
面向Spark的批处理应用执行时间预测模型
2021-03-09 16:41李硕,梁毅
计算机工程与应用 2021年5期
李 硕,梁 毅
北京工业大学 信息学部,北京100124
Spark分布式内存计算系统已被广泛应用于大数据处理的众多场景中[1-2]。批处理应用是Spark系统支撑的一类主要应用,其特点是基于有向无环图(Directed Acyclic Graph,DAG)计算模型对静态数据集进行并行处理。批处理应用执行时间预测是保证批处理应用达到软实时需求、指导Spark系统资源分配、应用均衡决策以及保障批处理应用服务质量的基础。然而,如何精确预测Spark批处理应用执行时间仍然是一个开放的技术挑战。
近年来,针对大数据系统的批处理应用执行时间预测研究工作可分为两类,一是基于源代码分析的执行时间预测,二是选取相关因素构建执行时间预测模型。在基于源代码分析预测的工作中,PACE系统及Pablo系统通过分析源码中包含的每一类操作的执行复杂度和执行次数来预测应用的执行时间[3-4]。然而,这类方法属于基于源代码的白盒分析,不能适用于无法获取源代码的第三方批处理应用。在选取相关因素构建执行时间预测模型的相关工作中,文献[5]选取输入数据规模作为相关因素,针对Hadoop批处理应用,采用KNN方法构建批处理应用执行时间预测模型。文献[6-7]在上述基础上又增加了资源分配规模作为相关因素来构建预测模型,针对Hadoop批处理应用,文献[6]中应用首先通过资源监控模块对应用的计算及网络资源进行监控,获取到计算和网络资源后,利用SVM模型对应用的执行时间进行评估;文献[7]针对Hadoop批处理应用,利用LR模型来预测应用的执行时间,从而为任务调度奠定基础。然而,既有基于相关因素建模的工作均采用针对不同批处理应用统一建模的方法,且考虑因素较为单一。在Spark系统中,批处理应用的计算具有多样化特征,在相同的数据输入规模和资源配置下,应用执行时间具有较大的差异;并且随着输入数据规模和资源配置的改变,不同应用的执行时间变化趋势也差异较大。
针对上述问题,本文提出了一种区分应用特征的Spark批处理应用执行时间预测方法。该方法选择典型的基准程序测试集Hibench作为基础,首先根据Spark系统中批处理应用执行原理选取分类方法影响因素,利用斯皮尔曼相关系数从中筛选出强相关指标并构建Spark批处理应用执行时间分类方法;然后在每一类批处理应用中充分分析了影响应用执行时间的指标并利用主成分分析法(PCA)和梯度提升决策树算法(GBDT)对应用执行时间进行预测;最后当即席应用到达之后,先判断其所属应用类别继而使用已构建的预测模型来预测其执行时间。实验结果表明,与采用统一预测模型相比,本文提出的基于分类的Spark批处理应用执行时间预测模型可使得预测结果的均方根误差和平均绝对百分误差平均降低32.1%和33.9%。
1 Spark批处理应用的执行时间特征分析
1.1 Spark基本原理
在Spark中,RDD(Resilient Distributed Datasets)是分布式海量数据集的抽象表达,用以表示Spark应用在数据处理过程中所产生的分布存储于多个计算节点的数据。每个计算节点保存RDD的一部分,称为RDD分片。Spark计算模型如图1所示[8]。
在一个Spark应用中,根据计算逻辑的不同,可存在一个或多个作业。作业执行时,调度器会依据当前作业对RDD的操作类型将作业划分为多个阶段(Stage),并构建DAG图来对作业中的计算逻辑进行描述。Spark作业中存在依赖关系的Stage间串行执行,一个Stage内部包含多个任务来并行处理RDD数据。在DAG调度中划分Stage的依据是RDD之间的依赖关系,RDD之间的依赖关系分为窄依赖和宽依赖。窄依赖指父RDD的每个分区只被子RDD的一个分区所使用,例如图1中RDD1与RDD4间的操作。宽依赖指父RDD的每个分区都可能被多个子RDD分区所使用,例如RDD2与RDD3间操作。

