
基于多尺度特征模仿的无监督异常定位算法
2021-02-11 08:19叶颖,周越
中国体视学与图像分析 2021年4期
叶 颖,周 越
(上海交通大学 自动化系,上海 200240)
0 引言
异常检测是一些计算机视觉信息处理系统中潜在的重要任务,比如行为监控[1-2]、自动化制造过程检查[3-5]以及医学诊断和疾病监控[6]。异常检测任务的困难在于异常模式的稀少与未知,异常样本难以捕获。在这种情况下,很难获取足够的异常样本作为训练数据。相应的,一种无监督学习范式更适用于异常检测任务,即只使用正常样本训练模型和建立决策边界。
图像级异常检测包括:①基于重建的方法,比如使用自编码器[7]、变分自编码器[8]、生成对抗网络[9]、添加记忆力模块[10]等方法,通过对比重构图像和原始图像的差异判别异常图像数据;②基于分布的方法,构建正常数据的概率分布,判别低概率密度值的数据为异常,比如使用高斯混合模型的方法DAGMM[11]和ADGAN[12];③基于分类的方法,构建数据特征训练一分类器进行判别,比如一分类支撑向量机(OC-SVM)[13],利用深度网络特征的支撑向量数据描述(Deep-SVDD)[14],结合全监督分类任务训练一分类器[15]等。Patch SVDD[16]方法将SVDD扩展到基于图像块的异常定位任务。
对于像素级的异常检测,基于生成的方法利用生成模型,生成与输入图像最接近的图像,与输入图像进行像素级对比。比如Baur等[17]利用自编码器,对比重构图像和输入图像;Schlegl等[18]利用生成对抗网络,从隐空间寻找最接近输入图像的重构图像等。近期的一些工作结合类激活图进行图像异常分割,比如Venkataramanan等[19]提出结合变分自编码器和注意力方法(CAVGA);Salehi等[20]结合知识蒸馏模型和各种类激活图。许多方法利用高表达性的预训练网络构建正常数据模式分布。Bergmann等[21]将预训练网络知识迁移到图像块描述器,利用特征表征差异判别异常图像块;Defard等[22]将预训练网络的多中间层特征拼接作为数据特征描述,用高斯分布描述正常数据特征分布并用马氏距离度量异常程度;Cohen等[23]构建特征金字塔,并用k近邻聚类判别异常数据。
一些工作利用在大型自然图像数据集训练的特征网络。Bergmann等[21]提出一种基于教师-学生结构的异常检测框架。他们通过知识蒸馏过程将来自强大预训练网络的高表达性特征迁移到教师网络并将教师网络的特征作为学生网络的回归目标,然后将学生网络的表征误差和学生间的预测不确定性作为异常判别依据。为了得到像素级的判别,这个方法使用了局部重叠图像块特征嵌入,从而导致较低的推理效率。与该方法的图像块建模方式不同,本文采用特征图对比方法[24]。特征图由神经网络自然生成,因此,可以直接使用来自于整张输入图像的特征图进行判别。由于这个特性,本文方法不必训练图像块描述器,并且能通过一次前向推理获得像素级的异常判别分数图,极大地提高了推理效率。
本文提出一种中间特征回归和对比方法,将学生网络拆分成子块,每个子块的输出模仿教师网络相应位置的特征,子块的输入来自于前一层教师网络特征,这种结构有着更稳定的训练表现。另外,本文提出一种多尺度处理策略,除了保持使用多特征层学习外,同时结合了图像金字塔操作,即使用多种输入尺寸图像进行训练和测试。然而,经观察发现,对一个模型进行输入图像缩放训练会严重破坏模型性能。因此,本文将每个输入尺寸对应到不同的学生块群,纵向组成多层次学生网络结构。这种情况下,更多输入尺寸意味着计算开销的增加。因此,本文设计了一个辅助任务,对每个学生网络块设置一个权重,基于一个异常数据验证集利用梯度下降方式优化这些权重。这个过程和模型训练的主任务是相互独立的,因此,网络参数不会受到异常数据的影响。以这种方式能够实现更高效的多尺度处理。
1 本文方法
