
儿童运动协调障碍AI诊断系统研究综述
2021-01-22 05:59陈艳杰舒大伟杨吉江
计算机工程与应用 2021年2期
陈艳杰,舒大伟,杨吉江,王 欢,王 青,雷 毅
1.首都医科大学 附属北京儿童医院 儿童保健中心,北京100045
2.清华大学 深圳国际研究生院 信息科学与技术学部,广东 深圳518055
3.清华大学 信息技术研究院,北京100084
4.国家体育总局体育科学研究所,北京100061
儿童的运动协调能力是儿童发育过程中的核心能力之一,该能力正常的发展对儿童的语言、智力、情感等方面的发展也具有促进作用[1],患有运动协调能力障碍(Developmental Coordination Disorder,DCD)的儿童通常语言、认知等方面的能力也会受到影响,在儿童阶段及成人远期都可能会影响其生活自理能力及社会性相关功能,所以运动协调能力的评估成为儿童早期发育水平的重要指标[2]。
根据美国精神联合学会(American Psychiatric Association,APA)的调查显示,5~11 岁儿童的发病率为5%~6%[3],我国2011 年上海地区的一项调查显示7~12 岁儿童的发病率为8.3%[4]。其较高的发病率不容忽视,但其病因复杂,目前发病机制仍不明确[5],而多项研究表明,早发现早干预是目前行之有效的治疗手段。
目前的儿童运动协调障碍的主要诊断手段是通过各种专业量表法[6],如儿童运动协调能力评估量表第二版(Movement Assessment Battery for Children-Second Edition,MABC-2)、发育性协调障碍量表(Developmental Coordination Disorder Questionnaire,DCDQ)等,评分依据有客观标准,如动作的频次,也有主观标准,如动作标准程度判断,这就要求做诊断的医生需要有一定经验及专业性,才能有效评估得出正确诊断结果。我国儿科医师缺乏情况一直比较突出,且由于地域发展的不平衡,基层的儿科医师更为缺乏,所以需要一套简单易行且诊断准确度在一定水平之上的解决方案。
计算机动作识别系统可对人体动作进行识别,目前主要应用于电影演员动作捕捉、运动员动作评估等方面,通过观察者在身体各部位携带一定数目的标记进行动作数据的采集,计算机进行后台数据处理及动作分析,其对设备和场地都有较高的要求,有着成本高、操作复杂、泛用性差的缺陷,这就意味着难以大范围地推广使用。
随着人工智能的发展,仅基于移动端所拍摄的视频数据进行动作识别辅助诊断系统有了实现的可能,患者根据提示完成一系列的动作,系统根据所得视频数据即可对疾病做出诊断,这种形式的诊断方式有着易推广、易实施的特点,具备良好的应用前景。利用移动端设备进行视频采集,服务端对视频数据进行诊断,该方式可有效向基层进行推广,在此基础上可获得大量的数据并进一步提升诊疗识别能力,对缓解医疗资源不足问题有着重要意义。
1 相关领域研究现状
当前,儿童运动协调障碍人工智能诊断系统领域的研究较少,动作识别多用于体育视频分析,Joshi 等[7]基于深度学习方法提出一种视频分析方法,对体育视频中的高光时刻进行分析捕捉并截取精华片段,但其只是对视频内容作是否精华部分的判断,并不涉及对运动员实例级别的动作评估。Wang 等[8]提出一种分析自由滑雪运动项目的动作评估方法,第一步对视频数据输入进行目标跟踪任务,第二步对抽取出的跟踪目标进行单人姿态估计,第三步对得到的姿态估计数据进行动作评估,即对动作好坏做二分类任务。Tian等[9]基于花式滑冰动作分析任务,提出利用多个不同视角的摄像头捕捉动作,然后进行位置矫正补偿从二维影像数据获得三维立体数据的方法,给从二维数据获取更为准确的三维数据任务提供了新思路。
