
一种基于个性化成对损失加权的新颖推荐
2021-03-22 03:45唐晓凤雷向东
小型微型计算机系统 2021年3期
唐晓凤,雷向东
1(永州职业技术学院 医学技术学院,湖南 永州 425000) 2(中南大学 计算机学院, 长沙 410083)
1 引 言
推荐系统作为一个研究如何有效地把系统中的实体连接起来的系统,在当今的企业中起着至关重要的作用.推荐系统的主要目的是为用户生成有趣的负项列表(与特定用户没有历史互动的项目),以使用户和项目的提供者从系统中受益[1,2].在推荐系统中,大多数工作主要着重于提高预测用户与项目交互的准确性,前提是假定准确的推荐可以最好地满足用户的需求.例如,以准确性为中心的系统将向观看过“权利的游戏-第1季”的用户推荐“权利的游戏-第2季”.但是,仅关注准确性会给用户和提供者带来负面影响,因为它可能会偏向于流行的商品[3].用户将不得不承担他们很了解的相同受欢迎的推荐,并且发现新奇有趣物品的机会更少.供应商,尤其是那些销售不流行的项目的供应商,将很难获得收入.更好的推荐系统还应考虑其他因素,例如“项目新颖性”[3].由于提倡新颖性会降低准确性,因此需要优化它们之间的权衡.以往大多数关于小说推荐的研究都采用两阶段重排序的方式来生成前N名列表[4].通常,重排序方法将首先训练一个注重精度的基本模型以生成候选列表,然后对候选列表重新排序以提供新颖的前N个列表.尽管重新排序通常是高效且灵活的,但存在两个主要限制.首先,他们没有经过端到端的训练,而是两个阶段的训练,这使得训练过程相当冗长,并且整个推荐并未同时针对新颖性和准确性这两个目标进行优化.其次,性能基本上受独立基础模型的限制.当基础模型高度偏向流行项时,其输出的候选列表也包含流行项,从而导致后处理的重新排名也有偏向.
此外,在训练基础模型时,大多数损失函数由于无法区分两种类型的负面项目(“未知负项”和“不喜欢的负项”)而存在问题.在推荐系统中,希望可以给用户推荐不知道其存在的“有趣但未知的项目”[5].推荐系统中常用的损失函数,如贝叶斯个性排名(BPR),对负项项进行统一处理,抑制所有预测的评级,而与否定,未知或不喜欢的类型无关[6].
另外,用户个人偏好未明确包含在损失函数中.大多数损失函数仅将目标评级作为输入[6,7].如果模型明确地集成到损失函数中,则可以更轻松地学习用户偏好.
为了提高系统中的新颖性以及处理损失函数的问题,在此提出了个性化成对新颖性加权(PNW)方法.该方法自然地将用户和商品的新颖性信息明确地集成到成对丢失函数中,从而形成了一个一阶段的新颖性推荐系统,并使基本模型能够有效地学习用户新颖性偏好.此外,它还有助于减轻“有趣的未知项目”与其他“不喜欢的项目”受到一样抑制的问题.由于用户对某个项目的不了解与该项目的新颖性成正比[8],因此,一个新颖的项目更可能是“未知”,而不是“不喜欢”.通过将新颖性引入损失函数,该方法能够根据负项的新颖性水平来降低或增加负项的损失.而且,上述在准确性和新颖性之间的权衡也可以变成双赢的解决方案,这意味着推荐不流行或仅有轻微下降的不流行的新颖物品.为了实现这一目标,利用了用户对新颖项目的个人偏爱.直观地,该方法尝试仅向对新颖性有强烈偏好的用户推荐新颖的项目,否则推荐新颖的项目会带来巨大的准确性成本[9].
具体而言,首先根据项目受欢迎程度来衡量用户和项目的新颖性.然后,采用改进的高斯RBF核函数对项目在新颖性方面与用户的偏好匹配进行建模.接下来,通过提升项目新颖性评分来进一步强调新颖项目.最后,为了将所有这些信息集成到损失函数中,设计了两种新颖性加权策略,将新颖性信息映射到适当的尺度以进行损失加权.总体而言,提出的方法旨在推广新颖的项目,并且该项目也符合特定用户的新颖性偏好.与普通物品相比,新颖的项目更加重要;新颖的匹配项比新颖的不匹配项更受重视.
2 相关工作
在这一节中大致介绍了现有的推荐系统相关研究工作.
新颖性在推荐系统中的重要性已得到公认.为了提高系统的新颖性,大多数作品采用了重新排序策略,对基本模型的输出进行后处理.PRA[4]引入了一种通用方法,通过重新排列前N个项目和下M个候选项目来提升长尾项目.通过只考虑前N+M项,PRA能够保持准确性.
除了常用的基于频率的新颖性度量外,一些研究还使用了其他新颖性定义并相应地改变了方法.在文献[10]中,新颖的东西是没有互动的餐馆.作者根据用户的求新现状,设计了一个推荐新餐厅的框架.
损失加权是训练过程中调整损失的一种直观、方便的方法,被广泛应用于处理其他问题,如不平衡类问题[11].在推荐系统中,损失加权主要是为了提高推荐精度.文献[12] 根据交互频率加权隐式反馈.更高的交互频率意味着更高的置信水平,因此在训练过程中,应该通过增加其损失来强调交互的重要性.在文献[13]中,采用基于等级的加权方案来惩罚在列表中排名较低的正项目.
3 背景介绍
在这一节中,首先介绍相关符号,然后给出了新颖性的定义以及在本文中使用的度量.并在此基础上,简要讨论了BPR损失函数的优点和局限性.
需要使用的符号总结在表1中.

