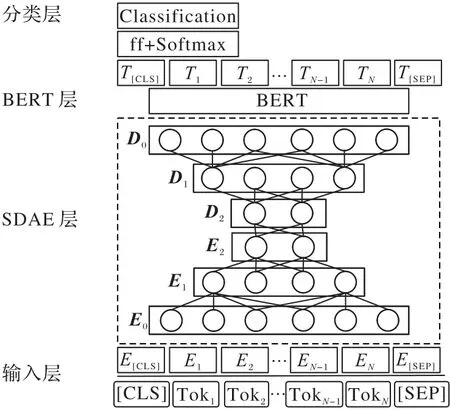
图4 SDAE-BERT模型结构Fig.4 SDAE-BERT model structure
2.2 SDAE-BERT模型结构
2.2.1 输入层
将原始的句子转化为大小为(Nbs,128,768)的词嵌入表示,其中:128 为句子的最大长度,768 为隐藏层单元个数,Nbs为批量处理数据的大小。
2.2.2 栈式降噪自编码器层
栈式降噪自编码器层由3 个分别含有两个隐藏层的降噪自编码器堆叠而成,编码和解码过程如式(1)、(2)。
编码过程:
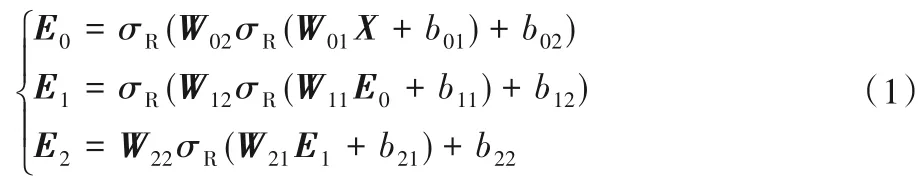
解码过程:
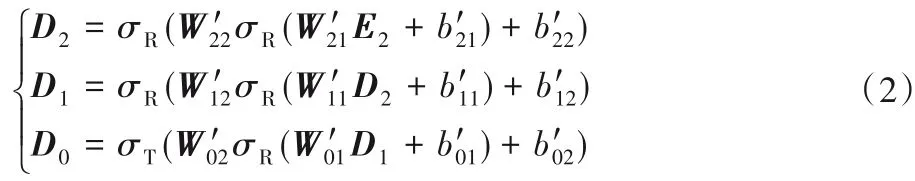
其中:X为不完全数据经过输入层后的向量表示;E0、E1、E2,D2、D1为编码,解码过程中的中间变量;W、b,W′、b′为编码,解码过程中的权重和偏置。例如,W01表示第一个编码器的第一个隐藏层的权重,b01为对应的偏置,为最后一个解码器的第一个隐藏层的权重为对应的偏置,依此类推;σR为修正线性单元(Rectified Linear Unit,ReLU)激活函数,σT为双曲正切(Tanh)激活函数。
把同样的数据(即不完全数据)经众包平台的纠正处理后也即将不完全数据转化为相对“干净”完整的数据,纠正后的数据经过输入层得到的X0作为栈式自编码器的训练目标,将SDAE 层的输出D0与完整数据X0用均方误差(Mean Squared Error,MSE)函数计算误差并对误差反向传递,使训练数据D0接近于干净完整的数据X0,误差计算如式(3),其中Nbs为批量大小,表示每隔一个批量计算一次误差大小,一个批量的误差为整个批量的平均误差。用Adam 优化器更新网络参数直至损失在预期范围内,保存此时的网络参数用于下一层的BERT模块。
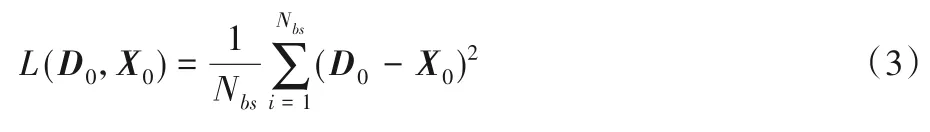
2.2.3 BERT层
将上一层栈式降噪自编码器的输出D0作为BERT 的输入,用预训练模型BERT 对输入的特征向量微调。微调过程中使用二分类交叉熵损失函数,计算公式如式(4)所示。BERT 模型由12 个Transformer 串接而成,取最后一层的第一个特殊标记[CLS]用于情感分类。

