
CNN-XGBoost混合模型在音频场景分类中的应用
2021-02-04 13:51杨立东胡江涛张壮壮
小型微型计算机系统 2021年1期
杨立东,胡江涛,张壮壮
(内蒙古科技大学 信息工程学院,内蒙古 包头 014010)
1 引 言
随着机器“听、说、看”等能力的不断提升,人工智能开始了从感知智能向认知智能的迁移.目前,音频场景分类作为人工智能领域场景理解的研究热点也被广泛关注.音频场景分类就是通过算法模型将音频数据集分成记录环境声音的场景类别[1],是计算机听觉场景分析(Computational Auditory Scene Analysis,CASA)领域的主要研究内容,广泛应用于森林动物的监听设备[2]、机器人导航系统[3]、音频检索[4]和辅助设备[5]等方面.
近年来随着计算机性能的提高,深度学习技术在音频场景分类中表现出良好的性能,例如卷积神经网络(Convolutional Neural Networks,CNN)[6,7]、长短时记忆网络(Long Short Term Memory Network,LSTM)[8,9]和深度神经网络(Deep Neural Networks,DNN)[10]已经成功应用于音频场景分类,针对传统的机器学习算法在分类性能上难以提高的情况,许多研究人员开始利用深度学习算法和机器学习算法结合起来的混合模型改善分类性能.例如,利用CNN与LSTM混合算法提升音频分类正确率[11];文献[12]中通过引入i-vectors与卷积神经网络结合,同样在音频场景分类中取得了很好的效果;文献[13]中引入机器学习中的梯度向量机并与CNN结合产生并行结构模型,用它来处理音频场景的混合特征,实验结果显示在分类性能上有所提高;此外,还有在CNN的最后一层加上高斯混合模型的SuperVector作为概率线性判别分析分类器的特征向量[14],也可以提高分类性能.综上所述,机器学习与深度网络构造的混合模型在音频场景分类上应用越来越广泛,并提升了分类的精确率.
本文采用CNN与极端梯度提升算法(eXtreme Gradient Boosting,XGBoost)[15]相融合的算法模型解决音频场景分类问题.首先通过变换把预处理后的音频信号转换为梅尔声谱图,然后输入到卷积神经网络对其进行特征学习和提取,最后利用极端梯度提升算法完成分类.在该混合系统模型中,特征提取部分和分类器分别采用了不同的模型,从而提高了分类精确率.
2 基于CNN-XGBoost的混合模型
音频场景分类主要包括特征提取和分类器两部分,本文采用的混合模型基本算法流程如图1所示.

图1 基本算法流程图Fig.1 Basic algorithm flow chart
2.1 CNN
特征提取是音频场景分类中重要的环节,直接影响分类性能的好坏.CNN能够将一维的音频信号转换成二维的梅尔声谱图,再进行特征提取.CNN是一种高效的深度学习模型,具有层次结构,可以通过每一层对输入信号的学习获得高质量的特征.此外,CNN通过稀疏交互、参数共享等手段,利用空间局部相关性进行特征提取,可以减少模型的复杂度,提高运行速率.CNN网络的卷积核与输入进行卷积操作,设卷积核为K,偏置为b,在第l层通过激活函数输出如公式(1)所示:
Xl=f(Xl-1*Kl+bl)
(1)
其中f()为激活函数.
池化层通过降采样函数对特征图提取抽象特征,保持特征图的位移不变性,其定义如公式(2)所示:
Xl=f(down(Xl-1))
(2)
其中down()为采样函数.
经过卷积层和池化层操作后得到新的特征表达作为卷积神经网络的输出.为了避免模型复杂度过高,效率较低,分类精确率不高等问题,本实验采用浅层的神经网络模型,并且舍弃全连接层,避免特征位置信息的丢失,最后直接采用分类器模型进行分类.
2.2 XGBoost分类器
XGBoost属于Boosting算法,是一种基于梯度提升决策树的改进算法,主要通过把许多树模型集成在一起构成强分类器.Boosting算法有两个比较大的缺点:1)方差过高,容易产生过拟合;2)Boosting算法模型在构建过程中是串行的,不易在大数据场景中应用.而XGBoost算法有效地改善了上述两个问题.传统Boosting算法只是对一阶导数信息进行了运用,XGBoost算法则是通过对代价函数进行了二阶泰勒展开,能够提取一阶导数和二阶导数中的信息并运用,以及通过加入正则项降低模型的复杂度,从而防止模型过拟合.XGBoost提出了Boosting算法的多线程计算思路,能够提高CPU内核的利用率,使之很好地应用于大数据场景.
XGBoost的核心思想是对目标函数不断进行优化,设其目标函数定义如公式(3)所示:
(3)
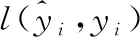
(4)

