
基于多视图的半监督集成学习方法*
2021-02-25 06:27张振良刘君强
计算机与数字工程 2021年1期
张振良 刘君强 黄 亮 张 曦
(1.鄂尔多斯应用技术学院 鄂尔多斯 017000)(2.南京航空航天大学民航学院 南京 211100)
1 引言
在机器学习和数据挖掘应用程序中,我们寻找很多方法来提高分类器的性能。集成学习是一种机器学习方法,最初,集成学习的提出是由于Schapire 证明了多个弱分类器可以形成一个强分类器,所谓的弱分类器是指分类效果很差的模型,集成学习的目的是通过组合多个分类器的输出来构造多个不同的分类器[1]。所谓“集成”是专家的混合体,用以防止过度拟合以及减少所有基础学习器的误差,而如何结合多种学习器的输出结果和提高基分类器的多样性来提高分类器的精度是重点[2]。
集成分类器的关键是根据所有基分类器的预测来量化未标记样本的置信度,而精度也随分类器的数量增加而增加,而且对所有的训练集以及算法没有要求,避免了大量交叉验证[3]。
现有的算法大多只使用标记数据来构造分类器,而且在很多情况下,标记数据的数量通常不足以训练出鲁棒性很强的分类器,同时大多数情况下,标签数据的获取成本很高,而未标记的数据则很容易获得而且数量更多。基于这个原因,半监督学习获得了越来越多的关注,它致力于从未标记样本中获得信息,寻找大量的未标记数据中的规律,再利用少部分已标记数据的信息,做出预测。大多数现有的SSL(Semi-supervised learning)技术主要是在未标记数据的信息获取方式上加以区别。
将半监督学习方法引入到集成学习中,邬[4]提出三重训练的思想,训练生成三个分类器,而且无需满足苛刻的独立条件,然后使用其他两个分类器同意的未标记数据对另一个分类器进行改进,由于未标记数据的分类误差估计比较困难,因此,在未标记数据与标记数据具有相同分布的前提下,仅对标记数据进行分类误差计算。三次训练过程的学习一直持续到误差停止减小为止,这意味着已经达到了最大的泛化效果。在一定的理论证明限制下,将一致的未标记样本逐步加入到标记数据中,用于细化相应的分类器,直到没有一个分类器的预测误差进一步减小,一旦学习过程完成,就可以用两个或多个成员分类器一致同意的标签来预测未标记或看不见的数据[5]。三重训练方法很有吸引力,因为它在原始的共同训练方法中成功地解除了对两个条件独立视图的要求,而没有经历过实践中提出的耗时的交叉验证过程。
王立国[6]提出改进的三重训练算法,先选取信息量最大的未标记样本,利用差分进化算法产生新样本,再利用这些新样本继续迭代[2]。杨印卫、王国锋[1]选取了支持向量机(SVM)、隐马尔科夫模型(HMM)以及径向基神经网络(RBF)这三个单分类器作为异构集成学习模型的基分类器,同时采用了majority voting和stacking两种集成结果整合策略来选择最优组合,证明异构集成学习模型的泛化能力相比于以往单分类模型得到了改善,同时模型复杂度降低。傅向华、冯博琴[7]等提出一种异构神经网络集成协同构造算法,利用进化规划同时进化网络拓扑结构和连接权值,连续学习生成多个异构最优网络,然后对异构网络进行组合。在构造神经网络集成的过程中通过协同合作,保持各网络间的负相关,从而在提高成员网络精度的同时增加各成员网络之间的差异度。
这些算法的优点在于不要求用于分类的属性由多个独立视图描述,从而大大扩展了基于共同训练的半监督学习的适用性。但是,这些算法的一个潜在弱点是,因为初始分类器是由Boosting 算法进行自举采样,基分类器差异性被样本多样性局限,算法的成功在很大程度上取决于原始集合分类的多样性