先做人体姿态估计再去做动作识别任务是一个普遍采用的思路,Chen 等[10]基于Openpose[11]框架,提出使用人体姿态估计的输出来做摔倒检测任务,摔倒检测可以认为是动作识别中的子任务,其使用skeleton-base的人体姿态估计数据根据手工设计的特征标准进行摔倒动作的识别,王新文等[12]使用双重残差网络做摔倒检测任务。唐心宇等[13]指出直接使用Kinect 作为姿态估计的数据输入对动作识别的准确度有较大影响,因其对遮挡情况的判断精度较差,结合深度学习的方法进行姿态估计能大大改善遮挡识别不准确的问题。腾讯医疗AI实验室提出帕金森疾病诊断系统,该系统提示患者作出相应动作并对其进行诊断,通过深度学习方法识别人体的关键点构建人体动作模型,依据成熟的帕金森疾病打分量表进行诊断,其也针对训练数据不足的情况结合自动融合技术做了数据增强。
2 运动协调障碍的辅助诊断步骤
基于深度学习方法做运动障碍诊断目前有两种思路,关键区别在于是否进行人体姿态估计的中间处理生成skeleton数据,因而产生了两种不同的处理步骤,需要注意的是由于后续动作识别任务的输入数据类型不同,所以动作识别任务中采用的模型将有较大差别。
步骤类型1见图1:
(1)使用移动设备根据提示进行幼儿动作指导并视频采集,为保证最终检测效果,对输入数据的一致性要有一定要求,如光照环境、拍摄角度等方面,对拍摄后的视频进行必要的预处理操作。
(2)由于得到的视频数据是已经剪裁好的对应动作视频,对其分别进行人体姿态估计任务,生成人体姿态估计的skeleton数据,为了保证对儿童识别的准确度,人体姿态估计任务的模型要在对应的儿童数据集上做finetune。
(3)将skeleton数据输入Skeleton-based类型的动作识别模型,输出动作准确度的评估结果,对相应动作根据打分量表进行诊断打分,汇总打分结果输出诊断结果。
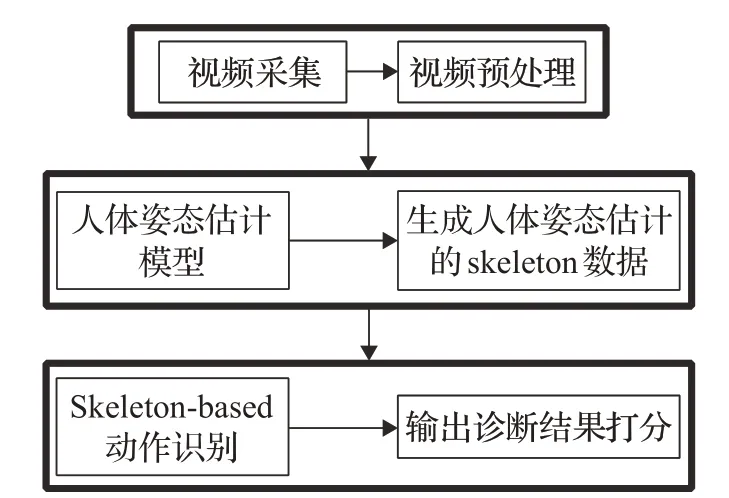
图1 辅助诊断流程图类型1
步骤类型2见图2:
此类型无需进行人体姿态估计的中间任务,直接将视频数据输入Video-based类型的动作识别模型进行动作识别,然后进行诊断打分操作,这种类型对动作数据集的要求较高,需要大量的带标注的动作视频数据进行训练。
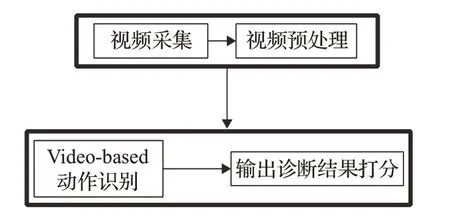
图2 辅助诊断流程图类型2
3 人体姿态估计
人体姿态估计是计算机视觉的基础任务之一,在目前权威的公开比赛COCO keypoint track[14]中,COCO数据集把人体表示为17 个关键点,分别是鼻子、左右眼、左右耳、左右肩、左右肘、左右腕、左右臀、左右膝、左右脚踝,该任务需要对人体的关键点进行位置估计,这个任务通常还可细分:根据检测画面中的人数分为单人姿态估计和多人姿态估计,根据关键点信息是否包含三维深度信息分为2D姿态估计和3D姿态估计,此外还有对关键点进行跟踪的人体姿态跟踪任务。
在应用上,人体姿态估计可用于电影动画、虚拟现实、人机交互、视频监控、医疗辅助诊断、运动分析、自动驾驶等方面,同时人体姿态估计面临着诸多挑战[15]:
(1)人体是柔性的,这就意味着人体是一个具有高度自由度的物体,对这样物体的估计难度较高[16]。
(2)对于背景复杂或光照条件弱的待处理图片,人体与背景的外观相似性可能较高,且身体的各个部分是被不同的纹理(衣服)所覆盖的,有时不同部位的纹理是接近的。
(3)环境的复杂性会造成较大的影响,比如出现遮挡,尤其是对于不同人人体相似部位的遮挡。
3.1 传统方法