(5)
而XGBoost回归树的复杂度惩罚函数可以表示如公式(6)所示:
(6)
其中T为叶结点的个数,‖w‖为叶结点向量的模.γ表示节点切分的难度,λ表示L2正则化系数.由公式(6)将目标函数转换为公式(7):
(7)
通过求解最优的叶子节点分数w,将目标函数转换成一个关于叶子节点的一元二次函数,最优w如公式(8)所示:
(8)
计算出最优值如公式(9)所示:
(9)
最终将目标函数转换为公式(10):
(10)
本文使用XGBoost这种新兴的机器学习算法,相较于其他算法,其精度和运算速度都有明显的提升.
2.3 混合模型
CNN-XGBoost混合模型从宏观上看是由CNN特征提取网络和XGBoost分类器构成.CNN模型具有强大的特征学习能力,可以有效提取Mel声谱图特征参数.XGBoost模型的优势在于可解释性强,不易产生过拟合.充分结合两者的优点,本文采用CNN-XGBoost混合模型.系统模型如图2所示.

图2 CNN-XGBoost模型图Fig.2 CNN-XGBoost model diagram
本文设计CNN网络结构采用3个卷积层、2个池化层,在网络中的每个卷积层和激活函数之间添加批量归一化,并使用Dropout层,提高网络模型泛化能力.在模型训练阶段,将场景音频文件经过预处理得到的Mel声谱图作为CNN网络的输入,经过训练直至模型收敛,然后将学习到的特征参数输入到XGBoost分类器进行分类.
实验中采用基于python语言的Tensorflow-gpu深度学习框架进行训练与测试.卷积神经网络卷积层采用5×5的卷积核,步长为1,卷积层之后连接2×2的最大池化层,激活函数使用ReLU函数.每个卷积层的输出特征依次设置为64、128、256,最后与XGBoost分类器相连接.XGBoost树的最大深度为5,每棵树使用的样本百分比为0.8,构建的树的数量为280,使用L2正则化控制树模型的复杂度,学习率设置为0.1.为了提高网络模型的效率,采用小批量输入,大小设置为64.
3 实验与结果分析
3.1 语料库
本实验采用公开的城市音频数据集UrbanSound8k[16]和环境声音数据集ESC-50[17]进行训练和验证.UrbanSound8k数据集分为10个类别的场景,包含了空调(air_conditioner)、汽车喇叭(car_horn)、儿童游戏(children_playing)、狗叫(dog_bark)、钻孔(drilling)、发动机空转(engine_idling)、枪击(gun_shot)、手提钻(jackhammer)、警笛(siren)和街头音乐(street_music).每个场景的数据个数如图3所示,共8732个音频数据,被平均分配到10个文件夹中,每个音频信号的采样率为44.1kHz,存储为wav格式.ESC-50数据集包含2000个环境音频数据,共50类声音,每一类别有50个环境音数据,其采样率亦为44.1kHz.

图3 UrbanSound8k数据集分布图Fig.3 UrbanSound8k dataset distribution map
3.2 音频预处理
音频信号的预处理包含预加重、加窗和分帧等.通过高通滤波器实现预加重,其定义如公式(11)所示:
H(Z)=1-μZ-1
(11)
其中μ为预加重系数,实验中设置为0.97.
分帧可以得到音频信号的短时平稳的信号,选择Hamming 窗函数.预处理之后的信号通过短时傅里叶变换得到时频信号,表示为公式(12):
(12)
其中m为帧数,L为帧长,i表示第i帧.

