
面向深度卷积网络的多目标神经演化算法
2021-02-05 03:26陈禹行胡海根刘一波郝鹏翼李小薪周乾伟
小型微型计算机系统 2021年1期
陈禹行,胡海根,刘一波,郝鹏翼,李小薪,周乾伟
(浙江工业大学 计算机科学与技术学院,杭州 310000)
1 引 言
最近几年人工智能技术在众多领域内都取得了令人瞩目的成就,尤其是在图像领域,卷积神经网络通过其强大的特征提取能力和权值共享机制不断刷新在图像分类,图像检测任务中的识别率.这使得越来越多的学者和工程师们都开始对基于卷积神经网络的工业应用产生了强烈的兴趣.以无线传感器网络为例,传统的无线传感器通常利用声音或震动传感器来检测并识别野外场景下的多个相邻目标,声音或震动传感器虽然具有如低成本,低能耗以及算法复杂度相对较低等有优点,然而在面对混合目标时则表现出分辨率不够这一严重不足,因此难以实现目标的精细分类.为了克服这一不足,可以在无线传感器网络中引入相机来加以辅助,这在当前已经证明对密集目标识别是一种有效的方式,因此如果能将卷积神经网络部署于无线传感器网络中并利用其来对低分辨率的图像信息加以处理,则可以有效的帮助解决密集目标的精细分类问题,从而推动无线传感器网络下野外多目标识别的进一步发展.然而为了确保卷积神经网络符合无线传感器网络的实际使用条件,模型本身必须服从许多限制条件,如模型的乘法次数必须能够满足无线传感器节点的运行要求,并且要保证模型在运行时有着良好的性能表现.但是现有的模型并不满足上述要求,所以如何有效构造出适用于无线传感器网络等特殊应用场景下的卷积网络模型已经成为领域内一个迫切需要解决的问题.
目前在面向无线传感器网络等特殊应用场景下开展的深度卷积神经网络构建工作相对较少,本文通过收集,调研了大量相关的研究资料得到如下结论.当前针对该问题主要存在以下两种解决方案:基于手工设计和基于随机优化.基于手工设计的思想是借鉴,吸收当前领先小型网络的结构设计方案,通过额外增加或改进现有的设计方案来获得符合要求的神经网络.大多数该方向的工作都会参考主流的残差网络(Residual Network[1]),稠密网络(Dense Network[2]),移动网络(Mobile Network[3])等包含跨层连接的残差结构,然后根据具体的工业限制条件再进一步统筹规划模型的各个组件成分.基于手工设计的方法能够直接,快速地设计出神经网络模型,然而其得到的模型往往需要消耗大量的时间,人力成本,此外这种方式还需要涉及大量模型的调参技巧且设计的模型结构过于单一.基于随机优化的核心是通过充分利用目前越来越廉价的计算资源,将模型结构的设计过程类比成自然界中物种的演化过程.拓扑和权重演化人工神经网络(Topology and Weight Evolving Artificial Neural Network[4])是其中最为广泛应用的方法,这种方式可以实现模型从无到有,从简到繁的演化.由于其首次构造的模型往往都是非常精简的,后续的演化过程中都将基于精简模型继续迭代优化,所以其构造的最优结构往往具有较小的网络规模.基于随机优化的方法能够自动地构造出模型,相比于基于手工设计的方法有着更大的潜力和发展空间.特别需要说明的是:目前相关文献[5-8]的工作都仅仅只考虑演化出单一条件下的卷积网络模型并没有考虑多约束条件下的情况,如何找到一种方法能够克服,规避现有遗传演化算法的弊端同时构造出特定应用场景下的深度卷积神经网络是未来所需要重点考虑的.
本文提出了一种面向深度卷积网络的多目标神经演化算法,该方法能够建立多约束条件下的神经演化与深度卷积模型结构自动探索过程的联系,可以快速,有效的找到符合给定约束条件下的卷积网络模型.本文的具体贡献如下:
1)将传统神经演化中基因编码翻译为卷积层的参数配置并引入线性规划方法进行求解,使得演化算法可以通过基因自动调整各个网络层的具体配置,从而保证演化生成卷积模型的可靠性和多样性.
