
基于RoBERTa-WWM的中文电子病历命名实体识别
2021-02-27 01:29朱岩,张利,王煜
计算机与现代化 2021年2期
朱 岩,张 利,王 煜
(1.蚌埠医学院护理学院,安徽 蚌埠 233030; 2.中国科学技术大学科学岛分院,安徽 合肥 230001)
0 引 言
随着“互联网+”医疗体系的兴起,产生了大量的电子病历。这些非结构化的文本中包含着关于患者诊疗过程的关键信息,例如临床症状、诊断结果和用药表现[1]。从电子病历(Electronic Medical Records, EMR)中抽取这些医学信息可以更好地帮助研究人员理解某类疾病的病因、病理表现和治疗手段。此外,研究人员还可以利用所抽取的信息构建医疗决策支持系统(Decision Support System, DSS)[2]或医学知识图谱(Knowledge Graph, KG)[3]。然而,从电子病历中手动抽取这些信息是耗时费力的,因此,人们尝试使用自然语言处理(Natural Language Processing, NLP)技术来解决这一问题。
命名实体识别(Named Entity Recognition, NER)是NLP的一项基本任务,其目的在于从非结构化文本中识别出结构化的命名实体。如图1所示,即为从电子病历中抽取关键信息,并让计算机理解语义知识的关键步骤[4]。早期的命名实体识别方法包括基于规则(Rule-based)的方法和基于字典(Dictionary-based)的方法[5-6]。但是这些方法只能识别预先定义或存储于字典中的实体,缺少泛化性。传统的机器学习方法也被用于命名实体识别,例如隐马尔可夫模型(Hidden Markov Model, HMM)[7]。但是这些方法需要人工选择特征。随着深度学习的兴起,人们也使用深度学习的方法进行命名实体识别任务。其中使用最广泛的是可以捕获序列信息的循环神经网路(Recurrent Neural Network, RNN)以及其变种,如双向长短时记忆(Bidirectional Long Short-Term Memory, BiLSTM)网络[8]。但是深度学习方法的效果仍受限于训练集的质量。
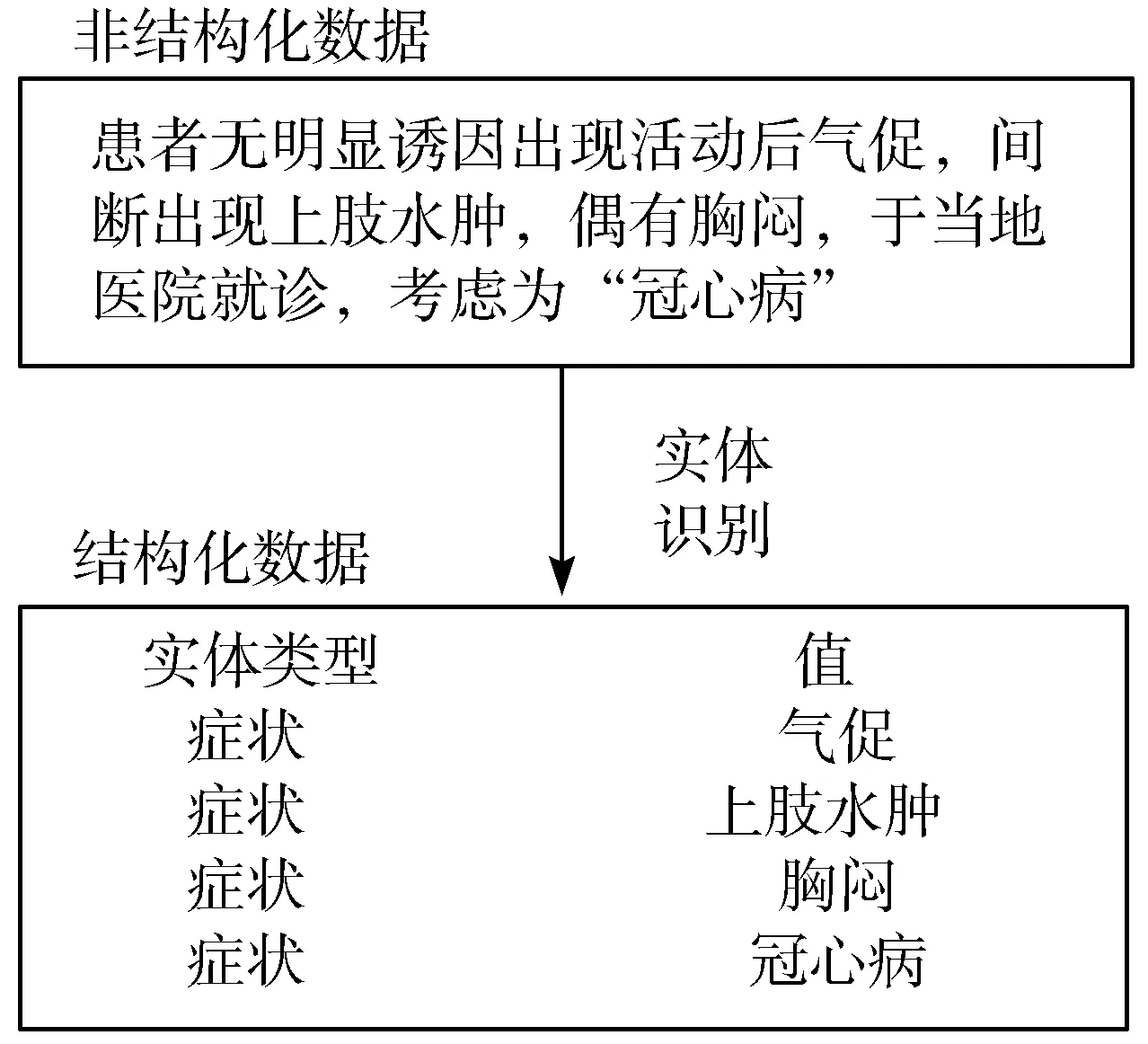
图1 从中文电子病历中识别命名实体
因此,人们开始关注如何从大量无标签文本中获取先验语义知识来增强语义表示,并提出了基于Transformer的预训练模型[9],例如BERT(Bidirectional Encoder Representations from Transformers)模型[10]。BERT通过2种预训练任务,即掩码语言模型(Masked Language Model, MLM)和预测下一个句子(Next Sentence Prediction, NSP),从无标签文本中获得先验语义知识,并通过微调(Fine-tuning)将蕴含这些知识的增强语义表示应用于下游自然语言处理任务中,如识别中文电子病历中的命名实体。