表1 相关符号介绍Table 1 Symbol and itsdefinition
3.1 新颖性的定义
根据以往的研究[14],项目新颖性可以根据工作的重点进行不同的定义.在这项工作中,主要关注长期存在但不流行的项目.一个项目已经在系统中存在了一段时间,但它还不够流行,无法被大多数用户看到.然后,对这些用户来说,这个项目是新颖的[14](再未具体解释的情况下,新颖等于不流行).由于不流行的项目构成了许多系统的大多数,通过向适当的用户推荐这些项目,可以实现大量的潜在交易.此外,推广不流行的产品有利于用户和供应商,并提高市场竞争力.

(1)
对于项θi,公式(1)根据用户总数对频率进行归一化,然后对数缩放.对于用户θu,还包括反映用户对该项目的满意度的评分等级rui.因此,用户对新颖性的偏好与用户的过去项目的新颖性分数成正比,并通过用户的评分进行校正.
3.2 贝叶斯个性化排序(BPR)

相反,BPR将隐式推荐任务定义为一个分类问题.
(2)
在BPR中,σ(·)是sigmoid函数,输入是一对(u,i+,i-)具有i+的用户u和采样i-,其中i+∈Iu和i+∉Iu.
1)逐点损失函数的优点:首先,BPR成对的优化模型,一次使用两个项目,而不是在实例级别.此外,BPR除了对所有负项的预测得分均匀地抑制以外,还随机抽取负项,根据正负项对的相对差异来评估损失,从而捕捉用户对项目对的个性化偏爱.相对差异的概念是决定性的,因为负项的目标值不再像MSE一样为零.
2)BPR的局限性:然而,BPR并非完美无缺.当一个负项在训练中有更高的预测评分时,BPR惩罚更严厉.但是,否定项可以是未知项,但不一定是不喜欢的项.在这种情况下,较高的预测评分表示用户可能对这个未知的负项感兴趣,应该推荐它.为了缓解对有趣的“未知项”错误惩罚的问题,在BPR中引入新颖性评分有利于区分“未知项”和“不喜欢项”.此外,用户偏好并没有明确地包含在BPR损失函数中.如果模型明确地集成在损失函数中,那么它可以更容易地学习用户偏好.
为了解决这些问题并提高系统的新颖性,所以提出了个性化的成对新颖性加权(PNW)方法.
4 提出的模型概念
4.1 用户和物品的新颖性调整
在这一部分中,首先对用户和项目新颖性进行建模,并将其调整为适合于后续损失加权的形式.
1)用户新颖性偏好:假设每个用户都有一定的新颖性兴趣范围.例如,喜欢小众项目的用户对大众项目的兴趣会降低.为了模拟用户的新颖性偏好,使用的方法是均值和标准差.
(3)
θu的值越大,对应于新颖性偏好越高.σθu的值显示了该用户的新颖性兴趣有多大.有了这些用户新颖性偏好的统计数据,可以测量用户和项目之间的新颖性匹配得分.采用带可控参数λ的高斯径向基函数(RBF)核来度量新颖性匹配分数.
(4)
