
卷积神经网络及其分析在抑郁症判别中的应用
2021-03-09 16:41王凤琴柯亨进
计算机工程与应用 2021年5期
王凤琴,柯亨进
1.湖北师范大学 物理与电子科学学院,湖北 黄石435106
2.武汉大学 计算机学院,武汉435001
作为脑健康服务的核心部件,在线脑电分类能远程监测和评估脑障碍状态(如癫痫[1]和抑郁症(MDD)[2])而蓬勃发展。对于MDD,准确评估脑状态并及时跟踪其发展状态可以将其陷入危险和自杀的风险降为最低[3]。EEG通常是弱信号、强噪声和非平稳的混合体,对其准确分类仍然是一个亟需解决的问题[4]。几十年来,其活跃在两个研究领域:(1)预处理;(2)特征提取。预处理旨在去除脑电信号中的噪声与伪逆。在大多数情况下,噪声和干扰与患者密切相关,其去除即使理论上可行,也需要昂贵的人工处理[5];特征提取能够实现降维,并支持对感兴趣信号的有效探索[6]。在众多特征提取方法中,共有空间模式的精度最高,达到87.4%[7],矩阵分解方法精度达到86.61%,近年来,作为脑电特征提取的主导方法,时频分析的精度达到87.5%[8]。传统的预处理与特征提取方法不仅需要昂贵的计算量,而且分类性能仍落后于临床实践应用日益增长的精度需求。
EEG分类一直是脑神经科学研究和临床实践中的重要课题。现有工作大多依赖特征提取,最近,机器学习方法蓬勃发展。沿着这一方向最突出的工作介绍如下:Mumtaz等人[8]提出了一种基于小波变换的时频分解的分类方法,对MDD患者和健康对照组的诊断准确率为87.5%。为了有效地识别严重抑郁症的异质性病变,提出了一种基于脑电信号的频谱空间特征提取方法,达到平均81.23%的准确率[9]。与传统的支持向量机等分类器相比,卷积神经网络(CNN[10])在噪声数据分类方面有着明显的优势,在癫痫发作[1]和帕金森病[11]的识别方面取得了令人满意的性能,同时具有良好的抗噪声[12]。基于特征提取的机器学习通常呈现出高的计算密集性,只适用于离线脑电信号分类。
近年来,虽然神经网络在AI领域中发挥关键作用,但它们只是有限可解释性的黑盒函数近似器。如何判断并解释神经网络是否做出正确的预测[13]是一个极其重要的问题。当人工智能系统易于理解时,可帮助做出更好的决策,进而改进模型的设计,得出更重大的发现,深化对AI的信任。拿抑郁症分类来说,当神经网络通过识别能刻画脑疾病的关键特征而做出正确分类时,该系统被认为是合理的,反之,虽然最终结果识别正确,但是神经网络并没有分析出关键特征,而是外围因素甚至是由于噪声或者干扰的正确识别而做出决定,显然,该神经网络由于过高的假阳性不能满足医学要求。为此,需要在脑疾病发生时通过度量脑区与模型间的复杂性关系,以期对神经网络黑盒进行解耦。与现有的研究工作相比,本研究旨在寻找一种能够(1)对原始脑电信号进行准确的在线分类,(2)减轻预处理和特征提取的工作量,以及(3)对神经网络提供定量解释。
综上所述,本文的主要贡献如下:
(1)设计并实现一个基于云服务的在线脑电信号分类平台,该平台以一个CNN为核心,其模型训练于云服务器,而在本地网关上实现热部署与在线分类任务。