但是中文的词之间并没有分隔符,因此BERT在使用中文语料进行预训练时只能掩盖字,而不是掩盖词。这样,通过预训练产生的语义表示仅仅是字级别的,并不能获得词级别的语义表示,即无法在预训练过程中获取词的信息。而RoBERTa-WWM(A Robustly Optimized BERT Pre-training Approach-Whole Word Masking)模型在预训练时,首先将语料进行分词,然后随机遮掩一部分词并进行预测[11]。这样,该预训练模型所生成的语义表示便含有词的信息,更适用于中文命名实体识别任务。同时,RoBERTa-WWM也对预训练过程进行了优化,提出了动态掩码模型(Dynamic Masking Language Model)并删除了NSP任务。
本文提出一种基于RoBERTa-WWM的中文电子病历命名实体识别方法。其主要工作如下:
1)该方法使用RoBERTa-WWM而不是BERT获取语义表示。该语义表示更适用于中文命名实体识别任务。
2)获取语义表示后,利用BiLSTM网络捕获序列信息,再使用条件随机场(Conditional Random Field, CRF)限制标签间的序列关系。
3)在真实的电子病历语料上验证模型的效果。该数据集由“2019全国知识图谱与语义计算大会(China Conference on Knowledge Graph and Semantic Computing 2019, CCKS 2019)”提供。实验结果表明,该方法可以有效提升中文电子病历中命名实体的识别效果。
1 相关工作
1.1 命名实体识别
命名实体识别旨在从非结构化的文档中抽取结构化的命名实体,例如电子病历中的疾病名称、药物名称等。基于规则和字典的方法曾经占据重要的地位。例如Song等人[12]提出了一种基于字典的方法识别生物命名实体。但是基于规则和字典的方法缺乏泛化性,针对某一特定实体识别任务设计的规则或字典很难用于其他实体识别任务。也有研究人员使用传统的机器学习方法来识别电子病历中的命名实体,例如Liang等人[13]提出了一种将支持向量机(Support Vector Machine, SVM)和CRF结合的级联型方法。虽然这些方法相较于基于规则和基于字典的方法具有更好的泛化性,但是需要手动选择特征。近年来,随着深度学习的发展,RNN及其变种被应用于命名实体识别。深度学习方法可以自主学习特征,并且更深的模型结构可以抽取出更抽象的特征。例如Li等人[14]设计了一种特殊的词向量并使用BiLSTM-CRF模型提升了识别效果。Xia等人[15]提出了一种基于自训练的BiLSTM-CRF模型来处理中文NER任务。也有研究人员使用卷积神经网络(Convolutional Neural Network, CNN)来识别实体,例如Zhu等人[16]使用CNN来编码中文字符。虽然深度学习的方法优于传统的机器学习方法,但是它们的表现均受限于训练集的规模和质量。因此,人们考虑是否可以从大规模的无标签语料中学习先验知识,并将其应用到各种NLP任务中,例如命名实体识别。