其中:y表示真实的标签值表示经过BERT 层后模型预测为正类的概率值。
2.2.4 分类层
把第一个特殊标记[CLS]经前馈神经网络变换后用softmax 函数将线性变换的结果O(i)转化为概率分布P(i),其中i∈1,2,分别表示正负类情感极性,计算公式如式(5),最后用arg max进行分类,取概率值大的对应标签Y作为分类的结果,计算公式如式(6):

3 实验结果及分析
为检验提出的模型与对比算法在情感分类中的性能,本文选取自然语言处理领域的两个主流数据集Sentiment140 和IMDB 进行实验。所提模型是在预训练模型BERT 上进一步改进,预训练的BERT 已经编码了大量语言信息,所以在少量样本上训练即可得到理想的效果。
3.1 数据集
表2 为实验的数据统计情况,Sentiment140 是斯坦福大学收集用户情感信息的数据集,IMDB是有明显情感倾向性的二分类影评数据集。从Sentiment140 和IMDB 中选取有明显结构不完整性的句子分别6 000 个和3 600 个,其中训练集占80%,测试集占20%,取训练集中10%作为验证集。同时复制一份同样的数据,借助众包平台纠正这些不完整的数据,以获得完整数据作为栈式降噪自编码器的训练目标,使得不完整数据经过堆栈自编码器训练后得到相对完整数据。
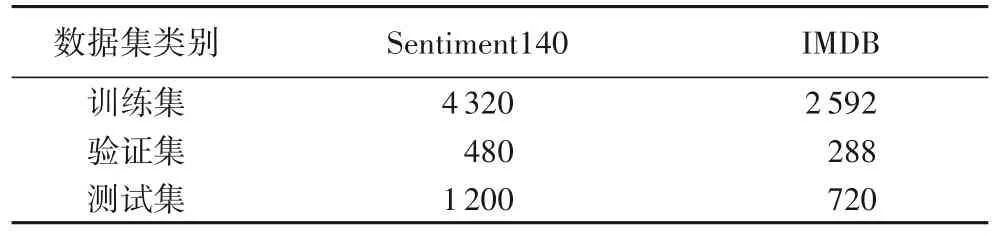
表2 实验数据统计Tab.2 Statistics of experimental data
针对不同数据含有的不同错误类型,表3 中为对应的样本数量统计,由表可知不完全数据中的错误类型主要是拼写、语法、缩写、发音、拟声,因此有必要对不完全数据进行去噪处理,来提高不完全数据的情感分类准确率。
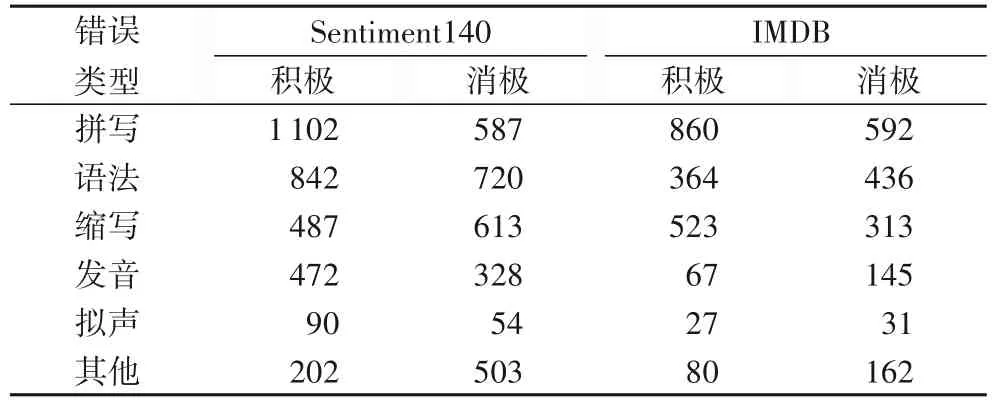
表3 不完全数据的错误类型统计Tab.3 Statistics of incomplete data error types
3.2 评价指标
本文分类器的主要评价指标有准确率(Accuracy)、精确率(Precision)、召回率(Recall),实验采用准确率和调和平均值F1(F1-Score)值作为分类器的评价指标,由于实验所选取的数据均为有明显不完全数据特征的句子,因此采用宏平均(Macro-average)即macroF1 值代替调和平均值,以防止因数据标签分布不平衡对实验结果的影响,准确率的计算公式如式(7),macroF1值的推导如式(8)~(11):