θu和θi是用户和项目的新颖性分数.这里的λ是一个超参数,与σθu一起,控制用户新颖性偏好范围的扩展程度.大多数真实世界的数据集,由于其极端的稀疏性,由许多用户组成,他们有狭隘的新颖性.λ≥1可以扩大计算出的新颖性偏好,允许新颖项具有更高的匹配度.从经验上讲,λ∈[1.5,2.5]在这里的所有的实验中都很有效.第四节详细讨论了λ在系统中的作用,新颖性匹配分数的取值范围为M(u,i)∈[0,1].
4.2 个性化新颖性评分
在这一部分,介绍了个性化的新颖性评分.首先,个性化新颖性评分应满足两个要求:
1)如果一个项目更好地满足用户的偏好,它应该有更高的个性化新颖性评分.
2)当一个新的项目和一个流行的项目到一个特定的用户有相同的距离时,新项目应该比流行项目有更高的个性化新颖性得分.
最后,个性化的新颖性评分不仅应强调新颖性,而且应正确反映出某项匹配用户新颖性偏好的程度.
首先将归一化的项目新颖性评分提高到公式(5),从而得到一个高阶的新颖性评分.这个高阶分数是以指数级强调新项目,而不是原来的线性.因此,与普通项目相比,新项目被赋予了更高的价值.
(5)
然后,通过合并“高阶新颖性评分”和“新颖性匹配评分”计算个性化新颖性分数,如公式(6)所示:
(6)
个性化新颖性分数包含两个决定性因素:对新颖的强调和个人新颖性偏好.因此,过此单个分数即可实现两个要求.
4.3 个性化成对新奇加权(PNW)
在这一部分中,将个性化新颖性得分π(u,i)转换为用于BPR的损失权重Wloss.当Wloss=1时,不用损失权重.经验上,当使用更大的损失权重,如Wloss∈[1,10]时,损失权重的大部分值都会落在Wloss∈[0,2]区域,最终会过分强调原始损失.此外,负损失权重应限制为0,因为不应更改生成的梯度方向.

第1个损失加权策略称为Gamma匹配(PNW-G),由于其Gamma参数而具有很高的灵活性,可以通过另外两个超参数获得更好的性能. 第2种策略称为“批归一化匹配(PNW-BN)”,它使用批归一化来生成权重以进行损失加权,并且几乎没有超参数.
1)伽玛损失加权(PNW-G):首先对每个用户π(u,i+)和π(u,i-)的正和负项的个性化新颖性评分进行建模,如前文所述 .然后,通过以公式(7)获得伽马损失权重.
(7)
此处的超参数γ用于控制损耗加权的强度.当gamma设置为0时,加权后的BPR会减小为原始BPR损失函数. 在[π(u,i+)-π(u,i-)]的大多数值较小的情况下(例如0.005),损失加权在训练中几乎没有影响,而更大的γ值可以帮助放大.
(8)
当Gamma损耗加权策略在原有α和λ的基础上增加一个参数γ时,可以获得更高的性能.
2)批量归一化损耗加权(PNW-BN):PNW-BN不依赖γ来调整损失加权的强度,而是采用批量归一化来自动调整.如公式(9)所示.
(9)