2)提出了一种面向深度卷积网络的多目标神经演化算法,通过将深度卷积神经网络表达成有向图,使用基于增强拓扑的神经演化(Neuro-Evolution of Augmenting Topologies[9]),带精英策略的非支配排序遗传算法(Non-Dominated Sorting Genetic Algorithm-II[10])算法以及面向卷积神经网络的适应度评估函数实现了深度、计算量和识别率的同时优化.
本文第2节论述了相关工作;第3节论述了面向深度卷积神经网络的多目标神经演化算法;第4节进行了相关实验;最后总结全文.
2 相关工作
目前领域内对模型构造问题的解决方案更多选择的是基于随机优化的方法,该方法的核心内容是基于自然选择的神经演化算法.此外为了解决构造出适用于无线传感器网络的卷积神经网络问题还会涉及到多目标优化算法.本节接下来的内容将围绕上述两方面的已有工作进行详细阐述.
2.1 基于增强拓扑的神经演化算法
NEAT算法利用有向图表示神经网络,一个节点代表一个神经元,连接两个节点的有向边代表神经突触.它利用基因编码、基于历史标记的基因跟踪、新颖物种保持以及最小结构增长技术改善了TWEANN中存在的信息编码、物种竞争,多样性维持以及初始化种群等问题.该方法不仅可以提升传统神经演化算法的效率,而且找到的解具有更强的鲁棒性.文献[11,12]的研究工作则对上述工作进行了扩展,提出了基于Hyper-NEAT的方法(Hypercube-based Neuro-Evolution of Augmenting Topologies),这类方法通过引入额外的几何形状信息来改善传统拓扑过程节点连接中的权重分配模式,可以把大型人工神经网络的构造问题转换为高维空间的几何图形构造问题,然而如果转换后的节点在高维空间内过于分散则其效果会不尽如人意.
2.2 多目标优化算法
多目标优化算法在解决多优化问题中一直扮演着重要的角色.目前对多目标优化算法的研究方向可以分为以下3大类:基于支配的方法,基于指标的方法和基于分解的方法.基于支配的方法(Domination-Based method[13,14]的核心是通过数学上定义的支配原则(大部分采用的是 Pareto Domination)去评估不同解的适应度.此外为了保证解的多样性通常还需要设计多样性的保持方案.然而由于现实条件的限制,使用该方法解决具体问题时会面临一个问题:在多约束的条件下,种群中所有的解存在相互竞争关系,如果存在一种占据绝对优势的解,则其一定无法保证同时满足多约束条件.因此此类方法虽然使用了基于支配的原则求解问题但在实际情况中其最后找到的最优解是非支配的,这在一定程度上会降低种群在进化过程中的选择压力同时也会影响种群整体的进化进程.基于指标的方法(Indicator -Based method[15,16])是通过使用一些指定的性能指标(如超体积Hyper-volume)来评估解决方案在多目标演化算法中收敛和多样性上所做出的贡献,从而获得一个衡量解决方案表现的适应度值.然而这类方法的计算成本与选定的评估指标存在较大关联,根据不同选定的指标,其计算成本会随着目标数量的增加而呈指数增长.基于分解的方法(Decomposition-Based method[17-20])会将一般的多目标优化问题先分解为多个单目标优化子问题,然后使用演化算法在单个运行中同时求解所有子问题.这种方案能够充分利用多个子方案的适应度来综合评估整体解决方案的性能,具有更好的鲁棒性和更快的演化速度,然而如果相邻的解决方案在决策空间中相距遥远,则无法取得理想的效果.
综上,为了演化出适用于无线传感器等特定应用场景下的卷积神经网络,需要在传统的神经演化过程中添加额外的约束条件,如乘法次数,模型精度,模型深度等,然后使用多目标优化算法同时优化多目标下的神经演化,进而保证改进算法能够自动演化出符合相关约束条件下的网络模型.第3节将具体介绍本文提出的改进算法.
3 面向卷积神经网络的多目标演化算法
本节将从卷积神经网络的有向图表示,基于线性规划的基因翻译,多目标个体竞争方法以及算法流程来详细介绍提出的算法.
