
改进的生成对抗网络图像去噪算法
2021-03-09 16:41陈人和赖振意钱育蓉
计算机工程与应用 2021年5期
陈人和,赖振意,钱育蓉
新疆大学 软件学院,乌鲁木齐830046
数字图像在采集和网络传输的过程中,往往会受到一些随机信号的干扰而产生图像噪声,导致图像质量降低,从而影响人对图像的理解,所以有效地降低图像的噪声,提高图像的质量仍是图像处理领域的热点之一[1-2]。
图像去噪已经有很长的一段历史了,传统的图像去噪方法有空域滤波[3]和变换域滤波[4],空域滤波直接对图像的像素用滤波模板进行卷积,包括领域中值滤波[5]、均值滤波[6]等。变换域滤波利用噪声图像和无噪图像在频域的分布差异,将图像转换到频域进行处理后再将结果变换回空间域,从而获得去噪后的图像,常见的变换域有小波变换域[7]、傅里叶变换域[8]等。这些方法在一定程度上可以抑制图像的噪声,但修复结果往往会使图像纹理信息缺失,导致图像模糊。BM3D[9](Block-Matching and 3D filtering)利用自然图像中存在的自相似性,通过对相似块转换并进行加权处理得到目标块,取得了不错的去噪效果。CBM3D[10]是BM3D改进的彩色图像去噪方法,该方法利用了亮度-色度颜色空间的每个通道中高度稀疏的局部3D变换域中的滤波,这种去噪效果依赖相似块的选取,在图像去噪过程中常常存在一些复杂的优化问题。
近年来,深度学习在目标识别及检测等图像处理领域大放异彩,使得很多学者将深度学习模型应用于图像去噪。深度卷积神经网络拥有很好的学习能力,通过对噪声样本的学习,能够实现图像去噪的自动化与智能化。Burger等[11]提出多层感知器MLP(Multi-Layer Perceptron)将噪声图像映射到去噪后的图像成功实现图像去噪,Mao等[12]利用深度卷积编码器在对图像进行编码和解码的过程中学习噪声图像到去噪图像的分布来实现图像去噪,Zhang等[13]提出DnCNN网络来对图像去噪,通过残差学习并加入批量归一化将去噪任务扩展到通用性的图像去噪。为了应对更复杂的真实噪声,Zhang等[14]提出FFDNet去噪网络,FFDNet使用噪声估计图作为输入,权衡对均匀噪声的抑制和细节的保持,从而应对更加复杂的真实场景。生成对抗网络[15]相比于卷积神经网络多了一个判别网络,其采用博弈论的思想用判别网络来指导生成网络学习样本的分布。由于其有较强的样本模拟能力,在图像去噪领域取得了成功应用。张元祺[16]针对现有图像去噪方法存在的纹理细节丢失等问题,提出一种新的生成对抗网络作为去噪网络,通过采用大小不同的卷积核提取图像的多尺度特征进行去噪与筛选,采用跳跃连接以便更好地修复图像的纹理细节并加速网络收敛。谢川等[17]针对现有的蒙特卡罗图像去噪方法存在的高频细节丢失问题,设计了全卷积网络的生成对抗网络,网络的输入除了图像像素以外还包括多维辅助特征。损失函数采用包含平滑损失函数,并采用基于法向量方差和梯度大小相似度偏差的局部重要性采样技术用于网络训练。Chen等[18]提出一个新的两步去噪网络框架,首先利用生成网络生成输入噪声图像上的噪声样本,将得到的噪声样本与干净的图像构建成训练数据集,然后再用卷积神经网络训练该数据集得到去噪模型。
