
基于双阶段网络的交互式目标分割算法
2021-02-05 03:03张华悦张顺利
计算机工程 2021年2期
张华悦,张顺利,张 利
(清华大学电子工程系,北京 100084)
0 概述
近年来,深度学习技术的发展使得目标分割在自动驾驶、图像分析等领域得到广泛应用与发展,但以往对分割任务的研究主要集中于自动语义分割[1-3]、实例分割[4-6]和全场景分割[7-8]等方面,而对交互式目标分割算法的研究较少。当人在一张图中通过某种交互方式标注出自己感兴趣的目标时,交互式目标分割可以有针对性地将此目标物体从原图中分割出,因此,其在现实中应用更加广泛,如利用交互式分割在深度学习中对图像数据的实例进行像素级标注、在手机端的图像娱乐软件中进行目标抠图以及将该方法应用于平面图像设计或医学图像领域[9]等。
在交互式分割中,可以将交互方式分为单轮交互和多轮交互2种。文献[10]中的多轮交互方法通过第一次交互标出目标的边界框得到初步的分割结果,然后每次交互时通过标出错分区域来对上一轮分割结果进行修正,直到结果满意为止。由于多轮交互过程复杂且具有低效性,因此本文主要研究单轮交互方式。在单轮交互中,只通过初始的一次交互直接得到分割结果。文献[11]中的GrabCut算法和文献[12]中的水平集算法均基于传统机器学习算法进行分割,文献[13]中基于深度学习的DEXTR算法采用四点交互法(标注目标的最上、最下、最左、最右边界点),在ROI中进行大目标分割。
基于ROI的交互方式可以较好地继承和利用传统图像分割算法并在构造交互数据集时更为便利,但其也存在一定不足,一是当目标物体具有细长支架的结构时,通过外接矩形框获取的ROI中仅含有占比极少的前景像素,使得网络难以判别前景信息,二是部分目标的4个边界点不清晰,一旦边界点标注错误就会造成分割结果截断。已有交互式分割方法利用FCN[1]和Deeplab系列[14-16]等经典图像分割方法,将ROI信息仅在输入端一次性地输入图像分割网络,这种直接的方法难以充分利用交互信息,使得分割结果较为粗糙,尤其是在多个物体之间紧密交叉重叠或目标连通性较差的情况下,其分割结果更加不完整。
本文采用在目标内部随机涂画的交互方式,利用骨架随机性仿真算法模拟大数据下的人机交互情景,构建一种基于双阶段网络的精目标分割模型ScribNet,以充分利用交互信息并对交互目标进行更精细和完整的分割。
1 交互方式
在四点交互法中,每个目标的4个端点是固定不变的,容易出现误标而导致误分的情况。相比而言,本文采用的涂画式交互允许人们在目标中涂画任意形状的曲线,其具有更好的容错性和鲁棒性,也正因如此,训练数据时对这种交互数据的仿真更为困难。针对该问题,本文提出一种骨架仿真算法以在大数据上实现仿真涂画式交互。
1.1 涂画式交互
在给定一张图像后,本文方法允许人在图像中的兴趣目标区域内涂画任意形状的曲线,不超出目标区域即可。涂画的曲线涉及更多的目标区域,将更能提高目标分割的完整性,例如对于图1所示(图中曲线表示交互曲线)的婴儿而言,本文自左到右的交互假设将越来越有益于分割。

图1 不同的涂画交互方式假设Fig.1 Hypothesis of different painting interaction modes
在网络学习阶段,交互曲线由骨架随机性仿真算法计算得到,该算法将在1.2节中进行详细阐述。在实际应用中,交互曲线则由人为交互涂画产生。在得到涂画的交互曲线P后,将曲线通过高斯编码形成交互指导信息图以用于后续分割算法。具体步骤为:
