
基于改进ISOMAP算法的手写数据非线性结构分析
2021-02-10 06:53郭爱心
电脑与电信 2021年10期
郭爱心
(山西师范大学物理与信息工程学院,山西 太原 030006)
1 引言
随着信息技术的发展和海量数据的积累,数据处理与挖掘日益重要。而现实中的数据往往具有很高的维度,如手写数据、人脸数据和监控视频等,难以用现有的数据分析方法去处理,故需要对高维数据进行降维处理,分析其内在结构和特征。手写数据的非线性结构分析在手写数据识别[1]和手写签名认证[3]中扮演了重要角色。鉴于手写数据的高维非线性特征,应使用非线性降维算法进行降维分析。常用的非线性降维算法有等距特征映射算法[4](Isometric Feature Mapping,ISOMAP)、局部线性嵌入算法[5](Locally Linear Embedding,LLE)、拉普拉斯映射算法[6](Laplacian Eigenmaps,LE)和局部切空间排列算法[7](Local Tangent Space Alignment,LTSA)等。其中ISOMAP算法可以保留全局特征,广泛应用于图像处理、数据可视化和信号处理。然而,由于要计算最短距离和特征值分解,当数据量过大的时,ISOMAP算法的效率会降低。为了提高ISOMAP的可扩展性,Silva等提出了随机选择地标点的ISOMAP算法,即Landmark-ISOMAP(L-ISOMAP)算法[8],但随机选择地标点会导致算法性能不稳定。在此基础上,文献[9]基于最小子集覆盖进行地标点的选择,提出了Fast-ISOMAP算法,但地标点仍存在冗余。本文从地标点的选择出发,提出了改进ISOMAP算法(Improved ISOMAPBased on Landmark,IL-ISOMAP),并将其应用于手写数据的非线性结构分析。
2 ISOMAP算法
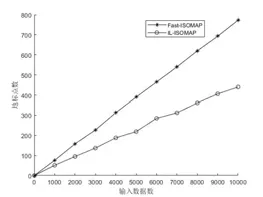
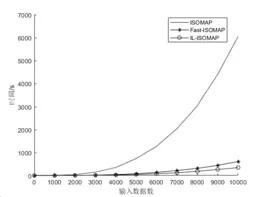
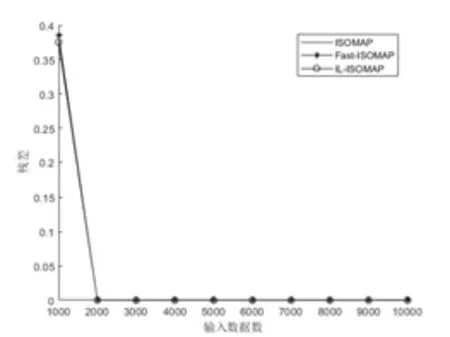
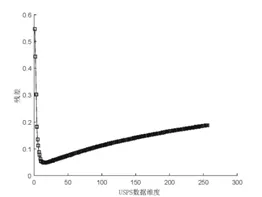
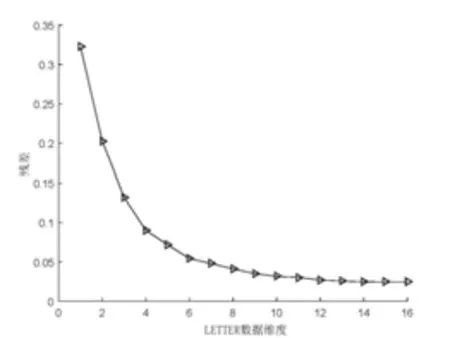
ISOMAP算法降维的实质是通过保持高维空间和低维空间的距离相似来保持数据的内在特征。设流形数据X={x1,x2,…,xn}⊂M⊂Rd,其中M为D维流形。设Y={y1,y2,…,yn}⊂Rd为d维欧几里得空间的嵌入结果,其中d< (1)通过k近邻或固定阈值的方法构建数据点的邻域图G,邻域图中的每条边的权重为d(xi,xj)。 (2)计算数据点之间的测地距离。对于近邻的数据点,点之间的欧氏距离即为测地距离,而对于互不为邻域数据点,可通过Dijkstras或Floyds算法计算数据点之间的最短路径进行近似,得出测地距离矩阵Dn,n。 (3)将多维尺度分析算法[10](Multidimensional Scaling,MDS)应用到测地距离矩阵Dn,n中,即可得到d维嵌入数据Y。 在ISOMAP算法中,其时间复杂度主要来源于最短路径的计算和特征值分解。若采用Floyds算法计算最短路径,其时间复杂度为O(n3),若采用Dijkstras算法为O(kn2logn),而MDS特征值分解的时间复杂度为O(n3)。当输入数据量n过大时,算法时间复杂度指数级增长,ISOMAP会出现计算瓶颈,故改进ISOMAP算法多从减少最短路径和特征值分解的计算量入手。本文提出了一种基于地标点选择的改进ISOMAP算法。 文献[11]指出流形局部线性区域的数据点或靠近该区域的点可以互相用其邻域内的点进行表示,因此邻域图中相连的数据点具有相似的测地距离。地标点的选择原则是尽可能用较少的地标点去表示输入数据较多的特征。基于此,本文提出了一种新的地标点选择策略,即选取互不相邻的数据点集合作为地标点。 设N={N1,N2,…,Nn}为邻域点的集合,其中Ni为xi邻域内的数据点的集合。设C=X={x1,x2,…,xn}为初始的地标点集合,如果xi是xj的近邻点(i≠j),则从集合N中移除xj,从集合C中移除xi,此时C中所有点的邻域都不包含xj,在输入数据X上执行该操作,可以得到互不为邻接点的地标点集合。该地标点选择策略伪码可以描述为: (1)C=X={x1,x2,…,xn} (2)N={N1,N2,…,Nn} (3)for i=x1:xn (4) for j=N1:Nn (5) if xi∩Nj非空 (6) 从N中删除xj (7) end (8)从C中删除xi (9)end (10)最终得到的C即为地标点集合 本文改进的ISOMAP算法包括地标点的选择、基于MDS的地标点d维嵌入,基于LMDS[8](Landmark MDS)的其余点d维嵌入,具体描述为: (1)构建邻域图G,根据2.1所提地标点选择策略选取地标点,设其个数为p。 (2)计算测地距离矩阵Dp,p和Dp,n。 (3)对于地标点,将MDS算法应用到测地距离矩阵Dp,p,构建地标点的d维嵌入;对于其余点,将LMDS算法应用到测地距离矩阵Dp,n,构建其余点的d维嵌入。最终得到数据X的d维嵌入Y。 为检验本文所提IL-ISOMAP算法的有效性,本文在Swiss Roll数据集上进行实验,从地标点的分布、数量、算法效率和准确性方面进行分析,并与具有代表性的Fast-ISOMAP算法[9]进行比较。 图1为当Swiss Roll数据集的数据点取2000,IL-ISOMAP和Fast-ISOMAP算法地标点(圆圈圈出的点)的分布,由图1可知,IL-ISOMAP算法选取的地标点数量更为稀疏分布更为均匀。 图1 地标点的分布 图2为不同数据点下IL-ISOMAP和Fast-ISOMAP算法地标点数量的比较,由图2可知,IL-ISOMAP算法的地标点数量要比Fast-ISOMAP算法少得多,且随输入数据的增长速度缓慢,这意味着IL-ISOMAP算法的效率比Fast-ISOMAP算法高,该结论也可从图3中得到验证。图3为ISOMAP、Fast-ISOMAP、IL-ISOMAP算法计算输入数据二维嵌入的时间,可以得出IL-ISOMAP算法的效率最高。 图2 不同算法地标点数比较 图3 不同算法计算时间比较 文献[4]指出用残差评价算法低维嵌入的质量,残差越小降维效果越好。图4为三种算法降维的残差曲线,由图4可知,三种算法的残差曲线基本重合,说明IL-ISOMAP在提高算法效率的同时没有牺牲太多的准确性。 图4 不同算法残差曲线比较 本文选取了MINIST、USPS和LETTER三个手写数据集进行非线性结构分析,探索其本征维度并进行三维聚类可视化。 三种手写数据集的简要介绍如下: (1)MINIST数据集包含60000张28×28的手写数字图片,手写数字包括0~9共10个类。 (2)USPS数据集包括9298张16×16的手写数字灰度图片,手写数字包括0~9共10个类。 (3)LETTER数据集包含20000个由16个属性描述的大写英文字母,手写字母包括A~Z共26个类。 数据降维应尽可能保持原高维数据的内在特征,故降维的维数至关重要,能够准确描述数据特征的最小维度称为数据的本征维度[11]。本征维度可以通过残差曲线的“拐点”对应的维度进行估计。图5、图6和图7分别为IL-ISOMAP算法对三个手写数据集降维的残差曲线,由图可估计出中MINIST中高维数据的本征维度为24,USPS中高维数据的本征维度为24,LETTER中高维数据的本征维度为5。 图5 MINIST数据残差曲线 图6 USPS数据残差曲线 图7 LETTER数据残差曲线 在手写数据识别相关的领域,由于手写数据集通常具有高维特征,使得直接分析这些数据非常困难,研究者可以将原始数据降维至其本征维度空间进行预处理。 可视化是分析数据内部结构的重要工具,本文将ILISOMAP算法应用于三个手写数据集进行可视化处理。在手写数据原始的高维空间,相同类的手写数据具有相似的表示,故在其低维嵌入空间,相同的类应聚集在一起。为了得到更好的可视化效果,本文选取部分类进行展示,如图8所示,可以得出IL-ISOMAP算法在降维的同时可以进行很好的聚类,保留高维数据的内在结构。 图8 手写数据集可视化 本文提出了一种互不为邻接点的地标点选择策略,在此基础上,改进了ISOMAP算法,并将改进算法IL-ISOMAP应用于手写数据的非线性结构分析中,探索出MINIST、USPS和LETTER三个手写数据集的本征维度和内在结构,这也为其他高维数据的分析和处理提供了有效参考。3 改进ISOMAP算法(IL-ISOMAP)
3.1 地标点的选择
3.2 算法描述
3.3 算法性能分析

4 手写数据的非线性结构分析
4.1 手写数据集
4.2 本征维度估计

4.3 聚类可视化

5 结语
猜你喜欢
数学杂志(2022年4期)2022-09-27
农业工程学报(2022年7期)2022-07-09
故事作文·低年级(2021年12期)2021-12-21
数学年刊A辑(中文版)(2021年3期)2021-11-05
作文成功之路·小学版(2020年7期)2020-08-24
数学物理学报(2020年1期)2020-04-21
测控技术(2018年4期)2018-11-25
电子制作(2018年18期)2018-11-14
自动化学报(2016年8期)2016-04-16
应用数学与计算数学学报(2014年3期)2014-09-26