本文实现异常定位的基本方法为知识蒸馏式的特征回归和对比。正常样本输入教师和学生网络,学生网络的中间特征模仿教师网络的对应特征,那么就可以认为未在训练过程中出现的异常模式在学生网络的中间特征和在教师网络的中间特征差异比较大。我们用一种距离度量表示这个差异。因此,可以用学生网络特征和教师网络特征的距离来作为判别依据。本文提出的学生子块群结构避免了不同层的监督信息互相影响,使训练过程更稳定并且特征模仿的效果更好。另外,这种结构对本文使用的多尺度策略很灵活,能够减少计算负担,避免重新训练网络。本节将详细介绍网络结构、多尺度处理策略和模块权重搜索辅助任务。
1.1 教师-学生特征模仿框架
与其他工作所使用的教师-学生结构不同,本文设计了一种分离式的学生网络块群。整体的结构如图1所示。教师网络是一个完整的网络结构,其中间特征作为学生网络的学习目标。学生网络为互相分离的网络模块,每个模块与对应位置相连的教师网络的模块结构相同。教师网络的前一层特征通过这一模块,生成当前层学生特征。之后,基于当前层学生及教师特征之间的差距构建损失函数。按照知识蒸馏工作[25]的思路,本文使用多层中间特征进行指导和学习。一方面,神经网络中的不同隐藏层编码不同抽象层次的特征;另一方面,不同特征层具有不同层次的感受野,这一点对于推断具有不同面积占比的异常区域是非常重要的。
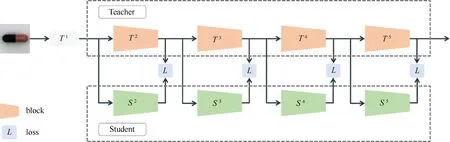
图1 教师-学生特征模仿网络结构
1.1.1 训练过程
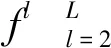
(1)
(2)
其中,p代表特征图的一个位置。标准化所有特征能使训练收敛更加稳定。对于多层次特征学习,整体损失为:
(3)
1.1.2 推理过程
对于异常定位,希望输入图像的每个像素点能预测一个分数,并且判别高分为异常。推理标准基本和训练标准一致。对于所有特征层,逐像素计算教师特征和学生特征的距离,以此得到该特征层的分数图。这里将所有分数图上采样到输入图像大小,并将所有分数图的平均作为最终的判别分数图。
(4)
(5)
(6)
所有特征位置的分数为标准化向量间距离的平方,取值范围为[0,4] 。将分数图乘上0.25的比例系数,使其取值限制在[0,1] 。
所有学生模块相互独立,因此可以任意拆解和组合不同的学生模块。这种结构能让我们在不需要重新训练模型的条件下搜索最优的学生模块组合,大大节省了模块搜索时间。同时,拆解了低效的学生模块,又能增加模型的推理效率,节省内存开销。因此,本文在该结构的基础上提出了一种灵活的多尺度处理策略和模块重要性搜索策略。
1.2 多尺度处理策略
在1.1节,提出一个教师-学生框架和多中间层学习方法。神经网络的不同中间层编码不同层次的特征,比如浅层编码细节或结构特征而深层编码语义级特征。特征层的多级感受野实现不同尺寸图像区域的信息归拢。特征金字塔的使用一定程度上能够满足多尺度检测的需求。尽管如此,这种固定的尺度设置对于众多检测物体类别和瑕疵类型并不能一一满足。因此,本文将图像金字塔结合进现有的框架中。
一种直观的处理方式是将输入图像设置成不同尺寸,输入同一网络进行训练和测试。这是一种在判别模型中广泛使用的数据增强方法。然而,这种方式并不适用于异常检测任务,因为输入数据的增强变换会加强模型的泛化能力,从而将定为正常样本的模式泛化到异常类别,而又无法明确定义异常类在模型中的表现,因此会破坏正常类与异常类的界线。本文通过对不同输入尺寸构建不同的模型来解决这个问题。每增加一个额外的输入尺度层,就增加一组学生模块群Si={Sl|l=2,3,…,L}到网络中。所有学生模块都是相互分离的,因此它们的中间表征不会互相干扰。教师网络是一个固定的预训练网络,可以被所有学生网络共享。整体的结构如图2所示。学生模块网络可以独立训练。所有图像尺度对应的学生模块群层级及层级内部的多层特征图计算得到的分数图均通过插值到一个基准尺寸,并通过取平均的方式得到最终的判别分数图。