相对于目前主流的深度学习方法,早期的传统方法已经很少被使用了,其主要原因很大程度上是因为深度学习领域的发展,在各类人体姿态估计的数据集上,深度学习的方法已经全面超过了传统方法的效果,但传统方法提供的基本思路依然值得学习借鉴。
传统方法主要针对的是单人的姿态估计任务,粗略可分为两类,一类方法是直接使用全局的feature,将问题转化为分类或者回归问题来进行解决,如文献[17]中采用的是HOG 直接抽取浅层的全局特征,然后利用Random Forest的方法转化为分类问题来解决姿态估计问题,第二类方法是基于图模型,如pictorial structure framework,对图像的单个part进行特征表示,Andriluka等[18]基于pictorial structure framework 对特征表示优化,来提取更好的特征表示,传统的方法基本上还是利用的比较浅层的特征,如HOG、SIFT 等,然后对空间位置关系进行建模,而深度学习方法将二者合为一体,这样的优势是便于设计和优化。
3.2 深度学习方法
深度学习的方法自2012年AlexNet[19]提出以来就引发了研究热潮,在人体姿态估计领域也引入了深度学习模型,在2013 年就有文章提出使用CNN 来解决人体姿态估计问题[20],但当时的网络设计还比较简单,而且利用CNN只是替代了原有姿态估计方法中的特征表示部分,但在性能上却已经和传统方法一致,甚至超过,表1总结了目前主流的人体姿态估计模型。
3.2.1 单人姿态估计
在早期主要发展的是用于2D 单人姿态估计的方法,其中最具有代表性的是2016年发表的Hourglass[21]、CPM[22]两个工作。CPM 里已经把空间位置关系和特征表示建模在一个模型之中了,不像之前仅把CNN 作为特征表示的方式,输出的每个channel 实际上就代表一个关键点,采用多stage的方式,每个stage可以看作是在前stage 的基础上做refine,在输出关键点坐标的方式上,不是采用直接回归坐标的方式,而是采用先预测出heatmap,然后再取argmax等操作获得最终坐标值,heatmap相对而言能保留更多context 信息,是一种中间态的信息,在此之后的人体姿态估计问题,基本上都是采用heatmap 的方式来获得关键点坐标。Hourglass 网络的突出特点是结构简单明了,通过融合feature map 的前后特征来获取具有更强表示能力的特征,这种U型结构也广泛用于其他任务,如图像分割、检测等。整体的pipeline和CPM是相似的,这本质上是back-bone层面的改进提升。除了以CPM 为代表的思路之外,还有一些思路是基于GAN 的方式[26]进行单人姿态估计任务,在MPII上取得了很好的效果。

表1 人体姿态估计深度学习模型
3.2.2 多人姿态估计
随着COCO数据集中多人姿态估计任务的提出,用于2D 多人姿态估计的方法逐渐增加,其中较有影响力的代表是Openpose[11],这是多人姿态估计中基于bottomup 的思路,而基于top-down 的思路,后续提出的有CPN[24]、MSPN[25]。
在多人姿态估计中bottom-up思路是先检测出所有关键点,然后对这些关键点进行分组,确定关键点所属的对象,openpose基于CPM组件,首先找出图中的所有关键点,然后使用PAF(Part Affinity Fields)方法将这些检测出来的关键点分组确定所属对象。除了利用PAF来确定关键点所属对象之外,还有一种利用Associative Embedding 的思路[27],就是对每个输出的关键点都输出对应的embedding,使同一个人的embedding 结果接近,不同人embedding结果差距变大。
