
改进RetinaNet的伪装人员检测方法研究
2021-03-09 16:41邓小桐曹铁勇郑云飞
计算机工程与应用 2021年5期
邓小桐,曹铁勇,方 正,郑云飞,2
1.陆军工程大学 指挥控制工程学院,南京210000
2.中国人民解放军炮兵防空兵学院南京校区,南京210000
迷彩伪装是军事装备、工事、作战人员常用的隐藏手段,其通过迷彩纹理[1]降低目标与背景的区分度,破坏目标轮廓信息,以达到欺骗敌方军事侦察手段的目的。
迷彩目标检测是计算机视觉中的难点问题,目前成熟的研究较少。传统的检测方法主要将迷彩伪装看成特殊的纹理结构,设计特定的算法提取迷彩纹理,从而检测目标。Tankus等人[2]对旋转多个角度得到的凸算子响应进行融合,以获得迷彩目标检测结果。武国晶等人[3]提出利用目标具有的三维凸面的灰度差异来检测目标。Bhajantri等人[4]提出用强化的纹理分析方法检测迷彩目标。Sengottuvelan等人[5]利用图位置关系和特征构建图像块的树状图,聚类后选择最大的图像块作为包含迷彩目标的区域。以上的传统方法只利用了图像的浅层特征信息,检测效果不太理想。
近年来的研究成果大多将该问题视做基于深度学习的迷彩目标分割任务。基于此,文献[6]构建了密集反卷积网络提取目标的语义信息,与传统的方法相比检测效果得到了较大的提升;文献[7]构建了基于强语义膨胀网络的卷积神经检测架构,利用网络深层输出的特征图强化浅层特征图的语义信息,相比文献[6]的检测效果有进一步提升。但许多实际应用只需要得到迷彩目标的区域级定位,因此本文将迷彩目标检测问题看做一类较特殊的基于矩形框的目标检测问题来进行研究。
根据预测流程,可将目前基于深度学习的目标检测算法分为两大类:一类是以Faster R-CNN[8]为代表的基于候选区域的目标检测算法,如SPP-Net[9]、Fast R-CNN[10]等。这类算法首先通过区域建议算法生成可能包含目标的候选区域,然后通过卷积神经网络对候选区域进行分类和位置回归得到最终的检测框。另一类是以YOLOv3[11]为代表的基于回归的目标检测算法,如SSD[12]、RetinaNet[13]等。这类算法基于回归直接从图片中回归出窗口的类别和位置偏移量,得到目标的检测框。
本文以回归模型RetinaNet为基础,针对迷彩目标检测特点,对原模型特征提取网络和后处理方式进行了改进,构建了一种基于回归的迷彩伪装人员检测算法。其中在骨干网络Resnet50[14]的各个残差块之间嵌入视觉注意力机制模块,在通道和空间两个维度对特征进行加权;在筛选候选目标框时,用定位的置信分数作为非极大值抑制算法[15](Non-Maximum Suppression,NMS)中的排序标准,有效提高了算法取舍预测框的准确度。本文的工作是基于文献[7]中的迷彩伪装人员数据集进行的。为了增加数据和迷彩图案样式的多样性,还对其进行了扩展。
1 迷彩伪装人员数据集扩展
本文沿用了文献[7]中用到的数据集,以完全包括目标且最小化背景区域为目标,对原数据集中的分割标注结果用最小外接矩形框进行了重新标注,即根据图片中目标上下左右的坐标最值,将目标范围连接成平行于图片边缘的矩形框,以用于本文的研究。
原数据集中一共包含26种迷彩样式的2 600张图片。本文通过新搜集到的迷彩测试视频,新增加7种迷彩样式,共计33种迷彩样式(https://github.com/Dttong/camouflage-dataset),如表1所示。每种迷彩对应视频截取100张,共计700张图像。在截取图像时,为最大可能地反应真实需求,遵循了如下规则:

表1 迷彩样式名称
(1)选取的图像包含大、中、小的各种尺度目标;
(2)图像目标包含站立、卧倒、跪下、背身、侧身、正面等多种姿态;
(3)图像背景包括不同气候、不同地理环境、不同光照、以及遮挡情况等。
最终,本文将数据集扩展到3 300张图像,每张图像大小为500×282,对图像进行矩形框标注。部分扩充的图像及标注结果如图1所示,标注图中用黄色框标注目标,下方是对应迷彩名称。

图1 数据集标注示例
2 基于RetinaNet架构的检测模型
迷彩伪装是通过各种迷彩图案掩护目标,以降低其显著性的一种手段。经过迷彩伪装的目标大都与背景对比度低、遮挡情况严重并且轮廓特征被破坏,因此检测难度远大于常规目标。
基于迷彩的以上特性,本文在设计模型时关注如何有效提取图片中的迷彩特征。本文将注意力机制引入RetinaNet模型,把通道注意力和空间注意力串联嵌入特征提取网络Resnet50(https://github.com/Dttong/camouflagedataset)的每两个残差块之间,模仿人类视觉注意力转移机制,以期更好地抑制背景区域,提升模型对伪装目标的特征表示能力;模型通过特征金字塔网络[16]中的上采样和按元素相加操作将图像深层语义信息融合到各特征层中,得到具有各种尺度的特征集合,最后,使用全卷积神经网络[17]并行分类和位置回归,实现对目标的预测。此外,模型还通过Focalloss损失函数来解决训练中正负样本失衡的问题。本文网络结构和主要网络参数如图2所示。
2.1 注意力机制
即使经过伪装,人眼仍能发现大部分迷彩伪装目标,而注意力机制可以模仿人类观察事物的注意力转移过程,有重点地关注特定区域。同时,大量论文[18-22]证明了在网络结构中引入注意力机制可以提升网络模型的特征表达能力。因此,本文将CBAM(Convolutional Block Attention Module)[23]模块嵌入残差网络的每个残差块结构之间(如图2所示),以此将注意机制引入网络的通道和空间两个维度,模仿人类视觉,提高对迷彩伪装目标的特征表达能力。CBAM模块与残差结构的具体嵌入关系如图3所示。

图2 模型结构图

图3 CBAM结构图
2.1.1 通道注意力模块
对输入特征图在空间维度上进行压缩,分别使用平均池化和最大池化两种运算,最终得到两个一维矢量;再经由多层感知机运算后按像素点相加得到输出Mc;最后与输入特征图进行像素级的点乘得到F′,作为其后空间注意力模块的输入。
通道注意力模块能够反映输入特征图中响应最大、反馈最强的部分,突出该特征图中可能存在目标的区域。
2.1.2 空间注意力模块
空间注意力模块以通道模块最后输出F′作为输入,同样使用平均池化和最大池化,在通道维度压缩特征图,各生成一张二维的特征图。然后按照通道维度将两张特征图拼接,经卷积操作输出通道数为1的特征图Ms,再通过卷积运算使Ms与输入有相同空间分辨率。最后同样与输入F′进行像素级点乘,得到输出F″。
空间注意力模块对通道进行压缩,可以反映特征图上响应较高的像素点集合,引导神经网络更有针对性地提取特征。
图4 用热力图展示了通道注意力和空间注意力模块在网络c2层提取的特征图,热力图中颜色越红表明该区域对预测结果的贡献越大。图中(b)、(c)、(d)分别是c2层最后一个残差块中通道注意力和空间注意力模块处理前后的特征图,对应于图3中的F、F′和F″;(e)是c2层的最终特征图。可以看出,(c)突出了右侧区域,即反映了(b)中响应最强即最深色的部分,同时抑制了响应较弱即较浅的区域,一定程度上强调了可能存在目标的区域;而(d)强调了(b)中所有响应较大的像素点,即特征图中偏红色的区域,反映了相应较高的像素点集合。