1)以曲线上的每个坐标点(x0,y0)∈P为中心,建立与原图等大的二维高斯分布图,每个坐标点处的g(x,y)值表示中心点(x0,y0)对周围像素(x,y)的影响程度,表达式如下:
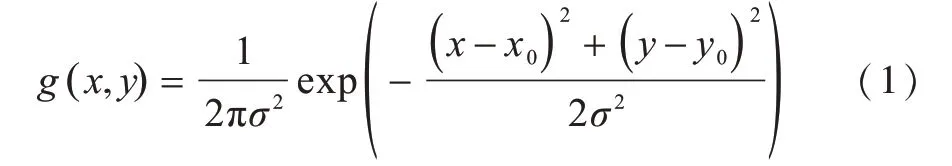
其中,方差σ2取经验值40。
2)针对曲线上所有点形成的高斯分布图,在每个像素位置取最大影响值,形成最终的交互信息图,将其记作I。
1.2 骨架随机性仿真算法
在深度学习的模型训练及验证过程中,人为标注的大量交互数据会消耗巨大的人力成本。本文对视频交互方法[17-18]进行改进,提出提高交互曲线随机性的骨架随机性仿真算法,并模拟实际情况中人的随机涂画交互行为,以在大数据上进行交互仿真。本文算法除在目标物体的骨架中求取最长路径外,还通过求取骨架中任意点到其他点最远距离的方法使得计算出的交互曲线具有多样性和随机性,以丰富训练数据集。骨架仿真算法的具体描述如算法1所示,图2中的白色曲线即为相应示例图的仿真结果。
算法1骨架随机性交互仿真算法


图2 骨架随机性仿真算法的仿真交互结果Fig.2 Simulation interaction results of skeleton randomness simulation algorithm
2 双阶段交互式分割网络
双阶段交互式分割网络由顺序级联的粗分割(粗预测)和优化(细预测)2个阶段组成,在2个阶段的输出端,均有损失函数进行显式监督,完整的网络结构如图3所示。

图3 双阶段交互式分割网络框架Fig.3 Two-stage interactive segmentation network framework
2.1 粗分割阶段
近年来,性能较优的自动分割网络大多呈现为编、解码结构,如SegNet[19]、U-Net[3]和Deeplab v3+[16]等。在该结构中,特征的上、下采样和跳跃式连接可以增大卷积核的感受野,并利用多尺度信息获得较好的分割结果。因此,在本文ScribNet模型的粗分割阶段,采用编、解码的网络结构,如图3中E(Encoder)和D(Decoder)模块所示。
在传统的分割任务中,网络采用三通道RGB数据作为输入,并实现自动的全图场景分割或特定类别实例分割。在以人为交互主体的交互式目标分割任务中,除通过RGB通道获取全图信息外,网络还利用交互指导信息图获取交互主体的分割意图,并将其作为第4个输入通道。本文采用高斯编码结果作为交互指导信息图I,形成网络的RGBI四通道输入数据。在输出端,得到一张像素级预测的目标前景概率图,通过Sigmoid和二值化操作得到像素级预测结果,如式(2)所示,其中,1表示预测为目标前景,0表示预测为目标背景。该结果为交互分割的粗分割结果,记作C,如图3中阶段1所示。由于辅助损失函数在此处进行了显式监督,使得粗分割结果可以正确预测大部分像素的类别。
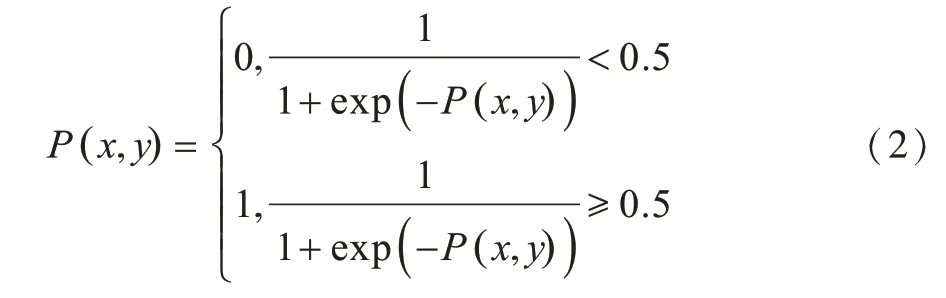
2.2 优化阶段
随着网络层的加深,在输入端输入的RGB信息和交互指导信息被逐渐地削弱,尤其是到了网络的输出端(也称为预测层)。因此,优化阶段将对第1阶段的粗分割结果进行细化,先将第1阶段输入端的RGB信息和交互信息I通过跳跃式连接的方式与粗分割结果C叠加在一起形成RGBIC五通道数据,输入优化阶段,再经过图3中的R(Refinement)模块输出最终的分割结果,即为优化分割或细预测结果,如图3中的阶段2所示。