多人姿态估计的第二种思路是top-down思路,即先进行检测任务将图中的人都找出来,然后进行单个人的姿态估计,此思路下的模型精度更好,由于人体目标比关键点更大,检测到人比检测关键点更容易,这就意味着recall 会更高,其次不需要对类似的关键点进行所属对象分组,而这个问题在bottom-up 思路中会比较困难。CPN[24]设计两个stage,第一步的GlobalNet 输出一个coarse的结果,第二步进行进一步的refine,此外和之前研究的不同是采用了更主流的backbone,即ResNet50,更强的backbone对特征具有更好的表征能力。MSPN[25]同样是基于top-down 的思路,是在CPN 的基础上做的改进,相比于CPN的两个stage设计,这篇工作采用了多个stage 的设计,相当于有多步的refine,这样取得的结果也会更好。
3.3 数据集及评估标准
在深度学习方法中,数据集是尤为重要的,好的数据集不仅可以作为评估不同方法效果的标准,还可以随着数据集的扩张变化来提升深度学习网络的性能,下面将对主要数据集及评估标准进行介绍。
3.3.1 2D人体姿态估计主要数据集
在深度学习兴起之前就已经存在许多2D人体姿态估计的数据集,这些数据集具有一些缺点,如场景过少、单一视角、图片数量过少等,这些缺陷导致其无法在深度学习任务中达到更好的效果,尤其是数据量过少,这就会导致深度学习网络的鲁棒性减弱,也会导致容易过拟合等问题,所以本文主要介绍数据量级在千级及以上的数据集,这些数据集出现的时间节点为深度学习兴起之后,具有更多样化的场景及图片数量,数据集的总结见表2。
Frames Labeled in Cinema(FLIC)Dataset[28],此数据集包含从好莱坞电影中收集到的5 003 张图片,通过人体检测器捕捉到了20 000多个人体候选图片,这些候选图片送到Amazon Mechanical Turk 进行人体姿态的标注(10个关键点),然后手动删除其中遮挡较为严重的数据最后得到总数5 000级别的数据集。

表2 人体姿态估计数据集
Leeds Sports Pose(LSP)Dataset[29],这是一个收集于Flickr 中的运动图片数据集,包含8 种运动标签(棒球、体操、跑酷、足球、网球、排球、羽毛球、田径),其包含2 000张图片,关键点数目为14个。
Max Planck Institute for Informatics(MPII)Human Pose Dataset[30],这个数据集是目前最为主流的数据集,其标注信息相当丰富,数据集数量首次达到了万级别,数据集的原始来源是youtube 的视频,从中挑出大约24 920帧的图片数据,标注了16个关键点,相较于之前的数据集增加了眼鼻关键点。
3.3.2 2D人体姿态估计的评估标准
数据集的不同也意味着其特点(人体体长标准选用上半身或全身)和适用的任务范围不同(单人多人),这就需要不同的评估标准来进行算法模型效果的衡量。
Percentage of Correct Parts(PCP)[31],早期使用的标准之一,主要用于表明躯干的定位精准程度,如果两个端点定位偏差在ground-truth 的一定阈值范围之内(通常这个阈值设定为50%)则表明定位正确,这个躯干部位包括身体、大腿、小腿、前臂、头部等,在每个部位的基础上取其平均值即可得到mPCP值。
Percentage of Correct Keypoints(PCK)[32],与PCP不同,PCK的评判标准适用于判断关键点(如手关节、踝关节、膝盖等)的预测准确度,定位正确的判断标准为判断定位的位置是否落在groud-truth 的一定阈值半径范围之内,这个阈值通常设定为躯干长度的一定比例值或者头部长度的一定比例值,常用的标准为头部50%的比例值,标记为PCKh@0.5。
