
基于注视兴趣区域聚类和转移的群体扫视路径生成
2021-01-21 03:23刘楠博张文雷李旺鑫
计算机应用 2021年1期
刘楠博,肖 芬,张文雷,李旺鑫,翁 尊
(智能计算与信息处理教育部重点实验室(湘潭大学),湖南湘潭 411105)
0 引言
人类通过视觉这一重要感官捕获到日常生活中的海量信息。在人类视觉系统(Human Visual System,HVS)选择注意机制的引导下,人们将视觉注意集中于海量信息的感兴趣区域(Region Of Interest,ROI),摒弃了其中的大量冗余,使人脑实时、高效地完成视觉信息处理[1]。挖掘、研究人类视觉系统的选择注意机制,赋予机器类人的视觉信息处理能力,对于人工智能和机器视觉领域的发展具有重要意义[2]。
目前,人们利用眼动追踪技术记录的眼动数据研究视觉注意的分布和转移。原始的眼动数据是通过红外设备以一定频率采集的视线位置样本点,经后处理操作可以得到注视点数据和扫视路径数据。长期以来,多数工作利用计算建模的方法挖掘群体观察者的注视点数据研究人类的视觉注意机制,通过生成静态显著图直接、整体地反映人类对图像场景的视觉注意程度[3-6]。然而人类观察图像是一个动态的视觉注意转移过程,静态显著图无法反映群体观察者整体的视觉注意转移模式。相较于注视点数据,扫视路径数据额外记录了注视点的转移信息,可以反映视觉注意的动态变化,具有更高的研究价值。
在相同的观看条件下,群体观察者的扫视路径虽然复杂多变,但是个体扫视路径间具有相似但不等同的潜在特性[7]。例如,通过分析阅读场景下的群体观察者的扫视路径数据探索中文阅读中的词切分,研究人类的阅读认知行为[8];通过研究广告与网页等刺激样本下的群体扫视路径设计,可以设计并优化网页排版[9-14];自然场景下通过归结表征群体的扫视路径,不仅能为基于深度学习的扫视路径预测模型提供监督信息,而且有助于计算机优先定位、处理人类的感兴趣区域信息,提升智能图像处理模型的速度和精度[15-16]。挖掘群体观察者的扫视路径数据,归结一条包含共有注视信息和注视转移模式的群体扫视路径,不仅能够表征刺激样本和刺激内容对人类的吸引程度,更重要的是,可以建模人类的动态视觉注意,对于探究人类的认知行为、精准改善视觉效果、提升计算机视觉的智能性都具有重要理论意义。
1 相关工作
近年来,群体扫视路径研究相对较少,现有的生成方法主要基于三种思路。其一,将群体观察者的扫视路径映射为字符串序列,利用序列模式挖掘进行群体注视模式归结。2006年West 等[17]开发了eyePatterns 工具,该工具通过统计单个序列中所有子序列模式及出现频率,提取出现次数或涵盖人数最多的序列模式生成群体扫视路径;同年,Hembrooke 等[18]提出多序列对齐方法,通过迭代过程将某一序列与其他所有序列逐一进行对齐操作,提取共有、对齐的子序列和序列元素生成群体扫视路径;2010 年Goldberg 等[19]提出Dotplot 对齐算法,可用于提取两个序列的共有、最长序列模式,在此基础上Eraslan 等[9]提出eMine 方法,通过迭代过程提取所有序列的共有、最长序列模式;2012 年,Hejmady 等[20]提出序列模式挖掘算法(Sequential Pattern Mining Algorithm,SPAM),通过提取所有序列的频繁子序列生成群体扫视路径。