
Spark环境下不完整数据集成填充方法
2021-02-04 13:51邹萌萍彭敦陆
小型微型计算机系统 2021年1期
邹萌萍,彭敦陆
(上海理工大学 光电信息与计算机工程学院,上海 200093)
1 引 言
自进入大数据时代以来,数据日益极速增长和积累,对工业、金融等各个行业都有着无比重要的应用价值.如何高效且精准地从这大量数据资源中挖掘出有价值的信息已成为了当今研究者们广泛关注的焦点.而现实中,由于数据采集过程中的丢失或网络传输过程中的错误,数据不完整已成为一个常见且不容忽视的严重问题.基于不完整数据的挖掘工作严重影响着信息的准确性和可利用性,更对后续深度学习和模型建立等工作有着直接或间接的深远影响.因此,不完整数据的填充应运而生,为大数据的分析带来了巨大的挑战.
直至今日,国内外学者已经提出了许多对不完整数据进行填充的方法.虽然一些方法在特定条件下都有着很好的填充效果,但都局限于单一类型的缺失数据填充,或适宜于连续型缺失变量,或适宜于分类型,未充分考虑数据对象的类型特征,对于真实数据中多种缺失类型共存的情况,易忽略不同类型对象之间的相互作用,严重影响填充结果的准确性.鉴于集成学习中的随机森林能有效地处理混合型变量的数据,Daniel等将其引入到对不完整数据填充的研究,构建了MissForest[1],并取得了很好的填充效果.这也意味着集成学习在混合类型的不完整数据填充问题上有着明显的优越性.但实践也表明,MissForest在运算效率上有着很大的不足,极易产生过拟合的现象,这对数据量庞大的真实数据而言,无疑也是不推荐的.
针对大数据的缺失值处理,运算效率自然是学者们广泛关注的焦点之一.分布式和并行化技术的发展为大数据研究提供了有效提升运算效率的环境.其中,Apache Spark(1)http://spark.apache.org作为一款基于内存快速处理大数据的计算框架,与机器学习算法和交互式数据挖掘的结合成效卓著.Chen等人提出的Spark平台大数据的并行随机森林算法[2]在分类精度和运算效率上都有着很大的优势,可见机器学习算法和Spark技术的结合在效率方面的优越性显而易见.因此,如何最大限度地利用Spark框架的并行计算优势来解决不完整大数据的填充问题可见尤为重要.
针对以上问题,本文提出了一种在Spark分布式环境下基于集成学习的不完整数据集成填充方法.该方法引入XGBoost[3]算法,保留了对多种数据类型的处理特性,解决了基于随机森林模型的过拟合问题,从而实现对混合数据类型的有效填充.同时,优化XGBoost算法以将其多级并行化,将同一类缺失划分到相同的簇中,并在Spark环境下进行了模型实现和验证,以解决运算效率的不足.实验结果表明,本文所提出的填充技术能够实现对混合型缺失变量的快速填充,不仅保证了缺失数据的填充精度,同时满足了大数据背景下对数据处理的要求.
2 相关工作
2.1 不完整数据填充
目前国内外学者已经提出了不少解决不完整数据的充填方法.最朴素的填充方法莫过于用统计值(均值、中位数等)或频率最高的数据进行插补.方法虽然简单,但是误差比较大,精确度也较低.后续,无论是基于统计学的填充方法,还是基于机器学习的填充方法,都可以根据其填充的数据类型分为三种:连续型、分类型以及混合型.在已有填充方法中,回归方法和支持向量机较为常用,对于连续型变量,可以利用线性回归和支持向量回归法来拟合估计其取值;而对于分类型变量,则可以利用逻辑回归或支持向量机来估计其取值.此外,期望值最大化和基于贝叶斯的填补方法也常被用于处理不完整数据的填充,但都局限于单一类型的缺失.
当前,关于混合类型数据填充的文献相对较少.对混合型变量的考量最早出现在鲁宾(1978)提出的多重填补理论[4]中.基于K近邻估计的充填方法(KNNI,K-Nearest Neighbor Imputation)[5]是实际应用中较为常见且效果很好的,其基于最靠近的k个观测样本进行缺失值的预测,分别用投票法和平均法处理分类型和连续型变量.基于决策树的填充方法,是利用已有数据构建树模型,常与EM算法结合以便于处理混合类型变量.但决策树的训练过程可能会出现过拟合现象,容易导致分类精度不高、决策时间过长.MissForest使用随机森林作为回归方法来估计缺失值,不需要假设数据的分布情况,对不同数据类型的填充都有着较高的准确度.