1.2 预训练模型
预训练模型可以从语料库中学习含有先验语义的字向量。Peters等人[17]首先提出了ELMo(Embeddings from Language Models)模型。该模型通过BiLSTM对上下文信息进行建模,获得包含上下文信息的字向量。但是BiLSTM的信息抽取能力弱于Transformer。同时,由于BiLSTM的序列特性,其并不能进行并行计算。Devlin等人[10]于2018年首次提出了BERT。BERT由12层的Transformer组成,并通过2种预训练任务MLM和NSP从无标签的非结构化文档中学习先验语义知识。这些先验语义知识通过微调被应用到各种下游NLP任务中,包括命名实体识别。但是,对于中文语料而言,BERT在进行预训练任务MLM时会随机掩盖字,而不是词,如图2所示。
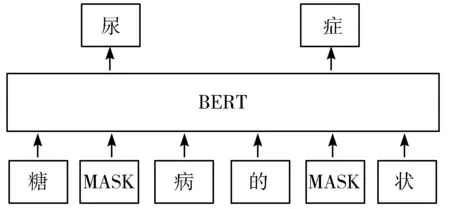
图2 BERT的掩码过程
BERT通过预测这些被掩盖的字学到含有先验语义知识的语义表示。但是这些语义表示仅仅是字级别的,其中并不含有词级别的信息。与之相反,RoBERTa-WWM在进行中文预训练时会首先对句子进行分词,然后随机遮掩一部分词并进行预测,如图3所示。通过这种方式,RoBERTa-WWM可以在预训练时学到词级别的语义表示,更有助于提升中文NLP任务的效果。
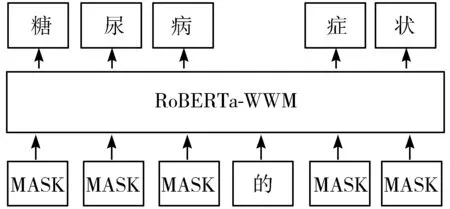
图3 RoBERTa-WWM的掩码过程
2 本文方法
本章介绍基于RoBERTa-WWM的中文电子病历命名实体识别方法,该方法包括RoBERTa-WWM模块、BiLSTM模块和CRF模块。
2.1 RoBERTa-WWM模块
RoBERTa-WWM由12层Transformer组成,如图4所示。每个Transformer都包含多头自注意力[9]。假设输入是T={t1,t2,t3,…,tn},输出是H={h1,h2,h3,…,hn},并且该输出含有RoBERTa-WWM在预训练阶段获得的先验语义知识。RoBERTa-WWM的参数在训练时会根据训练集进行微调,其数值会被更新,以便学习训练集中的语义知识。

图4 RoBERTa-WWM模块
2.2 BiLSTM模块
RNN可以通过传递隐藏层参数来捕获序列信息,然而,这样也可能造成梯度爆炸或梯度消失。作为RNN的变种,LSTM通过引入门控单元来解决上述问题[18]。LSTM基本单元的计算公式如下所示:
(1)
(2)
ht=ot⊙tanh(ct)
(3)
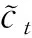