本文将从采用多个视图以及不同的特征降维方法和学习模型来创建更加多样化的基学习器,未标记的数据通过集合成员的简单多数表决来预测,而不是复杂测量方法,以期有效地提高以最小的开销成本预测未标记样本的标记的准确性,其次所提出的方法预测具有特定标签的数据的概率,然后可以使用该方法选择最可靠的预测的未标记数据以添加到标记数据。相比之下,其他算法随机选择池中的一定数量的未标记数据用以训练。鉴于这些属性,基于多视图的半监督集成学习算法能够可靠地应用于各种分类问题。
2 相关工作
2.1 多视图方法(Multi-View,MV)
所谓视图其实就是特征集,在具体的分类过程中,由于训练集可能有着多种多样的特征属性,如果全部输入到网络中进行学习不但数据庞大难以学习,而且特征之间也无主次,影响精度。我们以垃圾邮件的分类为例[8],在诸如公共垃圾邮件数据集之类的研究中,如主题长度,信息大小,附件大小和图片数量等特征都在分类垃圾电子邮件时有所帮助。基于以上特点,本文总结了上述14 个特征如表1 所示,并且采用两个视图也就是数据集来表示电子邮件。这种特殊的数据构建方法使我们的工作与大多数现有工作不同。在实际部署中,我们确定可以通过当前的电子邮件技术(即路线跟踪和内容记录)轻松捕获和计算上述特征。

表1 视图示例
为了更好地描述本文方法,使用ɑ 和b 表示两个视图的所有特征,已标记样本用(<ɑ,b>,c)表示,其中 ɑ∈ A 和 b∈ B 是示例的两个部分,c 是标签,0表示负类,1 表示正类。假设在A 和B 上有两个函数f1和f2,使得f1(ɑ)=f2(b)=c。这意味着每个标签都与两个视图相关联,其中每个视图都包含足够的信息来确定示例的标签。因此,如果给出k 个例子,可以给出具有标记的数据集 L:(<ɑk,bk>,ck)(k=1,2,…,ck是已知的)。设 U=(<ɑi,bi>,ci)(i=1,2,…,ci未知)表示大量未标记数据,我们的任务是训练一个分类器来分类新的例子。
2.2 多特征降维方法(Multi-Feature)
由上可知,采用多个视图描述两组特征,但为了构建用于解决分类问题的可靠模型,期望特征应包含尽可能多的有用信息,并且特征的数量尽可能小[9]。但是,由于关于数据集的先验知识通常很少,因此难以区分哪些特征是相关的哪些特征不相关。因此,通常需要考虑大量功能,包括许多不相关和冗余的功能。不幸的是,不相关和冗余的特征不仅会降低学习效率,而且会对因此训练的机器学习的性能产生负面影响,从优化的角度而言,特征选择是一个组合优化问题。首先,由于特征子集的大小不是先验已知的,因此决策空间的维度是不可简化的。其次,因为功能可能彼此之间具有互补或相互矛盾的相互作用,决策空间是不可分离的。因此,给定m 维特征集,所有可能的特征子集的数量都大到2m,这使得用传统的穷举搜索方法解决它的可能性很小[10]。
现有的特征降维方法有独立成分分析(ICA)、主成分分析法(PCA)、粒子群优化算法(PSO)以及竞争群优化算法(CSO)等。ICA的基本思想即在线性变换的基础上,使用训练样本找到一组相互独立的投影轴,利用其独立成份作为样本数据。PCA利用去除了样本二阶统计意义的相关性信息,ICA则利用去基于训练样本的二阶统计信息。使样本的各阶统计意义下的信息都得到了充分利用。PCA 基于训练样本的二阶统计信息,因而其忽视了高阶统计意义下的信息。在PSO中,每个粒子在n 维搜索空间中保持位置和速度,表示候选解决方案和可能更好的解决方案的方向。为了搜索全局最优的位置,每个粒子按公式迭代更新,但当优化问题具有高维度和复杂的搜索空间时,其性能仍然有限,为了提高PSO 的性能,已经提出了许多PSO变体,包括基于参数自适应的变体,基于结构的拓扑变体等。在CSO中[11],粒子从随机选择的竞争者中学习,而不是从全球或个人最佳位置学习。在每次迭代中,将群体随机分成两组,并在每组的粒子之间进行成对竞争。在每次比赛之后,获胜者粒子将直接传递到下一次迭代,而输家粒子将通过从获胜者粒子中学习来更新其位置和速度。