3)两种情况:这些损失加权策略涵盖了两种情况,并在以下直观的层面上进行了讨论:
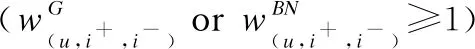
4.4 与其他损失加权法的关系
所提出的方法是用于新颖性推荐的一般成对损失加权策略.损失函数中同时考虑了新颖性和个人偏好,使得基本模型能够更好地在预测精度和推荐新颖性之间进行权衡.先前的研究“AllRank-Pop”[15]也使用了损失加权方案来改善推荐中的不受欢迎程度,在一般情况下与提出的方法类似.事实上,AllRank-Pop是一个更通用的“ALL-Rank”损失加权模型的改进版本[16].它旨在设计一个“无偏流行程度分层测验”,而新颖性的损失权重并不是主要关注点.在AllRank-Pop中将只对一种项目(正或负)与过去用户数的倒数成比例,而对剩余的一种商品按固定值加权.该模型在3个方面与AllRank-Pop不同.
1)将损失权重整合到成对损失函数中,同时使用逐点MSE.
2)提出的模型没有区别对待正项和负项,每个项目都将以相同的方式加权.然而,在AllRank-Pop中,正项或负项将被分配一个固定的权重.
3)提出的方法考虑了个人偏好.然而,AllRank-Pop损失权重在全局范围内,但是个人偏好被排除在外.
具体的比较请参考实验部分.
5 实 验
在这一节中,将描述实验的设置,并详细讨论实验结果.
5.1 实验环境与数据集
整个实验是在一台Windows 10 64位操作系统的台式机上进行,电脑配置为英特尔I7 3.5Ghz处理器,16GB内存,以及英伟达GTX 2080Ti显卡.实验采用python 3.7编程语言实现.
在此使用了3个公开的数据集来评估模型的有效性:论文推荐数据集Citeulike-a[17],视觉推荐数据集Pinterest[18]和电影推荐数据集MovieLens-1M[19].这些数据集的描述汇总在表2中.Citeulike-a和Pinterest是非常稀疏的设置,ML-1M更密集.

表2 3种数据集的介绍Table 2 Three data sets
5.2 基础模型设置
为了评估该方法的通用性,选择了3个以准确性为重点的模型作为基础模型:广义矩阵分解(GMF)[20],神经矩阵分解(NMF)[6],和协作内存网络(CMN)[7].并将在其上应用提出的方法.通过优化BPR损失函数来训练所有基本模型.
参数设定
对于基础模型,ML-1M和Pinterest的最小批量大小设置为256,Citeulike-a设置为128.对于BPR损失函数中的所有实验,使用负比率为6. GMF和CMN的隐藏特征数固定为50.另一方面,对于NMF,最后一层具有32个隐藏特征. 在隐藏层方面,NMF受3层训练; 具有2层的CMN; GMF默认为1.所有模型都使用BPR损失函数进行训练.
对于提出的方法PNW,无论基础模型如何,都仅基于数据集设置参数.对于Citeulike-a,α设置为1.5.对于Pinterest和ML-1M,普通用户的新颖性偏好相对较窄(σθu较小).为了使用户能够更加注意项目,将α设置为2.5. 在BN损失加权PNW-BN中,分别对ML-1M,Pinterest和Citeulike-a使用λ={2,2,7}.在伽玛损失加权PNW-G(λ)中,对于ML-1M,将γ={40,125}设置为PNW-G({2,4}); 对于Pinterest,使用PNW-G({2,4})设置γ={25,100};对于Citeulike-a,分别使用PNW-G({7,9})设置γ={40,75}.如第4.3节所述,根据经验选择这些值以确保大多数权重落在[0,2]的范围内.
5.3 基准模型和设置
进行比较实验时,使用两种重新排序方法和一种损失加权方法.
5.3.1 重新排序方法