此类方法可以挖掘有代表性的子序列和序列元素,但当个体注视行为差异较大,没有共同子序列或共同子序列过短时都会影响生成路径质量。其二,确定群体观察者的共同视觉元素,归结其转移模式。2010 年Tsang 等[21]开发了eSeeTrack 工具,按照时间轴生成群体观察者视觉元素间转移概率的可视化树,并分析群体的注视转移模式;2014 年Chuk 等[22]及2015 年Kang 等[23]构建视觉元素间的马尔可夫转移概率矩阵,研究群体的注视转移模式。采用这些策略依据视觉元素间的转移概率生成群体路径时,常常存在重复、循环某一转移模式的现象,为防止生成路径过长需要预设长度阈值。2016 年Eraslan 等[11]提出扫视路径趋势分析(Scanpath Trend Analysis,STA)方法,该方法对网页进行分割,将所有观察者观看的区域视作共同视觉元素,定义优先度排序共同视觉元素,最终生成群体扫视路径。其三,将群体观察者的扫视路径表征为多个多维向量,寻找或生成表征群体的扫视路径向量。2017 年Li 等[15]提出基于候选约束的动态时间规整质心平均方法(Candidate-constrained Dynamic time warping Barycenter Averaging method,CDBA),通过动态时间规整策略找出与其他个体扫视路径动态时间规整距离最小的一条个体扫视路径,使用亲和力传播聚类算法生成的聚类区域调整该个体路径中的注视点,最终生成群体扫视路径。2018 年Li 等[16]提出Heuristic 方法,该方法在CDBA框架的基础上加入注视时间分析模块,生成包含注视时间的群体扫视路径。此方法中动态时间规整策略找出的个体扫视路径往往较短,直接受该个体路径影响,生成的群体扫视路径包含的注视兴趣区域数目较少、路径长度较短。
值得注意的是,目前扫视路径的研究主要针对的是网页场景[9-14,17-18,20,22-23]、自然场景的扫视路径研究较少[15-16]。究其原因,本文认为网页排版较为固定,注视区域基本呈现F 型,所以扫视路径相对有规律,生成较简单;而自然图像中由于场景的多样性、目标的复杂性,导致注视区域复杂多变,因此群体扫视路径研究相对困难,生成方法十分欠缺。本文借鉴自然场景中聚类注视点生成注视区域的思想以及网页场景中注视区域的转移策略,考虑不同类型的注视行为,提出了一种针对自然场景的群体路径生成方法。图1 展示了所提生成方法的模型框架。

图1 群体扫视路径生成模型的框架Fig.1 Framework of group scanpath generation model
2 基于注视兴趣区域转移的群体扫视路径生成方法
2.1 注视兴趣区域提取
众所周知,人类在观察、获取图像信息时,图像对人类的视觉吸引源于场景中的某个区域而非某个具体像素。即使观察者们注视了场景中的同一区域,由于高度的观察自由度,注视点着落的像素位置不尽相同。本文通过亲和力传播(Affinity Propagation,AP)聚类算法[24]对位置相关的观察者注视点进行聚类,确定注视兴趣区域。
