
电网行业元数据集成数据存储策略研究
2021-01-28 03:35万婵魏理豪杨秋勇杨朝谊苏华权
微型电脑应用 2021年1期
万婵, 魏理豪, 杨秋勇, 杨朝谊, 苏华权
(广东电网有限责任公司 信息中心, 广东 广州 510000)
0 引言
随着电力行业以及智能电网技术的持续发展,电网行业中形成了大量的智能配用电数据,此类数据包括不同的类型,并且涉及到了不同的用电主体,例如有企业、政府等,而各个主体的业务以及工作重心存在明显的差异性,使得智能配用电数据表现出不同的特征。一是具有较高的数据维度,首先是电力企业的业务类型不一,并且众多的业务之间具有较高的独立性,但是无法保证各个系统数据采集时间的一致性,这是增大数据维度的重要因素;其次是不同主体在智能配用电数据的存储与管理方面难以保持一致,显著提高了数据维度[1-3];二是不同形式的智能配用电数据并存,从数据类型的角度来看,一般可以将智能配用电数据划分为结构化、非结构化以及半结构化类型,通常三者是共存的。其中结构化数据主要指的是定义比较明确的数据类型,包括常见的数据库表中的结构化数据等,而这正是传统的智能配电网业务相关的数据类型。在智能电网等新技术发展的过程中,智能配用电的基础分析数据变得更加丰富,不再只是传统的结构化数据,而是集成了音频、图片以及视频等类型的非结构化数据,在这种情况下逐步形成了三种数据类型共存的局面[4-9]。由此看出,智能配用电数据总体体现出数据规模大、更新频率高等特点。如采用传统的数据管理方式,已经无法满足智能配用电数据的管理要求。与此同时,存储设备、处理器等硬件也处于高速发展的状态,此类技术的发展都为智能配用电数据的管理提供了支持。因此,应结合大数据处理技术等新技术来实现对智能配用电数据的妥善管理,从而为用户提供更高质量的数据服务。
1 配用电大数据多源集成
