
自适应动态肤色检测技术研究进展
2021-03-02 13:38王烨东李文元李昌禄雷志春
液晶与显示 2021年2期
张 坤, 王烨东, 李文元, 李昌禄, 雷志春*
(1.天津大学 微电子学院,天津 300072;2.海信视像科技股份有限公司,山东 青岛 266071)
1 引 言
肤色检测实质上是在数字图像中划分皮肤和非皮肤区域的过程。随着信息社会的发展,图像和视频已经成为人们广泛使用的信息载体,对于肤色检测和处理的需求也日益增多。在各种计算机视觉任务中,肤色检测已经被应用于人脸检测[1]、人体追踪[2]、表情识别[3]、手势识别[4]、疲劳驾驶[5]、智能监控[6]、中医皮肤病诊断[7]以及敏感图像过滤[8-9]等方面。近年来,“美图秀秀”、“天天P图”等人像自动美化软件受到了广大女性用户的喜爱,肤色检测在网络社交媒体中展现出很高的应用价值。2019年度中国网络视听发展研究报告中[10]指出,截止2018年底,我国网络视频用户总规模已达7.25亿,短视频、网络直播等领域正表现出迅猛发展之势,人们更加喜欢使用皮肤美化功能来使自己的皮肤表现得白皙、有吸引力。同时,“智能电视”也迎来了发展革新的浪潮,肤色呈现作为衡量画质的重要指标自然受到广泛的关注。因此,肤色检测作为肤色美化[11]、肤色增强[12]的关键步骤,也变得越来越重要。
近20年来,从最初的阈值分割法到现在的深度学习语义分割技术,有大量肤色检测相关的方法和理论被提出。文献[13]中根据是否涉及物理成像过程将肤色检测方法分为基于物理的方法和基于统计的方法,但由于需要使用光谱摄制仪等成像设备,基于物理的方法应用范围较小。根据是否需要获取像素的空间分布信息,可以将肤色检测方法分为基于区域的检测方法和基于像素的检测方法两大类型,综述文献[14]中重点对基于像素的各种肤色检测方法及其所涉及的相关技术进行了总结。
上述文献中所介绍的内容主要是静态的肤色检测方法,而这些方法在非限制性场景中的实用性较低。值得注意的是,统计法和机器学习法依赖于一定规模的训练数据并受到数据集质量的影响。虽然深度学习技术可以通过在特征提取网络中增加隐藏层来提高精确度,但与此同时,也将会增加训练时间和计算成本。自适应技术可以在提高准确率的同时,减少或避免对数据集的依赖,维持较低的计算成本,具有极强的实用价值。本文对自适应肤色检测方法近20年来的研究成果进行了归纳总结,主要从基于参数动态调整和基于高层语义特征的自适应肤色检测方法入手,介绍了各类代表性方法,并进行了分析和讨论。
2 自适应肤色检测技术研究背景
为了便于理解肤色检测技术的研究背景,本部分简要介绍了传统的静态肤色检测技术以及近些年应用较广的深度学习方法,并分析了这些技术在实际场景中所面临的难题,介绍了几种常用的性能评价指标。
2.1 静态肤色检测技术
静态肤色检测方法主要通过使用某种固定规则来实现肤色检测,主要涉及色彩空间的选择、肤色模型的建立两大步骤。本文总结了常见的静态肤色检测方法,详细分类如图1所示。