图1 Spark计算模型
任务是Spark应用执行的基本单元,Spark中任务的执行过程为如下几个阶段:数据拉取、数据聚集、数据合并、数据计算、数据存储。Spark任务执行过程如图2所示:首先对任务所需数据进行远程拉取,任务每一批次拉取的数据会被放入用以进行数据聚合的操作的内存缓冲区中,当缓冲区内数据规模超过阈值时,将缓冲区内数据溢写至磁盘。数据在被不断拉取的过程中也不断进行聚集。接着读取本地数据至内存中并进行聚合操作。任务所需全部数据进行聚集完成后,合并后的数据被立即计算,计算结果写入内存缓冲器或溢写到磁盘中,当全部数据计算完毕,将数据进行合并,该任务执行结束。任务执行过程中,Shuffle的性能高低直接影响Spark批处理应用执行时间。由上文可知,Spark作业中存在依赖关系的Stage间串行执行,不同Stage的数据传输操作称为Shuffle[9]。Shuffle过程中,上一个Stage的每个任务将自己处理的当前分区中的数据相同key写入一个分区文件中,接着下一个Stage的任务从上一个Stage的所有任务所在的节点上将属于自己的分区数据拉取过来。从中可以看出,Spark任务执行过程是一个大量消耗内存资源、CPU资源、网络IO以及磁盘IO的过程。
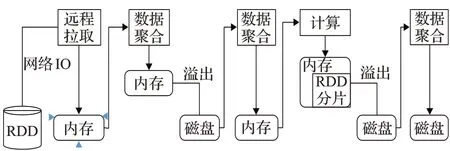
图2 Spark任务执行过程
1.2 Spark批处理应用的执行时间可分类特征分析
本节基于具有代表性的Spark批处理应用量化分析输入数据规模和资源配置对应用执行时间的影响,验证Spark批处理应用的执行时间具有可分类特性。首先选取了HiBench基准测试程序集中9个典型批处理应用:PageRank、Wordcount、Sort、Terasort、Kmeans、Bayes、Nweight、LR以及LiR,对批处理应用的执行时间进行分析。图3~5分别给出了不同输入数据规模、CPU和内存配置下,Spark批处理应用的执行时间比较。
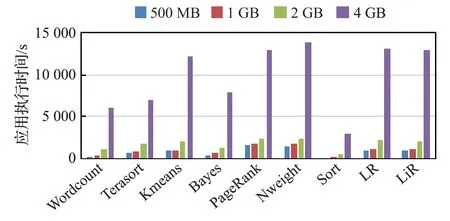
图3 不同输入数据规模下Spark批处理应用执行时间

图4 不同CPU配置下Spark批处理应用执行时间

图5 不同内存配置下Spark批处理应用执行时间
综上可观测到:(1)在相同的输入数据规模与资源量配置下,应用间的执行时间具有明显的差异。对于所有应用,例如当输入数据规模均为2 GB时,Kmeans、PageRank、Nweight、LR、LiR的执行时间达到2 000 s,Wordcount、Terasort、Bayes的执行时间约1 000 s,而Sort的执行时间仅约200 s。虽然不同应用的执行时间各不相同,但这些应用的执行时间呈现较为明显的值域分布。(2)变动应用输入数据规模或资源配置情况下,批处理应用执行时间的分类具有稳定性。例如Kmeans、PageRank、Nweight、LR、LiR应用在不同的数据规模、资源配置下运行,执行时间呈现出相似的变化趋势特征。由此可推断,应用执行时间的分类结果基本不受应用输入数据规模和资源配置的影响,Spark批处理应用执行时间具有可分类的特征。
2 Spark批处理应用执行时间分类方法
本章给出Spark批处理应用执行时间的分类方法。由于HiBench基准测试程序集涵盖了Spark主要应用领域中的核心数据操作,具有全面性和普遍性。因此本文仍选取1.2节中9个典型批处理应用作为测试应用:PageRank、Wordcount、Sort、Terasort、Kmeans、Bayes、Nweight、LR以及LiR,上述应用代表图计算、智能搜索、机器学习等多个领域的核心数据处理操作。依据上述应用,首先选取影响分类的指标,然后基于所选指标给出应用分类方法。
2.1 备选指标的选取
显然,作为Spark批处理应用分类的指标应该具有稳定性,即所选取的指标在不同的输入数据规模和资源配置下,应呈现出较为稳定的量值,以保证应用分类的准确性。依据Spark批处理应用的运行特征,分别从Spark应用的计算特征和对资源使用的特征进行指标选取。
由1.1节Spark应用的运行特点可知,Spark应用的执行过程是一个大量消耗CPU、内存、磁盘I/O和网络I/O资源的过程。将根据上述特点在应用层和系统层选取影响Spark批处理应用执行时间的备选指标[10-11]。
应用层首先可以获取最直观的性能观察指标,本文选取的应用层指标如表1所示。

