
多判别器协同框架:高品质图像的谱归一生成对抗网络
2021-02-04 13:51张哲新原俊青郭欢磊何熊熊吴安鹏丁佳骏
小型微型计算机系统 2021年1期
张哲新,原俊青,郭欢磊,何熊熊,吴安鹏,丁佳骏
1(浙江工业大学 理学院,杭州 310014) 2(浙江工业大学 信息学院,杭州 310014) 3(杭州电子科技大学 计算机学院,杭州 310018)
1 引 言
在过去的几年内,深度学习方面的研究取得了长足的进展.深度学习算法的核心是构建一个具有深层结构的神经网络,从输入数据中提取并分析特征,以适应各种各样的下游任务.随着任务需求的变化,深度置信网络(Deep belief network,DBN)、卷积神经网络[1](Convolutional Neural Networks,CNNs)等各式各样的网络模型不断涌现[2].其研究结果被应用到生活中的许多方面,例如语音识别,文本翻译,人脸识别,智能监控,自动驾驶,智慧城市等,极大地提升了各行各业的工作效率.
计算机视觉领域是深度学习应用的主要方向之一,其原因在于相对结构化的高维图像数据更容易实现数据的特征提取,进而能更好地配合下游任务.深度学习在计算机视觉方面一个典型的应用场景是在广域图像大数据集ImageNet[3]上进行的图像分类(Image classify)问题,在深度卷积网络[4]的基础上,许多学者设计了多种不同的网络结构来处理这一问题,Kaiming等[5]设计了整流神经网络(Rectifier neural networks),通过可变的激活函数来限制图像分类中的过度拟合现象;Rastegari等[6]设计了同或卷积网络(XNOR neural networks),通过二值化权重层在提高训练中的空间利用率的同时取得更好的训练效率.
在后续的研究中,部分学者开始不再满足于基于图像的模式识别,转而开始研究如何将低维信号还原成图像;然而高效地生成高仿真度的图像需要对原始图像的特征值具有更加精准的把握.2014年,Ian Goodfellow[7]创造性地提出了生成对抗网络(Generative Adversarial Networks,GANs).生成对抗网络是一种由生成器与判别器组成的神经网络架构,以判别器的判别结果作为生成器的损失函数,交替训练优化.迄今为止,GAN在图像生成方面取得了相当优秀的成果.Yang G等[8]利用GAN对具有特殊噪声的磁共振(MRI)图像执行重建,在观测过程中以更高的容错率期望减少观测成本,取得了优秀的成效.
近年来,在GAN架构的基础上,涌现出了一系列神经网络变体.其中,谱归一生成对抗网络结构(Spectral Normalization GAN,SNGAN)是一种较新颖的网络架构,最早由Takeru Miyato[9]提出,相关实验表明,SNGAN在图像还原方面效果显著.SNGAN通过在卷积神经网络中加入谱归一化层,限制训练过程中的梯度回传,在理论层面避免了通常意义上的“梯度爆炸”问题,从而获得优秀的训练结果.
本文基于SNGAN网络结构,建立了利用独立分布式训练的多判别器协同架构Multi-SNGAN.并通过实验与其他常用网络结构进行了对比.
2 相关工作
2.1 生成对抗网络(GAN)
生成对抗网络由生成器网络G与判别器网络D构成,生成器可以通过表征向量生成仿真样本,一同与真实样本输入判别器,判别器分析仿真样本和真实样本真假的概率,反馈生成器,从而达到两者相互对抗、共同学习、共同优化的目的.生成对抗网络在数据生成的领域中效果显著.一个非常好的例子是康云云等[10]将GAN架构(如图1所示)应用于LSTM模型上,构建了法律文书生成系统.此外,GAN也被广泛用于医学图像重建[11]、人脸还原[12]等方面.
以图像生成这一应用情景为例:生成器接受满足一定分布特征的随机信号,生成图片样本;而判别器同时接受真实图片与仿真图片,判别输入图片的真实性.随后该判断被反馈至生成器,用于训练生成器以生成更加逼真的图片,期望判别器难以分辨真实图片与仿真图片.
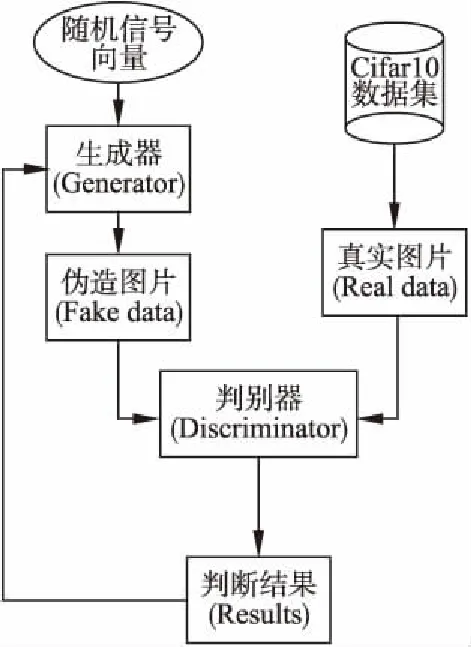
图1 经典GAN网络结构图Fig.1 Classical GAN structure
记样本集{x1,x2,x3,…,xn}~P,与给定真实样噪声集{z1,z3,z3,…,zn}~Pz,其中Pz为预先确定的分布,P为样本集满足的未知分布.记生成器的输入为z,输出的 “假” 数据可表示为G(z).判别器的输入对真假数据分别输出一个一维标量,代表输入为真的概率,分别记为D(x)与D(G(z)).生成器和判别器进行极大极小博弈,网络优化过程目标函数为:
(1)
理想情况:

(2)
其全局最优解为:
z~PzG(z)=P
(3)
在实际训练过程中,生成器与判别器的训练过程是交替进行的,更新一方的参数时,另一方的参数固定住不更新.在两者彼此交替的过程中,生成器与判别器同时逐步向全局最优解靠近.
2.2 谱归一化生成对抗网络(SNGAN)
在图像识别的网络训练过程中,随着神经网络的层数叠加,梯度爆炸和梯度衰减等梯度现象是影响网络识别率下降的主要原因之一[13].谱归一生成对抗网络架构(Spectral Normalization GAN,SNGAN)是一个新近提出的,基于谱归一化操作构建,以解决上述问题为目标的架构.SNGAN网络结构如表1所示.

表1 SNGAN网络结构Table 1 Network structure of SNGAN
经典CNN的结构中,一个层一般由一个卷积层与一个归一化层(Normalize Layer)复合构成.目前的大多数神经网络采用的归一化层是Sergey Ioffe 等[14]于2015年提出的Batch Normalize,即对于每一组传入归一化层的梯度,输出:
(4)
Batch Normalize虽然在一定程度上钝化了在训练过程中偶尔会出现的极端梯度值,减少了随机性对训练过程的影响,但是Batch Normalize的效果受限于每组数据的分布.在神经网络训练多代之后,整组数据的方差非常小,而极端值仍有可能出现,此时Batch Normalize也无能为力.针对这一问题,Arjovsky 等[15]提出了Wasserstein GAN(WGAN),通过直接设定梯度上限并剪裁梯度的方式使得梯度反向传播过程满足Lipschitz连续条件,略微优化了神经网络的效果.然而,简单地剪裁梯度虽然有效避免了梯度爆炸,却同时损坏了梯度回传过程中产生的信息完整性.
我们知道,一个典型的前馈神经网络可以被抽象为一个函数:
f(x,θ)=WL+1aL(WLaL-1(WL-1aL-2(…a1(W1x)…)))
(5)
其中θ为网络超参数集,W是各层可优化的网络参数,an是对应第n层的激活函数.
SNGAN的特点是以其独创的谱归一化层替换传统网络中的归一化层,在反向传播过程中对矩阵进行谱归一化(处理,使得层与层之间的梯度传递过程始终满足Lipschitz连续条件.为了避免随着神经网络的逐层前馈误差逐渐增加而引起梯度爆炸,我们需要令:
‖f‖Lip≤1
(6)
显然传统的Batch Normalize不能满足这个条件,故我们采用Spectral Normalize替换之,即:

(7)
其中σ(W)为矩阵W的谱归一化值,即:
(8)
由(7)式,对于任何层的抽象函数gn(x):=xWnan(x),有‖g‖Lip≤1,进而由Lipschitz连续的传递性,我们可以保证‖f‖Lip≤1.
谱归一化处理将每组数据对权值产生的影响限制在一个小范围内,使用多次少量更新权值的方法训练神经网络,使得训练过程自始至终保持平滑,偶发性的极端数据的影响降到了最小.
2.3 其它改进损失函数的尝试
Zhao J等[16]提出的能基生成对抗网络(Energy-Based GAN,EBGAN)是在原始的GAN的基础上,通过改变训练过程中的损失函数方式而产生的新的GAN架构.架构中的判别器抽象为两层:编译(Encode)与解码(Decode).即:
D(x)=‖Dec(Enc(x))-x‖
(9)
对应的生成器与判别器的损失函数LG,LD分别为:
LG=Ex~Pr‖Dec(Enc(G(z)))-G(z)‖
(10)
LD=Ex~Pr[Dec(Enc(x)))-x]+Ex~Pg[max(0,m-‖Dec(Enc(x))-x‖)]
(11)
EBGAN的损失函数设计基于与谱归一化相同的思想,即通过限制损失函数的值域限制单次训练中权值的变化.
2.4 其他协作式生成对抗网络
张龙等[17]构建了应用多个生成器共享部分权值的GAN架构,称为协作式生成对抗网络.Liu等[18]构建了一个应用两组生成器-判别器组之间共享权值的GAN架构,称为耦合式生成对抗网络(CoGAN).这些协作式生成对抗网络均采取了在运行过程中共享部分神经网络的权值的方式.这一方式确实可以非常好地完成“共享训练成果”这一目的.然而在实际运行中,共享权值是一个内存或显存读写量非常大的操作,导致在多个物理设备上并行运行多个神经网络时,共享权值的行为开销非常高昂,效果优秀但时间成本相对高昂.
3 多SNGAN架构
神经网络的训练是随机梯度下降过程,不可避免地,在单次训练过程中会存在部分未能进行有效学习的特征模式.在GAN的训练过程中,生成器与判别器彼此对抗,判别器的判别结果反馈作为生成器的损失函数,若一个判别器没有充分学习到真实数据的特征,对应的生成器就无法得到正确的反馈.也就意味着生成器不可能习得判别器没有学习到的特征模式,生成器的模式崩溃问题将会比判别器体现得更加严重.
基于这一现实中存在的问题,我们认为,如果设置多个各自不同的判别器,令其分别并行训练,并与同一个生成器对抗,多个生成器学习到的模式可以在更大程度上覆盖样本空间,减少判别器组整体的模式崩溃,让生成器学习到的模式更加全面.