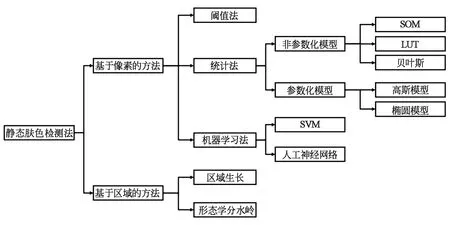
图1 静态肤色检测技术
色彩空间是一种表示颜色的抽象数学模型,常用的色彩空间有RGB、YCbCr、HSV等,肤色在不同色彩空间中的分布特征存在差异,如图2所示。根据色彩模型构建的方式不同,静态肤色检测方法可以细分为阈值法、统计法、机器学习法、区域生长法等。
阈值法是一种实现简单、计算量小、速度快的分割方法[15],阈值法的性能表现与所设定的阈值密切相关,适用于目标和背景存在明显灰度级差异的场景,而在复杂环境中无法准确地描述肤色的分布。统计法根据肤色样本在色彩空间中的分布构建肤色概率图(Skin Probability Map,SPM),即在离散化的色彩空间中为每个点分配概率值,然后利用建立起来的SPM判断待检测颜色是否属于肤色。非参数化模型通常使用直方图估计样本的SPM,主要方法包括自组织映射(Self-Organizing-Map,SOM)、查找表(Look-Up-Table,LUT)、贝叶斯分类器等方法。但是建立可靠的非参数化模型需要较大规模的肤色样本点和较高的存储空间。参数化方法则根据肤色聚类特性,直接使用高斯模型或椭圆模型等已有模型进行拟合即可。由于参数化模型可以在较少训练样本中得到可靠的SPM,因此常被用于自适应方法[16-17]。机器学习方法与统计法类似,即通过学习训练样本中的规律来实现肤色检测,但与之不同的是机器学习技术不需要建立明确的肤色模型,而是将肤色检测视为一个二分类的过程。其中常用的方法有支持向量机(Support Vector Machine,SVM)和人工神经网络(Artificial Neural Network,ANN)等。
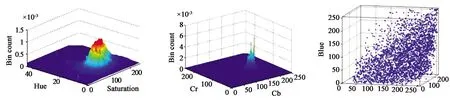
图2 肤色分别在(a) HSV, (b) YCbCr, (c) RGB色彩空间中的分布特征[15]。
上述肤色检测方法主要是通过每个像素点的色彩信息判断其是否属于肤色点,没有考虑像素与像素之间关系,而基于区域的方法则主要通过像素之间的空间关系来进行判断。区域生长法从种子点开始,不断向周围进行扩散,将具有与种子相似属性的邻近像素附加到每个种子上,并继续向周围扩散,直到遇到边缘或者临近像素均不与种子点相似为止。区域生长法可以使用图像的纹理特征,对去除背景有一定帮助,但是区域生长法十分依赖种子点的选取,并且在实际图像尺寸中需要较大的计算量[15]。
2.2 基于深度学习的肤色检测技术
值得注意的是,近些年来机器学习得到了空前的发展,神经网络的层数越来越多,学习到的特征也越来越丰富,深度学习逐渐发展成为解决图像问题的一个重要的分支,在肤色检测领域也得到了越来越多的关注。