随着数据处理技术的不断发展,逐步出现了更先进的数据集成技术,能够对各种异构数据源内的数据进行统一管理,降低由于数据格式不同而产生的影响,从而提升数据的使用效率。由于配用电数据的类型较多,在这个过程中不可避免的存在异构化问题,目前主要利用数据规范化以及生成标准化元数据的方式进行处理,其中前者主要是根据构建的数据字典来规范数据的存储格式;后者则是将各种类型的数据转化为规范化的XML格式数据[10-11],在这个过程中首先要通过预处理技术解析非结构化、半结构化以及结构化数据的内容,由此形成标准的XML格式数据,然后利用中间件技术来实现对标准格式数据的管理。
1.1 数据预处理
对于智能配用电数据的处理过程来说,首先应该进行预处理的过程,具体包括数据的筛选、归一化等过程,由此可以将各种类型的元数据存储为统一的XML 格式,并保存在集群节点中,从而为数据的查询与应用奠定良好的基础。其中数据的预处理过程,如图1所示。
(1) 数据筛选
首先是进行数据筛选的过程,其实就是先采用一定的方式对现有的数据进行过滤,将无用或者干扰数据剔除,一般包括数据分类、属性识别等过程。
(2) 数据变换
在数据筛选完成后,即需要进行数据变换的过程,数据变换有不同的方法,例如有平滑聚集、简单函数变换等,在实际应用中应该根据具体要求选择合适的方法,通过数据变换即可得到 XML 格式的元数据。
(3) 数据归一化
在数据变换之后需要进行归一化的过程,即采用规范化的XML格式表示数据,目前数据归一化的方法较多,常用的有离散化方法、维度归一化方法等。对于本文研究的智能配用电数据来说,首先将原始数据转化为标准的XML 格式数据,然后按照合理的方式对电网数据进行命名,如果元数据属于电网外部,则主要划分为电力用户、第三方机构以及政府元数据;而电网内部的元数据主要是根据电压等级进行划分,具体包括0.4 kV、10 kV、35 kV、110 kV电压等级元数据。在完成数据的预处理工作后会得到较为规范的XML 元数据集,便于对数据进行后续的处理。
1.2 中间件技术
中间件技术已经广泛应用于不同类型的系统设计中,能够对不同的技术提供统一的数据访问接口,从而实现数据的共享与交换。随着对中间件技术研究的增多,逐步出现了多种类型的中间件技术,并获得了较多的应用。在本次研究中主要使用了数据访问中间件技术,通过这种方式能够有效地管理XML 元数据仓库。其具体的流程,如图2所示。
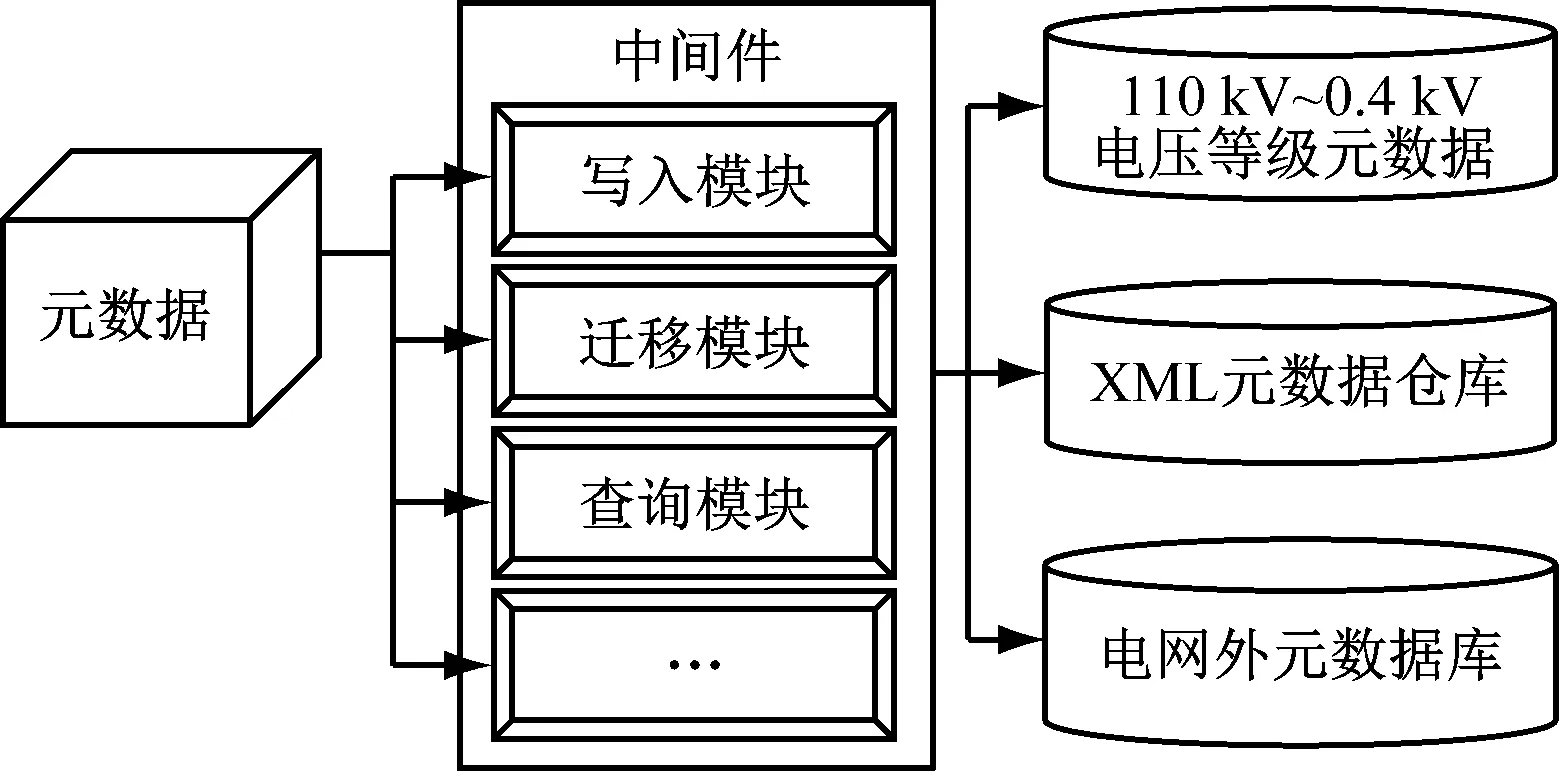