The Average Precision(AP),这个指标主要用于多人姿态估计的准确度评估,且适用于那些没有标注人体的bounding-box图片,这些图片通常只标注了对应的人体部位,其评判方式类似于目标检测的评判方式,主要通过判断关键点是否落在一定区域范围内来进行评判,在这个范围内即被判断为正样本(true positive),所有预测出的关键点会依据PCKh的得分情况次序列出,没有在ground-truth 范围内的检出结果被判定为负样本(false positive),mAP 表示的是所有关键点的AP 指标平均值。COCO[14]中,这个评判方式被进一步细化,提出了Object Keypoint Similarity(OKS)的计算方式,以OKS为评判正负样本的标准,此指标与目标检测中Intersection over Union(IoU)的功能是一致的。
3.4 小结
人体姿态估计作为动作识别任务的前置任务,直接影响了动作识别任务的最终效果,由于目前的数据集数量约束,人体姿态估计可作为动作识别的中间任务,进一步进行下游任务时也可以处理得比较灵活,既可以使用手工特征对动作进行判断识别,也可以进一步使用更高级的算法对动作进行识别,在动作识别实现落地的过程中,人体姿态估计是必不可少的一环。
4 动作识别
动作识别是视觉任务中理解范畴的任务,即对视频中的人的行为进行识别,其应用范围广泛,包括智能安防、虚拟现实、多媒体视频内容理解等,其中简单层面的动作识别任务又叫做动作分类,这类任务是给定了一小段视频片段,然后对其进行分类,处理起来相对容易,还有一类任务是检测并分类,即给定一段视频要先进行人的定位和视频时间区间上的分段,然后再对检测出来的段进行动作分类,这类任务相对较难。
4.1 传统方法
在传统方法中,其主要特点是动作识别所使用的特征是手工设计的特征,如iDT[33-34],其使用的分类器主要是SVM、决策树或随机森林,相对深度学习方法,传统方法的可解释性更强,在理论分析上更有优势。
4.2 深度学习方法
随着计算机视觉[19,35]和自然语言处理[36-37]的深度学习方法的兴起,基于深度学习方法的动作识别模型也得到了进一步的研究,且相较于传统方式取得了更好的效果,其主要优势在于用深度学习模型抽取特征替代了传统的手工设计特征,且可以实现端到端的训练方式,但在可解释性上目前还存在一些问题。动作识别的最初直接思路是对视频中的每一帧静止图像进行动作识别,这种做法丢失了时间维度的信息,在区分高度相似的动作时会存在很大的问题,如“开门动作”和“关门动作”,所以如何建模时间维度的信息是动作识别准确度的关键要素。后续发展的方向可以根据是否进行检测人体关键点的上游任务来区分为不检测关键点的videobased的方法和检测关键点的skeleton-based的方法,表3是对动作识别模型的总结。
4.2.1 Video-based
这类思路是直接方式,即对视频输入进行直接检测分类,不需要skeleton关键点生成的中间步骤,相对关键点检测能建模更多丰富的上下文信息,其中有两类主要采用的方法。
第一类方法是三维卷积,为了解决前述时间维度信息建模的问题,直接思路是引入三维卷积,在原来二维卷积的基础上扩展空间特征到时间维度上,直接提取包含时间维信息的特征表示,卷积核扩展为3D卷积核,卷积的结果是通过堆叠的方式产生的,Ji等[45]首次将三维卷积的方法引入了人体动作识别领域,7个连续的图像帧被随机地从视频中截取出来,通过一些手工设计的操作输出有33 个通道的特征图(如灰度特征图和光流特征图),这些特征图作为卷积网络的输入,通过一组设计好的卷积网络抽取更深层的特征表示,最末端接上全连接层进行分类任务,文中的实验证明在有噪声干扰、有遮挡的情况下也能取得很好的识别效果。