Lumini等学者[18]发现使用SegNet[19]、Unet[20]、DeepLab[21]等深度学习语义分割网络检测肤色能够获得明显优于传统方法的结果。一方面,借助深层的特征提取网络,深度学习网络可以有效地提取肤色区域的颜色、纹理等特征,有助于减轻复杂背景的干扰,提升检测精确度,因此深度学习方法通常能够得到比传统方法更加出色的检测效果。但另一方面,深度学习方法需要使用大量标注的皮肤数据进行训练,而像素级的准确标注仍是一项艰巨的任务。尽管Dourado等学者[22]以及He等学者[23]已经尝试通过迁移学习和多任务弱监督技术来减弱网络对大量标注肤色数据集的依赖,但是一个性能优异的肤色检测网络通常需要结构复杂的特征提取网络以及较长的训练时间。在深度学习中,检测精度和速度之间的矛盾也在一定程度上制约了深度学习肤色检测在实际中的应用。例如DeepLab通用分割网络的深度较大,能得到出色的精度,在本文第3章的实验对比中有所体现。但对于一张306×306的输入图像,即使在TITAN X GPU中也仅能获得8 FPS (Frames Per Second)的速度,与实时性要求差距较大。因此在一些实时性要求高、运行设备性能低的情况下,深度学习方法可能不是最佳的选择。
2.3 肤色检测方法所面临的挑战
静态和深度学习肤色检测技术主要受到以下因素的影响:
一方面,在非限制性场景中,光照分布和强度的改变都会导致肤色出现变化,是影响肤色检测性能的最重要因素之一;其次,种族、性别等个体差异,化妆等皮肤涂覆手段、相机传感器的性能和参数、图像的尺寸、清晰度、噪声以及调色处理过程等都会对肤色造成影响;此外,去除背景中与肤色相近的颜色干扰也是一个比较困难的问题。虽然深度学习方法可以在一定程度上改善上述问题,但是网络结构复杂度高、训练成本大、不易平衡精度与速度的特点限制了其实际应用范围。另一方面,数据集是获取先验规则或训练模型的基础,但是标注数据工作量大,目前公开的肤色数据集较少、质量不高,不同种族覆盖程度不均衡等因素也限制着肤色检测技术的发展。
2.4 肤色检测方法使用的评价指标
肤色检测的评价指标主要分为定性和定量两种。其中定性方法将肤色检测结果可视化为二值图像,通过主观判断来确定肤色检测的好坏。肤色检测任务实质上是对每个像素进行的二分类任务,因此研究中常用的定量分析指标有:
(1)
(2)
(3)
(4)
(5)
(6)
式中,TP(True positive)、TN(True negative)分别代表正确分类为肤色和背景的样本数,FP(False positive)、FN(False negative)分别代表错误分类为肤色和背景的样本数,在肤色检测中总样本数是图像中的总像素数。式(1)~(6)中,FNR、FPR、Precision、Recall、Accuracy以及F-measure分别代表漏检率、误检率、精确率、检出率、准确率和F值,其中F值常被用作肤色检测器的综合性能指标。除此之外,还有ROC曲线[24]、混淆矩阵行列式[25]等定量分析指标。
3 自适应肤色检测方法