3 基于多视图的半监督集成学习方法
3.1 基于多视图的未标记样本筛选
半监督学习算法的关键步骤是估计标签置信度,以选择适当的未标记样本进行标记。这对于普通的分类而言很简单,只需要随机选择未标记样本即可,但由于有着大量的未标记样本,有些未标记样本可能对于学习没有帮助甚至会起到反作用,所以对未标记样本的筛选是很有必要的,很多文献[12]忽略了这一点。
为了解决这个问题,通过评估未标记样本的标记对现有标记数据的影响来估计标记置信度是可行的,但是基于假设标记数据上的回归量的误差应该减少最多,如果使用最可信的未标记样品在每次迭代中重复评估模型将导致高计算复杂性。基于这些原因,提出了一种基于分歧的筛选算法。借用Tri-Training[13]的想法,使用基于三个视图训练的三个回归量来确定如何选择合适的未标记样品进行标记。对于任何回归量,我们通过利用其他两个回归量的均匀性来估计标记置信度。如果其他两个回归量的估计值之间的差异较小,则未标记的样本获得较高的标记置信度。使用此方案,不再需要评估模型。在每次迭代中,我们选择具有最小估计差异的未标记样本以扩展标记数据。
然而,仅考虑估计差异将导致所选未标记样本的分布偏差。原因是较小的估计差异倾向于有利于具有较低估计值的未标记样本。例如,如果样本A 和 B 的估计变量值约为 30 和 300,则样本 A 更容易获得较小的估计差异。这个问题会导致模型倾向于仅从样本空间的一部分学习知识,从而降低模型的泛化。为了缓解这个问题,在每次迭代中,我们按照它们的估计值对未标记的样本进行排序,并将它们分成几个具有相同数量的未标记样本的区间,然后分别为每个区域选择未标记的样本。
在学习步骤中,它应用学习模型根据当前标记数据从三个视图重新训练学习模型,并且用以对未标记样本U1预测,在选择步骤中,对于每个视图,它首先通过使用式(1)计算估计差异Δy,其次,它根据候选样本集进行排序估计并将其分成具有相同数量样本的β部分。最后,它分别选择每个部分中具有最小估计差异的α%样本筛选出来得到U用以下面的算法。

3.2 构造基学习器
构造差异性更好的基学习器是我们的目的,从而促进半监督以及集成学习的泛化性能。值得一提的是,为了尽可能独立地创建视图,模型应尽可能地不同。例如,线性判别分析(LDA)和线性支持向量机(LSVM)都具有线性超平面,因此,它们创建的“模型”不太独立。相比之下,LDA 和k-近邻(kNN)更可能会创建不同的视图,因为KNN具有与LDA 不同的离散超平面。假如我们根据特征的多少我们构建了两种视图,选取了独立成分分析(ICA)、主成分分析法(PCA)、粒子群优化算法(PSO)以及竞争群优化算法(CSO)四种特征降维方法,模型上采用朴素贝叶斯分类器(NB)、J48 决策树(J48)以及KNN(k=5)3 种模型。则我们可以提供2*4*3=24 种不同的训练方式,再通过重抽样方法提高训练集的多样性,提供具有稳定差异性的基分类器。
通过上述步骤,可以生成大量的基分类器。但由于基分类器的数量可能很大,所以其他所有分类器都不太可能就未标记数据达成一致。该问题的解决方案是引入投票机制来预测标签,与给出确定性标签的三训练算法不同,所提出的方法预测具有特定标签的数据的概率。然后可以使用该概率来选择最合适的未标记样本。这不会增加太多计算复杂度,因为基于来自每个基础分类器的置信度输出而不是如在共同学习算法中使用交叉验证来计算置信水平。
3.3 基学习器集成算法步骤
首先定义已标记样本L 及筛选后的未标记样本集U,重抽样算法[14]B(x),排序函数S