本文提出一种基于生成对抗网络的图像去噪算法,该方法可以很好地保存图像纹理细节,生成网络采用双层网络来增加网络的宽度,并引入一个全局残差,很好地保留图像的原始信息,避免训练过程中梯度消失,使训练更加稳定。对抗损失采用WGAN-GP损失(Wasserstein GAN losses),并在生成网络中加入重构损失提高生成图像的质量。采用CelebA作为训练数据集。相比于其他算法,本文提出了一种新的生成网络结构,可以直接从噪声图像中生成干净的图像,通过加宽网络而不增加网络深度的同时获取到更多的图像特征,降低计算成本。利用Wasserstein距离和Lipschitz连续性条件来改进对抗损失函数,有效地提高模型训练的稳定性,同时改进网络的输入模式,使其输入并不限制输入图像的大小,增加网络的灵活性。实验结果表明,本文提出的算法在去除图像噪声的时候能够很好地重建出图像的细节。
1 相关工作
1.1 生成对抗网络
生成对抗网络(GANs)最先是由蒙特利尔大学的Ian Goodfellow提出,被广泛地应用于图像处理的各个领域。其灵感主要来源于零和博弈的思想,即参与博弈的各方,一方的收益必然导致另一方的损失。GANs的强大之处在于它可以模拟任何数据的分布,它由两个网络组成,生成网络G(Generator)和判别网络D(Discriminator)。生成网络G用来模拟数据的分布,判别网络D用来分辨生成网络G模拟数据分布质量的好坏。GANs的优化目标函数为:

式中,pz是生成网络的输入,pdata是真实数据的分布。整个函数的目标就是让pz尽可能地去模拟pdata数据的分布。生成网络G的目标就是生成的图像尽可能地真实。判别网络D的目标就是将生成网络G生成的图像与真实的图像区分开。当判别网络无法区分生成网络G生成的图像与真的图像的时候,说明生成网络G生成的图像已经达到最优。
1.2 残差模块
随着卷积网络层数的加深,网络能够提取到的特征也更加丰富,但是,过深的网络在进行带步长卷积或者池化操作的时候会导致图像信息的丢失。残差网络的引入很好地解决了这个问题,残差网络通过跳跃连接将浅层特征直接传递到深层特征,从而只需要学习浅层特征与深层特征之间的差异。典型的残差模块[19]如图1所示。
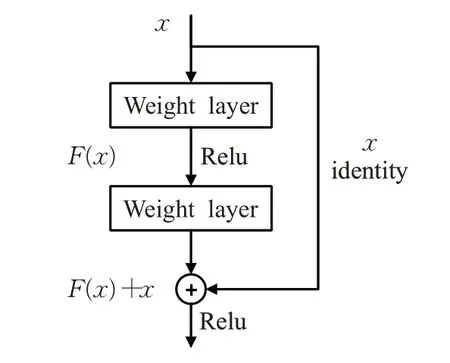
图1 残差模块
x为这个残差模块的输入,F(x)+x是残差模块的输出,通过跳跃连接将信息传递到神经网络的更深层,即使网络再深,图像的特征也不会丢失,有效地解决梯度消失和梯度爆炸问题,稳定了网络的性能。