在非限制性场景中,肤色容易受到光照变化的影响,从而出现不同程度的亮度和色彩偏移。人眼具有颜色恒常性的特点[26],即人可以在图像整体存在色调偏移时正确识别出图像中物体原有的颜色,而抛开了所受光照的影响。然而,目前人们并未研究透彻颜色恒常性的机制,无法得到完美覆盖不同环境的静态方法,同时在很多场景中对实时性有较高的要求,因此研究学者提出了各种自适应肤色检测技术来加以解决。在本文中,自适应肤色检测方法主要分为两种:基于参数动态调整和基于高层语义特征的自适应肤色检测方法。
3.1 基于参数动态调整的自适应方法
3.1.1 自适应阈值法
虽然使用特定的阈值方法具有实现简单、易于调整、计算成本低的特点,但是固定阈值无法适应光照变化的环境,针对这种情况,学者们提出使用自适应阈值法来提高检测准确性,光照变化通常会给皮肤带来亮度和颜色上的变化。许多肤色检测算法选择舍弃亮度分量,而Jayaram等学者[27]在850张图像中对比了使用亮度分量和不使用亮度分量的方法,发现亮度分量可以提供不同层次的皮肤颜色信息,因此设定一组随亮度信息变化的规则可以达到自适应肤色检测的目的。Gracia等学者[28]在YCbCr和HSV色彩空间中分别设定了一组受亮度控制的肤色检测规则,有效提高了不均匀光照环境中的检测准确率。由于该方法在两个色彩空间中使用的是同一种实现方案,因此本文只介绍YCbCr色彩空间中的自适应阈值规则,即如果像素满足以下条件,则将其判定为肤色像素:
(7)
(8)
.
(9)
Cho等学者[29]在HSV色彩空间中初始化了一组阈值H(0.4, 0.7),S(0.15, 0.75),V(0.35, 0.95),然后根据S-V平面的直方图信息进行阈值更新。该方法对颜色复杂的场景表现不佳,只适用于背景简单的限制性场景,使用类似方法更新阈值的还有文献[30-31]。
郭耸等学者[32]提出了一种基于肤色相似度的自适应阈值方法,通过计算类间方差、类内离散相似度的方式确定分割肤色的最佳阈值,减轻了Adaboost人脸检测算法的计算负担,但是对人脸检测率提升较小。
张明吉等学者[33]利用4种线索辅助建立最优阈值。该方法认为最优阈值通常位于肤色概率分布图的某个谷底,且一般靠近肤色峰左侧。基于此规则,作者使用机器学习技术寻找最满足条件的谷底位置作为最优阈值。结果显示,该方法可以获得88.6%的检出率,12.1%的误检率,其中检出率与Cho等学者[29]的结果相比较提高了11.76%。Phung等学者[34]提出了一种利用人体皮肤纹理特征来选择合适肤色阈值的肤色检测方法,结合非颜色特征能够有效提高肤色模型的性能,该方法得到了4.5%的误检率和4.0%的漏检率。
自适应阈值法虽然能够在一定程度上提升肤色检测效果,但是在复杂背景中不容易得到可靠的阈值范围,同时在某些情况下阈值法难以精确描述肤色的分布情况。
3.1.2 自适应椭圆模型
肤色在YCbCr等色彩空间的色度平面中通常呈现椭圆分布,但是在光照变化、不同人种等情况下,固定的椭圆模型不一定能准确描述实际肤色。
李晓光等学者[35]提出了一种在DCT压缩域中使用的动态椭圆模型。作者利用图像亮度对色度聚类造成的非线性影响,根据亮度变化采用不同参数的椭圆模型表示肤色,形成了一种三维的椭圆模型,可以适应于不同的光照强度。