Tran 等[39]分析了三维卷积核的尺寸对模型性能的影响,文中用大量实验证明,对于多数情况下,使用3×3×3尺寸的卷积核能获得最佳性能,文中设计了一个简单的三维卷积模型C3D,结构简单且容易训练,该模型除了可应用于动作识别之外也可用于目标检测。
Sun 等[40]提出可将三维卷积进行分解的思路,将三维卷积分解为二维卷积和一维卷积,在模型的低层使用二维卷积来抽取低层的特征,然后在高层使用一维卷积来进行时间维度的特征融合,这样的设计降低了模型的复杂度,其实验结果表明此设计有利于缓解过拟合问题。
第二类方法是Two-stream,这是目前研究最为主流的方法,视觉方面的研究表明,视觉信息的处理是由两个不同信息处理函数的分支组成,分别是做动作的指导调整分支和认知识别分支,由这个思路启发,Simonyan等[41]将Two-stream的思路用于动作识别领域,思路是做两个分支,一个分支的输入是随机选取的一帧静止图像,将静止图像输入RGB 分支提取空间域的特征,另一个分支是光流分支来提取时间域的特征,光流分支采取的输入是该帧静止图像的前后10 帧图像,这两个分支是独立的,提取空间特征的网络结构和做图像识别任务的网络结构类似,所以可以采用ImageNet上的预训练模型,然后结合起来做动作识别任务,其实验结果表明可在小数据集上也取得良好的效果。

表3 动作识别模型
Feichtenhofer 等[46]基 于Two-stream 进 一 步 进 行 改良,将三维卷积融合的方式加入到卷积网络的后段进行时空域信息的融合操作,其文中的实验结果表明这种操作可明显提升网络性能且缩短训练时间。
之前的研究提出的方法是在一个预固定好的区间范围内做的动作识别任务,即对一段完整的视频进行采样,选取其中需要判断的部分进行识别,而不是直接对完整视频进行处理识别,Wang 等[42]提出了Temporal Segment Network(TSN),这是首次实现对完整视频的端到端处理,TSN基于Two-stream的思路,引入了VGG网络结构,一段较长的时间序列视频经过时间域稀疏采样策略被分割成了不交叠的视频片段,然后每一段视频都独立作为训练样本输入,最后通过融合函数将不同序列段的输出特征进行融合,最后输出整个视频的动作描述。
4.2.2 Skeleton-based
人体的骨架信息实际上是对人体的拓扑结构进行简化,其在描述人体动作上是信息充分的,相较于直接对视频片段进行处理,既可以降低噪声干扰,也可以减少多余的计算消耗,在面对图像的各种变化时也具有更强的鲁棒性,同时也有一些针对人体骨架识别的传感器被开发出来,如微软的Kinect[47],还有一些优秀算法也可以轻松生成人体骨架数据,基于骨架信息进行的动作识别可能会是之后动作识别领域的主流方式。
基于骨架序列做动作识别问题实际上是时序问题,传统的方式是通过手工设计的特征来进行动作识别和判断,这些特征包括不同关键点之间的位置偏移旋转等,Wang 等[48]指出这种方式做动作识别会导致模型的泛化性能很差,基本只能针对特定的任务才能表现出效果,深度学习方式具有很强的抽取特征能力,在模型泛化性上会比手工设计特征的方式要好得多。
由于动作识别存在时域的信息,最早的思路是引入具有抽取时域特征能力的RNN 网络,Du 等[43]采用了RNN 结构进行序列特征的表示,文中将人体的骨架序列分为五个序列部分分别输入五个RNN子网络之中进行序列特征的表示,采用了多层堆叠的方式处理前后输入的特征,对最后输出的特征向量进行分类判别动作。