ScribNet优化阶段对粗分割结果的细化具有有效性主要有以下3个原因:
1)从信息利用角度而言,网络的2个阶段均有RGB和交互信息作为输入,实现了对输入信息的充分利用,尤其是对底层信息起到了强化补充的作用。同时,优化阶段输入的第5个粗分割通道,可以看作目标分割的先验知识,其告知了网络目标前景、背景的主体大致区域,能够对交互目标实现更加准确的定位。
2)从网络学习角度而言,由于目标主体部位像素的分布已经在粗分割阶段学习完毕,因此在优化阶段中损失函数的构成主要来自错分的像素,包括被错分的边缘处像素和部分主体像素,使得优化阶段的网络可以针对性地对预测细节进行学习,起到对粗分割结果进行“查漏补缺”的作用。
3)从网络结构角度而言,由于优化仅需学习前一阶段的错分区域,网络任务明确,因此优化阶段的网络结构可以很简洁。此外,为了避免由于分辨率的变化造成细节信息丢失的问题,该网络结构中未采取任何升采样或降采样操作,完全由图像原始分辨率下的若干层卷积和非线性激活操作组成,如图4所示。
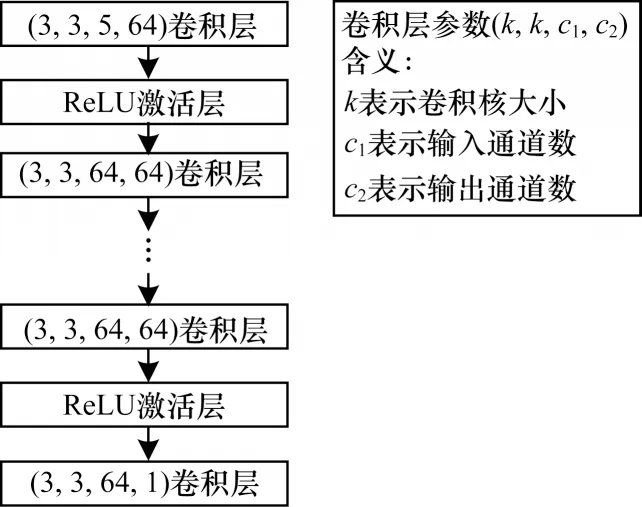
图4 优化阶段的R模块结构Fig.4 R module structure in optimization stage
2.3 算法性能分析
本文交互式目标分割算法采用骨架仿真算法模拟随机涂画式交互,具有标注成本低、交互容错率高的优势,同时采用双阶段网络实现精细化分割,使得分割结果具有更高的准确率和鲁棒性。
在对大数据进行交互时,四点式交互极易出现交互错误的现象,由于目标的4个端点固定且唯一,一旦交互标注错误就会对目标造成截断。而本文采用的骨架仿真算法在避免大量人力交互成本的同时,通过引入随机子路径使得仿真交互数据具有一定的随机性,即无论是在网络训练还是验证阶段,算法均可以对同一张目标图像仿真出多种不同的交互曲线,从而提高数据集的多样性以及模型在实际应用中对人为涂画交互的容错率。
本文算法采用双阶段网络结构,在粗分割阶段获得初始预测结果,初始预测中被错分的像素区域也有机会在优化阶段被纠正和优化,使得分割结果更加准确,尤其对于某些较难分割的情况,如图像彼此之间存在紧密重叠的目标或在交互中未被直接标注的目标区域,双阶段网络结构具有更高的鲁棒性。
3 实验结果与分析
3.1 实验数据与评价指标
本文双阶段交互式目标分割算法可以实现任意类别、不同实例的目标前背景分离,因此,分别利用COCO[20]和PASCAL[21](SBD[22]的扩展)数据集,构造本文实验所用的目标分割数据集。具体步骤为:首先,分别在原数据集的图像中提取每一个实例;然后,以任意大小、任意位置的矩形剪裁出该实例以形成新的图像和真值对。由于COCO和PASCAL数据集的一张图像中平均包含3个~5个实例,因此构造出的新数据集的规模也相应地比原始数据集大3倍~5倍,从而保证了数据的丰富性。需要说明的是,下文提到COCO和PASCAL数据集时,均指本文实验新构造出的交互式目标分割数据集。同时,为了进一步保证仿真交互的多样性,即一张图像可以有多种甚至无数种交互方式,本文实验没有提前一次性地为所有训练数据生成仿真交互图,而是在训练过程中实时地进行仿真交互,使得同一张图重复出现时其对应的交互结果不一样,符合现实中的交互分割逻辑。