Hsu等学者[17]提出了一种使用光照补偿的自适应椭圆模型,如图3所示。首先判断图像中参考白(前50%亮度)的像素个数,如果大于某个阈值,则对RGB图像各分量进行线性调整。同时作者为了消除肤色和亮度分量之间的非线性关联,提出了YCb'Cr'色彩空间,并在Cb'Cr'平面建立椭圆模型用于肤色检测。该方法对一般光照强度变化适应较好,但是在复杂的光照环境中,光照补偿可能使图像更糟,同时也未能很好地解决偏色问题。
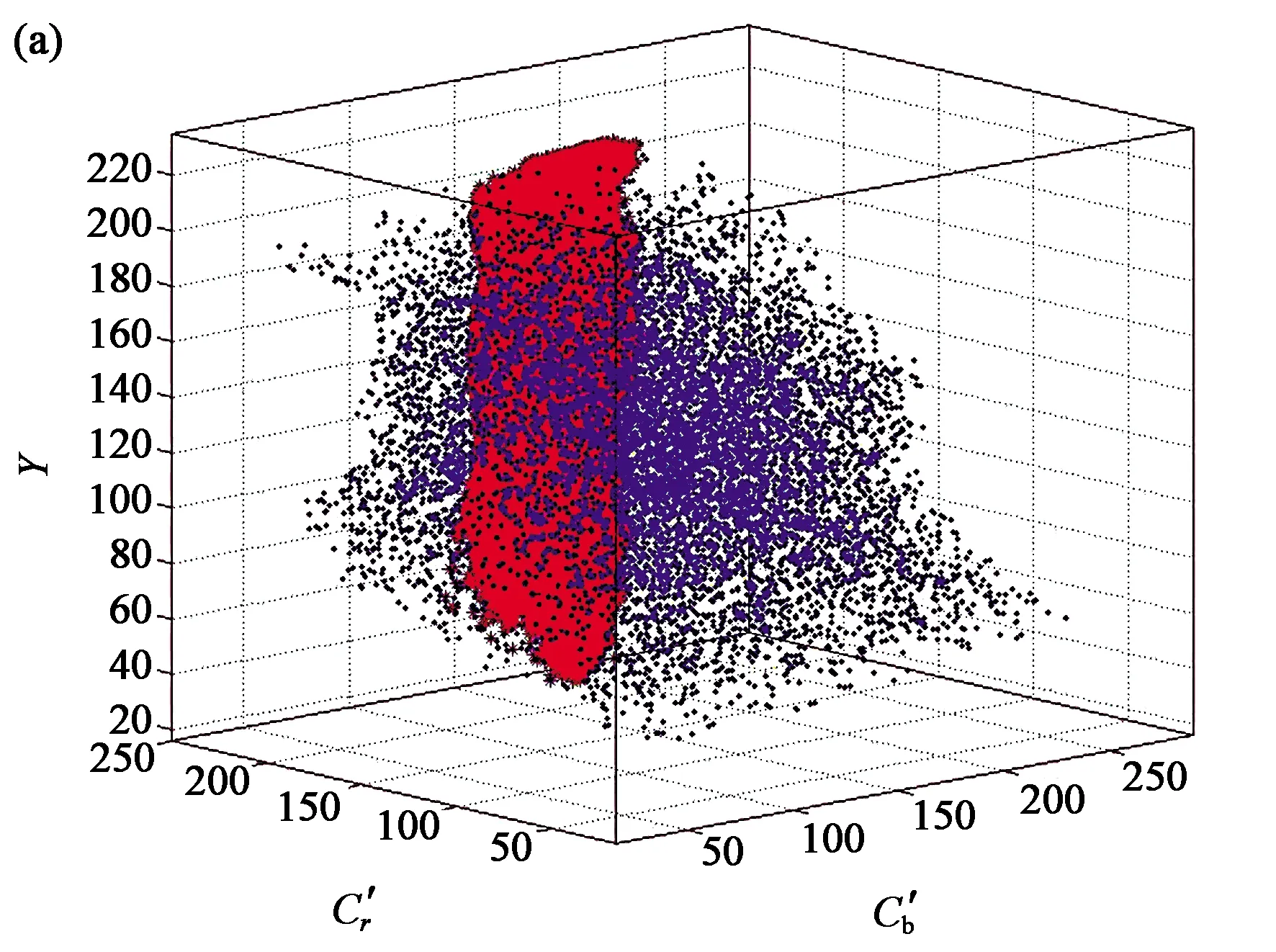
(a) YCbCr色彩空间(a) Color space of YCbCr
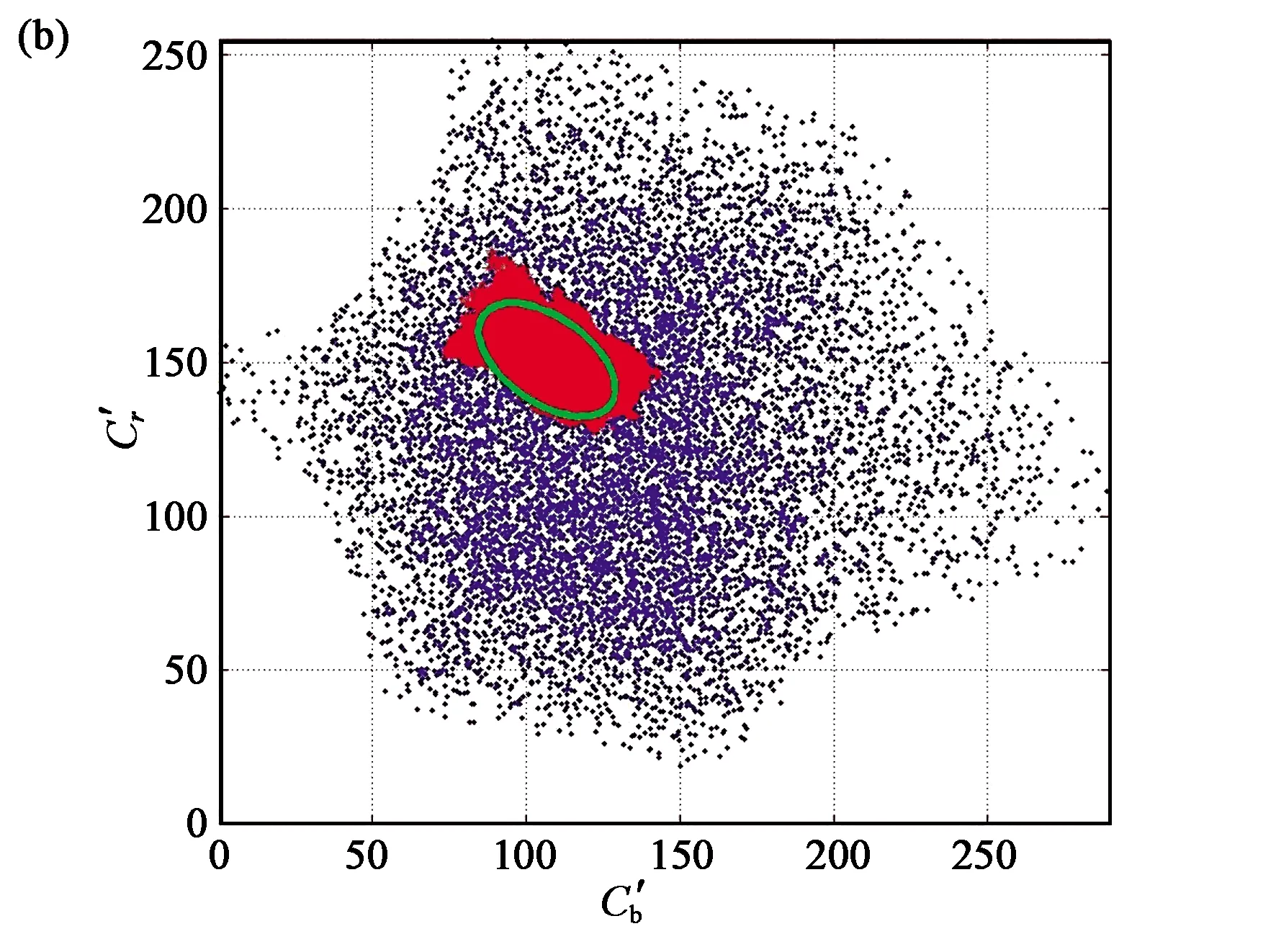
(b) CbCr子空间投影(b) Projection of CbCr subspace
夏思宇等学者[36]在Hsu基础上提出了一种自适应椭圆模型,使用白平衡法代替Hsu中的亮度补偿,利用退水法从二维直方图中获取新的椭圆模型中心,然后使用调整后的椭圆模型进行肤色检测。该方法中的结果一定程度上依赖于白平衡算法的实际效果以及退水法选择肤色峰的精确度。曾飞等学者[37]在Hsu自适应模型基础上,设计了可以随光照环境变化改变长短轴的椭圆模型,以解决人脸检测中的色彩偏移问题。在200张不同环境的测试图像中,改进的模型相比Hsu的椭圆模型提高了3.5%的人脸检测精确率,同时漏检率和误检率也得到了一定程度的降低。
椭圆模型可以刻画肤色在色度平面的分布特征,但是难以描述肤色在椭圆区域中的概率分布,此外,在椭圆模型建立不准确时,会产生较差的效果。
3.1.3 自适应高斯模型
高斯模型是一种有效描述肤色分布的方法,描述了肤色的概率分布情况,主要使用的是单高斯模型(Single Gaussian Model,SGM)和混合高斯模型(Gaussian Mixture Model,GMM)。Sun等学者[16]提出了一种基于直方图技术和动态GMM的视频皮肤区域跟踪方法。通过预训练的肤色模型对检测器进行初始化,然后利用GMM估计皮肤像素的分布,对每一幅图像的肤色模型进行微调。
熊霞[38]使用相关矩阵法对环境光照进行了估计,主要分为室内白炽灯、室外晴天、室内日光灯、室外阴天,如果检测图像属于某一预设的光照环境,则使用对应单高斯模型进行检测;反之,则使用4个SGM组成的GMM进行肤色检测。
张情等学者[39]在移动端掌纹分割应用中,通过“工”字形辅助定位手掌中心的小块区域,得到该子区域Cb、Cr的均值mf,根据图像中所有像素点到mf的欧氏距离进行排序,选择距离小的点作为肤色参考点生成单高斯模型进行后续肤色检测。江国来等学者[40]使用固定阈值获得肤色的高概率区域。然后由此得到高斯模型的均值和方差参数,再使用高斯模型进行肤色检测,对检测结果中位于固定阈值之外的肤色区域,使用贝叶斯分类器做进一步判断。其中高概生成的高概率区域和最终结果如图4所示。