2 网络结构设计及去噪模型
2.1 生成网络结构
图像去噪的本质实际上是一个图像翻译过程,即将含噪图像通过非线性映射到去噪图像。本文设计的生成网络由上下两层卷积神经网络组成以便提升网络的宽度,不同层的网络提取出更丰富的特征可以更好地映射到去噪图像。图2是本文构建的生成网络,上下两层为一样的结构,用来获取更多的图像特征。输入图像经过一个卷积层和Relu激活层,然后经过6个卷积块,每个卷积块由卷积层、归一化层、Relu层组成。其中通过一个全局残差,直接将输入传到最后一层特征前面并进行融合,最后再次卷积后输出去噪图像。
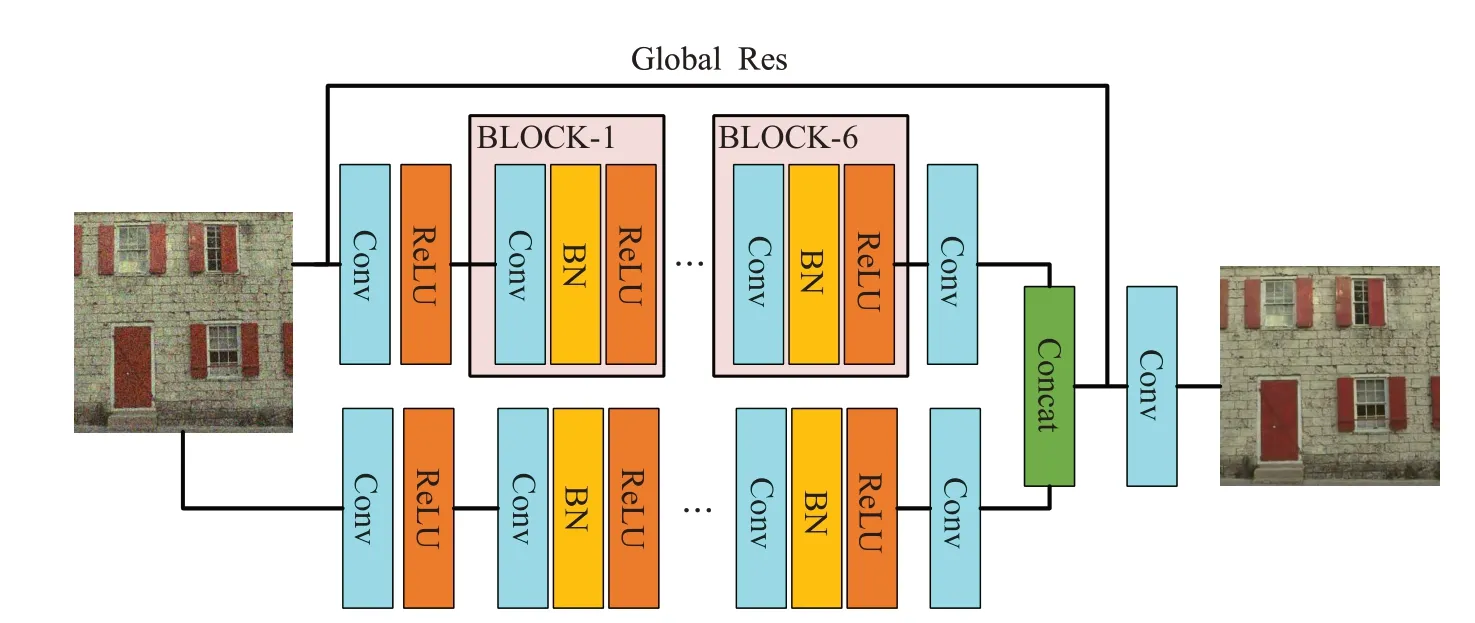
图2 生成网络模型
本文设计的网络具有输入灵活性,网络的深度为22层,除了最后一个卷积层,其余卷积层的卷积核大小均为64×3×3×64,最后一层卷积层的卷积核大小为64×3×3×3,该网络并不限制输入图像的大小,采用双层网络可以获取更多的图像特征,并引入一个全局残差将噪声图像的特征直接传递到输出,使生成网络能够保留更多的图像特征。
2.2 判别网络结构
判别器网络用来判别生成的图像与原图像是否相似,本文设计的判别网络为全卷积网络,对输入的噪声图像和清晰图像进行特征提取,如图3所示。
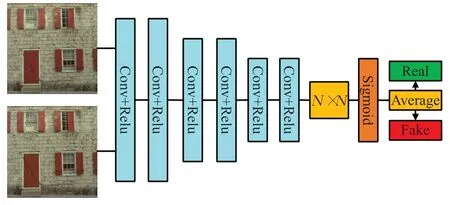
图3 判别网络模型
该判别网络共有6层卷积层,每一层都使用Relu激活函数,其中第二层和第四层卷积核使用步长为2的卷积核,最后一层激活函数为Sigmoid函数,前5层卷积核大小均为64×3×3×64,最后一层卷积核大小为64×3×3×1。判别网络输出的为一个N×N的矩阵,这个矩阵中的每一个元素代表原图中的一个区域块。元素的值表示生成图像区域块与原图像区域块相似度,然后求这个矩阵的平均值得到判别网络的输出,也就是整个生成图像与原图像的相似度。
2.3 损失函数
本文采用对抗损失和重构损失的加权和:

式中,LossWGAN代表对抗损失,LossR代表重构损失,对抗损失是WGAN的改进版本,WGAN使用EM(Earth-Mover)距离来比较原始数据与生成数据的分布,WGAN的优化公式为:
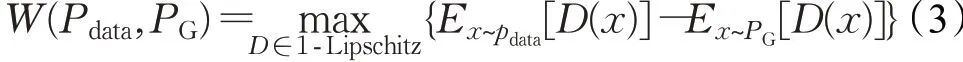
式中,判别网络D要符合1-Lipschitz条件,Pdata表示原始数据分布,PG表示生成数据分布。判别网络D为了满足1-Lipschitz条件,对参数weight做了一个weightclipping操作,即将weight限制在某个常数(-c,c)之间,这样就间接满足了1-Lipschitz条件,然而这样会导致weight几乎都集中在最大值和最小值上。WGAN-GP是一个带有梯度惩罚的WGAN改进版本。它增加一个额外的损失来限制判别网络D的梯度:

式中Pxˆ是对Pdata、PG之间的空间采样,||∇xˆD(xˆ)2||是判别网络的梯度。在判别网络充分训练之后,其梯度会稳定在1附近,通过加梯度惩罚可以稳定住梯度。
重构损失采用均方误差l2loss,均方误差通过计算去噪后的图像与原图像像素之间的平方差距,均方误差越小,说明去噪后的图像与原图越接近,去噪的效果也就越好。
3 实验验证
3.1 实验平台及数据集
为了对本文所设计的算法进行验证,实验的硬件配置为CPU为Intel Core i7,GPU为NVIDIA GeForce1060,内存为16 GB,软件配置为Window10 64 bit,CUDA9.0,python3.6,神经网络的搭建采用Google的深度学习框架Tensorflow1.14.0。
本文的训练数据集采用香港中文大学的开放数据集CelebA,随机地从中选取1 000作为本实验的训练集,并在训练集图像中添加高斯白噪声。测试集采用经典的Kodak24数据集,Kodak24由24张自然图像组成,大小为500×500。
3.2 评价指标
图像的质量包含图像的可读懂性和图像的逼真度,可读性往往与人类视觉的主观感受有关,图像的逼真度是指被评价图像与标准图像的偏离程度,偏差越小说明逼真度越高。本文采用PSNR(峰值信噪比)和SSIM(结构相似性)作为定量评价指标,PSNR是基于对应像素点间的误差,它通过均方差(MSE)进行定义:
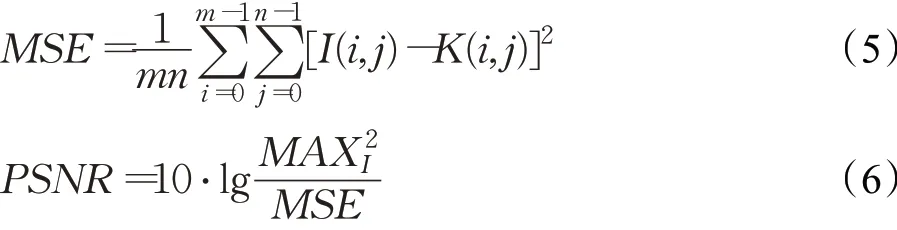
式中,MAXI表示像素点的最大值,由公式可知MSE越小,PSNR越大,说明修复的图像与原来越接近。SSIM分别从亮度、对比度和结构三个方面来度量图像的相似性,它的取值范围为[0,1],值越大,表明图像失真越小。
3.3 实验结果
本文采用的对比算法CBM3D、DnCNN和FFDNet都是当前具有一定代表性的算法。在Kodak24测试集上分别添加标准差σ为15、25、50的高斯白噪声。图像去噪后的PSNR和SSIM对应的实验结果如表1和表2所示。
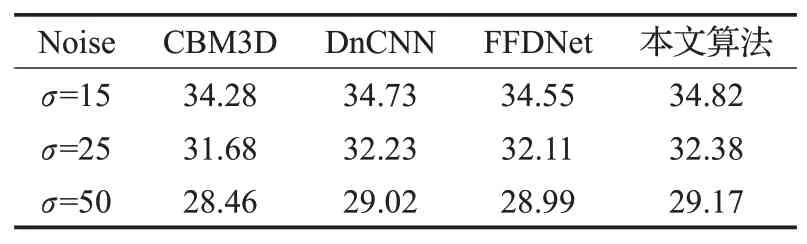
表1 不同方法的PSNR值
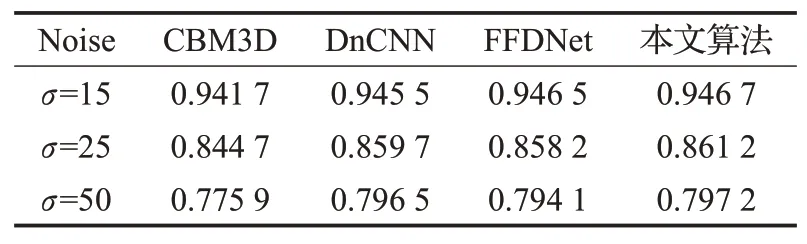
表2 不同方法的SSIM值
从表中的实验数据可以看出,在不同的噪声环境下,本文算法的去噪效果均要优于其他经典的算法,不管是PSNR值还是SSIM值相比其他算法都有一定的提高,说明本文算法对不同的噪声环境具有更强的鲁棒性。
一个好的去噪网络不仅需要能够很好地去除噪声,去噪的时间复杂度也是影响去噪网络能不能得到实际应用的一个重要指标。因此本文对比了CBM3D、DnCNN和FFDNet算法运行所用的时间。测试的图像大小为500×500,添加的高斯白噪声标准差为σ=25,所使用的GPU为GeForce1060,CPU为Intel Core i7-7700HQ。