(2)提出基于AP聚类信息熵方法,实现分类器模型的定量分析服务,实现对神经网络黑盒进行解耦。
1 系统体系结构与实现
本文首先介绍了图1中所示的系统架构,接下来讨论了系统的核心部件——CNN的设计。
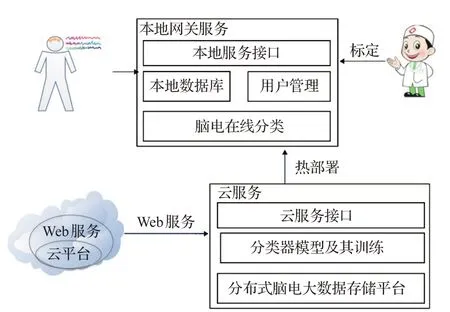
图1 系统体系结构
脑电时间片首先被传送到网关。网关主要完成模型下载和基于用户请求的数据上传功能,从云端下载最新训练好的分类器后,网关通过热部署加载到网关中。然后直接对脑电片段进行分类,并在相关智能设备(如台式机和智能手机)中显示分类结果。经过用户授权的脑电数据经医生校准后上传到云服务器。最后,云服务器将增量地对模型进行训练。管理员对训练后的模型进行评估后,保存相应的分类器模型文件供网关下载。
1.1 基于云计算平台的CNN
云计算平台提供按需和可扩展的存储,以及能够满足物联网需求的处理服务。云维护的主要功能如下:对分类器进行训练并评估分类器。
1.1.1 CNN网络结构
图2 显示出了CNN的体系结构,该CNN试图利用尽可能少的隐含层,同时获得高分类性能。分类器从一个独立的dropout层开始,接着是两个卷积层和一个最大池化层以及三个全连接层(模型的超参数通过贝叶斯超参数优化算法调优得到,并显示在图2中,关于卷积层,其参数格式为:过滤器数目@[感受野大小],所有全连接层FC的激活函数都为Sigmoid,其他层的激活函数显示在Activation中,None表示无激活函数)。CNN的最终Sigmoid激活函数输出特定脑电时间片的分类结果,主要设计要点总结如下:
(1)“高卷积层”旨在通过在一个卷积层上放置大量卷积滤波器来处理高维原始脑电片段,每个滤波器只处理一个通道数据。对于每个时间窗口,来自每个电极的每个时间序列数据(1 024)将被重塑为一个正方形矩阵(32×32),然后整个段将被组织为通道层叠的3D数据块。

图2 CNN的网络结构
(2)“沙漏(Hourglass)”全连接(FC)层块旨在快速减少神经元数量,减少模型参数数量。它包含几个FC层。输出层越近,神经元数量就越少。本研究中的“沙漏”全连接层块是最后三个FC层。
1.1.2 模型训练与测试
CNN采用动量SGD算法进行优化。为减少模型误差,本文采用一个非常小的动量衰减因子[14],其初始化策略沿用文献[15]中的设置,同时设置和文献[16]相同的批规范化。对样本空间进行洗牌后,将样本空间分为训练集、验证集和测试集。采用5倍交叉验证算法对训练集和验证集分类器的训练性能进行评估。用测试集报告分类性能。然后用反向传播算法训练CNN的参数[14]:
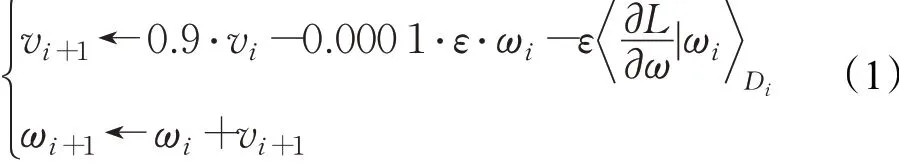
其中,i是迭代次数,v是动量变量,ε是学习率,是目标函数关于连接权值ω在Di批上的偏导数,其显示了当前批次的优化方向。
模型训练后,可以在测试集(或新EEG时间片)上进行测试。当输入经过Dropout层、两个卷积层和一对一映射层后,中间的三维数据块将被展平成一个矢量。矢量通过最后三个FC层,输出尺寸分别为300、60和1。最后,输出脑电片的状态。