对于命名实体识别任务,句子前向和后向的信息均十分重要,但是LSTM仅能捕获单方向的信息。因此,本文使用双向长短时记忆BiLSTM来捕获句子前向和后向的信息,如图5所示。该模块的输入即为RoBERTa-WWM模块的输出。
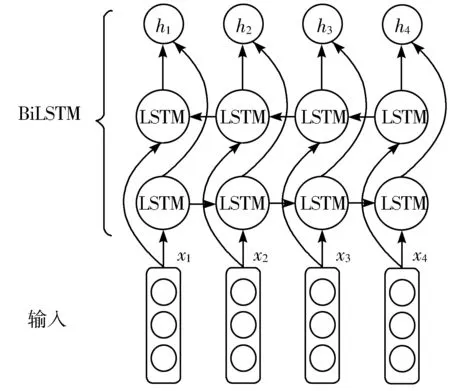
图5 BiLSTM模块
2.3 CRF模块
在命名实体识别任务中,临近的标签间有顺序关系。例如,I-Drug标签必须出现在B-Drug标签之后。本文引入条件随机场来确保这一顺序关系[19-20]。具体地,将T视为转移矩阵,P视为分数向量。对于某一可能的输出序列Y={y1,y2,…,yn},其分数为:
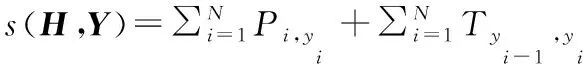
(4)
其中H={h1,h2,h3,…,hn}即为BiLSTM的输出,同时也是CRF模块的输入。当进行解码时,使用维特比算法[21]寻找所有Y中得分最高的Yr,即:
Yr=arg maxy∈Ys(H,Y)
(5)
其中yi表示所有可能的序列。
3 实验与结果分析
本章介绍实验所使用的数据集并展示实验结果。实验基于深度学习框架飞桨(Paddlepaddle)。硬件方面,使用4块CPU以及1块NIVIDA V100 GPU。
3.1 数据集
本文实验的数据集源自2019年全国知识图谱与语义计算大会(CCKS 2019)。其中包含真实的电子病历数据,这些电子病历数据由专业医学团队进行标注,表1展示了该数据集中各种类型的实体的分布。
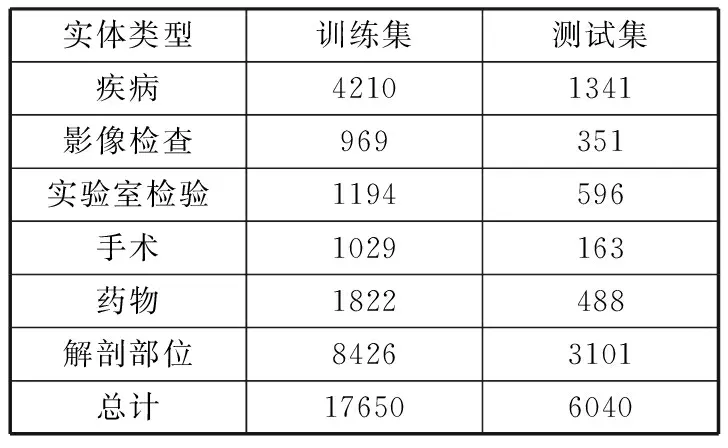
表1 CCKS 2019数据集的实体分布
3.2 超参数设置
本文使用试错法寻找最优的超参数。表2列出了本文所使用的超参数值。
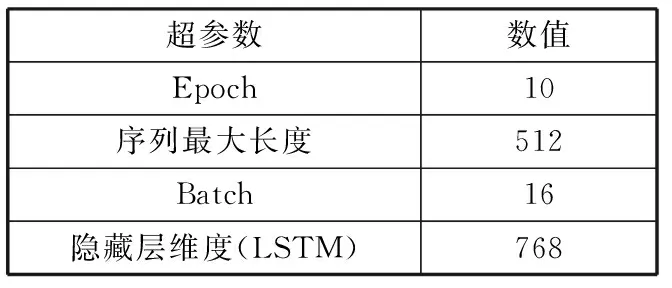
表2 超参数
3.3 实验结果
表3列出了在数据集上进行不同实验时所获得的结果,对比了不同的预训练模型以及不同的下游模型结构对于识别效果的影响。使用精确率(Precision)、召回率(Recall)和F1值[22]作为本次实验的评价指标。其中,精确率指所预测实体中正确实体的比例;召回率指训练集中被预测出的实体的比例;F1值根据下式进行计算:
F1=(2×Precision×Recall)/(Precision+Recall)
(6)
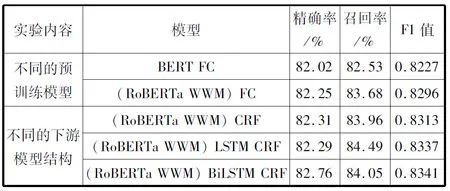
表3 不同模型的实验结果
从表3可以看出,使用RoBERTa-WWM可以获得相较于BERT有更好的识别效果,F1值可以提升0.69。对于不同的下游模型结构,使用BiLSTM和CRF可以获得最好的效果,其F1值为0.8341。
4 讨 论
4.1 BERT与RoBERTa-WWM