1)根据上述方法构造24 种学习模型P=<V,F(x),H(x)> ,其中 V 为视图,F 为特征降维方法,H 为基本模型,同时对L 进行重抽样,依照重抽样后的样本以及学习模型训练24 种基分类器hi=P<B(L)>,其中B为重抽样算法。
2)使用第i个分类器hi预测未标记样本xk,得到其分类结果hi(xk)=yi,同时使用其余23 个分类器进行预测得到分类结果hj(xk)=yj,(j≠i,i,j=1,2,…,24),若有ni个预测结果与hi预测结果相同,则得到xk在置信度为
相比于其他算法,本算法优点有:
1)通过增加多视图以及特征降维方法增加基学习器差异性。
2)通过对未标记样本的筛选,增加半监督学习的稳定性。
3)集成方式在运算中调整各分类器权值,进行增量式学习,进一步提升分类器性能。
4 仿真实例
4.1 UCI数据集实验
为了比较所提算法与其他算法的性能,我们对来自UCI 机器学习库的8 个数据集进行了一系列实验[15]。数据集的属性总结如表2。

表2 UCI分类数据属性
对于每个数据集,使用数据集中的25%样本作为测试数据,其余75%用于训练。在我们测试SSL 算法时,并非所有训练数据都与标签一起使用,尽管所有数据都已标记。我们人为地将20%的数据设置为标记其余80%未标记。例如,假设有一个包含1000个实例的数据集,250个实例用作测试数据,750个实例用作训练数据,其中750个实例中的150 个被视为已标记,其余600 个被视为未标记,训练和测试集的选择是随机的,同时保留所有集合中正负类的原始比率。
本文使用n 倍交叉验证的平均错误率(用n =3)在标记数据上作为CSO的适应度函数,以降低选择特征子集中过度拟合的风险。CSO 算法中的其他参数设置如下。种群大小为30,最大迭代次数为100,φ为0.1。在第一次在[0,1]之间随机初始化粒子,阈值参数λ为0.5。PCA 转换中涵盖的方差设置为0.95。每个算法独立运行25次,
4.2 实验结果
计算各分类器绝对误差后的具体结果见表3~表6,其中“MT”表示采用多种学习模型,“MF”表示多种特征降维方法,“MV”表示多视图方法,“3M”表示所提算法,“ST”表示单视图方法,“TT”表示三重训练方法,具体的特征降维以及学习模型的字母表示在3.2 节中已有描述。在表3 中,我们发现J48决策树在这些特定数据集上比其他学习模型有着更好的性能,而其他模型在相同数据集上产生更大的误差。因此在MT算法中由于其他模型会降低整体集成,因为他们给出了更多的错误决策,即便如此,MT 方法仍然具有与J48 方法极其相近的误差。我们可以得出结论,直接使用原始的学习模型,不经过其他方法的调整,MT方法并没有展现出自身的优势,因为他集合多种模型优势的同时也吸收了其劣势。
表4~5 为使用多种特征降维方法以及多视图方法对分类器泛化能力的提升,可以看到无论对于单一的学习模型,还是MT方法,多视图以及多特征降维方法都可以极大提升分类器的精度,单一的特征操作方法误差都与MF 方法相差甚远,多视图方法对TT 学习模型也有着巨大的改进。同样的,在有其他算法的调整下,无论是特征降维还是多视图方法,MT算法都展现出了优于单一分类器的性能,此时集成学习能够更好吸收多种学习模型的优势,展现出对单一分类器模型的巨大优势。

表3 MT算法误差比较
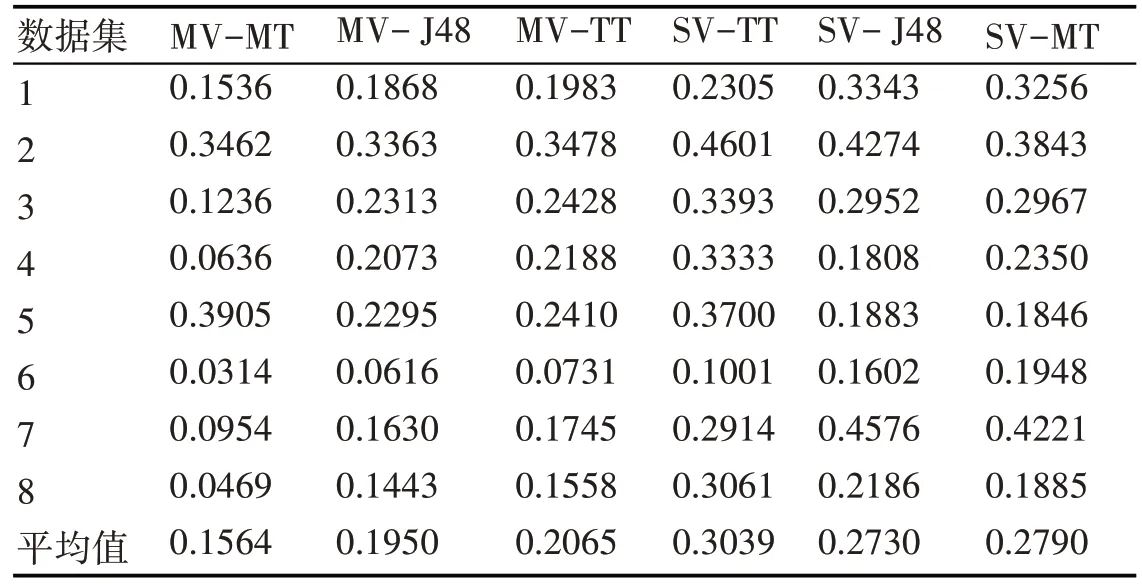
表5 MV算法误差比较

表6 3M算法误差比较