云服务器加载最新的模型,从网关增量训练新的校准脑电数据。将有两种情况:分类性能将提高或降低。导致性能下降超过阈值(精度降低1%)的分类器将不会被保存。
1.2 CNN的复杂性解释
本节主要讨论了输入层的激活最大化,基础神经元的特征可视化将提供网络的全局视图,网络很少孤立地使用神经元,同时理解停留在主观层面。为此,通过度量输入模式的信息熵,以期验证模型决策的合理性,以及增强解释的客观性。
1.2.1 激活最大化
激活最大化是寻找一个给定的隐含层单元激活值最大的输入模式。第一层的每一个节点的激活函数都是输入的线性函数,所以对第一层来说,它的输入模式和滤波器本身是成比例的。形式化的,
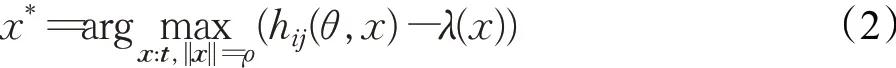
其中,θ表示CNN的模型参数,hij(θ,x)为神经网络中第j层第i个神经元的激活值,hij是输入x和模型参数θ的联合函数,λ(x)为输入x的正则项。x*为需要寻找的最大激活。该优化问题由于h不是具体函数,所以在大部分情况下为一个非凸优化问题。基于梯度下降法可以近似求解该问题,即至少能求解局部最小值,计算hij(θ,x)的梯度并沿着该梯度方向移动x:

当移动x的量小于某个预先设置好的阈值时,算法达到收敛。鉴于分类器的输入(第一层)是基于通道的,为了表征神经网络的激活模式,计算第一层的激活最大化值。因此,根据层的大小(20×32×32)对层的激活进行编码并计算为20个激活矩阵,其中每个矩阵表达了每个通道的最大化激活特征。
1.2.2 基于近邻传播聚类划分的信息熵
信息的基本作用就是消除事物的复杂性,信息熵刻画了信息的不确定性和复杂程度:
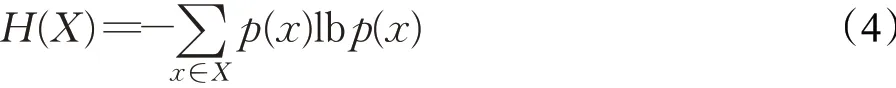
其中,X为随机变量,p(x)是随机变量X的概率。
图3 显示了两种不同划分计算的信息熵,属于同一分区的数据将归入相应的分区后利用公式(4)来计算信息熵。不同点在于传统方法假定神经数据服从均匀分布而进行等距离划分(在图3B中,数据被等分为6份),在数据样本点足够多的时候,计算结果会接近真实情况,但是,当数据不足时,这种等距离计算熵的误差比较大,无法有效度量随机变量的不确定关系;而聚类划分考虑到了序列自身的差异性而进行合理的划分(在图3A中,由于数据分布差异,被划分成3份,且每一份的划分区间不相同),刻画数据本身的特征进行信息熵的精确计算。在度量所有激活矩阵的熵后,被投射到大脑通道。根据10-20国际脑电系统,对应于大脑区域的大脑状态的平均特征进行可视化,脑区划分规则如表1所示。
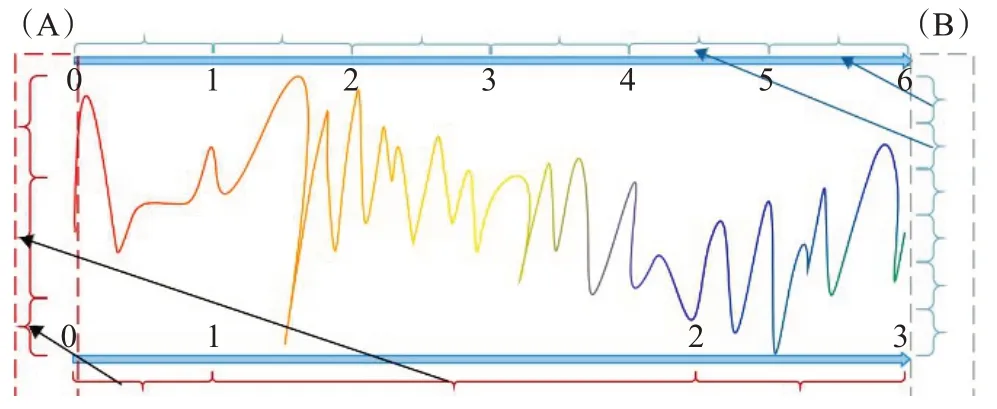
图3 基于近邻传播聚类划分(A)与传统(B)的信息熵计算

表1 基于10-20国际脑电系统的脑区划分
1.2.3 AP聚类算法
近邻传播(AP)聚类[17]是一种基于数据点间信息传递的聚类算法。与经典的聚类分析算法相比,它不需要在运行前确定聚类的个数,通过对每个样本点的竞争聚类中心进行迭代,以获得最佳的聚类性能。