图2 基于中间件的元数据管理
2 基于Hadoop的多源配用电大数据存储优化
2.1 数据分布问题
当前在电力数据管理方面大多采用了关系型数据库实现数据的管理与存储,这种方式能够满足大多数情况下的数据管理需求。但是随着电力行业的持续发展,特别是智能电网以及微电网技术的出现,电力数据呈现出更大规模、更高量级的特征,只是采用传统的集中式关系型数据库已经无法满足数据管理需求,并且还存在查询速率慢、安全性低等问题。为了有效地解决这些不足问题,很多学者进行了研究,逐步形成了更先进的数据管理技术。其中基于Hadoop的分布式文件系统HDFS即为一种有效的解决方案,已经广泛应用到了海量数据的存储中,在实际案例中的应用效果证明了其在大规模数据存储与管理中的优势,未来具有广阔的应用前景。
2.2 基于哈希分桶算法的数据存储优化方法
很多学者在分布式数据储存领域进行了研究,并提出了不同的数据优化算法,其中哈希存储算法在数据存储优化方面得到了较多的应用。部分学者提出多副本一致,哈希算法在分布式数据存储方面能够达到一定的优化效果,但是这种方式存在一定的不足,即忽略了数据自身的关系,无法直接应用到本文研究的配用电数据中。实际中的配用电数据具有较多的类型[12-15],例如有用电负荷数据、气象数据以及地理数据等,此类数据一般不是独立的,而是彼此关联、互相影响。因此在数据存储优化中应该考虑到这种关联性,即设计一种基于数据关联性的哈希分桶存储算法,如图3所示。
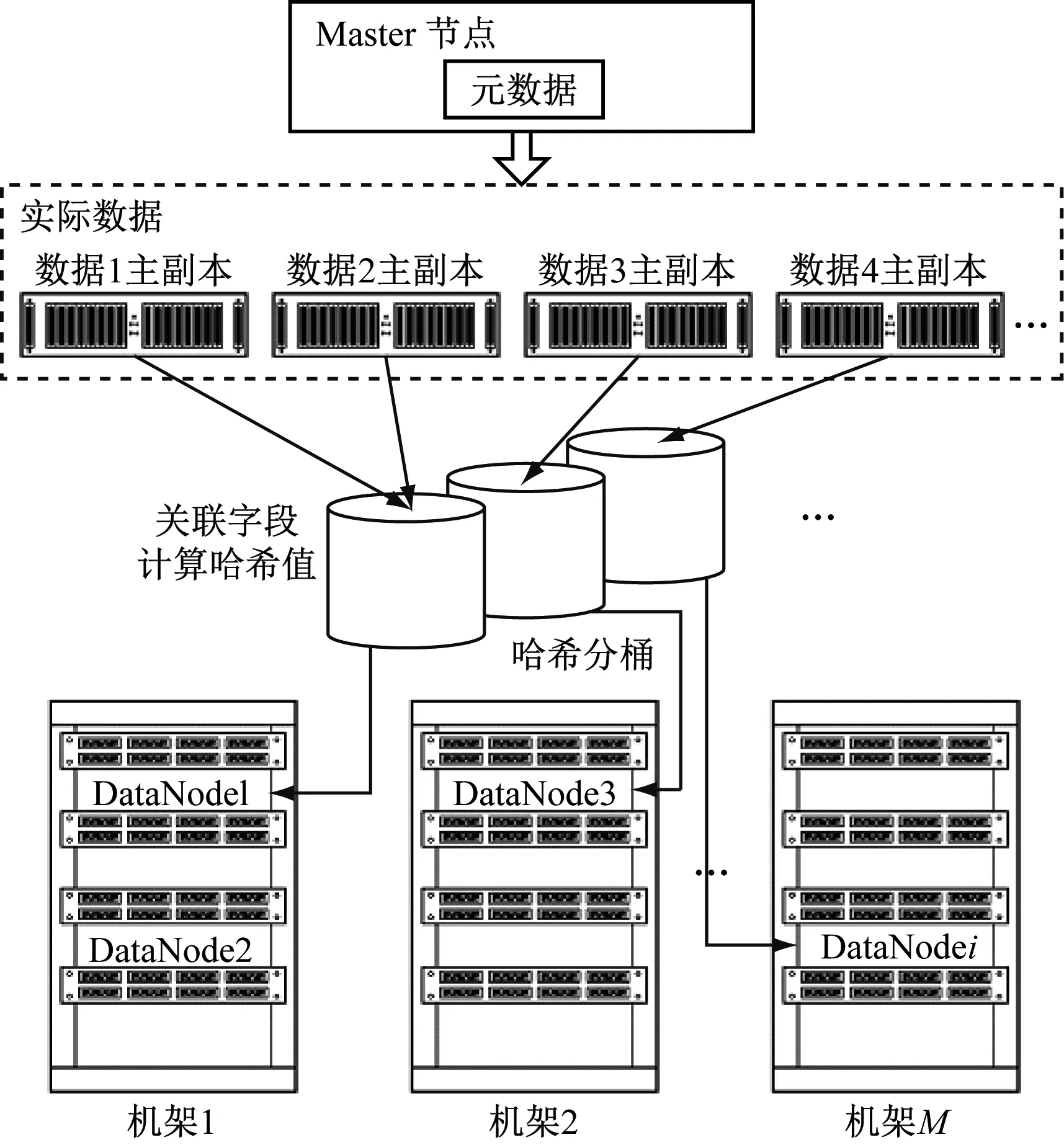
图3 基于哈希分桶算法的数据存储
由图3可知,在该存储优化方式中,体现出如下四个特点。
首先,采用分离存储的方式对实际数据与元数据进行管理,其中实际的数据都统一存储在Slave节点中,而元数据的管理则是利用Master节点实现的。分离存储的方式能够提升数据管理的逻辑性和规范性。同时对全部数据配置了三个副本,以保证数据管理的安全性与可靠性。在本次设计中考虑到不同类型业务的数据管理需求,分别采用了地理属性、设备ID当作电网外部、内部数据的关联字段,保证了数据查询的规范性。