3.1 卷积神经网络的有向图表示
基于NEAT算法,本文采用有向图中的节点表示卷积神经网络中某一层神经网络输出的特征图,网络的起始节点代表输入图像,终止节点代表网络的输出,其他节点携带有表达特征图长宽及通道数量的尺寸信息.
对于入度大于1的节点,将有多个卷积层输出相同尺寸的特征图并汇总到该节点,该节点将根据它的第4个参数来确定采用按通道拼接或者按特征点加和这些特征图.
所以,在卷积神经网络的有向图表示中,一个有向图可以理解为种群中个体的染色体,其中的节点可以理解过为染色体中的基因片段,每个基因片段包含4个可调参数分别表示特征图的通道、长、宽以及特征图之间的融合方法.此外,有向边包含一个可优化参数,将用于下文的线性规划.本文中所涉及的图像均为正方形,故特征图也限定为正方形,以长、宽中较大者为边长.
3.2 基于线性规划的基因翻译
由于节点中只规定了特征图的尺寸,为求解出卷积层的必要参数,本文提出了一种基于线性规划的卷积层配置方法.
1)标准卷积(Standard Convolution).当输入特征图的长宽大于或等于输出特征图长宽时,采用标准卷积.式(1)给出了标准卷积函数在给定卷积参数条件下,如何根据输入边长计算对应的输出边长.

(1)
其中输入的特征图边长为Xin,输出的特征图边长为Y,卷积核参数k,卷积步伐d,卷积填充参数p.
为了求解式(1),与之对应的目标函数如式(2)所示.
F(k,d,p)=ra×k+(1-ra)×d+p
(2)
其中k,d,p的定义同式(1),ra是一个属于[0,1]的值,随有向线段进行遗传优化,在不等式(3)下通过线性规划算法最小化式(2)中即可求得对应的卷积层配置参数.
(3)
2)全卷积(Full Convolution).当输入特征图边长小于输出特征图边长时,采用全卷积.式(4)给出了全卷积函数在给定卷积参数条件下,如何根据输入边长计算对应的输出边长.
Y=(Xin-1)×d-2×p+k+a
(4)
其中输入的特征边长为Xin,输出的特征边长为Y,卷积核参数k,卷积步伐d,卷积填充p,卷积自适应填充a.
同上,为了求解式(4),与之对应的目标函数如式(5)所示.
F(k,d,p,a)=ra×k+(1-ra)×d+p+a
(5)
其中k,d,p,a的定义同式(4),ra是一个属于[0,1]的参数,随有向线段进行遗传优化,在不等式(6)下通过线性规划算法最小化式(5)中即可求得对应的卷积层配置参数.
(6)
3.3 多目标个体竞争方法
目前基于NEAT的神经演化算法仅采用个体的某一项指标作为适应度,难以满足工业应用中的应用需求.如要求设计一种计算量低,网络层次较深,且识别率较高的网络,直接应用已有的NEAT算法则难以实现.
本文提出了一种多目标个体竞争方法.演化过程中,适应度计算函数返回个体的多个指标,如对个体所表示的神经网络在计算量、深度、识别率等指标的评估,并使用NSGA-II算法求解基于帕瑞托支配和拥挤距离下的多目标优化问题,将求解出来的Pareto Front可行解用于种群中新个体的生成.图1展示了加入多目标优化规则的神经演化算法流程图,此外具体的算法流程如算法1所示.

图1 算法流程图Fig.1 Algorithm diagram
算法 1.面向深度卷积网络的多目标神经演化算法
输入:初始种群规模N,种群演化代数T,面向卷积神经网络的适应度函数Fitness(.),有向图演化算法A(.),多目标筛选函数M(.).
输出:最终的解集合{Solution}.
1.初始化规模为N的种群.
2.Fitness(.)评估初始种群.