图2 多SNGAN架构图Fig.2 Multi-SNGAN structure

3.1 多判别器协作架构
本文实验中采用多个彼此独立的判别器对单个生成器的结果进行判断,并将结果求均值之后作为反馈提交给生成器,以此来引导生成器的训练过程.由于判别器的初始状态不同,从图像中提取的特征也不同,通过平均的方式可以使生成器的图像获取更完整的特征.
与此同时,多个独立判别器的架构也允许各个判别器在不同的物理设备上进行独立并行运算.虽然运算量提高了,但在实际应用中,其训练时间与单个判别器训练时几乎相等.
训练过程中,判别器Di的目标函数为:
maxEx~PlnDi(x)+Ez~Pzln(1-Di(G(z)))
(12)
生成器G的目标函数为:
(13)
SNGAN的成功是源自限制梯度回传时的数值,从而避免了梯度爆炸问题.基于这一思想,我们猜想,如果能够进一步限制梯度的取值范围,或可取得更好的效果.由于判别器与判别器之间相互独立,当n个判别器被训练多代之后,可以认为它们的结果是独立同分布的.记Pr为各判别器对伪造图片的判别结果的分布:
Pr:={D1(G(z),D2(G(z),…,Dn(G(z)}
(14)
取训练过程中的一个阶段,记各个判别器的判断与准确判断的差异为d=Dn(r)-L(r),由于训练过程是具有随机性的逐步逼近过程,故{d1,d2,…,dn}∈N(μn,σn2).其中μn,σn2分别代表该阶段生成器分布与实际分布逼近程度的期望值和各个判别器之间的方差.易得反馈到生成器的损失函数:
(15)
进而有:
(16)
即生成器得到的反馈比单个判别器更加集中于理论期望值.
由此可见,通过对多个判别器的结果取平均值,在整体上而言平衡单个判别器在训练过程中产生的损失函数值的震荡,使得生成器得到的反馈趋于接近判别结果的期望值E(Pr),有利于生成器对图像整体的把握.与此同时,在图像细节方面,单个判别器训练过程中不可避免的会存在一些没有学习到的特征,而多个判别器则可以在分立并行的学习过程中各自学习到数据集中不同的细节特征,进而帮助生成器学习到较为完整全面的特征.
理论上,多判别器架构允许任意数量的判别器共同工作.然而在实际训练过程中,判别器数量过多会导致判别器之间同质化严重,判别器数量过少则会导致单个判别器的权重对整体结果的影响过大而导致训练过程中生成器容易与单个判别器耦合.由于生成器间共享输入与判别器网络,可能会造成生成器生成分布趋于重合的现象.这样不仅无法达到预期的目标,还可能产生额外的网络负荷.为避免该现象,本文在初始化生成器时采取随机权值方式.实验表明,重合问题在实际训练过程中并未出现,不同生成器产生的结果始终保持着一定的差异.我们认为3个判别器能给出一个稳定而始终具有一定方差的结果分布Pr.
3.2 不同学习率判别器的协作
学习率是网络训练中最重要的超参数之一,以单张图片为例,较大的学习率意味着网络的更新更加快速,对图像整体结构的把握更优秀;而较小的学习率意味着网络的更新较稳定,对图像细节的把握更精准.由于初始状态的差异性在训练过程中会被快速地平滑化,为了保证训练过程中各判别器保有持续的差异性,可以调整各个判别器的学习率.来保证即使在训练的后期,不同的判别器也能保证一定程度上的差异.
本文实验中采用了多个实验组,以3个判别器学习率相同的情况作为对照,在保证判别器学习率差别不至于过大的前提下,将3个判别器的学习率进行调整,进行多组实验.实验结果表明,不同学习率的判别器组表现均优于单个判别器的表现.
4 实 验
在实验中选用cifar-10数据集作为训练与测试数据集.运行环境为pytorch0.4.0,显卡为NVIDIA GeFORCE GTX 1080Ti.
4.1 实验基准
本文实验使用弗雷歇距离(Fréchet Inception Distance,FID)作为评价图像相似程度的标准,两组图片之间的平均FID越低,则表明图像的特征越相似.
本文主要基于Miyato等[9]提出的模型框架,采用生成对抗网络进行实验验证.生成网络架构(如图3所示)主要由归一化层、3个反卷积层以及1个卷积层构成,判别网络架构(如图4所示)则主要由7层卷积层和1层归一化层构成,命名为SNGAN算法.同时,为了验证本文提出架构的合理性与有效性,我们加深上述生成器与判别器的层数,构建了一个更深层次的网络,称为深化SNGAN(Deepened-SNGAN)架构(如表2所示).

图3 生成器网络结构图Fig.3 Generator network structure

图4 判别器网络结构图Fig.4 Discriminator network structure
在训练过程中,生成器接收随机信号向量,并将其输出为仿真图像样本.判别器接收仿真样本图像或来自cifar10数据集的真实样本图像,输出各样本来自cifar10数据集的概率.其中对于伪造图片的判断将会被返回给生成器.以训练生成器生成更加贴近真实的图像,期望令判别器难以分辨仿真图像.
在经过一定的训练次数之后将生成的伪造图片与真实图片通过FID算法进行比较.FID值越小说明伪造图片与真实图片越相似,即生成器的质量越高.在生成器网络经过一定次数的迭代训练之后,可以认为训练基本已完成.此时将生成的伪造图片与真实图片进行对比,计算其FID值.

表2 深化SNGAN网络结构Table 2 Network structure of deepened-SNGAN
训练过程中使用的随机向量均满足:
zn∈R128~(0,1)
(17)
相应的,真实图像与伪造图像均为边长为32像素的正方形3通道RGB图像,满足:
xn∈R32*32*3
(18)
迭代次数均为100000次,以生成器更新次数为准,每次训练时传递给生成器的真实图片与伪造图片各32张.生成器与判别器的优化器均使用Adam动量算法优化器(β1=0.5,β2=0.999).
4.2 实验数据集
4.2.1 Cifar-10数据集
cifar-10数据集由加拿大高级研究院(The Canadian Institute for Advanced Research)提供,是目前世界上使用最广泛的计算机视觉库之一.由于其图像的标准化程度较高,易于判断而被深度学习研究大量使用[19-21].该数据集由10种不同类型的图片组成,每种类型分为两个数据集:5000张图片构成的训练数据集和1000张图片构成的测试数据集构成.表3给出了十个类别的一些示例图片.
在训练过程中,我们忽略类别标签,将训练数据集中不同种类的图片集打乱顺序随机混合作为判别器的输入,使用测试数据集中的图片与生成器生成的图片计算FID来评估训练的结果.
4.2.2 STL-10
STL-10数据集由斯坦福大学(Stanford University)提供,也是在使用广泛的计算机视觉库之一.该数据集由3个数据集:训练数据集、测试数据集以及无标签数据集构成.表3给出了一些示例图片.
在训练过程中,我们使用无标签数据集作为判别器的输入,同样使用无标签数据集中的图片与生成器生成的图片计算FID来评估训练的结果.