图4 注意力机制
2.2 特征金字塔和定位、分类子网
特征金字塔网络(Feature Pyramid Network,FPN)是对卷积神经网络特征提取的一种增强,它使得高层的语义特征与底层细节特征在各种尺度的目标上相结合,本质上是对卷积神经网络特征表达能力的增强,能更有效运用在后续检测以及分割任务上。
图5 为模型利用特征金字塔网络的特征热力图对比,以c3和p3为例,经融合了语义信息后的p3,对图片的特征表达更为准确。

图5 特征层融合对比
本文使用两个全卷积神经网络(Fully Convolutional Network,FCN)来预测目标类别和位置信息。FCN网络由卷积层构成,不含全连接层,在预测时利用上采样和反卷积将卷积运算得到的特征图放大到输入图大小,实现对原图的逐像素分类预测,比传统方法的全图预测更高效;同时,网络不限制输入图像的尺寸大小,因此可以将特征金字塔网络输出的不同尺度特征图作为输入来进行预测。由于本文是检测任务,不需要对目标进行像素级分割,因此没有采用上采样和反卷积操作,而是利用FCN网络不限制输入尺度的特性直接将所有尺度特征集输入预测目标的位置坐标和类别。
2.3 Focal loss
目标检测模型普遍存在正负样本比例失衡的问题,导致在计算训练损失时,负样本所占比例过大,大量负样本的小损失相加,主导了损失函数的走向,而正样本提供的关键信息无法发挥正常作用。
Focal loss是一种改进的交叉熵损失,通过在原有的损失函数上乘上一个因子,削弱容易检测的目标对训练模型的贡献,从而解决上述类别不平衡的问题。

则典型的交叉熵损失函数如式(2)所示:


Focal loss提出,在典型交叉熵损失上乘上一个调节因子,其公式如式(3)所示:其中参数α能够让损失函数对不同类别更加平衡。实验证明,较容易检测的目标对整体的损失贡献较小,而不易区分的样本对损失贡献相对较大,这样的损失函数会引导模型努力去辨别不易区分的目标,从而有效提升网络的整体检测精度。
2.4 预测框过滤算法
在标准RetinaNet的NMS算法中,通过分类置信度过滤初始预测框得到可信的候选目标位置。但在伪装条件下,目标大都隐藏在环境中,与树木、草丛等相互遮挡,轮廓信息被破坏,且与背景的对比度极低,分类置信度整体上误差较大,难以以此抑制误差大的矩形框。
为解决分类置信度在伪装条件下误差大,对预测矩形框抑制效果较差的问题,本文在处理矩形框时引入定位置信信息交并比(Intersection-over-Union,IOU)[24],代替分类置信度对矩形框进行排序并过滤,抑制交并比达到阈值、相似度高的框,并比较两者置信分数,将更高的分数更新给定位置信度最高的框,循环直到处理完所有的矩形框,具体排序过滤过程如算法1所示。最终,具有最高定位置信度的框同时也有了最高的分类置信度。通过这种方式,降低目标与背景对比度低对训练造成的负面影响,得到更准确的预测。
算法1使用定位置信度来排序所有预测框,并使用规则更新其分类置信得分。
输出:D,包含分类置信得分的预测框集合。


3 实验及结果
实验时,按照5∶2∶3的比例,将伪装人员数据集分为训练集、验证集和测试集,类别包括人和背景两类。模型基于pytorch架构,在128 GB内存,12 GB显存NVIDIA GeForce GTXTitan X GPU的工作站上进行训练。本文将模型与目标检测8个经典模型进行了对比。并且设计了模块实验,验证IOU-Guided NMS和注意力机制的有效性。
3.1 模型评价指标
本文使用平均精度均值(mean Average Precision,mAP)作为模型的综合性能评价指标,反映了模型中各个类别检测精度的平均情况。其计算公式如式(4)所示:

其中Q是数据集中包含的类别数,AP是指某一类的平均精度,由精度p和召回率r共同决定,其计算如公式(5)所示:

其中:

即给定11个召回率值r,找出大于r的所有r˜中,对应的最大精度值p,然后计算这些p值的平均值,即为AP。
目标检测的预测结果分为四种情况,如表2所示。其中误检率是指误检样本数量FP在所有负样本数量FP+TN中所占的比率;漏检率是指漏检样本数量FN在所有正样本FN+TP中所占的比率,两者计算公式分别为式(7)和式(8),其中count(∙)是计数函数。通常在目标检测中,会根据任务需求来平衡误检率和漏检率。


表2 预测情况分类说明
此外,为了评价模型的目标定位准确性,引用IOU指标,如公式(9)所示,其中Boxp和Boxt分别表示最终预测框和真值框,area(⋅)表示区域面积函数。若IOU值越大,则说明预测框与真值框重合度越高,定位更准确。
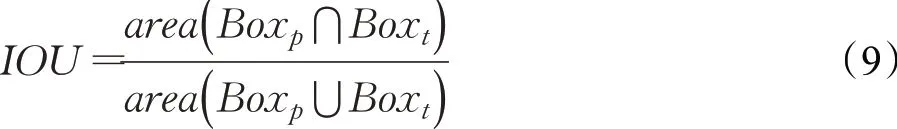
3.2 各种检测模型对比
实验对比了8种经典的深度目标检测算法在迷彩伪装人员数据集上的检测效果,包括M2Det[25]、SSD、Yolov3等表现较好的基于回归的模型和R-FCN[26]、Cascade R-CNN[27]、Faster R-CNN等基于候选区域的检测模型。
由实验结果图6、表3可看出,用基于深度学习的目标检测算法检测伪装人员是可行的,其中Ours指本文模型。本文使用对伪装人员的检测效果介于模型RefineDet[28]和M2Det之间的RetinaNet作为基础架构,改进后的模型效果比RefineDet提高9.3个百分点,比M2Det提高了4.6个百分点。这表明本文提出的改进能有效提升深度学习目标检测模型对伪装人员的检测性能。
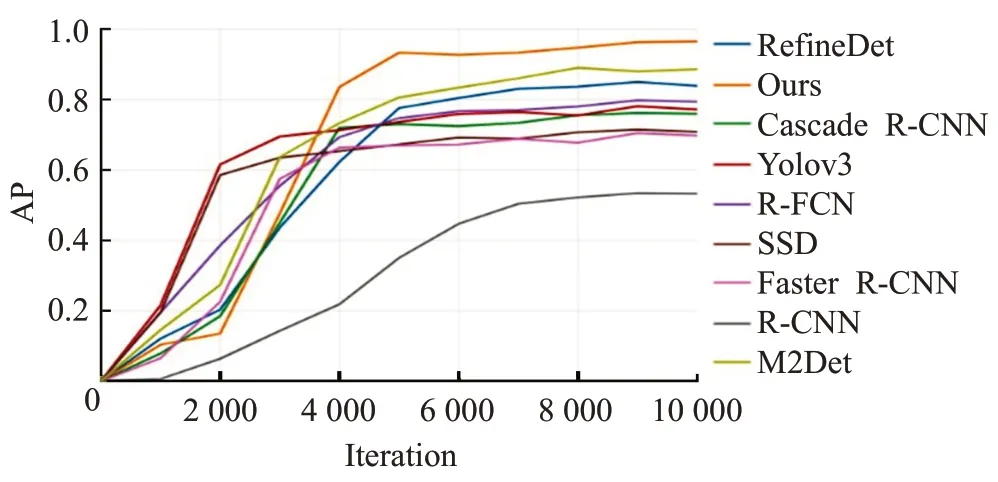
图6 不同模型mAP曲线

表3 不同模型结果对比
图7 展示了本文模型与基础模型RetinaNet的检测结果对比。其中的绿色框表示真值框,红色框是预测框,左上角黄色部分是预测类别及类别置信分数。可以看出,在图7(a)、(c)、(e)中,本文模型对目标的预测更准确,与真值框更接近。表4更加直观地说明了本文模型在目标定位上的优越性。