人体骨架是一个自然的拓扑结构,而RNN 只能抽取其序列信息,在表征其特征时仍有不足,而图结构可以有效表征图拓扑结构数据特征,所以基于GCN 的方法被越来越多地应用于基于人体骨架的动作识别任务之中,使用GCN 的核心问题是如何将原始数据组织为特定的图结构。Yan 等[44]首次提出了基于GCN 的动作识别模型ST-GCN(Spatial Temporal Graph Convolutional Networks),其将人的关键点作为时空图的顶点,而时空图的边是用人体连通性和时间来表示,最后使用标准的SoftMax分类器对输出的特征进行分类。
4.3 数据集
动作识别的数据集有两种类型,一种是RGB 类型的,另一种是适用于基于骨架的行为识别数据集,这种类型的数据集通常还包含深度数据,这两类数据集分别适用于不同的任务,进而又使得这些任务采用不同的方法,基于RGB的数据集主要用于Video-based的方法,而基于骨架行为识别类型的数据集主要用于Skeletonbased的方法。
UCF-101[49],这个数据集包含13 320个视频片段,包含了101 种户外的动作类别,是RGB 类型的数据集,其中视频的帧率为25帧,视频的分辨率为320×240,每段视频剪辑的平均时长为7.21 s,视频的总时长约为1 600 min,最短时长为1.06 s,最长时长为71.04 s。
HMDB-51[50],这个数据集的数据来源是youtube 上的电影以及视频,具有7 000左右数量的视频片段,分成了51组动作类别,这个数据集被分成了3个训练集和3个测试集,集合之间是没有重叠部分的,这个数据集也是RGB类型的数据集。
NTU-RGB+D[51],与其他数据集最大的不同是增加了深度数据,目前已有基于深度数据的算法[52],这个数据集的主要采集设备是Kinect v2,包含了56 880 个视频片段,是目前最大的基于骨架行为识别类型的数据集,其包含了25个关键点的3D空间坐标位置。为适应不同任务目标的需求,其有两个部分,分别适用于不同的评判标准,一个是Cross-Subject类型,总共包含40 320个视频片段用于训练集,另外的16 560个用于验证集,根据不同的subject划分为40个组,另外一类是Cross-View类型,包含37 920 个视频片段用于训练集,18 960 段用于验证集,划分的标准是根据相机视角不同划分,相机2和3作为训练集,相机1作为验证集。
NTU-RGB+D 120[53],这个数据集属于骨架动作识别类型,是近期出现的数据集,其包含120个动作类别,包含114 480 个骨架序列数据,在NTU-RGB+D 中表现良好的模型,在这个数据集中仍表现较差,是目前较为有挑战性的数据集。
4.4 动作识别与智能诊断难点分析
常规人体动作识别本质上是属于视频分类任务,根据视频数据判断动作类别,而智能诊断系统需要对动作做更加细粒度的判断分析,如动作的细节姿态、动作的频度等方面,相比于常规动作识别,智能诊断系统对动作精度的要求更高,除此之外目前主流动作识别算法还存在一些难点:
(1)目前的动作识别算法对场景和物体的依赖性较大,由于视频信息提取后建模的主要部分包括外观信息,其中场景以及物体信息和动作信息耦合在一起,动作识别的结果不得不依赖于外观信息的建模,这对模型的泛化性能是一个挑战。
(2)主流动作识别算法中提取的光流特征是用来建模时域信息的,由于光流是计算视频帧间差异,其表征长时动作能力有限,在建模时域信息上仍存在不足,智能诊断系统的输入是长视频段,具有丰富的时域信息,如何对时域信息的建模是核心问题之一。
(3)目前的动作识别数据集对于动作细粒度并没有定义,如人体的变化姿态角度等更细节的问题,而这对于智能诊断系统的诊断效果很关键,因为诊断判断的依据有时就是动作的细微差别,这要求诊断系统对于动作的细粒度如何定义需要更加明确,这也对数据集提出了更高的要求。