2.2 XGBoost集成学习算法
集成学习[6]通过结合多个学习算法来达到更好的预测表现,其使用多个学习器共同决策比使用单个学习器的预测更加准确.其次,集成学习器在大幅度提高基学习器精确率的同时,保证了基学习器的多样性,这在处理混合类型不完整数据填充问题上有着明显的优越性[7].
XGBoost(Extreme Gradient Boosting)由华盛顿大学的陈天奇博士于2016年提出,是集成学习中梯度算法的高度实现.其本质上是一个多轮迭代的过程.每轮迭代后产生一个弱学习器,然后基于该学习器的残差训练下一轮的学习器,最终的集成学习器则由每轮训练所得的弱学习器加权求和而获得.在传统梯度提升算法的基础上,XGBoost做了如下优化:
1)引入了正则化项来控制模型复杂度,优化目标函数;
2)对损失函数进行二阶泰勒展开,提升最优解的收敛速度;
3)采用列采样策略来减少训练时间;
4)采用交叉验证机制在每次迭代中运行交叉验证,以便一次运行即可获得精确的最优增强迭代数.
此外,XGBoost同随机森林(RF,Random Forest)一样能很好地处理混合类型的数据,同样具备处理缺失值的内置例程,也允许交互和非线性(回归)效应.实际运用中,基于RF的缺失值填充技术有着过拟合与运算效率上的不足.相比之下,上文1)3)两项措施的应用避免了过拟合现象的发生.其次,XGBoost采用加权分位数法来搜索近似最优分裂点,并利用CPU多线程实现了并行计算,有效地弥补了运算效率上的不足.
因此,采用XGBoost对不完整数据进行填充,更能满足大数据背景下对运算效率的需要,也能避免过拟合的发生.
2.3 Spark计算框架
由于MapReduce计算框架[8]的中间结果集缓存在外置存储系统中,且结构过于简单,不适宜于机器学习等高复用、高迭代的场景.因此,加州大学伯克利大学AMPLab实验室发布了Spark分布式计算框架[9].Spark是一种基于内存的通用高性能并行化计算工具.相比于MapReduce,Spark主要有着以下几点优势:
1)Shuffle过程中的中间结果缓存于内存中,相较于外部存储设备,内存RAM的IO读写速度能有效地提升计算效率;
2)作为分布式程序的逻辑结构,DAG模式的引入,有效增强了自己结果集的复用性和灵活性,解决了机器学习算法中的高迭代运算问题;
3)Spark在程序启动时即申请资源池,直至计算全部完成才释放,计算过程中每个线程按需从资源池获取资源,这一线程级别的资源分配方式,大幅减少了各阶段申请资源的时间消耗[10].
因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的分布式算法.
3 SXGBI—基于Spark的XGBoost填充模型
本节主要介绍基于XGBoost的数据填充算法在Spark平台上的实现.SXGBI填充不完整数据的过程如图1所示.填充模型的实现主要包括3个阶段:预处理、模型构建和缺失值填充.
3.1 预处理
预处理过程主要是对模型的并行化设计,并为后续的模型构建提供准备工作.
3.1.1 并行化设计
为了充分发挥分布式框架的计算性能优势,本文主要从两个方面考虑对算法进行并行化设计:数据并行化和任务并行化.
1)数据并行化:在物理层面上对数据进行划分,将计算所需数据分配到集群中各个Slave计算节点的机器上,各节点完成计算再将结果提交给Master节点.
2)任务并行化:XGBoost算法本身即支持并行处理,这也是选择XGBoost作为基填充器的原因之一.不过XGBoost的并行并不是在模型上的并行,它也是一种串行的结果,需要不断迭代的过程,它的并行是在特征粒度上的.结合这一特性,本文在以下两方面进行并行化处理:

图1 SXGBI模型框架Fig.1 Framework of SXGBI
一是预排序并行化:在训练填充模型之前,XGBoost预先对数据进行了基于数据块的预排序,采用压缩技术将数据集切割成多个块,并在每个数据块中按照各特征值排序后对样本的索引进行存储,并行操作每个数据块;
其次是分裂节点并行化:在进行节点分裂时,并行多线程计算每个特征的熵,以选择增益最大的特征进行分割.