图7 检测示例对比

表4 IOU值对比
图7 (b)和(d)展示出了模型能够解决基础RetinaNet因为目标与背景对比度低而产生的误检或漏检问题。据统计,模型的漏检率相较于15%下降到10%,而误检率从13%上升到17%。这表明了针对迷彩伪装人员通常小而隐蔽的特点,本文模型能够有效提升对目标的发现率和定位准确度。
图8 列出了不同模型的检测结果对比,左上角黄色部分是预测框中距真值框最近的框的预测类别和置信得分。5组图片与图7中示例图片相同,第五张图的目标较大,各种模型均能成功检测,但本文模型在定位准确度上效果更好,与真值框最为接近;其余图片中目标尺度较小,且与背景对比度较低,是常见的伪装人员图片类型,大部分模型如SSD、R-FCN等对此检测效果不佳,而本文模型在检测精度和定位准确度上较其他方法均有较大优势。
3.3 算法改进模块的效能对比
为了验证注意力机制和预测框过滤算法的有效性,本文设计了4个对比实验,其结果如表5所示,常规NMS即传统的以分类置信度作为排序依据的算法。从表5可以看出,单独使用IOU-Guided NMS函数和注意力机制,检测平均精度分别提升了8.2个百分点和1.1个百分点。

图8 不同模型检测结果图对比

表5 模块验证精度对比
如图9所示,c2~c5是Resnet50的不同尺度特征层,图片包含绿林地场景下的较小目标,该图片目标与背景区分度很小。在加入注意力机制CBAM后的热力图中,目标区域更加聚焦,颜色更深,即响应更大,这表明了更强的特征表示,由此能够证明注意力模块对迷彩伪装目标特征的高效提取确实有效。

图9 热力图对比
此外,根据热力值聚焦的区域,可看出在特征提取时,目标的身体结构特征更突出。在较浅层时,提取的细节特征主要是身体部位,随着特征逐步融合,躯干特征更加明显。

图10 模块验证mAP曲线
图10 是4个对比实验的检测mAP曲线,观察可知,嵌入注意力机制后,网络训练速度更快,大约2 000次迭代后模型精度开始趋于饱和,损失下降逐渐收敛,而基础模型大约在5 000次左右趋于收敛。这表明注意力机制虽然对检测精度的幅度增长贡献较小,但其可以有效加快模型的训练进程,这是因为注意力机制可以很快聚焦图像目标,减少训练过程。
观察增加NMS算法的mAP曲线,可看出更新NMS算法在精度值上有大幅提升,这也是本文模型检测精度提升的主要因素。此外,更新的NMS算法还能加快模型收敛,这是因为IOU-Guided NMS注重位置的准确性,在回归阶段加快了迭代进程。
观察图中红色曲线,可以发现在IOU-Guided NMS算法后叠加使用注意力机制,模型精度增加了0.5个百分点,但模型的收敛速度下降到与基础RetinaNet相似,在以后的工作中将对注意力模块结构进行优化,进一步提升模型训练效率。
3.4 模型训练参数
图11 比较了本文模型与基础模型的训练损失曲线。训练时两个模型使用相同的参数,其中输入图像大小调整为300×300,最大迭代次数为10 000,批处理大小为8,学习率为0.000 5,IOU阈值为0.5,Focal loss中α值为0.25。如图11所示,本文模型比基础模型RetinaNet有更好的收敛性。

图11 Loss曲线对比
4 结束语
本文研究了基于矩形框的迷彩伪装目标检测问题,在RetinaNet检测框架基础上,将注意力机制嵌入基础网络结构并设计了基于定位置信信息的检测框过滤算法。与经典目标检测模型的对比实验验证了本文构建模型的有效性,改进模块实验说明了注意力模块的嵌入与过滤算法的改进在基础模型上明显提升了性能和收敛性。在后续的研究,将进一步优化模型结构并进行轻量化改造,重点提升模型的运行速度。
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
传媒评论(2017年3期)2017-06-13
中学生数理化·八年级物理人教版(2017年11期)2017-04-18
第二课堂(课外活动版)(2016年2期)2016-10-21