在最后一组实验中最后我们同时采用MT、MF以及MV 方法来构造分类器,调查包含更多基础学习器是否能够进一步提高泛化能力。在这项工作中进行的最后一组实验是比较使用前3 组实证研究中使用的设置组合生成的集合。具体结果如表6,3M 通过结合使用三种不同的特征操作方法和四种不同的分类器模型来创建多样性,从而产生24种不同的基学习器。 MF-MT,MV-MT,MV-MF-TT,MF-TT 和 MV-TT 分别有着 12,6,6,4,2 种基分类器,其错误率也随基分类器数量的减少而增加。所以我们可以得出结论,所提方法通过增加基分类器的多样性来提升集成学习的泛化性能。
4.3 垃圾邮件分类实验
在本节中,我们使用真实邮件数据集并在真实的网络环境中评估我们提出3M分类模型。其中包含58 个属性和总共4601 封电子邮件(813 封垃圾邮件和688 封合法电子邮件)[16]。为了评估基于分歧的半监督学习算法,我们将该数据集分为两部分:标记数据和未标记数据,其中未标记数据由从原始数据集中随机选择的600个实例组成,进行60次迭代测试,然后计算预测率后与其他分类器模型相比较。
图1为ROC曲线图,是用于比较各种分类器性能的重要度量。它代表了作为单个标量的预期性能,其中曲线下面积越大,表示分类器性能实验越好,可以看出,即便在考虑原样本中正负样本比例的情况下,3M算法仍然展现了良好的性能。
图2 为在学习过程中分类器的精度变化,可以看出在少量训练样本时相较于其他算法由于3M算法可以吸收未标记样本的从而有着良好的预测性能,与普通的半监督算法相比,它有着多种模型用以及时纠正半监督算法中的错误。
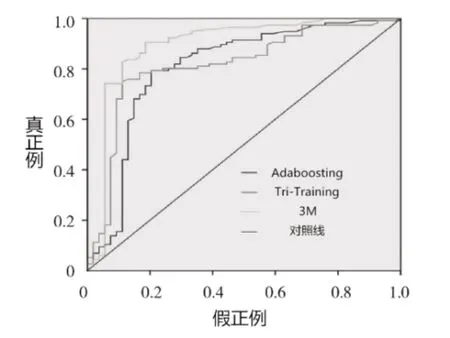
图1 ROC曲线图

图2 预测精度变化图

图3 参数β对算法的影响
图3~图4 为筛选未标记样本时参数的设置对误差的影响,当β=1 时,算法根本无法达到其最优性能。也就是直接选用全部的未标记样本根本无法穷尽半监督算法的性能,当β=3 时,多视图半监督回归算法可以很快最优性能。
其次,所提出算法在每组中选择ɑ%样本用以学习。为了研究参数ɑ的影响,我们确定β=3,并将ɑ从1 增加到9。结果显示在图4。如果我们为ɑ(ɑ≤1)指定一个太小的值,则多视图半监督回归算法在几次迭代中无法达到其最佳性能。它表明,ɑ可以加速半监督学习过程。但是,如果我们为ɑ(ɑ ≥7)设置了太大的值,则在多次迭代后RMSE 将显示不稳定的上升和下降趋势。它表明在一次迭代中选择太多未标记的样本往往会带来噪音。最终在ɑ=3时半监督效果较好。

图4 参数α对算法的影响
5 结语
本文提出了一种新型的集成分类器,使用多种视图、特征降维方法和学习模型来构造更多的基分类器来提高集成性能,筛选无标记样本加入到学习中,最后在将其与Tri-Training 和非SSL 学习模型进行比较,表明所提出的3M 模型优于比较算法。与原始单视图数据相比,更好的性能可归因于多个视图配合不同的特征操纵方法带来的多样性。此外,通过使用集成方法,改善了未标记数据的预测准确度,因此能够降低半监督学习未标记数据的风险。我们的结果证实,由不同类型的基础模型组成并使用不同特征的异构集成学习具有优异的泛化性能。
将来我们将研究此种方法在差异性方面的更多发展以及在故障预测方面的应用。并将其应用于民用航空故障诊断或分类中,更好地提升安全性以及降低维修成本。
猜你喜欢
现代电子技术(2022年15期)2022-07-28
电子产品世界(2022年4期)2022-04-21
汽车实用技术(2022年4期)2022-03-07
计算机系统应用(2021年2期)2021-02-23
海峡姐妹(2019年12期)2020-01-14
软件导刊(2017年4期)2017-06-20
现代兵器(2017年4期)2017-06-02
现代兵器(2017年4期)2017-06-02
试题与研究·中考数学(2016年4期)2017-03-28
科技视界(2016年16期)2016-06-29