3.1.2 数据预处理
RDD(Resilient Distributed Dataset)是Spark提出的弹性分布式数据集.因此,模型一开始先要使用parallelize算法将原数据集转化为Spark能处理的RDD形式.RDD是一种数据的集合,这个数据集合被划分成为许多个数据分区.结合XGBoost基于数据块(Block)的存储结构,RDD形式的原数据按照不同的块进行分区,并被分布式地存储到不同的节点上.
3.2 模型构建
模型构建的主要任务是训练各基学习器,并结合并行化处理,集成成为准确率和执行效率都较高的组合学习模型.
3.2.1 模型训练
模型训练过程主要是基于XGBoost的训练,其过程中主要有以下几个方面:
1)稀疏自适应分割策略:鉴于训练集含有部分缺失值,开始模型训练后,先采用默认值的方式忽略含有缺失值的数据(即稀疏数据),然后利用那些不含缺失的样本(即完整样本)来选择最优分裂点,以自动处理稀疏数据的方式构建初始树模型.
对于缺失值的处理,如果某个样本在特征Ak上的值tk缺失,则对于该特征上含有缺失值的所有样本做如下处理:全部分到左子节点,或全部分到右子节点.因此,根据不同的选择方向即可以得到两个不同的模型,将这两个模型中较优模型对含有缺失数据的样本(不完整样本)分裂方向作为最优分裂方向.这样,通过训练数据自动学习来确定不完整样本的分裂方向避免了预填充可能带来的偏差,更利于保留原始数据的特性.
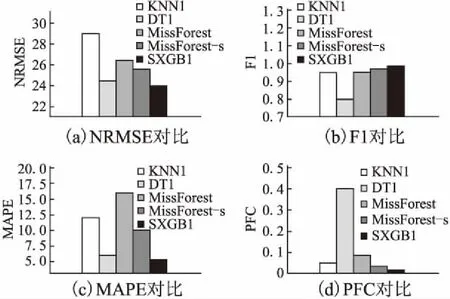
2)基组合学习器的训练:如图1的模型构建流程所示,m为Spark集群的计算节点数量.SXGBI在Spark的各计算节点上分别执行一个集成学习器的迭代训练,得到m个基组合学习器.单个Slave节点上基组合学习器的训练是串行迭代的过程,SXGBI将数据预处理后的训练集分成n份后,迭代执行n轮基学习器的训练.其中,子训练集i(1≤i≤n)用于执行第i轮基学习器的训练,且每一轮的训练都要基于上一轮的训练结果.比如,已知基学习器p和q(1≤p 此外,由4.3节实验2各对比方法对缺失率的敏感度可知,随着缺失量的增加,填充结果的偏差逐渐增大,所以在每一轮迭代的训练过程中,对于每一个缺失属性Ai={A1,A2,…,Al},本文根据其缺失量由少到多依次计算. 3)组合学习器的训练:执行上一步骤后可得到m个基组合学习器.分别用验证集验证各基组合学习器的预测能力.结合验证结果,SXGBI采用投票的方法来获得最终的组合学习器. 通过以上流程,SXGBI将学习器的训练并行化,实现了在不降低执行效率的同时还能提升组合学习器的精确性. 3.2.2 参数设置 XGBoost模型中涉及多种参数,已有一些学者对其调优做了进一步的研究.根据朱明等[11]在其文章中采用遍历方法确定的参数取值,本文中对参数的设置见表1. 表1 XGBoost参数设置Table 1 Parameter settings of XGBoost 算法1给出了缺失值填充的伪代码.对于原数据中的缺失值Mi,首先根据数据集所给定的特征属性类别标注及统计学变量分类规则来判断Mi是属于分类型变量还是连续型变量.若Mi⊂contibuous,即Mi为连续型变量,则将使用基于回归树模型的XGBoost方法进行预测填充;若Mi⊂categorical,即Mi为分类型变量,则将使用基于分类树模型的XGBoost方法进行预测填充. 算法1.基于XGBoost的缺失值填充 输入:D:不完整数据集: M{M1,…,Mi,…,Mn}:特征属性集合: Mi⊆{continuous,categorical} 输出:D′:填充后的完整数据集 1.Begin: 2.fori in 1:ndo 3.ifMi⊂continuousthen 5.endif 6.ifMi⊂categoricalthen 8.endif 9.endfor 10.returnR′ 实验环境为1个Master、7个Slave节点的spark分布式集群.每个节点的配置如下:操作系统为Ubuntu 16.04,64位,处理器为2.6Hz六核Intel Core i7,16GB内存;在Hadoop 2.7.1上构建的集群环境Spark 2.1.0;编程语言采用的是Scala 2.11.8. 