4.5 小结
动作识别相对人体姿态估计是更高语义层次的任务,依据目前的主流数据集和方法可以分为Video-based类型和Skeleton-based类型,相较于Video-based的方法,Skeleton-based 的方法使用的数据是骨架序列数据,其鲁棒性要更强而计算消耗会更少,其数据的获取方式可来源于Kinect 的采集数据也可来源于优秀的人体姿态估计算法,对于基于骨架模型的方式如何更好建模动作信息是核心问题之一,尤其针对骨架动作识别类型的数据集而言,目前比较有效建模的方法是基于GCN 的方法,因为图结构是更好表征自然拓扑结构的方式。
依据动作识别的Video-based和Skeleton-based方法可将儿童运动障碍AI诊断系统的分为两种方式:
Video-based诊断,这类方式的优势是可实现端到端的训练,网络结构简单,但是缺点是对数据集要求更高,且由于是直接处理的视频数据,对于算力的要求也更高,适用于有良好数据集标注的情况。
Skeleton-based 诊断,这类方式的优势是对算力需求较低,因为动作识别步骤需要处理的是skeleton数据,数据量比视频更少,也减少了更多的干扰成分,但其目前的性能相对较差,且性能依赖于人体姿态估计算法的skeleton 生成结果,但其可作为一个模态的特征作为其他模型的补充,适用于多模态学习的情况。
5 结束语
人体姿态估计和动作识别是做儿童运动协调障碍两个核心子任务,由优秀的人体姿态估计算法来生成准确的人体骨架模型,然后结合动作识别中基于骨架动作识别的算法进行动作判断和打分,最终得到医疗层面的诊断结果,这是目前而言最能实现落地的技术路线方向,而不采用人体骨架模型中间层的技术路线实现起来的难度以目前的研究进展来看是相当大的,但其优势是可实现端到端的训练,对人体的特征建模能包含更丰富的信息。
儿童运动协调障碍AI 诊断系统想要实现落地目标,其未来重点研究方向包含两个层面,第一是提升识别准确度方向,目前通用的数据集还没有针对儿童的数据集,在做迁移学习过程中可能会产生准确度下降的问题,第二是降低计算成本方向,目前移动端设备的算力水准不够满足要求,直接在移动端给出诊断结果不仅诊断准确性会有所下降,计算速度也不达标,目前的常规解决思路是通过移动端进行数据采集,在服务端进行运算,这样可以缓解移动端算力不足问题,该问题的另一个解决思路是做轻量化的模型,可将整体算力上的要求降低。
对于儿童运动障碍诊断系统目前数据集缺失问题,可行的解决手段主要有两种方式,第一类是通过与医院加强合作,这样可以直接获得所需的数据集,但这样得到的数据集数量可能存在限制,第二类是在已有的小数据集基础上,通过数据增强等技术手段扩展目前数据,可通过在主流数据集上进行预训练,在小数据集上进行fine-tune的方式解决数据集不足问题。
AI 诊断系统的开发仍面临着诸多难点,自动化诊断是其主流发展方向之一,通过建立数据采样、数据分析、数据产出等自动化流程,可进一步实现技术落地和推广,该技术的进一步发展有助于提升医疗普惠程度和医疗效率,对缓解医疗资源不足有着重要意义。
猜你喜欢
中学生数理化·中考版(2022年12期)2022-02-16
今日农业(2021年8期)2021-11-28
北京航空航天大学学报(2021年9期)2021-11-02
学生天地(2020年3期)2020-08-25
电子制作(2019年11期)2019-07-04
汽车观察(2018年9期)2018-10-23
中国自行车(2018年8期)2018-09-26
北京航空航天大学学报(2018年1期)2018-04-20
中国卫生(2014年2期)2014-11-12
电视技术(2014年19期)2014-03-11