长尾挖掘(5D)[22]是一种重新排序框架,特别是用于长尾物品促销.为了平衡重新排名列表的各种标准,框架将多个目标合并为一个分数,称为5D分数,该分数汇总了5个维度的表现,包括准确性,覆盖范围,平衡,数量和质量.重新排名需要两个步骤.首先,通过基础模型预测所有可能的用户项目对的缺失评分,然后使用评分将有限的资源分配给每个项目.其次,通过考虑用户的相对偏好和项目资源,计算5D得分并根据其进行重新排名.在本文中,进行了两个5D实验.“5D-Pop”仅基于5D得分生成top-N,从而显着提升长尾物品.在“5D-Pop”之后,“5D-RR ACC”执行2个额外的算法,即排名等级(RR)和准确性过滤(ACC),以保持基本模型的准确性.在此使用默认设置[22],在最大化问题中,我们遵循文献[9],将参数设置为K=3|I|和q=1.
5.3.2 新颖性损失加权方法
如第4.4节所述,AllRank-Pop是一种应用于逐点损失函数MSE的损失加权方法. 损失权重设计为与商品新颖性成正比. 在本实验中,使用模型的“递减策略”变体,以抑制受欢迎的正项的权重.对于负项,假设所有实验均基于隐式反馈,则使用固定权重Wneg=0.005并将估算的缺失评分设置为Rneg=0.4. 进行两个实验,分别为βw={0.9,0.95}.较高的βw应该会推荐新颖性更高的产品.

5.4 评价指标
本实验在实验时间上采用了“留一法”的评价策略[6,7].在这个设置中,每个用户随机拿出一个正项进行评估,而其他正项则用于训练.在评估过程中,如文献[6,7]所示,测试集由保留项和每个用户随机抽取的100个负项构成.任务是为每个用户对101项进行排序.所有的实验结果均在前十名中进行评估.为了验证提出的方法的准确性和新颖性,使用以下指标:
5.4.1 准确度指标
·命中率(HR)是保留在列表中前N名的项目的比率.
·归一化贴现累积收益(NDCG)衡量HR等准确性,当正项在列表中排名较低时会受到更大的惩罚.
5.4.2 新颖性评价
·长尾比(L_Tail)是前N名中长尾项目的比率.根据帕累托原则[23],与20%最流行的项目相比,长尾商品在不受欢迎的项目中占前80%.
·平均新颖性得分(Nov得分)是前N名推荐项目的平均新颖性得分.
5.5 与重排序方法的比较
在本节中,模型是在Citeulike-a、ML-1M和Pinterest数据集上进行的.比较了提出的方法PNW-BN和PNW-G与PRA,5D-Pop和5D-RR_ACC,除了PNW方法外,所有的比较方法在训练完3个基础模型后都使用了重新排序策略.为了使比较更清楚,用百分比计算基础模型的变化,并将其记录在括号中.实验结果见表3.
在稀疏的,较小的Citeulike数据集环境中,PNW通常提高了基础模型的新颖性推荐,但精度略有下降.在PNW的变体中,PNW-BN的准确性在竞争性新颖性评分方面相对较高.尤其是在GMF-Base中,PNW-BN的长尾和Nov分数排名第2.如前面所述,PNW-G提供了较高的灵活性,从而实现更好的性能.PNW-G的两种变体在所有的实验中,损失的减少最少.值得注意的是,GMF上的PNW-G(9)实际上提高了精度.5D-Pop专注于提高长尾和新颖的分数,并牺牲了大量的准确性.5D-RR_ACC平衡了权衡,但由此产生的性能都不能与任何PNW相比.
ML-1M是一个密度更大的数据集.总的来说,PNW显著改善了两种新颖性评分,在L_Tail和Nov评分中分别提高了41.5%和16%.再次,5D-Pop可以提高新颖性,但大大降低准确性.尽管PRA减少了长尾,但它提高了GMF和NMF的Nov分数.
最后,Pinterest是稀疏的,是本次实验中最大的数据集.所有的方法都无法像在其他两个数据集上那样显著地改进新颖性评分.在这种情况下,与其他两个数据集的结果相比,PNW变量以最低的准确度损失,提高了新颖性度评分.
综上所述,所提出的PNW和重排序方法的性能一般与基本模型无关,更多地依赖于数据集的特性、稀缺性和规模.此外,除了5D-Pop,PNW在准确性和新颖性方面优于所有重排序方法.5D-Pop增加了新颖性,显著降低了准确性.5D-RR_ACC比5D-Pop更能平衡精度和新颖性,但其结果无法与PNW相比.PRA对推荐列表进行了重新排序,以提高特别是Nov得分.总体而言,PNW在保持准确性的同时提高了新颖性,重排序方法侧重于单一目标,很难在权衡取舍之间取得平衡.
5.6 与损失加权法的比较
在这一部分中,对损失加权方法PNW和AllRank-Pop进行了比较实验.由于使用了不同的损失函数,为了进行公平的比较,计算了SacrificeRatio.实验结果如表4所示.在PNW的变体中,PNW-G始终提供小于0.1%的SacrificeRatios(SacrificeRatioLT和SacrificeRatioNS).另一方面,PNW-BN给出了更高的L_Tail和Nov分数.在两种AllRank-Pop方法中,βw越大,新颖性分数越高.一般来说,所有的PNW方法在SacrificeRatio都优于AllRank-Pop,更具体地说,SacrificeRatioLT和SacrificeRatioNS都比AllRank-Pop小10倍.
5.7 负比率
由于PNW是一种成对损失加权方法,因此需要分析负比率的影响.在本节中,将研究{2,4,6,8,10}中各种负比率的影响.由于前两个实验在不同数据集和基本模型上的结果是一致的,所以本实验只选择GMF和Citeulike-a.如图1所示,4个指标在不同的负比率上有所不同.当精度为主要关注点时,{4,6}的负比值表现得更好.当新颖性是主要关注点时,{6}的负比率优于其他比率.当负比值从8降到4~6时,一个简单的基础模型的准确性的结果与文献[6,7]一致.