AP聚类算法的输入是样本数据s[i,j](i,j=1,2,…,N)之间的相似性。本文用欧式距离表示相似矩阵S中的元素值,S对角线上的元素是一个参考矩阵P,它表示每个采样点被选为划分中心的概率。AP算法遍历样本数据,构造吸引度矩阵(responsibility)和归属度矩阵(availability),直到找到合适的聚类中心xk,迭代公式如下:
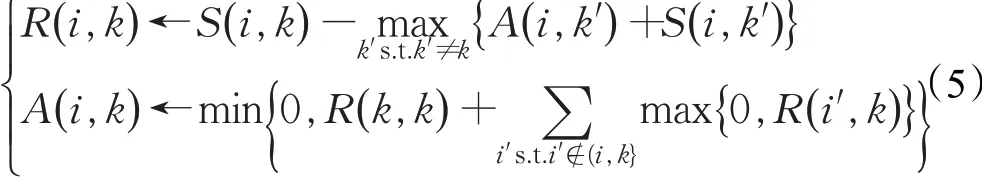
与K-means方法相比,该方法的主要优点是:(1)不需要人工初始聚类中心;(2)聚类中心是真实存在的数据样本,而不是虚拟的新数据样本;(3)对初始值不敏感;(4)结果的平方误差较小。
1.2.4 基于AP聚类的数据划分的信息熵
基于AP聚类的数据划分的信息熵(APM)的计算包括三个阶段。首先,对信号X进行排序(升序),加快AP聚类的收敛速度。其次,用AP聚类算法分别对变量进行分区,得到每个分区i的最大值和最小值的坐标,分区中心Ci和相应的分区半径Ri计算如下(Z表示一个分区中心的坐标):

求出数据的划分后,对落入不同划分的数据求相应的概率,进而求取该序列的信息熵。
为了刻画脑区与模型间的复杂性关系,首先获取每个通道的最大化激活特征矩阵(见第1.2.1节),所有矩阵展平成序列后计算其基于AP聚类的数据划分信息熵,该信息熵被投射为通道水平的复杂性,之后依据10-20国际脑电系统对脑区进行划分(表1),求脑区内复杂性的平均值作为脑区与模型间的复杂性。
2 实验
2.1 数据描述
公共数据集包含了严重抑郁症患者和健康对照组的脑电数据[8](MPHC),所有样本都采集自马来西亚塞因斯大学医院的34个抑郁症患者(17名男性,平均年龄=40.3±12.9)和30名健康受试者(21名男性,平均年龄=38.227±15.64)。该样本集已经排除有精神病症状、孕妇、酗酒者、吸烟者和癫痫患者的MDD参与者。健康对照组也排除可能的精神疾病或身体疾病。脑电图传感器按照国际系统10-20在256 Hz的频率下进行采集,该数据集选取前面20个电极(Fp1、Fp2、F3、F4、F7、T3、T5、C3、C4、Fz、Cz、Pz、F8、T4、T6、P3、P4、O1、O2、A2)的脑电数据。时间窗口设置为1 024(4 s);因此,整个样本空间被划分成18 442个片段(其中抑郁症的时间片:9 789,健康的时间片:8 653)。
2.2 计算复杂度
本文实验所用的测试环境为英特尔i7CPU(3.33 GHz)、24 GB运行内存和64 bit Win7个人电脑。本文所提出的分类器是基于子卷积神经网络和子全连接神经网络。首先讨论子卷积神经网络的时间复杂度。其时间复杂度正比于网络层数(L)及其相应的隐藏神经元个数(N)。整个子卷积神经络的时间复杂度计算如下:
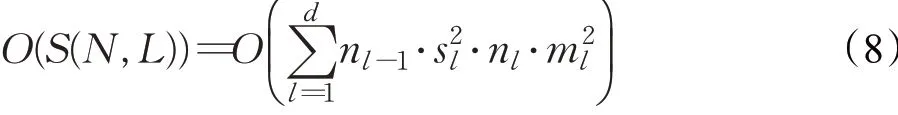
其中,l是卷积层的索引,d是深度;nl为第l层的过滤器的个数(也叫宽度);nl-1表示第l层的输入通道的个数;sl和ml分别表示过滤器的空间大小以及输出特征映射的大小(feature map)。