正如1.2节所述,BERT和RoBERTa-WWM均可以从大规模的无标签语料中学得先验语义知识,并提升下游任务的效果,例如识别电子病历中的命名实体。但是对于中文预训练语料来说,因为中文的词之间没有分隔符,因此BERT仅仅能获得字符级别的语义知识[23]。然而,RoBERTa-WWM在预训练阶段会首先对句子进行分词,并预测被遮掩的词。通过这种方式,RoBERTa-WWM可以获得词级别的语义知识。此外,与BERT在预训练阶段仅仅进行静态掩码的策略不同,RoBERTa-WWM会进行动态掩码策略,即每一个Epoch中遮掩的词是不一致的,这样可以获得相较于静态掩码策略更丰富的语义知识。最后,RoBERTa-WWM与BERT相比并没有进行预训练任务NSP。显然,对于NER任务,没有必要获得句子的上下文关系,因为输入总是独立的句子,而不是句子对。综上所述,对于识别电子病历中的命名实体,使用RoBERTa-WWM作为预训练模型可以获得比BERT更好的效果。
4.2 下游任务结构
不同的下游任务模型结构会对结果产生不同的影响。如表3所示,当下游模型结构仅仅是一层FC时,其F1值最低。使用CRF作为下游模型结构可以提升F1值,因为其可以确保标签间的顺序。而添加LSTM层可以捕获序列关系。然而,正如2.2节所述,对于从电子病历中识别命名实体的任务,句子前后的信息均十分重要,因此(RoBERTa-WWM)-BiLSTM-CRF模型获得了最高的F1值。其使用RoBERTa-WWM作为预训练模型,获得了词级别的语义表示,并添加了BiLSTM获得了双向的序列信息,同时使用CRF确保标签间的顺序。
5 结束语
本文提出了一种基于RoBERTa-WWM模型识别中文电子病历中命名实体的方法。相较于BERT仅仅能获得字级别的语义表示,RoBERTa-WWM通过在预训练时进行全词掩码来获得词级别的语义表示。这种预训练方法获得的语义表示更加适用于中文文本。本文使用CCKS2019提供的数据集评估模型的效果,该数据集由真实医院的电子病历组成。实验结果表明,使用RoBERTa-WWM作为预训练模型可以获得比BERT更好的效果。同时,当下游模型结构是BiLSTM和CRF时,可以获得最好的F1值。在未来的工作中,笔者将尝试使用RoBERTa-WWM识别出中文电子病历中命名实体之间的关系。
猜你喜欢
趣味(语文)(2021年9期)2022-01-18
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19
数学小灵通·3-4年级(2020年9期)2020-10-27
通信学报(2019年5期)2019-06-11
东方女性(2018年3期)2018-04-16
通信技术(2018年3期)2018-03-21
散文诗(2017年17期)2018-01-31
中国卫生(2016年10期)2016-11-13
中国卫生(2015年10期)2015-11-10
浙江大学学报(工学版)(2015年4期)2015-03-01