为了全面控制本文使用的数据库中的缺失值,本文选择的所有实验数据集均为没有缺失记录的完整数据集.为了评估本文所提模型对不完整数据集填充问题的有效性及对大数据处理的有效性,采用了Abalone、KDD99[12]和URL Reputation[13]等3个数据集,每个数据集都同时包含连续型和分类型特征属性.表2列举了上述数据集的实例个数和属性个数. 表2 数据集Table 2 Datasets 为了证明本文方法的性能,实验部分将本文方法SXGBI与KNNI、基于C4.5的决策树填充方法(DTI,Decision Tree Imputation)和基于随机森林的填充算法(MissForest)等常见的混合类型填充方法进行了对比. 鉴于缺失变量有分类型和连续型两种数据类型,所以实验也需要从这两个方面对填充结果进行评估.本文采用均方根误差(RMSE,the Root Mean Squared Error)、标准化均方根误差(NRMSE)和平均绝对百分误差(MAPE,Mean Absolute Percent Error) 来评估连续型变量的性能,用F1值F1[14]和误分类比率(PFC,the Proportion of Falsely Classified entities)[1]来评估分类型变量. (1) (2) (3) (4) 其中,TP表示当预测为真时,预测正确的数量;FP表示当预测为真时,预测错误的数量;FN表示预测为假时,预测错误的个数. (5) NfalseC表示预测中分类错误的个数,而NtrueC表示分类正确的个数. 对于以上5种情况,RMSE、NRMSE和MAPE越小表示性能越好,偏差越小,且MAPE是用来评估同一组数据上的不同模型.如,在同一组数据集上,模型a比模型b的MAPE大可以说明模型b的效果比a好,如果只说某一模型的MAPE=20%,并不能判断该模型的好坏;PFC越接近0效果越好;而F1越接近1表示性能越好. 此外,算法加速比作为一个常见的评价程序并行化效果的指标,是算法在单机环境下和分布式环境下执行所消耗时间的比率值.后续实验中将采用算法加速比来评估执行效率. 实验过程中,SXGBI默认是在3个计算节点的Spark集群环境上实现的,而其它对比方法默认在单机模式上实现.MissForest-s是在3个计算节点的Spark集群环境上实现的MissForest算法. 实验1.不同填充方法准确率的比较 本部分实验选用KDD99网络入侵检测数据集作为实验数据集.KDD99是从一个林肯实验室模拟的美国空军局域网上采集来的9个星期的网络连接和系统审计数据,共计500万条记录,每个连接记录包含了41个固定的特征属性和1个类标识,标识用来表示该条连接记录是正常的,或是某个具体的攻击类型.在41个固定的特征属性中,9个特征属性为分类型,其他均为连续型.本文仅使用其中完整的训练数据500000条作为原始完整数据集KDD99.实验开始前,在KDD99完整数据集上使用随机生成器删除15%的记录,生成本部分实验的模拟数据集KDD99′. 图2 不同方法在KDD99′数据集上的填充结果Fig.2 Results of different methods on KDD99′ 为了验证实验中各方法对混合类型不完整数据的填充效果,本文用KNNI、DTI、MissForest、MissForest-s以及SXGBI分别对KDD99′进行缺失数据的填充,并分别采用NRMSE、MAPE和F1计算每个方法所填充连续型数据和分类型数据与原完整数据集KDD99的偏差和准确性. 对比图2中的结果,本文方法SXGBI无论是对连续型还是分类型数据的填充上都优于其它4种填充方法.结合图(a)、(c)可见,DTI准确度仅次于本文的SXGBI,但F1却是最低的.结合3个指标,对比MissForest和MissForest-s可见,加入Spark并行化计算框架能够有效地提升不完整数据的填充效果;比较MissForest-s和SXGBI,由于XGBoost对过拟合现象的有效解决,SXGBI取得了更小的NRMSE、MAPE、PFC值及更高的F1值,这也进一步证明了本文选择XGBoost作为集成填充方法基填充器的优越性. 实验2.