其次是关联数据的集中存储过程,需要先将各个数据主副本统一存储在不同的桶内,然后在同一个节点中存储相同的数据,最后建立与HDFS系统的映射,由此实现了数据的集中存储。
第三,第2、3副本具有一定的特殊性,需要根据数据的传输效率等信息将其与对应的节点进行匹配。通常情况下,主副本与第3副本可以存在于相同的机架中,而第2副本存储的机架需要区别于主副本。
第四,对于各个数据节点来说,则需要采用合理的方式进行划分,例如划分数据块大小为256MB、64MB等,在这个过程中应该考虑到负载均衡以及存储的有序性,从而保证数据存储的规范性。
3 多源数据并行关联查询方法
当前在计算机计算领域中越来越多的使用了并行计算方法,其主要是把复杂的执行任务划分为多个不同的子任务,并将各个子任务分配到独立的处理器中,使得整个计算过程可以同时执行,采用这种方式能够提高系统的处理性能,并满足不断增长的计算需求。在本文中基于之前提出的哈希分桶存储优化算法已经实现了对多源配用电数据的存储,然后需要采用一定的方法解决多源数据的查询问题[16]。在本次研究中基于并行思想设计了一种基于MapReduce的查询方法,这种方法将主要的查询过程集中在Map(映射)阶段实现,避免在Reduce(约减)阶段产生过多的操作;同时在本地节点根据之前定义的关联字段完成查询过程,能够有效地提升查询效率,减少对资源的占用。详细的查询流程如下。
(1) 首先对查询的条件以及关联字段(地理标识或者是设备ID)进行确定,在此基础上可以得到MapReduce任务。
(2) 其次是形成节点中的数据文件,并通过预处理等过程得到符合标准的数据,整个过程需要考虑到集群中数据的存储特征。
(3) 然后获取Map任务中符合查询条件以及关联字段的数据,并将其划分到相同的组中,按照相同的方式可以得到各个Map任务的结果,最后汇总所有Map任务的处理结果,并得到统一的关联查询结果。
4 实验验证
针对上述提出的方案,采用试验的方式进行验证,以验证算法是否能够达到预期的性能。首先需要确定查询的条件以及关联字段,这里二者分别是时间与区域编号,将用电负荷、设备ID 建立关联后,根据确定的查询条件和关联字段对各个数据文件进行处理,由此可以得到含有气象、用电负荷等信息的数据集。在实验过程中设置不同大小的数据子集来测试对应的查询时间,如表1所示。