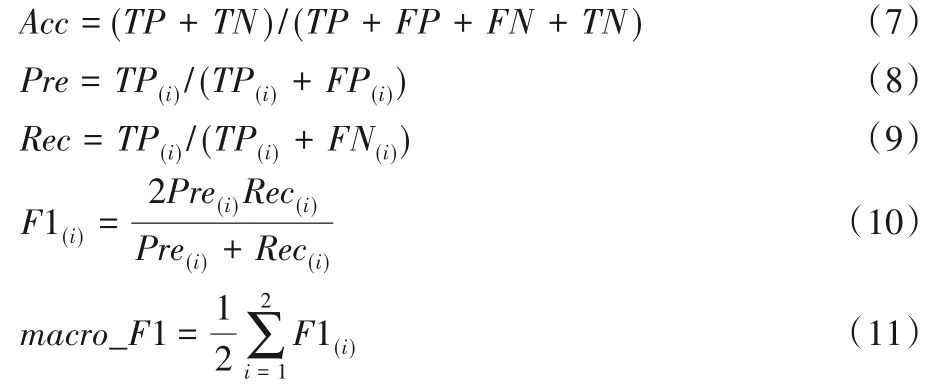
其中:Acc为准确率;Pre为精确率;Rec为召回率;macro_F1 为宏平均值;TP(True Positive)表示正类情感标签被模型预测为正类的样本数量;FP(False Positive)表示负类情感标签被模型预测为负类的样本数量;FN(False Negative)表示正类情感标签被模型预测为负类的样本数量;i表示第i个情感标签(i取1、2)。
3.3 超参数设置
栈式降噪自编码器层 输入句子的最大长度为128,输入的隐层节点数为768,在编码器中隐层节点数分别为384、128、32,在解码器的隐层节点个数分别为32,128,384,输出的隐层节点数为768,训练的epoch 值设为50,使用均方误差函数计算损失、Adam优化器更新网络参数,学习率为2E -3。
BERT 层 使用预训练好的BERT-base 模型,模型由12个Transformer 模块串接而成,12 个注意力头,768 个隐层节点数,输入句子的最大长度为128,模型的总参数大小为110 MB。在谷歌Colab 实验平台的GPU 上对栈式降噪自编码器的输出进行微调,训练epoch 值设为10,使用Adam 优化器更新网络参数,学习率为2E -5,批大小设为8。权重衰减系数设为0.001 以调节模型复杂度对损失函数的影响,为防止过拟合,dropout值设为0.1。
3.4 实验结果对比
为了避免由于实验过程中epoch 值的选定对实验结果的影响,对SDAE-BERT 模型在两个不完全数据集上进行实验,在模型的批大小、学习率、样本数量相同的情况下,改变epoch值,记录不同epoch 值下的分类准确率和F1 值。实验结果如图5 所示,X轴为epoch 值的大小,Y轴为分类的性能百分比(Percentage)。不同线段类型分别代表准确率和F1。实验结果表明,对于Sentiment140 在epoch 值为10 时,分类的准确率和F1 值达到最高分别为86.32%、85.55%,对于IMDB 在epoch 值为16 时,分类的分类的准确率和F1 值达到最高分别为84.86%、84.13%。随着迭代次数的增加,模型逐渐拟合并且趋于平稳。综合考虑分类性能和训练时间复杂度,选取epoch值为10进行实验。