AP 算法适用于高维、多类型数据的快速聚类。该算法无需事先设定生成聚类的数目,将所有数据点都视作潜在意义上的聚类中心,通过数据点间的通信,找出最适合作聚类中心的数据点。算法输入节点间相似度矩阵S,s(i,j)表示节点i和j之间的相似度;定义节点间的吸引度矩阵R和归属度矩阵A,并通过如式(1)~(3)更新矩阵(R0,A0均为零矩阵),直至聚类结果稳定或算法执行超过设定的迭代次数(1 000次),结束算法,输出聚类结果。

其中:rt+1(i,j)表示t+1时刻节点j作i聚类中心的适合程度,at+1(i,j)表示t+1时刻节点i对j作其聚类中心的认可程度。
对自然场景图像,本文将所有p名观察者注视点位置的负欧氏距离作为相似度矩阵S,执行AP 算法生成n个聚类注视点的集合Θ1,Θ2,…,Θk,…,Θn,将每个集合作为一个注视兴趣区域,其边界由集合中注视点的位置确定。
2.2 注视兴趣区域筛选
每个注视兴趣区域包含了不同的图像内容,对群体观察者具有不同的视觉吸引程度。为获取能够吸引群体视觉注意的兴趣区域,本节提出如下迭代筛选策略。
给定一组兴趣区域Θ1,Θ2,…,Θk,…,Θm,分别统计每个兴趣区域Θk的观察者数目ok、观看频次fk和观看时长tk,对各区域指标进行归一化后形成3个m元向量:O、F和T。定义兴趣区域注视强度Φ=(φ1,φ2,…,φk,…,φm)以及注视强度差E=(ε1,ε2,…,εk,…,εm),其中:

εmin_index表示向量E中的最小分量。通过迭代过程不断删去min_index 对应的注视强度最低的兴趣区域,更新O、F、T、Φ和E,直至min(E) <mean(E) -std(E)或者size(E) ≥m/2终止迭代。对聚类的n个兴趣区域执行以上过程,最终筛得n′个具有较高注视强度的兴趣区域。
2.3 注视兴趣区域转移
实验发现,注视兴趣区域的内容、空间位置及关联程度均会影响群体观察者的注视顺序。为生成群体路径,本文考虑每个兴趣区域中注视点在个体扫视路径中的注视顺序,在此基础上统计兴趣区域的注视优先度以及转移模式。
假设兴趣区域Θk有来自不同观察者的l个注视点,Θk={θk,1,θk,2,…,θk,l},定义其注视优先度为ζk:
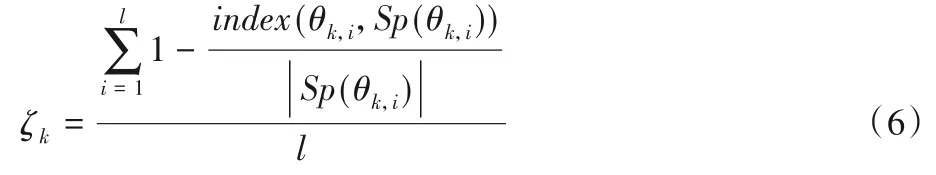
其中:Sp(θk,i) 表示获取θk,i所在的个体扫视路径,index(θk,i,Sp(θk,i))表示θk,i在Sp(θk,i)中的顺序索引,|Sp(θk,i)|是个体扫视路径长度。
考虑到生成路径的表征性能,本文仅统计筛选后的兴趣区域的注视优先度和转移模式,通过式(6)得到注视优先度向量Z=(ζ1,ζ2,…,ζk,…,ζn′)。分量ζk值越高,其对应的兴趣区域被优先注视的可能性越大,降序排列Z的分量得到兴趣区域转移模式。
2.4 群体扫视路径生成方法SCA
本节提出基于注视兴趣区域提取、筛选和转移的群体扫视路径生成方法(Sorting Clusters Approach,SCA)。算法1 展示了SCA方法的具体流程。
算法1 群体扫视路径生成方法SCA。
输入 所有观察者的扫视路径矩阵AllScanpathMat。
输出 群体扫视路径GroupScanpath。

3 基于注视行为的群体扫视路径生成方法