图2 多尺度教师-学生网络结构和尺度权重搜索
1.3 尺度权重搜索
尽管所采用的多尺度处理方法能带来更好的性能表现,但添加的模型单元无疑会增加额外的计算开销。为了克服这个局限,本文给每个学生块分配一个权重,并设置了一个由异常图像及其标签组成的验证集,用该验证集的表现确定这些权重。确定每个学生模块的权重以后,我们视权重大小为学生模块的重要程度,对于低权重的模块,可以直接抛弃。
具体来说,本文使用梯度下降进行权重确定。每个学生块的分数图以加权形式组合。考虑到异常与位置无关,因此图像中所有像素点共享相同权重,也就有最终的分数图Φ为:
(7)
(8)
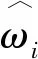
(9)
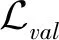
(10)
验证阶段优化模块权重,这一阶段与优化网参数的训练阶段是相互独立的。网络训练到一定程度后,固定所有学生网络模块的参数并将模块权重设为可学习模块并进行优化。模块权重确定以后,我们视高权重的模块更为重要,因此保留权重最高的k个模块,直接抛弃剩余的模块。因为学生模块是互相分离的,所以可以直接拆除模块而不需要重新训练。用这种方式,高效的模块得以保留,并以高权重的形式起到更大的作用。
2 实验
2.1 实验设置
2.1.1 实验细节
本文使用在ImageNet数据集以分类任务训练的预训练网络作为教师网络,学生网络随机初始化。使用4层特征层构建多层特征组合,比如ResNet[26]的conv2_x到conv5_x模块的输出,并且设置输入图像尺寸为[128, 256, 384] 来构建图像金字塔。模型使用SGD优化器,设置动量为0.9,学习率为0.5。批次大小设置为16,并进行600个周期的训练。
2.1.2 数据集和评价指标
本文使用MVTec[27]数据集进行实验。MVTec是一个工业检测数据集,包含超过5000张图像15种类别的工业产品。每一种类别都包含正常样本用于训练,异常样本用于测试。这种设置直接符合无监督异常检测的形式并且每个类别单独进行训练和测试。
实验使用阈值无关的评价指标,受试者工作特征指标(receiver operator characteristic, ROC),并计算其曲线下面积(AUROC)作为数值指标。另外,本文使用另一评价指标,区域重叠率(per-region overlap, PRO),该指标均等考虑所有连通区域的预测正确率。同样,计算其相对假阳率(false positive rate, FPR)曲线下面积(AUPRO)作为数值指标。这里计算假阳率从0%到达30%的曲线面积,并作归一化。
2.2 实验结果
特征模仿网络与同时期的几个方法进行了对比。这里选取教师网络结构为WideResNet-50,使用图像金字塔多尺度策略的实验结果。为了公平起见,不将进行模块权重搜索的实验结果在这里对比,因为模块权重搜索任务用到了一部分数据作为验证集,其测试集与其他方法不完全一致。对比方法数据均来源于原始文献。实验结果如表1所示,本文方法在性能上优于其他方法。

表1 不同方法性能对比
判别特征图的可视化效果如图3所示,可以看出对于多种类别的物体和不同类型与大小的异常区域,本文方法都能有较好的检测效果。
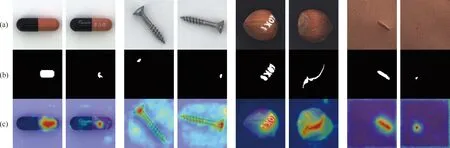
图3 多尺度特征模仿异常定位效果(a)原图;(b)标签;(c)预测概率图
2.3 消融性实验
2.3.1 骨干网络结构及特征层级组合