图4 音频波形和梅尔声谱图Fig.4 Audio waveform and Mel spectrogram
将每一帧频域信号叠加起来得到声谱图,通过梅尔标度滤波器组将声谱图转换成梅尔声谱图,梅尔声谱图能体现音频信号的时频域信息和能量值,图4列举了数据集中室内空调声的波形图和梅尔声谱图.
3.3 实验结果及分析
实验参数如上述2.3节所述.交叉验证是一种验证分类器性能的统计分析方法[18-20],其基本思想是将数据集按照某种意义划分为几组,一部分用作训练集,另一部分用作测试集.本实验采用10折交叉验证,将音频信号划分为10组样本,选取其中9组样本用作训练集,1组样本用作测试集.重复10次交叉验证,确保每一组音频信号样本都能够遍历一次测试集,最后取10次测试结果的平均值.
本实验采取精确率Precision、召回率Recall和F1-Score值对模型进行综合评价.如公式(13)-公式(15)所示[21-23]:
(13)
(14)
(15)
式中,TP表示预测和实际分类正确的标签数量,FP表示预测标签中分类错误标签的数量,FN表示实际标签中分类错误标签的数量,如图5所示.
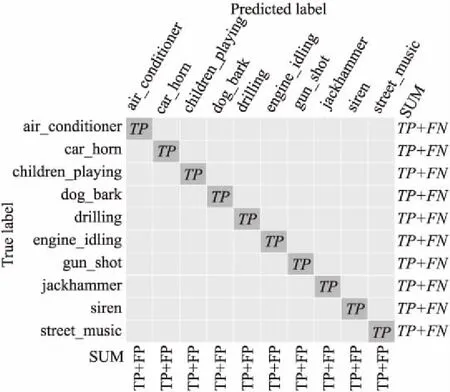
图5 TP、FP和FN含义及关系示意图Fig.5 TP,FP and FN meaning and relationship diagram
得到音频场景分类的精确率Precision、召回率Recall和F1-Score值的结果如表1所示,平均精确率为0.89,召回率平均值为0.87,F1-Score平均值为0.88.

表1 CNN-XGBoost 性能指标Table 1 CNN-XGBoost performance index
图6所示的混淆矩阵展示了每种音频场景分类的具体情况,可以看出有9%儿童玩耍的声音场景被误认为街头音乐场景,主要原因是在录制儿童玩耍的声音场景时伴随着音乐的声音,而在街头音乐场景收集过程中掺杂有人们嬉笑的声音,两类声学场景特征中有一定程度的相似性,容易产生误判,导致分类精确率降低;此外,手提钻声音场景也有一部分被识别为钻孔声音,这两类场景也存在一定的相似性,产生误判导致精确率降低.

图6 CNN-XGBoost音频场景分类混淆矩阵Fig.6 CNN-XGBoost audio scene classification confusion matrix
为了验证算法的有效性,在相同的音频数据集下将本文的算法与常用的CNN[24]、SB-CNN[25]、VGG[26]等算法进行比较,采用分类精确率作为衡量算法模型性能好坏的指标,采用CNN作为基线模型.对比结果如表2所示.

表2 模型对比1Table 2 Model comparison 1
为了进一步验证CNN-XGBoost混合模型的分类性能,我们选用公开的音频场景数据集ESC-50进行测试,测试结果如表3所示.从表3中可以得出,混合模型的分类性能明显优于单独模型的性能.
实验结果对比显示,本文中的CNN-XGBoost混合算法模型的精确率最高.该混合模型融合了深度学习算法和机器学习算法,充分利用其优点进行特征提取和分类,使算法模型性能达到了最优,精确率有了显著提高.

表3 模型对比2Table 3 Model comparison 2
4 结 论
针对音频场景分类正确率不高的问题,本文应用CNN-XGBoost混合模型,充分利用CNN可以提取具有显著区分度特征的优势以及XGBoost分类器中的树结构有很好的分类性能的特点,使混合模型的分类精确率达到了89%,实验结果证明优于传统的神经网络模型,从而验证了深度学习与机器学习算法模型相结合可以很好地适用于音频场景分类任务.
猜你喜欢
英语学习(2022年9期)2022-10-25
农业工程学报(2022年12期)2022-09-09
英语学习(2022年8期)2022-08-26
现代电子技术(2022年15期)2022-07-28
电子产品世界(2022年4期)2022-04-21
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
家庭影院技术(2021年1期)2021-03-19
计算机系统应用(2021年2期)2021-02-23