对于子全连接神经网络,假设网络的层数为L,每一层的神经元数为U,分类器的时间复杂度为O(UL)。因此,CNN的计算复杂度为O(S(N,L))+O(UL)。
2.3 优化器的影响实验
本节比较了CNN中不同的优化方法,包括本文的动量SGD、RMSprop[18]、Adagrad[18]、Adadelta[18]、Adam[18]、Adamax[18]和Nadam[18],图4显示了SGD获得了最好的性能,而三种优化方法(Adagrad、Adam和Nadam)在本研究中表现欠佳。Adagrad方法是在每个时间步中,根据过往已计算的参数梯度,来为每个参数修改对应的学习率,学习率总是在降低和衰减,模型的学习能力迅速降低,极有可能没有跨越局部最小值而性能低下,Adadelta方法作为Adagrad的延伸,解决其学习率衰减的问题,性能得到提升。基于动量的方法如本文的动量SGD和RMSprop优化方法在训练过程中优化的幅度跳过函数的范围,也就是可能跳过局部最优点。基于Adam的优化方法如Adam、Adamax和Nadam旨在快速训练结构复杂的神经网络,但是对于层数不多的神经网络(如本文网络)来说,越接近优化目标,其震荡更容易发生,造成性能不能满足要求。
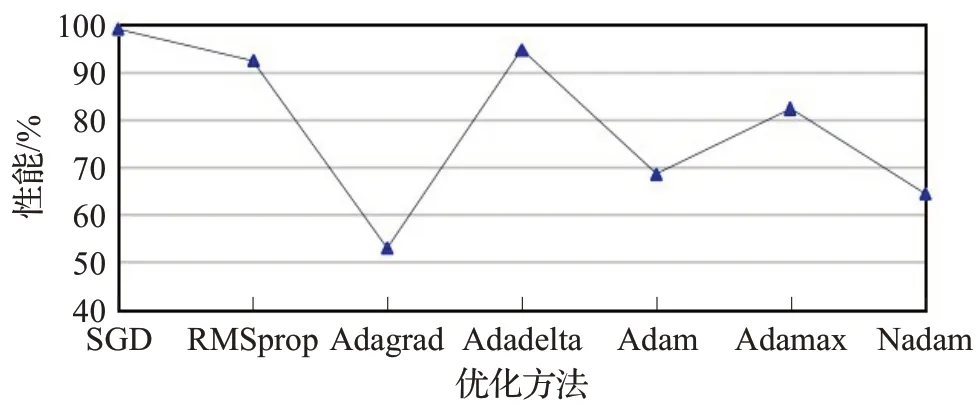
图4 不同的优化方法比较曲线
2.4 抑郁症分类性能评估实验
在评估分类器性能时,需要进行多次重复实验。在每一次重复实验中,都进行十次完整迭代过程,每个迭代过程都包括训练阶段(应用五次交叉验证)和测试阶段。在训练阶段,对特征矩阵进行洗牌,将其分为5个部分:4个部分作为训练数据,1个部分作为验证数据。然后将训练好的模型应用于测试集中,根据其敏感性、特异性和准确性报告分类器的平均性能。
图5 显示了分类器在严重抑郁症数据集上的学习曲线。分类模型在训练阶段,其在训练集和验证集上的准确率保持一致,并无明显的大范围间隔,同时测试集上优异的分类性能表明:分类器在该数据集进行抑郁症筛选时具有很好的泛化能力,并没有产生过拟合或欠拟合。
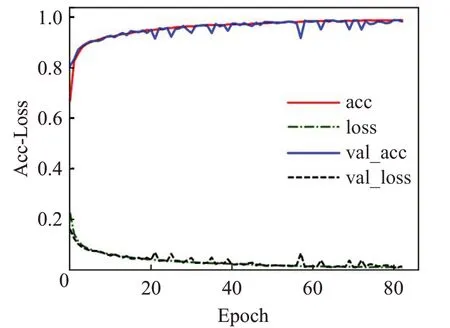
图5 训练和验证过程学习曲线
在同一数据集(MPHCs EEG数据)上,应用不同的分类器进行抑郁状态分类,其分类性能指标显示在表2中。这些分类器中,除了MLRW[8]之外,本文重新实现了几个代表性的神经网络模型,包括Resnet-16[19]、CapsuleNet[20]和LeNet[21],所有分类器只是修改了模型的输入(20×32×32)和输出维度(1),其他关于神经架构及每一层的超参数都未加修改。该表显示:(1)本文提出的分类器在所有分类指标上都最优,同时较高的敏感度和特异度也昭示出分类器不仅能有效地筛选出抑郁症患者,同时也能有效地筛选出正常人;(2)分类器的性能与其模型的层数不相关,比如层数更多的Resnet和CapsuleNet,并没有取得期望的性能指标,反而需要更长的时间进行训练,出现此情形的原因可能性是分类器过于复杂,在拟合数据时出现过分拟合,导致分类性能下降,如何使得分类器更好地拟合不同数据的非线性将极大地影响分类器的性能,而为了理解这一差异性将是理解神经网络黑盒的关键问题之一,这将作为未来研究的重点方向之一。