图4 文献[40]方法中的(a) 原图, (b) 肤色高概率区域, (c) 最终结果。
高斯模型作为一种普遍使用的参数化模型,能够较好地刻画肤色的分布规律,常用于进行肤色概率图的构建,在许多其他自适应模型中也有所体现,单独使用高斯模型的自适应文献相对较少。
3.1.4 其他自适应模型
Khan等学者[41]提出了一种自动切换色彩空间的方法。该方法使用马科维兹最优化理论对不同色彩空间在肤色检测中的实际表现进行评估,并由此设定每个色彩分量的权重参数。这种方法可以利用色彩空间的不同特性进行最优组合,但是会大大提高检测方法的计算复杂度,类似的方法还有文献[42-43]等。自动选择色彩空间的方法试图寻找最优空间,但受色彩空间本身的限制,这种方法不一定能够获得明显的优化效果,但却会带来较大的计算负担。
Brancati等学者[44]发现在YCbCr的子空间YCb和YCr中,肤色分布表现为梯形,如图5所示。通过方程拟合两个子空间的梯形边界,可以确定肤色的色彩范围。实验结果显示该方法在背景简单的情况下,对高低亮度均可以获得较好的结果,但是容易受大面积明、暗背景的影响而出现错误。
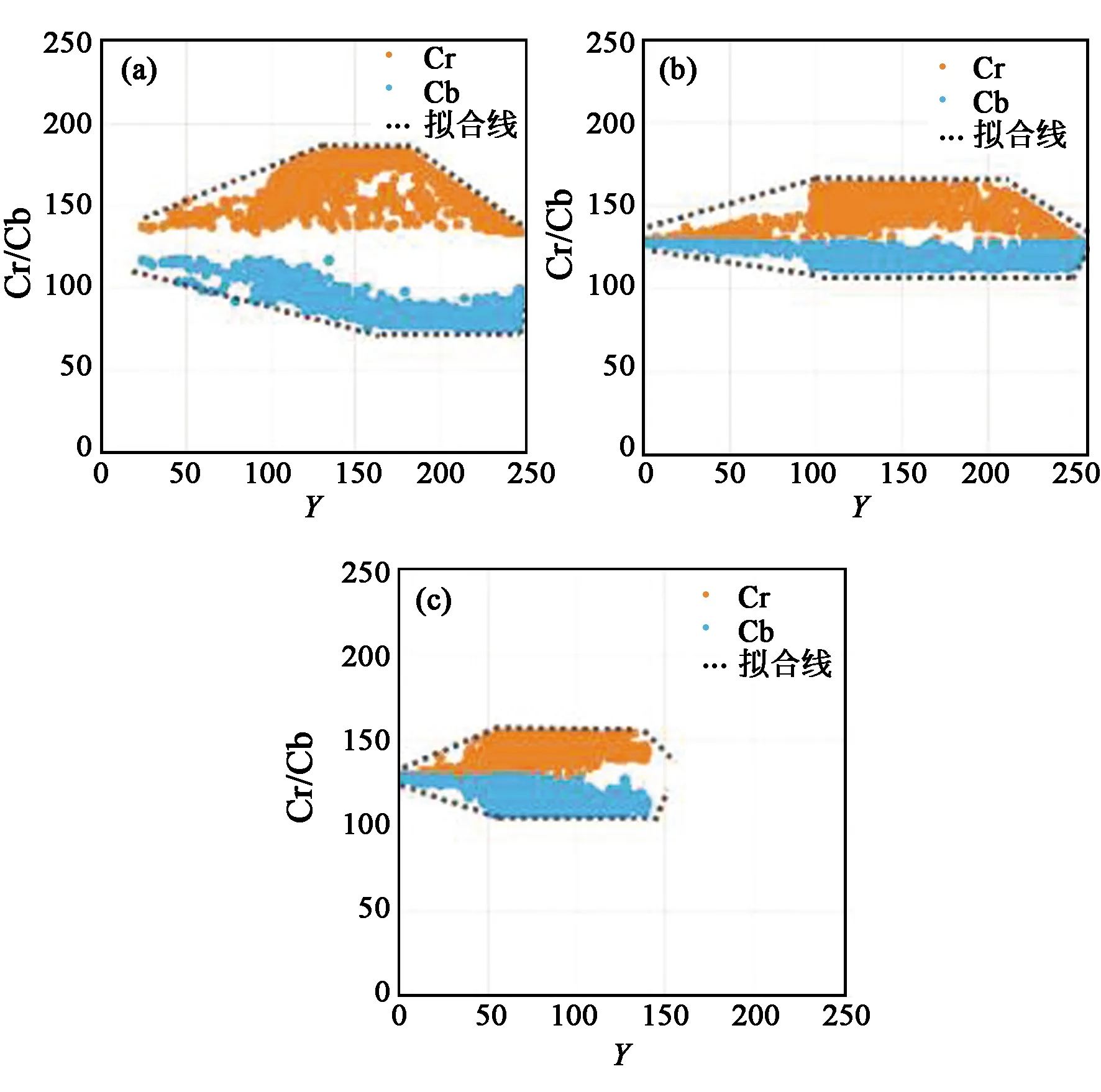
图5 Brancati[44]提出的梯形肤色分布。(a)室内;(b)室外;(c)弱光环境。
3.2 基于高层语义特征的自适应方法
在实际的肤色检测任务中,由于变化的光照环境、复杂的背景等因素影响,仅依靠色彩信息或简单纹理构建模型将不可避免地出现性能下降的现象。针对上述问题,学者们利用人脸等高层特征确定肤色区域,并根据可靠的肤色信息建立或调整肤色模型。
由于肤色是特指人体皮肤所表现出的颜色,而人脸作为图像中最常出现的肤色载体,同时人脸也是人眼重点关注的区域,通过建立肤色与人脸之间的联系可以有效提高肤色检测模型的适应性。此类方法通常假设图像中至少有一个可靠的人脸,并且能够被有效地检测到[45]。Wimmer等学者[25]首次利用肤色与人脸在同一幅图像中的相关性,提出了可动态调整的肤色模型,混淆矩阵的行列式平均值可达78.1。同时给出了3种对人脸区域肤色建模的常用方法:立方体聚簇、椭圆型聚簇以及基于规则的聚簇表示法。其中,立方体聚簇是通过计算每个分量在样本中的平均值和标准差。由于肤色分布为类高斯分布,因此通常根据95%置信区间近似边界设定色彩分量的上下限:
lr=μr-2σr,ur=μr+2σr,
(10)
lg=μg-2σg,ug=μg+2σg,
(11)
lbase=μbase-2σbase,ubase=μbase+2σbase,
(12)
式中,σI和μI分别代表对应分量的标准差和均值,l和u分别代表对应分量的上下界。椭圆型聚簇是根据待检测颜色cp与人脸区域肤色均值μ之间的马氏距离(Mahalanobis distance)mp来确定概率的,其中马氏距离mp表示为:
mp=(cp-μ)TS-1(cp-μ),
(13)
如果马氏距离mp小于阈值t,则可以认为当前颜色属于肤色,反之则属于非肤色。