在SCA 的基础上,本章通过定义4 种注视行为对兴趣区域作进一步细分,结合兴趣子区域的转移模式,研究基于注视行为的群体扫视路径生成方法。
3.1 注视兴趣子区域提取
实际观看过程中,内涵丰富、相互关联的兴趣区域往往会吸引观察者产生多次、反复的注视行为。如图2 所示,图像中存在3 个兴趣区域Θ1、Θ2和Θ3,scanpath_1 是一条个体扫视路径。观察可知,Θ1区域可能包含丰富的图像内容,引起scanpath_1 观察者产生θ1,1,θ1,2,θ1,3,θ1,4,θ1,5共5 个注视点。这些注视点在位置、时间、顺序上存在一定差别,为了获取群体观察者不同时刻、不同顺序关注的不同局部信息,本文定义了兴趣区域Θk的首视注视点、首视连续注视点、回视注视点和回视连续注视点,将Θk划分为4 个独立的注视点集Ffixk、FSfixk、Bfixk和BSfixk。
定义1首视注视点:x∈Θk并且x是对应个体扫视路径Sp(x) 中第一个落于兴趣区域Θk的注视点,如图2 中θ1,1∈Ffix1。
定义2首视连续注视点:x∈Θk,其个体扫视路径Sp(x)中x的前序注视点是兴趣区域Θk的首视注视点或x的多个前序注视点同属于兴趣区域Θk且包含首视注视点,如图2 中{θ1,2,θ1,3}⊂FSfix1。
定义3回视注视点:x∈Θk,其个体扫视路径Sp(x)中前序注视点不属于兴趣区域Θk,但x非首视注视点,如图2 中θ1,4∈Bfix1。
定义4回视连续注视点:x∈Θk,其个体扫视路径Sp(x)中x的前序注视点是兴趣区域Θk的回视注视点或x的多个前序注视点同属于兴趣区域Θk且包含回视注视点,如图2 中θ1,5∈BSfix1。

图2 注视兴趣区域与个体扫视路径示意图Fig.2 Schematic diagram of fixation region of interest and individual scanpath
将Ffixk、FSfixk、Bfixk和BSfixk作为兴趣区域Θk的兴趣子区域,分别表示群体观察者首次、首次连续、回视、回视连续注视关注的兴趣区域局部,其边界由各点集中注视点的位置确定。若Θk中某注视行为的注视点集为空集,则该兴趣区域不存在相应兴趣子区域。
3.2 注视兴趣子区域筛选和转移
实验发现,观看不同图像时,观察者产生各类注视行为的次数有所差别。为保证生成路径符合实际、表征群体,本节统计观各图像中所有观察者产生各类注视行为的平均次数,提出如下筛选策略。
对迭代筛选后的兴趣区域,本文考虑所有这些区域的首视兴趣子区域,筛选阈值记为len1,len1=n′。首视连续兴趣子区域的筛选阈值记为len2:

其中:size(FSfixi)表示FSfixi区域首视连续注视点的数目,p为观察者数目。在FSfix1,FSfix2,…,FSfixn′中筛选出观察者数目最多的len2 个子区域。回视、回视连续兴趣子区域的筛选过程与首视连续兴趣子区域一致。通过式(7)得到len3 和len4,最终筛得(len1+len2 +len3+len4)个兴趣子区域。
通过式(6)计算首次、回视兴趣子区域的注视优先度向量Z′=(ζ1′,ζ2′,…,ζlen1+len2′),降序排序Z′中的分量生成首视、回视兴趣子区域的转移模式。将筛得的(len3+len4)个连续注视兴趣子区域插入相应的首视、回视兴趣子区域之后,得出最终的兴趣子区域转移模式。