从表3中的数据可以看出传统的图像去噪方法CBM3D在CPU上处理时间要低于深度学习算法,但不能在GPU上加速。得益于GPU的加持,深度学习算法在GPU上的速度要远远高于传统图像去噪方法。本文算法的处理速度相比于DnCNN与FFDNet不管是在CPU上还是GPU上均有一定的优势,这是因为本文算法通过增加网络的宽度而不是深度在减少网络参数量的同时,降低了计算量,提升了运行速度,并取得了不错的效果。这说明本文算法在实际应用中更具有优势。
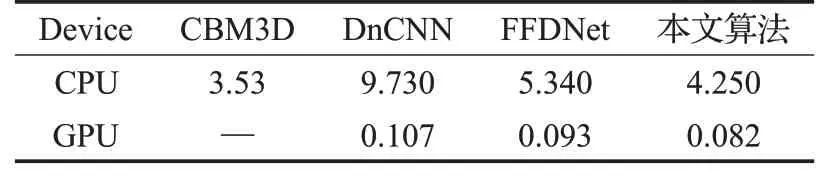
表3 不同方法运行时间对比 s
对去噪效果的评价中,人的主观感受也是非常重要的,为了对比本文算法与其他算法在主观视觉上的差异,从测试集中选取部分样本图并添加标准差σ=25的高斯白噪声进行测试,测试结果如图4和图5所示。

图4 不同算法去噪效果对比

图5 不同算法去噪局部效果对比
图4 (a)为原始不含噪声图像,(b)为添加高斯白噪声的图像,(c)为CBM3D算法去噪后图像,(d)为DnCNN算法去噪后图像,(e)为FFDNet去噪后图像,(f)为本文算法去噪后图像。图5为不同算法去噪后局部效果图,其中局部放大倍数为原图的三倍。从图中可以看出CBM3D算法在图像去除噪声后,部分图像纹理丢失,图像出现部分模糊状态。DnCNN算法和FFDNet在去除噪声的同时能保留图像的纹理信息,但是在图像的某些部分边缘会产生模糊的光滑部分,相比之下本文算法在去除噪声的同时能够得到更清晰的边缘,并且能够恢复出接近原图的纹理细节。
4 结束语
本文提出了一种基于生成对抗网络的图像去噪算法,该算法通过加宽生成网络来提取图像特征,并引入全局残差,有效地去除噪声的同时又很好地保留住了图像的细节信息。采用对抗损失与重建损失的加权和来对网络进行训练,不仅避免了网络训练中的梯度消失问题,还可以更好地恢复图像的纹理细节,使图像纹理恢复得更加自然。实验结果表明,本文提出的算法与其他去噪算法不论从视觉上的观察效果还是定量的客观评价,本文所提出的算法都取得了不错的效果。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
数学物理学报(2021年6期)2021-12-21
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2020年10期)2020-11-14
应用数学(2020年2期)2020-06-24
自动化学报(2019年6期)2019-07-23
电子制作(2019年11期)2019-07-04
数学年刊A辑(中文版)(2018年2期)2019-01-08
北京航空航天大学学报(2018年1期)2018-04-20
河南科技(2015年8期)2015-03-11