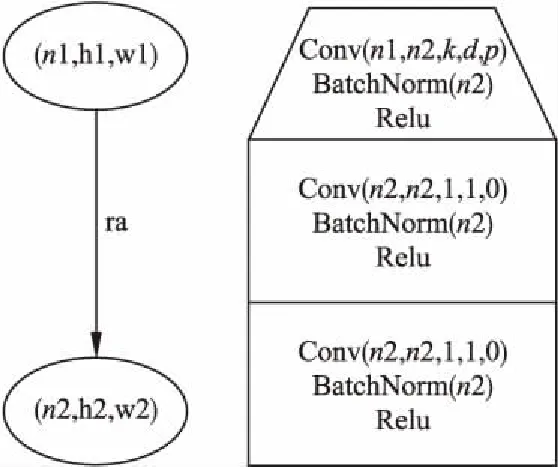
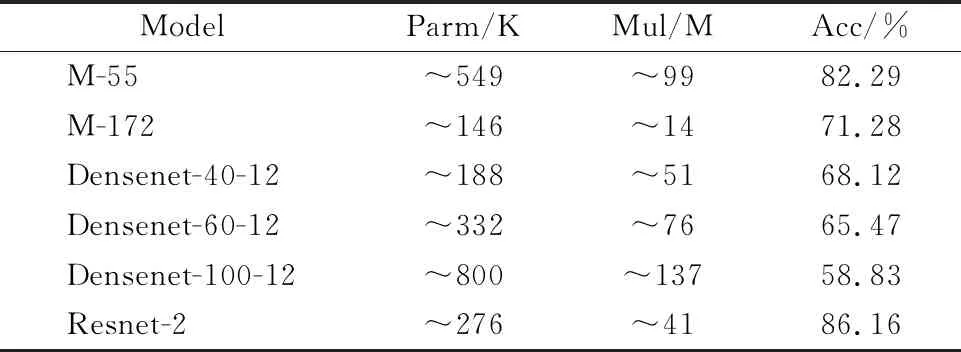
3.While t a.基于当前种群执行A(.)算法中物种多样性保护算法保留优秀个体. b.当前种群与上一代保留的2N/3个优秀个体合并成一个拥有5N/3个个体的临时群体,使用M(.)筛选并保留2N/3个优秀个体.(该步骤不作用于初始种群) c.在优秀个体中随机取出若干父代并使用M(.)确定优胜者用于生成一个子代. d.基于算法A(.)的遗传原则产生一个新个体. e.重复c和d直到产生N个新个体. 4.Fitness(.)评估新个体. 5.Return 最终的解集合{Solution}. 本节将详细描述本文提出算法的实施过程以及相应实验结果.通过实验框架,面向卷积神经网络的适应度函数,卷积模型演化以及相关实验结果模块化地介绍本文所做实验的各项准备工作,其中实验框架介绍本文使用到的各种仿真环境及相关配置参数,面向卷积神经网络的适应度函数介绍针对资源受限平台下的卷积神经网络演化而设计的适应度目标函数,卷积模型演化介绍本文算法的具体实施过程,相关实验结果介绍提出算法的成果和相关的性能分析,最后通过总结小节整体地概括本文所做出的贡献以及未来期望展开的工作. 本文实验选取的运行环境是Ubuntu16.04,使用了2张NVIDA GTX 1080Ti显卡来加快模型在演化阶段的探索速度.有向图算法A(.)采用的是基于JAVA语言实现的NEAT,在后续实验中该框架的大部分超参数配置与原始代码维持一致,不同的地方仅在于:本实验所设置的种群大小为50,物种更替的年龄阀值为50,存活下来种群的种群比例0.2,节点杂交概率0.25,节点突变概率0.5,优势基因个数10.此外本文中关于使用到的卷积模型中各个模块与基因节点的对应关系可以见表1,其中Sensor表示网络输入节点规定了输入图像的维度,Output表示网络输出节点规定了输出图像的维度,Hidden表示网络隐藏节点规定了特征图的维度,Link规定了节点间的连接关系,根据这些数据以及本文提供的线性规划方法可计算出卷积层的配置参数. 表1 卷积模型结构与基因节点的关系Table 1 Relationship between convolution model structure and gene nodes 本文在选择父代时采用的多目标筛选函数M(.)是基于Java实现的NSGA-II,其中与之相关的面向卷积神经网络演化的适应度函数将在4.2中进行详细阐述.采用Torch7框架(基于Lua言语实现)对演化构造出的卷积模型进行训练和测试评估.本文中有向边的基本单位如图2所示,图中左侧为有向边在图模型中的基本表示,右侧为有向边对应卷积结构下的基本单位其中涉及到的卷积参数k,d,p需要利用3.2中所提到的相关内容.其中n1和n2为输入输出特征图的通道数,h和 w 为特征图的长宽,本文中限定h=w.表2中的SGD-1给出了在演化过程中评估模型阶段SGD所采用的具体超参数配置. 图2 有向边的基本单位Fig.2 Basic unit of a directed edge 表2 SGD超参数Table 2 Hyper parameter of SGD 为了建立深度卷积神经网络,NEAT算法和NSGA-II算法三者之间的关系,需要使用特定的适应度函数来评估生成卷积模型的适应度并反馈给神经演化算法.传统演化算法选择的适应度函数:V=Max(Accuracy),通常仅仅只关注识别率指标,识别率高的种群个体其对应的适应度也相对较高.而为了演化出适用于无线传感器网络下的卷积模型上,仅仅使用识别率作为衡量指标是不足的,需要考虑诸如模型乘法次数,模型深度等额外评估指标. 本文使用的适应度函数建立在传统神经演化适应度函数的基础上,额外引入乘法次数,模型深度约束条件,让模型在进行适应度评估时更加综合考虑所有的约束条件.