表1 数据基本情况
为了验证本算法的应用效果,在实验中采用了其他的方法进行对比,如图4所示。
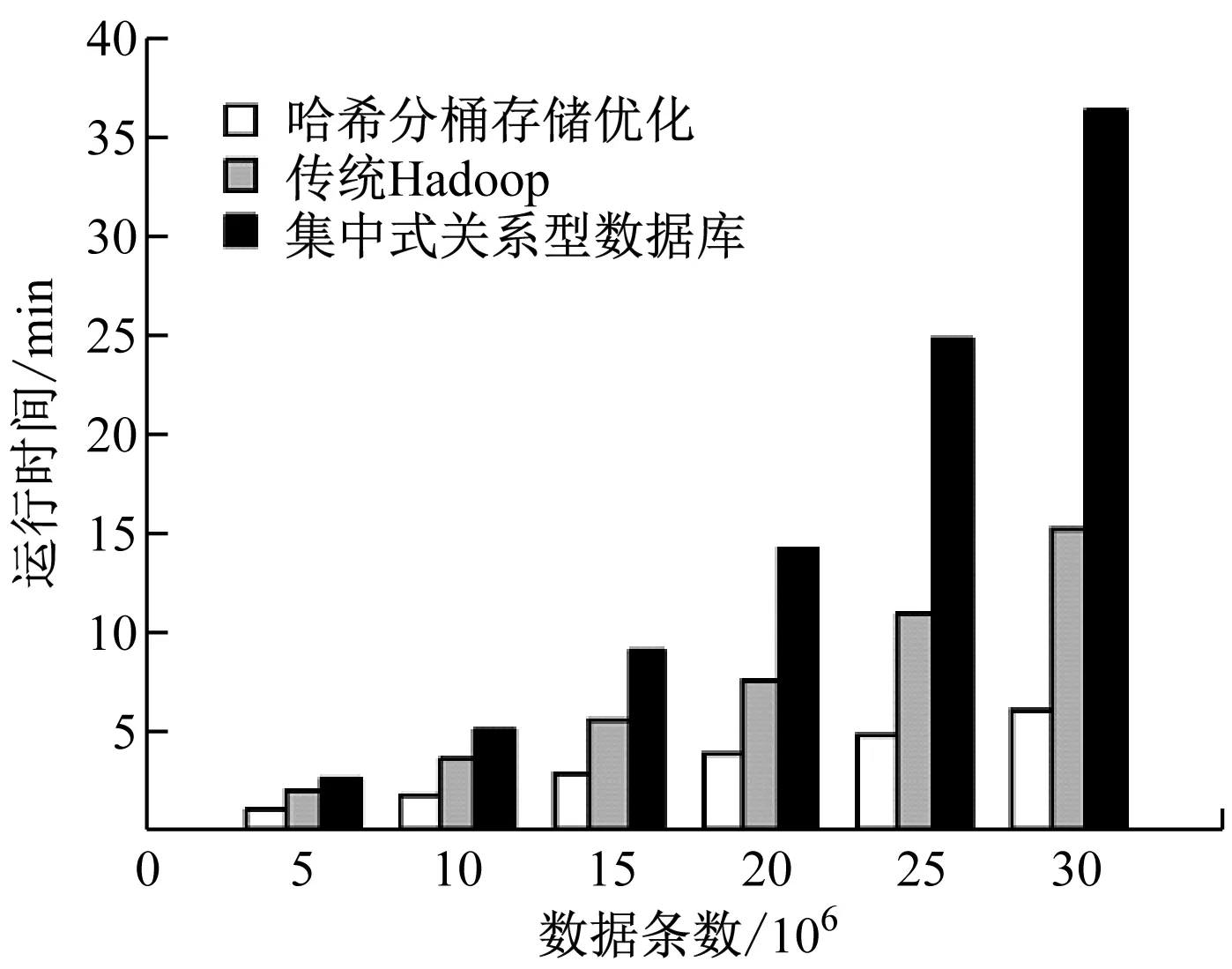
图4 不同存储方式的查询时间对比
由图4可知,相对于传统的Hadoop查询方法以及集中式关系型数据库查询方法,本文提出的基于哈希分桶存储分布优化的多源数据关联查询方法具有一定的优势,具体表现在较高的查询效率方面,能够显著降低查询过程花费的时间,在实验中根据测定的查询时间发现其分别占据其他两种方法查询时间的39.6%、16.4%。经过分析发现,本算法主要采用了集中存储关联数据的方式,无需过多的在节点之间传输数据,在本地节点即能够完成大多数的处理过程,由此不仅提升了处理效率,同时降低了对资源的占用。另外在数据集规模持续增大的过程中,本文提出算法的查询时间没有出现较大的增长,始终保持较为稳定的查询效果,因此可以将其有效地应用到多源配用电数据的关联查询中。
5 总结
通过上述的研究看出,本文针对电力行业元数据的存储问题,主要做了以下几方面的工作:一是将数据全部转换为XML格式数据,以方便进行管理;其次引入希哈分桶算法对数据进行存储,大大提高了存储效率;三是引入MapReduce的查询方案,提高了查询效率。结果表明,本文构建的方法可行,具有一定的借鉴。
猜你喜欢
汽车实用技术(2022年10期)2022-06-09
汽车实用技术(2022年5期)2022-04-02
大数据(2021年6期)2021-11-22
海洋信息技术与应用(2021年2期)2021-11-02
电脑爱好者(2021年8期)2021-04-21
电脑爱好者(2020年20期)2020-10-22
铁道通信信号(2020年4期)2020-09-21
电子制作(2018年14期)2018-08-21
电子制作(2017年13期)2017-12-15
电脑爱好者(2015年13期)2015-09-10