缺失程度对填充效果的影响 为了评估每个方法对缺失程度的敏感度,本部分用SXGBI在不同缺失程度的Abalone模拟数据集上进行填充实验,并分别使用RMSE、F1和PFC评估每个模拟数据集上的填充精确度.如图3所示. 图3 不同缺失程度下对Abalone的填充结果Fig.3 Results of imputing Abalone under different degrees of missing 1)当完整比相同时,缺失率的增长会极大影响填充的准确性.完整比一致时,随着缺失率的增长,RMSE和PFC 不断增大,F1不断降低,填充准确度逐渐下降.实验中的方法对缺失率的敏感度都较高,但相比而言,SXGBI在缺失率较高的情况下仍可以达到相对其它方法更好的填充效果. 2)在缺失率相同但完整比不同的情况下,完整比高的填充效果明显更佳,因为完整数据占比多更有益于模型的自主学习与训练.随着完整比的下降,如实验中的其它方法一样,SXGBI的填充效果也随之减弱,但SXGBI减弱的幅度相对较小. 实验3.不同方法在大数据集上的执行效率 为了验证本文所提出的Spark平台上集成填充模型的计算效率,本实验就所提方法SXGBI与KNNI、MissForest两种单机填充方法在URL Reputation数据集上进行了填充实验对比,并记录了各方法执行过程的运行时间.运行时间比,是方法执行所消耗时间与当前已知最短运行时间的比率值.表3显示了各方法执行的运行时间比.SXGBI的计算时间明显短于其它两个方法,执行效率高,这对于大数据的处理明显有着运行效率上的优势. 表3 不同方法的运行时间比对比Table 3 Run times ratios of different methods 为了深入探究SXGBI的分布式处理优势,本文进一步测试了SXGBI的加速比随集群点数量的变化情况.实验仍在URL Reputation数据集上进行,分布式集群节点的数量依次取{1,2,3,4,5,6,7},并记录各节点数量时的算法加速比.由图4中SXGBI算法的加速比实验结果可知,随着Spark分布式集群节点数量的增加,SXGBI加速比呈线性增长,但同时其增长趋势逐渐减缓.这也表明,在Spark分布式环境下训练的XGBoost有着更好的运行效率.面对海量不完整大数据时,可以通过增加Spark分布式集群中计算节点的数量来大大提升SXGBI的填充效率. 图4 不同集群点数量的加速比Fig.4 Speed-up ratio of different cluster points Spark环境下不完整数据集成填充方法的提出,对于大数据时代中数据的缺失问题有着十分重要的作用.本文综合考虑了真实数据中混合类型变量及数据集庞大两方面问题,在XGBoost集成填充缺失数据的基础上,通过结合分布式并行化的设计,提出了在Spark平台上改进的XGBoost填充方法—SXGBI.一系列实验结果表明,相比已有的填充算法,SXGBI无论对连续型还是分类型缺失变量都有着较高的填充准确度,同时也能适应大数据时代,满足快速处理大数据的需求.在下一阶段的工作中,我们将对不完整数据集进行深入分析,综合考虑样本不同缺失程度与不同类别的权重,改进采样方法;同时对算法进行优化和拓展,以获得更好的填充效果.
3.3 缺失值填充
4 实验及分析
4.1 数据集及实验设置

4.2 评估指标
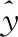
4.3 实验结果分析




5 总 结
猜你喜欢
导航定位学报(2022年4期)2022-08-15
现代电子技术(2022年4期)2022-02-21
小学生学习指导(低年级)(2021年12期)2021-12-31
计算机应用与软件(2021年10期)2021-10-15
科学与财富(2021年35期)2021-05-10
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
阅读与作文(英语初中版)(2019年8期)2019-08-27
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
中学生数理化·高一版(2017年1期)2017-04-25
中学生数理化·高一版(2017年1期)2017-04-25