本节在不同骨干网络结构和特征层组合上进行实验,输入图像尺寸固定为256。ResNet-18, ResNet-50和WideResNet-50及每个结构对应使用前三层特征层和全部四层特征层的实验结果如表2所示。实验结果表明,更大的模型如WideResNet-50效果优于较小的模型。大模型生成更具有判别性的特征,对于区分学习过的数据和未学习过的数据效果更好。对于不同特征层组合的实验结果,本文发现在所有基础结构上,前三层特征组合效果都优于全部四层特征组合。结合最深的一层特征效果下降,一方面因为分辨率过小,直接进行上采样导致结果不准确;另一方面因为过于抽象的语义级特征更偏向预训练网络的分类任务。
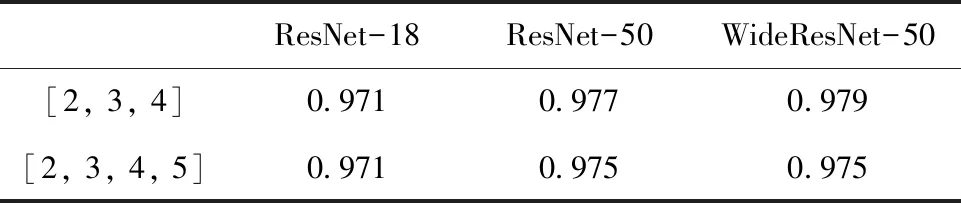
表2 不同网络结构和特征层级组合实验对比(AUROC)
2.3.2 多尺度处理
为了验证所使用多尺度策略的有效性,这里报告了单输入分辨率和多输入分辨率下的每个物体类别的实验结果,使用ResNet-50作为基础模型。输入尺寸设置为128、256和384,实验结果如表3所示。从这些数据可知,每种物体类别生成最适宜判别特征的所需感受野是不一样的。对于存在全局尺度异常区域的物体类别,比如晶体管,小输入尺寸更为适宜。相反,对于存在微小异常区域的物体类别,更大的输入尺寸效果更好。为了适应一般类别的多样性异常检测,使用多种输入尺寸组合是更为有效的。

表3 不同输入尺寸模型性能对比(AUROC)
2.3.3 模块权重搜索策略
为了进一步验证基于验证集的模块权重搜索策略的有效性,在此以MVTec数据集提供的异常数据类别作为先验,进行验证集选取方法与权重搜索策略效果关系的实验。这里验证集的选取按照覆盖异常数据类别的百分比(类别覆盖率)进行划分,近似表示验证集和测试集的分布相似性。从每个被选取的测试集异常类别中抽取10%的数据构建验证集,并计算不同异常类别覆盖率下的测试精度。实验结果如表4所示,0%代表不进行权重搜索。从表4中可知,验证集上的模型精度随着异常类别覆盖率的增加而减少。这是因为异常种类的增加提升了模型的学习难度。相反,测试集上的模型精度随着异常类别覆盖率的增加而提高。当测试集与验证集的分布一致时(100%),模型达到最高精度。该现象说明了异常类别覆盖率的提升能够有效克服模型的过拟合问题,提升模型在测试集上的精度。

表4 不同验证集异常类别覆盖率的模型性能对比(AUROC)
表5所示对学生模块分配权重的效果表现以及保留最大k对应模块的模型精度。从表5中可知,进行权重分配能有效提高模型效果。测试k取值为4、5、6的实验结果,其中k取值为6时精度最高。而从整体来看,保留权重最高的k个模块效果优于基础模型,说明经过权重分配,并拆除低重要性模块,不仅能使网络更为精简,也能一定程度提高网络的精度表现。

表5 权重搜索及模块保留模型性能(AUROC)
3 总结
本文提出了一种基于教师-学生网络的多尺度特征模仿异常定位方法。学生网络被设计成分离式的学生模块群,每个模块各自训练和推理,并以此结合特征金字塔和图像金字塔,进行多尺度、多抽象层次的异常判别推理。另外,提出了一种基于梯度下降方式优化的模块重要性权重分配策略,不仅实现优化网络结构,又能进一步提高网络的表现性能。实验结果表明,本文方法对比同类型方法有更好的性能表现,并能有效地实现各种类别物体、不同大小异常类型的定位检测。
猜你喜欢
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
当代陕西(2020年17期)2020-10-28
疯狂英语·新策略(2019年10期)2019-12-13
当代陕西(2019年10期)2019-06-03
人大建设(2018年5期)2018-08-16
数学小灵通·3-4年级(2017年9期)2017-10-13
电信科学(2017年6期)2017-07-01
太空探索(2016年5期)2016-07-12
时代英语·高三(2014年5期)2014-08-26
河南科技(2014年23期)2014-02-27