3.3 群体扫视路径生成方法DFS
本节提出基于划分、筛选、转移兴趣区域的群体扫视路径生成方法(Devide,Filter,Sort Clusters Approach;DFS)。算法2展示了DFS方法的具体流程。
算法2 群体扫视路径生成方法DFS。
输入AllScanpathMat,迭代筛选的兴趣区域结构体NewThetaStruct。
输出GroupScanpath。
第一阶段 兴趣子区域划分、筛选。

第二阶段 兴趣子区域转移。

第三阶段 生成群体路径
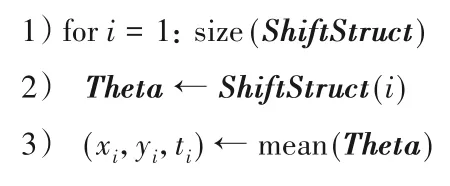

4 实验与结果
为验证所提方法的有效性,本文在MIT1003[25]和OSIE[26]两个公共数据集进行相关实验,并与现有方法进行对比。
4.1 实验数据集
MIT1003 数据集包含1 003 幅多个类别、尺寸不一的自然场景图像,对每张刺激样本采集15 名观察者3 s 观察时长的眼动数据。OSIE 数据集包含700 幅多个类别、尺寸相同的自然场景图像,图像尺寸统一为800×600 像素,每张刺激样本收集15名观察者3 s观察时长的眼动数据。
本文统计了两个数据集中每张刺激样本的平均注视点数和平均兴趣区域数,如表1 所示。通过对比两数据集的刺激样本和眼动数据,本文发现OSIE 中多数图像拥有较为明显的物体,观察者产生的注视点相对较多,注视区域分布较为集中;而MIT1003 中图像较为复杂,观察者产生的注视行为较少,注视点分布较为分散,因此MIT1003数据集的群体扫视路径生成更为困难。

表1 数据集对比Tab.1 Dataset comparison
4.2 定性分析
本节将提取的兴趣区域、筛选的兴趣区域、SCA 和DFS方法生成的群体扫视路径进行可视化处理,依据可视化结果作出定性分析。
图3展示了聚类注视兴趣区域的可视化结果。

图3 注视兴趣区域可视化Fig.3 Visualization of fixation regions of interest
图3(a)是未经筛选的兴趣区域,图3(b)是筛选后的兴趣区域,图像样本1、2 取自MIT1003 数据集,图像样本3、4 取自OSIE数据集。通过对比可以发现,对图像样本1~4,经筛选步骤,图3(a)中注视点数目较少、注视强度相对较低的兴趣区域能够被适当剔除,注视点数目较多、注视强度相对较高的兴趣区域可以被有效保留。
图4展示了群体扫视路径可视化结果,图像样本1、2取自MIT1003 数据集,图像样本3、4 取自OSIE 数据集。通过对比可以发现,对图像样本1~4,所提两种方法的群体扫视路径(b)、(c)能够涵盖群体观察者真实扫视路径(a)中的注视兴趣区域,可以表征群体的注视转移趋势。另外,DFS方法的群体扫视路径(c)包含了高注视强度兴趣区域的连续注视和回视,更加贴合真实的扫视路径。

图4 群体扫视路径可视化Fig.4 Visualization of group scanpaths
4.3 定量评价
目前常用的定量评价策略是将生成的群体扫视路径与每一条真实记录的个体扫视路径作相似度比较,以相似度的均值定量衡量其表征能力。