在单类别前背景分割问题中,本文实验使用目标前景的mIoU(mean Intersection over Union)作为结果衡量指标,其具体计算方式如式(3)所示:
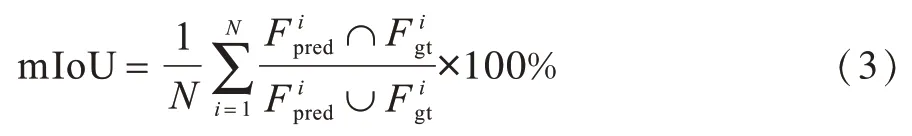
其中,N表示数据规模,F表示前景目标区域。
3.2 优化阶段的网络设计
双阶段级联的网络框架会因为网络层的增多而提高运算量。为了保证预测结果的精细化,避免由于特征分辨率的变化造成细节精度降低的问题,优化阶段的网络均由相同原始分辨率下的卷积和非线性激活层构成。为了在预测精度和运算量(优化阶段网络层数目)之间实现折中,本文进行优化阶段的网络设计实验。
当优化阶段的特征通道数为64、取不同数目的卷积激活层时,模型的预测精度和模型大小如表1所示。从表1可以看出:当卷积层数为0即仅有粗分割阶段而不添加优化阶段时,初始模型大小为237.36 MB;在优化阶段中增加少量卷积层,网络规模小幅增加;当网络层数为4时,预测精度的提升相对较大,模型规模仅增加0.31 MB,此时的双阶段网络结构在增加少许运算量的情况下取得了较大幅度的预测精度提升,说明了本文网络结构的合理性。
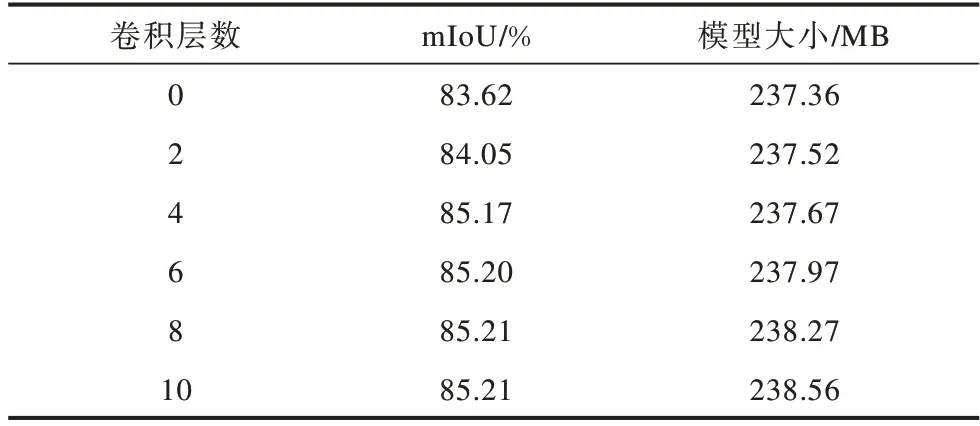
表1 优化阶段不同卷积层数下的模型大小和mIoU值Table 1 Model sizes and mIoU values under different convolution levels in optimization stage
3.3 双阶段网络的有效性实验
本文双阶段网络的目的是在交互式目标分割任务中实现更为精细的目标分割,网络由分割和优化2个阶段构成,在2个阶段的末端均有结果预测和真值监督。为体现ScribNet中优化阶段的有效性,本文分别将U-Net[3]、SegNet[19]和Deeplab[16]3个分割网络应用于ScribNet的第1个粗分割阶段,并分别记作U-ScribNet、Seg-ScribNet和Deep-ScribNet。在COCO和PASCAL数据集上进行预测,统计3个ScribNet模型在各自2个阶段中的预测mIoU值,结果如表2所示,同时,为了更直观地显示双阶段网络在提高目标边缘精度和分割完整性上的优势,通过图5呈现表2中Deep-ScribNet模型的部分可视化结果。
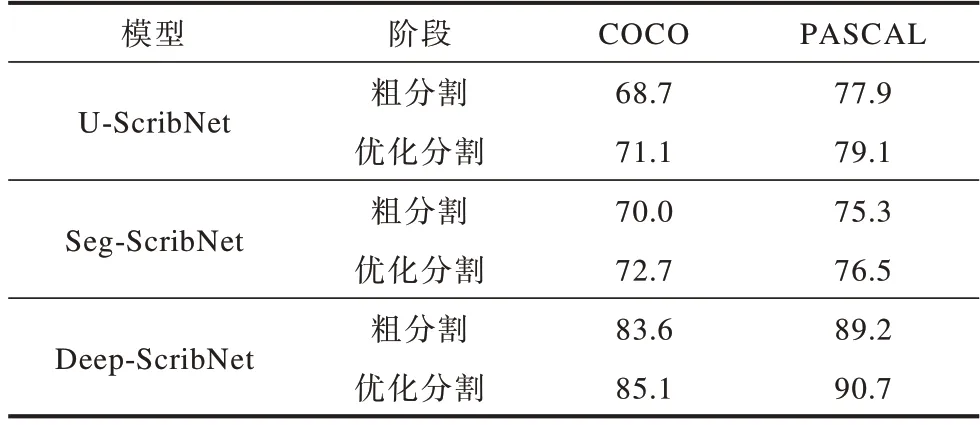
表2 ScribNet的粗分割和优化分割结果对比Table 2 Comparison of coarse segmentation and optimized segmentation results of ScribNet %

图5 不同阶段的分割结果对比Fig.5 Comparison of segmentation results in different stages
从表2可以看出,粗分割的预测结果精度较低,优化阶段是对初始预测结果的进一步细化,优化阶段的添加使得3个模型的预测精度均比粗分割提高了1个~3个百分点。通过图5中粗、细预测的对比结果可以看出,优化阶段的精细化主要体现在目标边缘的锐化、前景响应值的增强和背景响应值的抑制。在图中矩形框区域,粗分割会在某些背景处产生较高的响应值,这些错误响应在优化阶段中被有效抑制和纠正;相反地,在粗分割中响应较弱的目标主体在优化阶段也得到了加强,缓解了由于目标交叉造成的预测混淆问题。因此,双阶段网络的框架设计能够有效实现对图像的精细化分割。