具体的适应度函数如式(7)下所示. (7) 其中Multiplication,Depth,Accuracy为演化模型中乘法次数,深度,识别率对应的适应度值,可以通过相关功能函数进行获取.具体来说,适应度函数将接收一个NEAT算法生成的有向图对象,解读有向图中的每个节点和有向边,使用节点和边上记录的4加1个参数构建深度卷积神经网络并将其翻译为Lua代码,调用Torch7框架在CIFAR-100的训练集训练该神经网络K次Epoch,最后把在CIFAR-100的测试集上的Top5精度则记录为模型的精度指标.神经网络的深度及一次预测所需的乘法次数则成为其余的两个指标. 提出的适应度函数将对演化过程生成的每个卷积模型从精度,乘法次数,深度3方面进行综合评估,并及时更新适应度值,进而保证种群在每一代演化过程中能够及时,准确地评估当前所有种群个体并结合多目标筛选函数M(.)从中不断发现表现最好的个体. 本节提出的适应度函数可以有效的衡量多约束条件下生成卷积模型的综合能力,引导神经演化算法产生各种各样不同的神经网络,这些神经网络可能在某一项评价指标下相对优异,同时又能保证网络的多样性.基于本节内容的具体实验过程将在4.3节中进行详细描述. 根据本文算法1所描述的流程,本节将分别从初始化种群和多目标卷积模型演化2方面进一步扩充相关实验的具体实施过程.本文后续所有模型评估实验选取的数据集是标准的CIFAR-100,演化代数T设置为50,初始种群规模为50,为了减少计算代价和加快模型演化的整体进程,此外为了对生成模型的性能进行快速初步评估本文在演化模型评估阶段的K统一设置为8.算法A(.)采用NEAT,算法M(.)为NSGA-II,Fitness(.)请参考4.2节. 通过执行4.3所述的实验流程,能够得到符合Pareto约束的解,然而由3.2中的内容可知其对应的解并不是单个,而是帕瑞托前沿(Pareto Front),它是由所有Pareto解所组成的超平面.本节将从Pareto约束展开,综合分析其在多目标函数下对模型演化产生可行解方案的影响以及不同约束条件下对应可行解的性能,接下来将从Pareto约束下的可行解和扩展验证实验2方面来进一步地介绍. 1)Pareto约束下的可行解.读取种群演化历史中所有的Pareto解决方案,使用Pareto支配对所有解决方案进行重排序,选择排序前100的解决方案作为参考指标并画出相对应的竞争关系图,同时保存对应排名下解决方案的基因和模型配置文件.本文选取了精度,乘法次数和深度3个目标函数来约束Pareto Front,理论上其对应的解是一个三维超平面,为了更好的理解两两不同约束之间的相互关系,选择将单个三维超平面转换成3张二维的Pareto关系图.特别值得注意的是,因为式(7)对原始的适应度值施加了一个重映射的操作,使得适应度值的输出范围属于[0,1],与之相对应的原始评估指标可以通过相关逆运算进行求解.图3表明了Pareto约束下精度和深度之间的关系,由于深度是离散的因此可以发现深度与精度之间呈现一种离散的关系,且随着深度的增加其相应的精度能够得到明显的提升,但是无法得到一个明确的数学关系式.图3中精度和有向图深度综合评估的最好适应度值分别为0.028,0.024,与之对应重映射前的原始指标分别为33.92%,40.图4给出Pareto约束下精度和乘法次数之间的关系,从中能够发现精度和乘法次数之间呈正相关,乘法次数越大其对应的精度也越高,由于本实验中对于乘法次数实施倒数操作,所以在图4的纵轴上其乘法次数越大则越接近于0.图4中乘法次数和精度综合评估的最好适应度值分别是0.410,0.075与之对应重映射前的乘法次数和模型精度分别为584M,11.84%.图5反映了Pareto约束下乘法次数和深度的关系,因为深度是离散的所以深度和乘法次数的关系依旧趋近离散,深度的增加会明显带动乘法次数的上升且深度越深提升倍数越大,但同样不能从中找到两者明确的对应关系式.