4.3.1 评价指标
比较眼动数据相似度的方法[27-29]有很多,它们不尽相同,各有侧重。本文采用了两种较常应用的针对扫视路径的评价指标MultiMatch[28]和ScanMatch[29],从时间和空间角度比较群体扫视路径与个体扫视路径的相似度。
MultiMatch 指标将扫视路径视作注视点排列形成的扫视向量,利用Dijkstra 算法[30]生成两扫视向量的对齐矩阵,从扫视向量形状、长度、方向和注视点位置、时间5 个维度量化计算对齐部分子向量的相似度,求取对齐子向量相似度的均值衡量两扫视路径的相似度。通过计算群体路径与每条个体路径五项相似度指标的均值,衡量群体路径与所有个体路径的相似性,指标越高,表明群体路径的表征效果越好。实验中MultiMatch 中的参数设置为:global Threshold=Diagonal/10,direction Threshold=45,duration Threshold=inf。
ScanMatch 指标对图像作隔栅划分将扫视路径映射为字符串序列,利用Needleman-Wunsch 算法[31]计算两扫视字符串序列的最佳对齐分数,对齐分数越高,两扫视路径的整体相似性越高。通过计算群体路径与每条个体路径的对齐分数均值,衡量群体路径与所有个体路径的相似性,指标越高,表明群体路径的表征效果越好。另外,通过设置TempBin参数该指标可以考虑时间因素对两路径对齐的影响,假设格栅Grid1中存在一个300 ms 的注视点,TempBin=0 时,映射出的字符串序列为(Grid1),TempBin=100 时,映射出的字符串序列为(Grid1,Grid1,Grid1)。实验中ScanMatch 的参数设置为:Xbin=24,Ybin=18,Threshold=3.5,GapValue=0,TempBin=100(不考虑时间因素时TempBin=0)。
4.3.2 对比实验及分析
文献[16]中,Li 等将所提的自然场景群体扫视路径生成方法CDBA[15]、Heuristic[16]应用于MIT1003 和OSIE 两个公共的自然场景数据集,利用MultiMatch 和ScanMatch 指标,与网页场景的生成方法eMine[9]、STA[11]、SPAM[20]进行比较,取得了全面超越的效果[16]。为了衡量所提生成方法SCA和DFS有效性以及与现有方法的差距,本文使用相同的数据集、评价指标分别进行了生成实验、定量评价,并与文献[16]中现有方法的评价结果进行比较。由于MultiMatch 指标中参数durationThreshold=inf,对比过程对子路径进行了简化,导致SCA 方法在MIT1003 数据集中1 张图像和OSIE 数据集中11幅图像上简化后的路径过短,无法与真实路径对比,因此,SCA 的MultiMatch 评价结果中未计入这12 幅图像。表2 展示了不同生成方法的指标结果。
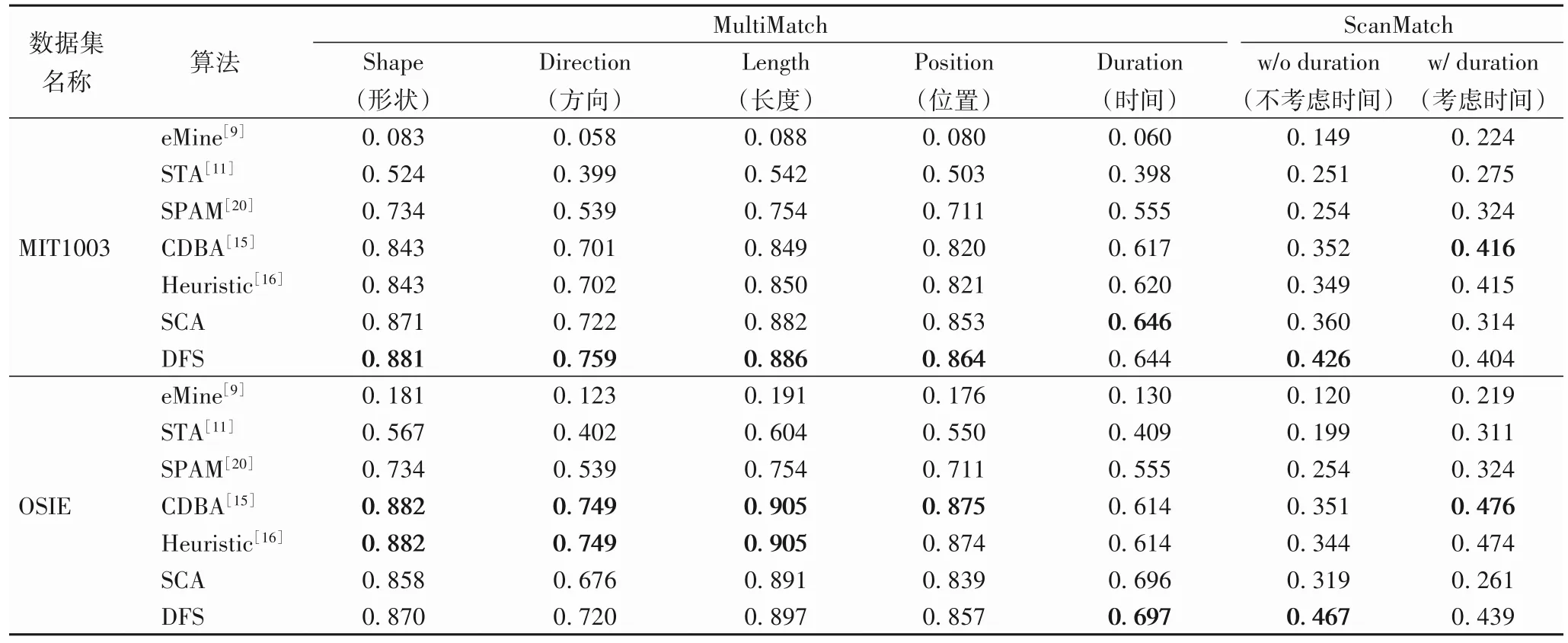
表2 利用MultiMatch↑和ScanMatch↑评估群体路径算法Tab.2 Evaluation of group scanpath algorithms by MultiMatch ↑and ScanMatch ↑