图6 Tan等学者[47]使用的检测人眼区域的方法
Yogarajah等学者[46]的研究也证实了以人脸颜色信息为依据,构建动态肤色模型的可行性。Tan等学者[47]使用机器感知工具箱(Machine Perception Toolbox)[48]中预训练的 Haar-GentleBoost模型检测人脸和人眼位置,并以两眼中心点为原点获取人眼椭圆区域,如图6所示。然后经过Sobel边缘检测去除纹理区域,并使用直方图与GMM的混合策略来生成肤色模型,需要对每一个检测到的人脸进行一次操作,最终将结果进行融合。但是由于人脸和人眼通常尺寸较小,仅根据其Haar-like特征进行检测容易受到画面中其他相似区域的干扰,从而产生较高的误检率。本方法的性能几乎完全取决于人脸和人眼检测的精确度,结果中的漏检和误检将容易导致无法建立准确的肤色模型,如图7所示。

(a)原图像(a)Original pictures

(b)错误检测结果(b)Wrong results of skin detection图7 Tan等学者[47]方法中误检人脸时产生的肤色分割结果
方晶晶等学者[49]首先使用Adaboost人脸检测器自动获取人脸的位置,并使用固定阈值排除明显不是肤色的区域,然后利用GMM来拟合人脸中心区域的色彩信息,从而形成适应性的肤色模型。Luo等学者[50]提出了一种基于人脸定位和面部结构估计的自适应皮肤检测器,其中排除了纹理区域,提取了人脸的中心平滑区域来生成皮肤模型。此方法构建的肤色检测器在TDSD数据集(Test Database for Skin Detection)[51]中性能表现良好,能得到93.74%的准确率和87.42%的检出率。但是本方法为了提高精度,引入了多个高斯模型来获取人脸区域的肤色分布,在对当前图像生成概率图之后,还需要再使用动态阈值法确定最终区别肤色与非肤色的概率阈值,因此该方法在提高结果的同时引入了大量的计算量和时间开销。此外,Mohanty等学者[52]和Shifa等学者[6]使用了RGB, HSV, YCbCr的联合色彩空间来优化基于人脸的肤色模型。
上述研究都论述了如何从人脸区域获取可靠肤色,但并未考虑如何避免与肤色颜色相近的复杂背景对肤色检测造成的干扰。Bianco等学者[53]根据皮肤区域是人体区域的一个子集的事实,提出了使用人体检测来优化肤色检测结果的方法,从而降低复杂背景的干扰,提供相对于单独使用人脸检测方案更可靠的肤色模型,可以在TDSD中得到更好的综合性能。该方法检测人体区域的过程如图8所示。

图8 Bianco等学者[53]所使用的人体区域检测示意图
基于人的面部与手部具有相似肤色的假设,Hsieh等学者[45]还提出了一种应用于手势识别的融合模型。该方法通过Viola-Jones[54]人脸检测器定位人脸位置,舍弃总像素数小于阈值的人脸区域以达到减弱误检现象的目的,使用人脸的中心区域生成肤色模型。在归一化和标准RGB的混合空间[r,g,R]中,依据人脸直方图分布规律形成自适应性的肤色模型,表现出对种族、肤质、偏色、光照环境等良好的适应性,整体过程可以实现640×480下39.5 FPS的处理速度,平均精度达到95.73%。基于高层语义的自适应方法与深度学习方法相比,在处理速度上和实现复杂度上具有一定优势。