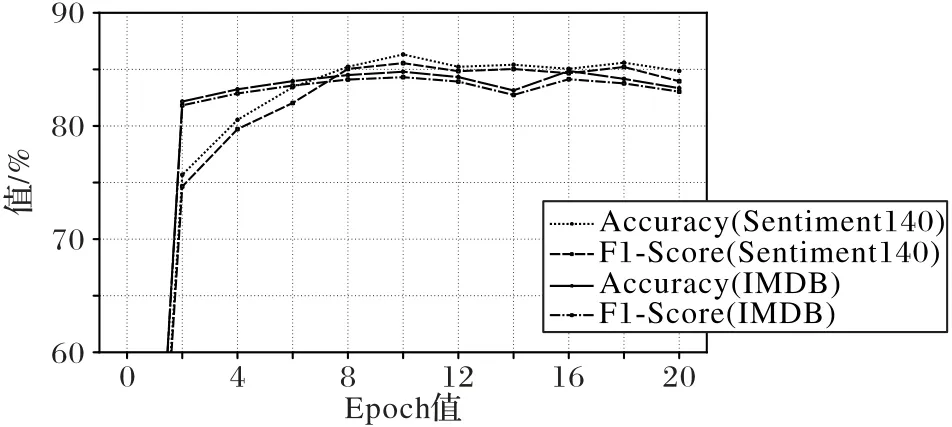
图5 不同epoch值的SDAE-BERT模型结果Fig.5 SDAE-BERT model results with different epoch values
表4 为不同模型在两个不完整数据集上的实验结果。其中,SVM 是使用径向基(Radial Basis Function,RBF)高斯核函数的支持向量机;LSTM是对文献[6]的复现,在一定程度上能解决RNN 的记忆衰退问题。BiLSTM-ATT 是引入注意力机制的双向LSTM 模型,其实验结果是来自对文献[8]的复现。BERT 是在两个数据集下微调的结果,SDAE-BERT 为本文提出的模型。
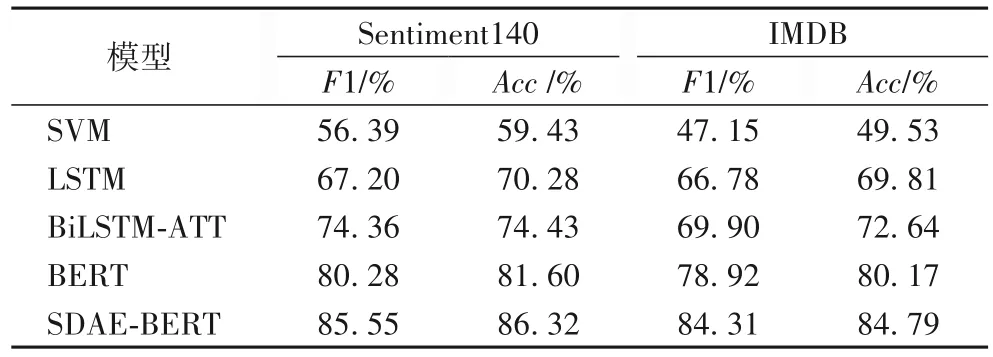
表4 不同算法在两个不完整数据集上的结果Tab.4 Results of different algorithms on two incomplete datasets
表5 为不同模型在两个完整数据集上的实验结果,用来与不完整数据的实验结果做对比,其所有参数设置与不完整数据集上的保持一致。
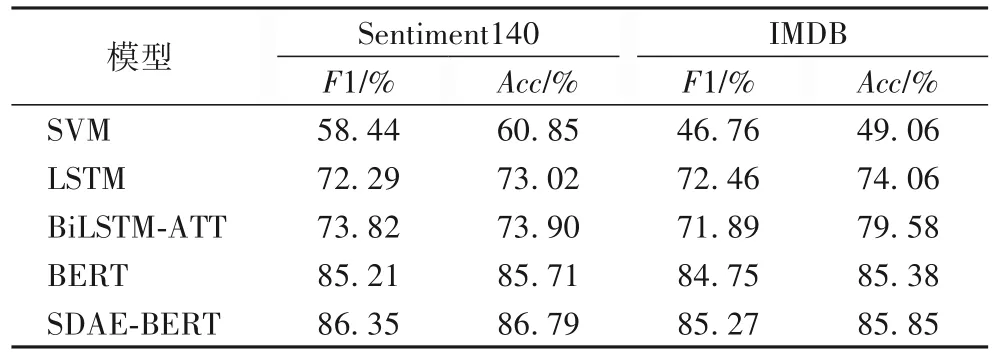
表5 不同算法在两个完整数据集上的结果Tab.5 Results of different algorithms on two complete datasets
实验结果表明,在训练数据较小的情况下。预训练模型BERT在不完整数据和完整数据上的F1值和分类准确率均高于支持向量机、LSTM 和有注意的LSTM 模型;对于不完整数据,LSTM 加入注意力机制比不加注意力机制的F1 值提高4%~10%,而对于完整数据则无明显效果,猜测注意力机制可能对不完整数据更有效,注意力机制能根据上下文语境预测当前最适合的单词;由表4 和表5 可知,在不完整数据集下的BERT 的分类效果比完整数据集下的BERT 低6%~7%,因此有必要对系统做进一步改进使其对不完整数据有同样的分类效果。本文提出的模型SDAE-BERT 在不完整数据上的F1 值和分类正确率均高于BERT 及其他模型,与BERT 模型相比在F1 值和正确率上分别提高约6%和5%(向上取整),从而验证SDAE-BERT 能有效地处理噪声问题。表5 完整数据集上的分类效果相比表4 的不完整数据都有一定提高,表明完整数据更有利于情感分类。表5中SDAE-BERT 与BERT 模型的实验结果无明显区别,表明提出的模型能够有效地对不完全数据进行情感分类。