首先,对比SCA和DFS方法可以发现,通过注视优先度排序注视兴趣区域的SCA能够生成一条与真实路径具有一定相似度的群体扫视路径。对SCA进行改进的独立处理不同注视兴趣子区域的DFS 方法,在MultiMatch 的扫视路径形状、方向、长度和注视点位置指标上,以及ScanMatch 的两项指标上都取得了一定的提升,实验数据验证了考虑注视兴趣区域的不同注视行为,生成的群体扫视路径会更加贴合真实扫视路径。
其次,将SCA、DFS 方法与网页场景方法eMine[9]、STA[11]、SPAM[20]对比可以发现,网页场景的生成方法不适用于自然场景的复杂情况,需要研究针对自然场景情形的方法。
最后,将SCA、DFS 方法与自然场景方法CDBA[15]、Heuristic[16]对比。由相关工作及评价指标的介绍可知,CDBA[15]、Heuristic[16]是基于筛选最佳对齐向量的生成方法,MultiMatch 是仅衡量对齐部分子向量平均相似度的指标,理论上这两种方法的MultiMatch 指标应该最优。通过观察可以发现,SCA 和DFS 方法在兴趣区域众多、图像较复杂的MIT1003 数据集上表现优于其他方法,初步判断原因在于本文聚类获取的注视兴趣区域结果较好,本文生成路径考虑的兴趣区域更全面、转移模式更详细,生成路径与真实个体路径达到了较好的对齐效果,得到了较高的对齐子路径平均相似度。ScanMatch 指标上,不考虑时间因素时,DFS 方法的生成路径可以取得与真实路径较高的对齐分数,说明生成路径的注视区域和注视顺序与真实路径相似;考虑时间因素时,对齐分数有所降低,是因为DFS 方法将筛得所有兴趣子区域的时长直接叠加,生成路径总时长超过了真实观察时长,导致生成路径未能与真实路径较好对齐,影响了最终的评价结果。DFS生成方法的时间策略有欠合理,有待继续改进。
5 结语
本文研究自然场景中人类的注视注意,通过分析同一刺激样本下多名观察者的眼动数据,提出了基于注视兴趣区域聚类和转移的群体扫视路径生成方法。可视化及指标结果表明所提方法的生成路径能够贴合群体观察者的实际的眼动行为且具有一定的表征能力。今后的工作中,会继续改进生成方法使之更好地适用于不同的数据集,提升模型的鲁棒性;继续研究合理的时间生成策略使之更好地贴近真实视觉注视和转移,提升模型的精确性;研究针对扫视路径的评价指标,探索新的评价方法。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
南京理工大学学报(2022年1期)2022-03-17
计算机应用与软件(2021年7期)2021-07-16
当代陕西(2020年20期)2020-11-27
中学课程辅导·教育科研(2020年22期)2020-08-14
华人时刊(2019年19期)2020-01-06
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
中外文摘(2019年8期)2019-04-30
当代陕西(2019年6期)2019-04-17
群众(2018年18期)2018-10-26