图5乘法次数和有向图深度综合评估的最好适应度值为0.410,0.030,与之对应重映射前的指标是584M,32.综上,通过上述多张Pareto关系图可以发现在多约束条件下神经演化的新特性,从演化整体上来看由于综合考虑了多约束条件使得演化模型的性能变得更加均衡化,从不同约束条件的相互竞争角度来看其模型的性能与给定组合约束条件下有着特定的联系.如何进一步协调好多目标函数下整体约束和相互约束对模型演化的共同作用力,是未来基于多目标神经演化算法所重点需关注的内容. 图3 Pareto约束下精度与深度的关系Fig.3 Relationship of accuracy and depth under Pareto constraints图4 Pareto约束下精度和乘法次数的关系Fig.4 Relationship of accuracy andmultiplication times under Paretoconstraints图5 Pareto约束下深度和乘法次数的关系Fig.5 Relationship of depth andmultiplication times under Paretoconstraints 2)扩展验证实验.虽然在演化模型阶段对生成的模型存在相应的评估环节,但是由于训练代数相对较低,其测试结果依然无法准确判断生成模型的综合性能,为此本小节将对选取的Pareto Front解决方案进行3种不同的扩展验证实验.在所有后续扩展实验中,均选取标准的CIFIA-100数据集作为训练集和测试集,除了使用标准的颜色正则化方法外不添加额外的数据预处理,在该实验阶段训练的代数统一设置为120代,batch size设置为16,该阶段的所有模型将使用一套SGD超参数,具体的配置见表2中的SGD-2. 扩展实验1.从Pareto Front中选取前100个解决方案,对经过筛选的解决方案分别按照精度,模型深度,乘法次数3个指标进行排序,根据再排序获得精度最好和最差,深度最深最浅,乘法次数最少和乘法次数最多6种解决方案(包含卷积模型和基因配置文件).从筛选的结果发现最浅深度为2层,乘法次数最少为1.8M的模型并不符合无线传感器网络下的使用需求故不参与后续扩展实验.最终的实验结果如下,图6,图7,图8,图9分别展现了乘法次数最大,精度最低,精度最高,深度最大模型的误差曲线.由上述曲线可以得出不同约束条件下生成的模型是符合其限制条件,其中深度和乘法次数为指导的Pareto约束下生成的模型在精度指标上效果不佳,但可以发现深度对精度的影响要大于乘法次数带来的效果,这也侧面反映了深度在深度卷积模型中是获取高识别率性能的重要保障.此外,从精度指标上来看演化出的最优精度模型在CIFAR-100数据集上有着相当不错的性能表现其乘法次数和深度也比较符合适用条件. 图6 最大乘法次数模型的误差曲线Fig.6 Loss curve for the maximum multiplication model图7 最低精度模型的误差曲线Fig.7 Loss curve for the lowest accuracy model 图8 最高精度模型的误差曲线Fig.8 Loss curve for the highest accuracy model图9 最大深度模型的误差曲线Fig.9 Loss curve for the maximum depth model 扩展实验2.使用Pareto约束从Pareto Front中选取200个解决方案,进一步从200个解决方案中选取满足乘法次数少于100M和精度大于25%的模型,将找到的所有解决方案在CIFAR-100数据集上进行120次再训练,记录最终的稳定精度.表3展示了找到的9个不同解决方案的综合性能,其中Depth代表卷积模型在有向图中对应的深度,Mul代表模型的乘法次数,Oacc表示模型在演化阶段的识别率,Facc表示模型在经过精校后的识别率,Model代表在Pareto约束下经过排名以及筛选后所选取的模型.