在TDSD数据集中,本文定量地分析了上述几种自适应动态肤色检测方法,如表1所示。同时在表中也对比了一种常用的深度学习网络DeepLab v3+,使用文献[18]中的训练方法进行测试分析。实验结果表明,基于高层语义特征的自适应方法通常能获得比基于动态参数调整的自适应模型更高的准确率和综合性能。虽然Bianco等人[53]的方法可以获得0.854 0的综合性能,但是该方法在无法检测到人体时会出现性能衰退。Luo等人[50]的方法与前面的方法相比,可以实现较高的精确度,但会增大计算量,对实时性表现会造成一定的影响。与深度学习方法相比,自适应方法表现出较为接近的综合性能,在训练时间和计算成本上自适应方法占有一定的优势,同时减轻了对大规模肤色数据集的依赖。

表1 肤色检测方法对比
4 结 论
自适应动态肤色检测方法是对传统方法的改进,避免了过高的训练耗时,更加着重于实用性和易操作性,针对不同的应用场景可选择使用不同的自适应方法。基于高级语义特征的方法利用了肤色与人脸等部位之间的相关性,能够构建符合当前图像的肤色模型,但是容易受到人脸检测精确度、人脸非肤色区域的影响。在视频等图像序列中可以通过人脸跟踪建立随时间变化的动态模型。参数自适应调整参数的方法,虽然难以适应各种的复杂环境,但是在大多数应用场景中可以大幅提升传统方法的效率,满足实际使用需求。
在高性能、轻量化的深度学习技术全面产业化之前,实际非限制性场景中的肤色检测主要还是以自适应方法为主。随着硬件水平的不断增长,自适应方法可以结合部分深度学习技术,例如已经较成熟的轻量级人脸检测、跟踪网络来实现辅助检测;此外,可以通过使用更有效的色彩空间、形态学后处理步骤、不同的肤色检测算法组合来提高精度、降低复杂度。未来的肤色检测任务将会更加注重实时性的需求,与显卡等并行计算设备的结合也将是一个研究方向。
本文总结归纳了自适应动态肤色检测方法的研究现状,从基于色彩模型和基于人脸检测的自适应方法方面进行了详细介绍,分析了各种方法的优势和不足,为肤色检测研究人员提供参考。
猜你喜欢
管子学刊(2022年2期)2022-05-10
中北大学学报(自然科学版)(2022年2期)2022-05-05
管子学刊(2022年1期)2022-02-17
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
疯狂英语·新悦读(2020年4期)2020-06-18
好孩子画报(2020年3期)2020-05-14
小天使·四年级语数英综合(2019年9期)2019-11-09
动漫星空(2018年9期)2018-10-26
影视与戏剧评论(2016年0期)2016-11-23