3.4 不同方法对比实验
为体现涂画式交互方法在时间上的高效性,本文将DEXTR[13]与ScribNet进行比较,其中,DEXTR采用四端点式交互,ScribNet采用涂画式交互。实验分别从COCO和PASCAL验证集中随机抽取500张图像进行实际人工交互,统计平均交互时间,结果如表3所示。四端点式交互由于需要精准地找到4个顶点,平均每张图像需要消耗2.3 s的时间,而涂画式交互平均只消耗1.5 s时间,后者更为高效。2种方法的分割网络运行时间均只需要300 ms左右,可见,交互操作占据了整个交互式分割过程的大部分时间,交互效率的提高对整个系统的性能提升具有重要意义。

表3 不同交互方式的交互时间对比Table 3 Comparison of interaction time of different interaction modess
为了验证ScribNet中交互指导信息图及双阶段网络结构的有效性,本文将ScribNet与基于传统机器学习的交互式分割方法GrabCut[12]、基于深度学习的实例分割方法Deeplab v3+[16]以及DEXTR方法[13]进行比较,表4所示为COCO和PASCAL验证集上的分割mIoU结果对比。

表4 不同方法的分割精度对比Table 4 Comparison of segmentation accuracy of different methods %
从表4可以看出,Deeplab v3+为三通道输入的自动图像分割方法,ScribNet为四通道输入的交互式图像分割方法,后者相对前者在COCO和PASCAL数据集上的精度分别提升14.3个和7.1个百分点,输入的交互信息通道向网络提供了待分割目标的位置信息,从而大幅提高了预测精度。3种交互式分割方法相比,ScribNet在2个数据集上较GrabCut有显著的精度提升,在PASCAL和COCO数据集上的精度相比DEXTR分别提升了0.9个和3.0个百分点。
图6所示为上述算法的一组可视化结果,从图6可以看出,ScribNet在目标完整度、边缘精度以及对交叉目标的区分等方面均优于其他方法。

图6 不同方法的分割结果对比Fig.6 Comparison of segmentation results of different methods
4 结束语
本文针对交互式目标分割任务,提出一种基于双阶段网络的交互式目标分割方法。采用涂画式交互方式提高实际交互的鲁棒性和容错率,通过骨架仿真算法节省大数据交互标注的人力成本。将交互信息编码输入网络,实现交互信息的直接利用,添加优化模块构成双阶段网络结构,通过多次充分利用输入信息来提高分割结果的边缘精度和目标完整度。实验结果验证了该方法的高效性。后续将在网络的不同特征尺度阶段,通过多阶段监督学习等方式来充分利用交互信息,以进一步提高交互分割的精度。
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
科学与社会(2022年1期)2022-04-19
莫愁(2019年36期)2019-11-13
孩子(2019年3期)2019-03-12
孩子(2019年3期)2019-03-12
中学生数理化·八年级物理人教版(2017年11期)2017-04-18
中国艺术时空(2015年5期)2015-12-10
营销界(2015年22期)2015-02-28