从模型识别率来看选取的模型都有着相当不错的表现,从深度或乘法次数上来看即使模型在某一项指标上相同却有着完全不同的性能表现,随着深度或乘法次数的增加模型的性能也有着明显的提升趋势,这侧面反映了本文提出的有向图演化算法的有效性和多样性. 扩展实验3.为了进一步衡量演化出模型结构与现有领先模型结构在性能上的差异,选取目前主流的Densenet,Resnet等业内领先模型与扩展实验2中的相关模型进行对比.Densenet实现的代码是论文作者在GitHub提供的官方版本(1)https://github.com/liuzhuang13/DenseNet,在控制成长率均为12的前提下分别选取了深度为40,60,100的3个模型版本.Resnet实现的代码是Facebook提供的官方版本(2)https://github.com/facebookarchive/fb.resnet.torch,选取了深度为20的模型版本.表4为现有模型与演化模型的对比分析,可以发现生成的模型其各项性能已经超越或接近现有的领先模型.特别值得说明的是,演化出的模型在没有利用基于残差的结构下却依旧能以极小的学习率实现有效,快速地收敛,证明了提出的算法在搜寻新颖,高效网络结构上的可行性. 表3 选取模型的综合性能Table 3 Comprehensive performance of selected models 表4 演化模型与现有模型在CIFAR-100上的性能对比Table 4 Performance comparison between evolutionary models and existing models on CIFAR-100 综上,尽管目前生成的精度最优模型的最小误差与残差网络,稠密网络等领先小型网络仍存在一定差距,但是本文方法最主要的目的是演化出可应用于无线传感器网络等特定应用场景下的卷积模型,从模型精度,深度和乘法次数3方面考虑本文演化出来的模型其综合指标已经符合特定工业场景下的使用条件,并且该方法能够自动化地构建出一系列各具特色的模型,极大减少了在设计特定模型时所面临的人力,物力上的成本. 本文提出了一种基于面向卷积神经网络的多目标神经演化算法,通过将深度神经网络表达成有向图,使用NEAT和NSGA-II算法实现了深度、计算量和识别率下的多目标同时优化,同时还创新性地引入了线性规划用于将基因编码翻译为卷积层可读的配置参数文件,使得演化算法可以自动调整各个网络层的具体配置.虽然目前演化出的精度最好模型与领域内领先的模型仍存在一定差距,考虑算法演化代数较少故存在巨大的提升空间,此外本文提出的方法不需要太多人为上的干预就能够自动构建出一系列各具特色的卷积模型结构且极大地降低了在设计特定模型时所面临人力,物力上的成本.我们相信本文提出的方法对于推动面向无线传感器网络的深度卷积网络的发展能够提供一种有效的解决方案.未来本文计划在此基础上继续深入研究多目标函数下和深度卷积网络模型构造的组合优化关系,进一步改善和提升模型结构的演化效果.4 实 验
4.1 实验框架


4.2 面向卷积神经网络的适应度函数
4.3 卷积模型演化
4.4 相关实验结果




5 结束语
猜你喜欢
计算机仿真(2022年8期)2022-09-28
农业工程学报(2022年12期)2022-09-09
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
商用汽车(2021年4期)2021-10-13
计算机系统应用(2021年9期)2021-10-11
作文周刊·小学一年级版(2021年36期)2021-01-14
阅读与作文(小学高年级版)(2020年8期)2020-09-12
当代旅游(2016年10期)2017-04-17
财经理论与实践(2015年2期)2015-04-16