表1 应用层备选指标信息
从应用层的角度看,影响批处理应用执行时间的因素包括算子规模、算子类型的比例以及数据的变化规律。算子的规模和算子的比例可以体现应用的算法复杂度,其中窄依赖算子主要与计算操作相关,宽依赖算子涉及I/O通讯和内存操作。数据变化规律可以通过输入数据、中间数据以及输出数据的比例得出。显然,这些指标仅与应用本身有关,与输入数据规模和资源配置无关。
从系统的角度来说,与Spark批处理应用执行时间相关的资源包括CPU、内存、磁盘和网络。因此,本文选取的系统层指标如表2所示。

表2 系统层备选指标信息
Spark批处理应用执行过程会消耗计算资源、内存资源、网络和磁盘IO,对应着计算行为、访存行为以及通信行为。因此计算访存比和计算通信比可以直观反映出Spark批处理应用的行为特征。已知应用消耗的计算资源、访存资源和通信资源只与应用本身的操作算子有关,并且随着输入数据规模的变化,应用所消耗的上述资源也会出现相同的变化趋势。因此,计算访存比和计算通信比具有稳定性。
2.2 强相关指标的筛选
在进行后续分析之前,为了降低分类方法的复杂度,选用斯皮尔曼相关系数(Spearman’s rank correlation coefficient)作为相关性分析的方法,从备选指标中选择与应用执行时间相关性最强的指标。斯皮尔曼相关系数是分析两个变量间相关性的常用方法[12]。斯皮尔曼相关系数计算公式为:

其中,N表示观测值的总数量,di=xi-yi,其中元素xi、yi分别为Xi在X中的排行以及Yi在Y中的排行。
本文采用控制变量法,分别变化上述备选指标,得到Hibench中9个典型应用在上述条件下的执行时间。根据所得数据集,分别计算每个指标与应用执行时间的斯皮尔曼相关系数。首先对每个指标集合和应用执行时间集合X、Y中的所有值进行排序,同时为升序或者降序,然后将对应元素的排行相减得到一个排行差分的集合d,然后带入公式(1)进行计算。其中,与应用执行时间相关系数较大的性能数据如表3所示。
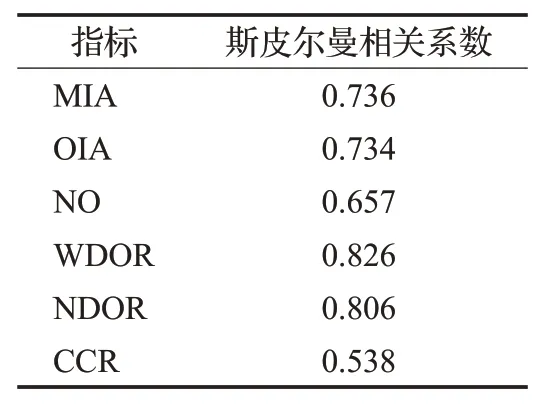
表3 强相关性能指标
选择斯皮尔曼相关系数值大于0.5的备选指标作为与应用执行时间具有较强的相关性的指标。根据该标准,本文选取了如下的指标作为Spark批处理应用执行时间分类方法的特征指标:MIA、OIA、NO、WDOR、NDOR以及CCR。
2.3 Spark批处理应用执行时间的分类方法
由于各种类型的特征指标的量纲不同,数值差异性较大。为了减少不同量纲的数值差异带来的影响,本文首先对指标数据进行归一化预处理,把所有的样本指标数据转化为(0,1)之间的数值。本文选用均值漂移聚类算法对应用执行时间进行分类[13]。均值漂移聚类算法通过将中心点的候选集更新为滑动窗口内点的均值来确定每个类簇的中心点。与K-means算法相比,均值漂移聚类会自动发现类簇的数量,但是需要用户首先设置好半径值r。随后,在迭代过程中寻找到能够使评价函数E最小的分类方式,计算方法如下:

式中,Pj表示类簇i的某个数据点,Oi表示类簇i的中心点,k为类簇个数,a为手动设置的权重,使得加号前后两部分在统一的数量集。
根据前文所述的均值漂移聚类算法可知,该算法中有如下的关键要素:样本的定义和生成、数据点距离的计算方法选取和半径值的设置。在样本的生成过程中,本文采用控制变量的方法,变化2.1节中与应用执行时间强相关的指标,寻找在当前的指标组合下,该批处理应用的执行时间。最终,模型中训练样本集的形式化定义如下:
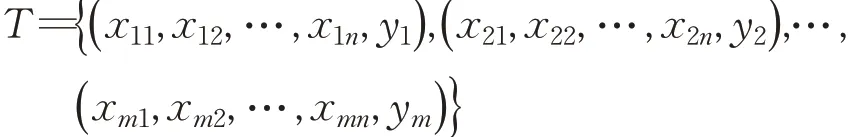
其中,xij表示第i个样本的第j个特征属性的特征值,m是样本的个数,n是特征指标的个数,yi表示在特征集{xi1,xi2,…,xin}下的应用执行时间。
对于数据点间距离的计算,常见的计算方法有曼哈顿距离、切比雪夫距离、欧式距离以及标准化欧氏距离等。然而曼哈顿距离、切比雪夫距离和欧式距离这三种距离计算方法都存在明显的问题:未考虑各个指标的量纲和数量级的差异。而本文提出的分类方法中特征指标的量纲和数量级差异明显,例如输出数据与输入数据比例的均值(OIA)与算子个数(NO)会有较大量级差异。因此,本文采用标准化欧氏距离来消除量纲和数量级对距离计算的影响。标准欧氏距离计算公式如式(3)所示:

其中,sk为两个数据点间第k个特征值的标准差。
筛选出影响分类方法的强相关指标共有6个,又选取标准化欧式距离作为数据点间距离的计算方法。因此在一个6维空间里,两点间的距离区间为[0,6],约为[0,2.5]。因此,本文在设置半径值r时,分别设置半径值从0变化到2.5,步长为0.05。选取有代表性的输入数据规模和资源配置进行测试,运行均值漂移聚类后计算聚类划分评价函数E的值,结果如图6所示。
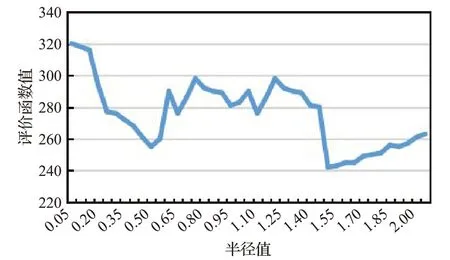
图6 不同半径值下的评价函数值
从图6中能够看出,当半径值从0.05升高到0.5时,随着半径值的增加,E值呈下降趋势;当半径值从0.5升高为1.5时,E值呈波动趋势;当半径值从1.5升高为2.5时,E值呈上升趋势。其中当半径值为1.5时,E值处于最低值。这是因为当半径为0时,每个数据点各自为一类,类簇数量k值最大,使得E值很大;随着半径值增大,虽类簇数量k减小,但每类中非中心点到对应类簇中心点距离和增大,因此E值呈现波动变化;当半径值从1.5升高为2.5时,每类中非中心点到对应类簇中心点距离和大幅度增大,E值呈上升趋势。
3 Spark批处理应用执行时间预测模型
第1章证明了常见的Spark批处理应用具有可分类的特征,并从应用层和系统层筛选出强相关指标构建分类方法,接下来将在每一类应用中首先利用PCA来提取影响应用执行时间的主成分,然后利用GBDT来建立Spark批处理应用执行时间预测模型。
3.1 预测模型的备选指标选取
首先根据1.1节Spark应用执行流程来筛选出所有可能影响应用执行时间的参数。根据Spark应用执行流程可以看出,影响应用执行时间的配置参数主要包括应用属性、Shuffle相关、内存管理、执行行为和资源调度等,因此本文列举出备选配置参数集如表4所示。
3.2 预测模型的构建
在样本的生成过程中,变化应用的输入数据规模以及配置参数的组合,寻找在当前输入数据规模以及配置参数下,该批处理应用的执行时间。最终,模型中训练样本集的形式化定义如下,对于每一类应用L,样本数据集可以表示为:

其中,xij表示为类别L中第i个样本的第j个特征属性的取值,m是样本的个数,n是特征指标的个数,yi表示在特征取值{xi1,xi2,…,xin}下的应用执行时间。
接下来本文首先对分类结果中的每个应用类别进行参数精简,得到精简参数集合,然后将每个应用类别的精简参数集合和输入数据规模进行组合,选取适当的预测理论工具进行预测。由于目前影响批处理应用执行时间的参数多样,且不同的参数之间的联系也非常复杂,PCA非常适用于这种特征量多样的数据集。PCA主要是利用降维的思想,把数据从高维空间映射到低维空间,同时使低维数据能够最大限度地保留高维数据的方差信息[14-15]。首先将样本中的特征值按列组成m×n的矩阵,为了避免计算结果受指标量纲和数量级的影响,需对上述矩阵进行标准化处理,计算相关矩阵并求取相关矩阵的特征根、特征向量、贡献率和累积贡献率。累积贡献率表示前k个主成分从所有备选指标中提取出的信息量。在本文的实验中,前5个主成分包含总信息量的90%,说明前5个主成分足以说明问题。因此选择5个主成分作为Spark批处理应用执行时间预测模型的主成分。

表4 预测模型的备选参数集
GBDT是一种模型树,具有强大的预测能力。核心是在每一次迭代中,后一个弱分类器训练的是前一个弱分类器的误差,且沿着最大下降梯度的方向[15]。GBDT调参时间短,预测准确率较高,且不容易出现过拟合现象。可将GBDT视为一个将多个弱分类器线性组合后对数据进行预测的算法,该模型可以表示为:

其中,b(x;γm)为基函数(即单个弱分类器),γm为基函数的参数(即弱分类器中特征的权重向量),βm为基函数的系数(即弱分类器在线性组合时的权重),f(x)就是基函数的线性组合。
GBDT算法中典型的损失函数包括均方差损失函数、绝对损失函数、Huber函数和分位数函数。本文分别选取有代表性的输入数据规模和资源配置来测试不同损失函数的预测精度,从而选出最合适的损失函数。测试结果如表5所示。

表5 GBDT在不同损失函数下的预测精度
由表5可知,绝对损失函数的预测精度最好,因此本文选择绝对损失函数作为GBDT的损失函数。
3.3 即席应用的类别匹配
本小节将介绍针对用户提交的即席Spark批处理应用如何进行类别匹配。即席应用的类别匹配流程如算法1所示。
算法1即席应用的类别匹配
输入:输入数据集合DS={ds1,ds2,…,dsn}批处理应用分类结果中类簇中心点集合O={O1,O2,…,Om}。
输出:即席应用所属类簇。
1.i=0,j=0,MinDis=∞
2.F=[]//用于收集Spark批处理应用执行时间分类方法特征指标的集合
3.Whilei<ndo
F[]i=collectFeature(dsi)//收集即席应用在输入数据集dsi下分类方法的特征指标4.end While
5.P=mean(F)//计算上述特征指标值的均值,得到数据点P
6.Whilej<mdo//找到距离数据点P最短的类簇中心点Oj
7.d=calDistance(P,Oj)//计算数据点P和类簇中心Oj的距离
8. Ifd<MinDis
9.MinDis=d
10.end If
11.end While
12.returnj
当用户提交新的Spark应用时,首先将该应用运行在一组小规模输入数据集DS={ds1,ds2,…,dsn}下,对于每个输入数据集dsi,分别收集Spark批处理应用执行时间分类方法的特征指标MIA、OIA、NO、WDOR、NDOR、CCR。随后分别计算这些指标的均值作为最终的特征指标,生成数据点P,随后对于分类方法中各个类簇的中心点Oj分别根据公式(3)计算距离d。最终,将使距离d最小的类别j作为该应用的类别。
4 性能评测
4.1 评价指标
为了评估Spark批处理应用执行时间预测模型的性能,本文选择均方根误差(RMSE)和平均绝对百分误差(MAPE)来衡量模型的预测精度。其中,均方根误差(RMSE)对预测误差中的特大误差非常敏感,平均绝对百分误差(MAPE)可以衡量模型相对误差。其计算公式如下所示:

其中,N为样本数量,yˆi为批处理应用执行时间预测值,yi为批处理应用执行时间真实值。
4.2 效果评价
本文选取随机森林算法(RF)、交替最小二乘(ALS)、支持向量机(SVM)、词频统计(Wordcount)以及K均值聚类(Kmeans)作为Spark批处理应用来评价本文提出的预测模型的性能。首先在变化输入数据规模与资源配置下,进行本文提出的预测模型与KNN、SVM、LR算法的性能对比[2-3,7];然后在固定输入数据规模与资源配置前提下,对本文提出的预测模型与无分类前提下、无PCA前提下的预测模型进行性能对比。
首先在固定资源量下,改变应用的输入数据规模分别为500 MB、1 GB、2 GB、4 GB,进行若干次实验,得到各评价指标值如表6所示。

表6 不同预测模型在改变输入数据规模下的预测精度
由表6可知,在固定资源配置、变换输入数据规模的条件下,本文提出的预测模型在所有测试应用的各组数据集上均比KNN获得了较低的RMSE和MAPE,经计算可得,与KNN相比,本文提出的预测模型使得RMSE和MAPE最大降低25.7%和28.5%。
然后在固定输入数据规模与CPU资源下,改变应用的内存资源分别为1 GB、2 GB、3 GB,进行若干次实验,得到各评价指标值如表7所示。

表7 不同预测模型在改变内存资源下的预测精度
由表7可知,在固定输入数据规模与CPU资源,改变内存资源的条件下,本文提出的预测模型在所有测试应用的各组数据集上均比SVM和LR获得了较低的RMSE和MAPE,经计算可得,与SVM和LR相比,本文提出的预测模型使得RMSE和MAPE最大降低50.1%和47%。
最后在固定输入数据规模与内存资源下,改变应用的CPU资源分别为2cores、3cores、6cores,进行若干次实验,得到各评价指标值如表8所示。

表8 不同预测模型在改变CPU资源下的预测精度
由表8可知,在固定输入数据规模与内存资源,改变CPU资源的条件下,本文提出的预测模型在所有测试应用的各组数据集上均比SVM和LR获得了较低的RMSE和MAPE,经计算可得,与SVM和LR相比,本文提出的预测模型使得RMSE和MAPE最大降低47.2%和41.3%。
前面已经进行了本文提出的预测模型与常见预测模型的性能对比,接下来将验证本文提出的预测模型中的分类方法和PCA方法的性能效果,即在固定输入数据规模与资源配置下,验证本文提出的预测模型与无分类前提下的预测模型PG(PCA-GBDT)、无PCA前提下的预测模型MSRG(Mean Shift-Random-GBDT)的性能对比,得到各评价指标值如图7、8所示。

图7 PG、MSRG与本文方法的均方根误差

图8 PG、MSRG与本文方法的平均绝对百分误差
由图7、8可知,在相同输入数据规模与资源配置下,与PG和MSRG相比,本文提出的预测模型均获得了更低的RMSE和MAPE。与PG相比,本文提出的预测模型使得RMSE和MAPE最大降低39.6%和35.5%;与MSRG相比,本文提出的预测模型使得RMSE和MAPE最大降低42.5%和37.7%。
综上所述,不管是KNN、SVM、LR模型,还是未分类前提下的PCA-GBDT模型、未PCA下的MSRG模型,本文提出的考虑了不同应用特征的批处理应用执行时间预测模型的预测精度均高于上述预测模型。实际结果表明,与上述预测模型相比,本文提出的基于分类的Spark批处理应用执行时间预测模型可使得均方根误差和平均绝对百分误差平均降低32.1%和33.9%。
5 结论与展望
本文提出了一种考虑不同应用特征的Spark批处理应用执行时间预测模型,并充分分析了影响应用执行时间的指标,同时评估了批处理应用执行时间预测模型的实际效果。通过与KNN、SVM、LR模型、未分类前提下的PCA-GBDT模型、未PCA下的MSRG模型进行性能对比可知,本文提出的面向Spark批处理应用的执行时间预测模型的预测精度更高。
猜你喜欢
今日农业(2021年8期)2021-11-28
科学导报·学术(2020年84期)2020-11-08
当代陕西(2019年13期)2019-08-20
能源(2018年7期)2018-09-21
电脑爱好者(2017年18期)2017-11-03
汽车零部件(2017年2期)2017-04-07
电脑爱好者(2015年21期)2015-09-10
电力工程技术(2014年5期)2014-03-20
中国卫生质量管理(2014年4期)2014-02-28
测绘科学与工程(2014年5期)2014-02-27