基于上述实验,选择SDAE-BERT模型对比不同的训练数据规模对实验分类效果的影响,在保持模型结构和初始超参数不变的情况下,只改变数据集的规模。实验结果如表6所示。

表6 不同样本数量下的SDAE-BERT模型分类结果Tab.6 Classification results of SDAE-BERT model under different sample sizes
由表6 可得,训练数据的规模对SDAE-BERT 的分类效果有较大影响,因此在对SDAE-BERT 进行训练时,适当增加训练数据模型能够学习到更多的特征表示,从而能提高不完全数据的情感分类性能。
4 结语
针对BERT 未考虑不完整数据给情感分类性能带来的影响,本文提出栈式降噪BERT(SDAE-BERT)模型。首先分析了栈式降噪自编码器能够对含有噪声的数据去噪;其次对预训练模型BERT 的输入表示、Transformer 编码层和掩盖语言训练方式进行描述;最后,提出将栈式降噪自编码器与预训练模型BERT 结合来处理不完全数据的情感分类模型。在不完全数据上的实验结果有所提升,从而验证了SDAE-BERT模型的有效性。
本文的不足在于所采用的数据集并非公共的不完全数据集,在对比方面存在一定的局限性;同时实验的数据较少,对上下文信息的捕捉不充足。下一步工作准备在两个方面进行展开:1)融合多个不完全数据集使得训练的模型更具有普遍性;2)增大训练数据的规模使模型充分提取上下文的信息。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
北京航空航天大学学报(2022年8期)2022-08-31
传感器世界(2022年3期)2022-05-24
中国典型病例大全(2022年7期)2022-04-22
数字技术与应用(2021年1期)2021-03-24
小天使·一年级语数英综合(2017年11期)2017-12-05
初中生世界·七年级(2017年9期)2017-10-13
少儿科学周刊·儿童版(2017年3期)2017-06-29
科技与创新(2017年5期)2017-03-28
少儿科学周刊·少年版(2015年3期)2015-07-07