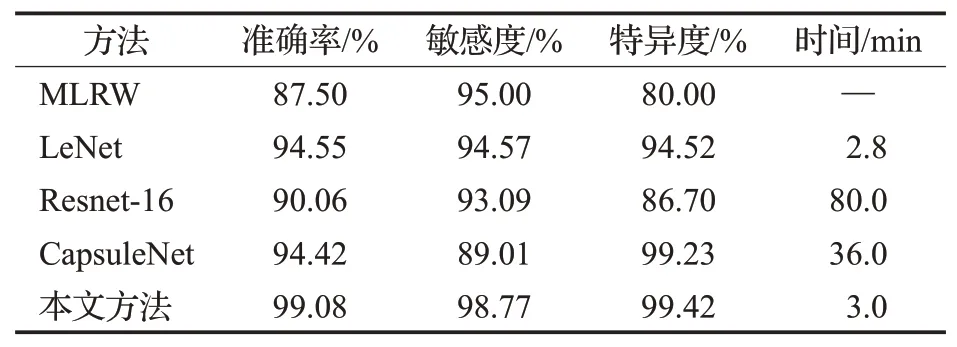
表2 相关方法分类性能比较
2.5 CNN的解释性实验
设计该组实验的目的是对CNN在进行抑郁症的分类任务时实现病理相关性解释,鉴于CNN的输入是通道相关的,为理解分类器处理脑电数据的机理,可视化了分类器第一层的激活最大化。根据输入层的大小(20×(32×32)),输入层的激活被编码成20个大小为(32×32)的激活矩阵,其中,每个矩阵刻画每个通道的特征。再利用AP聚类划分计算信息熵,获取每个激活矩阵的信息熵,并以通道级别投影到头皮地形图上。此外,在10-20个国际系统中,大脑区域对应的脑状态平均特征被可视化。
在分类领域,分类器总是倾向于根据差异较大的特征进行分类,而这些特征往往具有确定性。熵是随机变量不确定性的度量。显然,信息熵越大,变量包含的信息量越大,变量的不确定性也越大。解决分类问题的过程可以看作是降低不确定性(复杂性)以获得较低熵的过程。因此,计算每个激活矩阵的熵,找出CNN作用在哪些通道实现分类。
图6 显示了MPHC EEG数据上CNN的3D头皮地形图,通道级(A)和脑区级(B)。图6A中显示,Cz、T3、T4、T6等通道的熵值低于其他通道,说明该分类器主要是根据这些通道的电压幅值来区分抑郁和健康。图6B显示了与脑区水平相对应的三维头皮地形图,左颞叶和右颞叶显示了较低的平均熵值,证实了左颞叶和右颞叶脑区抑郁通道存在显著差异,这个结果同时也和数据提供者[8]的病理性解释一致。

图6 卷积神经网络的三维头皮地形图在通道级(A)和脑区级(B)上的可视化
3 结论
本文提出的方法在公开严重抑郁症数据集上能够获得高分类精度:抑郁症以99.08%精确度,98.77%敏感度和99.42%特异度进行判别,超过了现有方法的分类性能(基于相同数据集)。此外,通过基于近邻传播聚类划分计算信息熵方法,度量CNN在进行抑郁症分类任务时,对CNN网络的复杂性解释结果表明分类器有效地刻画了抑郁症的内在特征。
总体而言,本研究显示了物联网技术在脑保健领域的巨大潜力。该系统直接应用于原始脑电信号,无需进行预处理和特征提取,能精准、快速判别抑郁症状态。
猜你喜欢
军民两用技术与产品(2022年1期)2022-06-01
雷达学报(2017年6期)2017-03-26
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
现代电生理学杂志(2016年3期)2016-07-10
现代电生理学杂志(2016年4期)2016-07-10
现代电生理学杂志(2016年1期)2016-07-10
池州学院学报(2015年3期)2016-01-05
现代电生理学杂志(2015年1期)2015-07-18
电测与仪表(2014年15期)2014-04-04