表3 CIFAR-10 数据集示例图片Table 3 Sample images from CIFAR-10 dataset
4.3 实验结果
4.3.1 使用Inception score来执行初步优化
由于我们的训练过程旨在拟合整个数据集,在训练时未将图片的分类信息输入神经网络.而inception score是一个用于展示图片分类的明晰程度的指标,因此我们的实验并不以inception score作为最优化目标.虽然如此,inception score在评判同类模型相对优劣程度时仍不失为一个优秀的参考指标.4.3.2节展示了对于实验中一些模型的inception score预评估结果,根据表中数据可以得出,在本文的神经网络框架下,针对本文的训练任务最优的学习率大约是2×10-4左右,在实验中我们将它定为标准学习率.
4.3.2 基于Cifar-10与STL-10的实验结果
图5展示了FID距离在训练过程中的变化过程.图6展示了训练完成的生成器生成的部分图片示例.在图6中,可以发现生成的图片质量较高,图中可以明显地分辨出不同类别的动物与交通工具,图像主要部分具有的细节也大多在识别过程当中被有效保存下来.
可以看到的是,在使用相同的核心网络结构的基础上,相较于单个判别器,3个判别器合作的SNGAN架构生成器的生成图像质量有显著提升.

图5 训练过程FID变化图Fig.5 FID value over train epochs
在实际的训练过程中,卷积神经网络反向传播过程中权值的修改更新涉及大量的内存或显存读写,因而需要很长的时间.而相比而言,在判别器之间共享一组伪造图片所产生的额外开销几乎可以忽略.因此在实际应用中,各个判别器可以在不同的物理设备上同时并行运行,其实际训练时间与单一判别器几乎相同.

图6 最终生成图片示例Fig.6 Generated image sample
在多判别器训练的过程中,最危险的状况是多个判别器的状态在某个局部最优点的附近趋于一致,这样不仅使得生成器陷入局部最优点,还增加了额外的网络负担.图7展示了在训练过程中3个判别器的相对方差.可知判别器组在训练的全程中均保有一定的相对方差,趋于一致的情况并没有发生.

图7 训练过程中不同判别器的方差实验数据图Fig.7 Variance of different discriminators during train phase
与此同时,相较于学习率相同的架构,由多个学习率不同的SNGAN构成的合作架构训练出的生成器对图像的特征把握更精准.表4展示了目前主流的GAN网络架构在使用同样数据集和优化器,迭代次数均为100000次时的实验结果,以生成器更新次数为准.可以看出相较于其它主流GAN,本文提出的多SNGAN的架构在测试条件下均有更好的表现.
同时,我们将加深网络应用在我们的架构上.实验结果显示,针对更深的神经网络,本文提出的架构也具有提升训练表现的效果.
5 总结及后续研究
本文提出了一种SNGAN结构下的生成对抗网络的多判别器协作系统,尝试设计了该方法使用的复合式网络系统结构及相应的优化方案,实验结果表明多个判别器的复合架构可以有效地帮助生成器挖掘原始图像中的更多特征,在细节和整体两方面获取更加完整的图像信息.

表4 主流GAN实验结果Table 4 Results on mainstream GANs
在后续研究中,可以尝试更换基础网络结构,例如使用残差网络架构进行合作,或调整各个不同网络的结果权重,以增加判别器之间的差异.进一步提高网络架构整体的训练效率.
猜你喜欢
舰船科学技术(2022年11期)2022-07-15
煤气与热力(2022年2期)2022-03-09
北京航空航天大学学报(2021年4期)2021-11-24
汽车工程(2021年12期)2021-03-08
当代陕西(2019年16期)2019-09-25
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
福建基础教育研究(2019年3期)2019-05-28
西部资源(2018年1期)2018-11-01
软件(2017年6期)2017-09-23
中学生数理化·高三版(2016年9期)2016-05-14