表3 与重排序的比较结果Table 3 Comparison with re-ranking

表4 与其他损失加权方法的比较Table 4 Comparison with other loss weighting methods

图1 负比率实验结果Fig.1 Negative ratio experiment
5.8 BN损失加权的Lambda
为了证明PNW-BN是一个“无参数”模型,在本节中验证了PNW-BN对λ的不敏感性.选择GMF和Citeulike-a来进行这个实验.图2显示了不同λ值的结果.精确性和新颖性的稳定性能反映了PNW-BN对不同选择的λ一般不敏感.这些结果验证了关于PNW-BN在4.3节中稳定性的论点及其潜在应用.
5.9 消融研究


图2 λ对PNW-BN的影响Fig.2 λ′s impact on PNW-BN
“Novelty Matching”:PNW-BN只有πu,i
表5显示了实验结果. 从表中可知,仅考虑用户的偏好(“新颖匹配”),两个数据集的准确性都得到了提高. 这意味着用户确实具有特定的新颖性区域,并且用户倾向于从该区域中选择项目.在“Novelty Scaling”中,它在HR和NDCG略有下降的情况下都促进了这两个数据集的新颖性.最后,“Full Model”在所有实验中均提供了最佳的L_Tail分数,并且具有具有竞争力的Nov分数. 对于较小的数据集Citeulike-a,“Full Model”更喜欢新颖性,但代价是准确性更高.对于较大的数据集Pinterest,它给出的结果更加平衡. 这些可能是由于在较小的数据集上过度拟合造成的.

表5 消融研究的结果Table 5 Result of ablation study
6 结束语
本文提出了一种有效的损失加权方法,用于一阶段、端到端的新推荐.该方法将新颖性信息和用户的个人偏好融合到BPR损失函数中.大量实验表明,提出的方法优于现有的重排序或损失加权方法,在实际应用中验证了其有效性和潜在用户.
猜你喜欢
今日农业(2022年15期)2022-09-20
现代仪器与医疗(2022年2期)2022-08-11
中国典型病例大全(2022年12期)2022-05-13
中国典型病例大全(2022年7期)2022-04-22
小天使·二年级语数英综合(2019年10期)2019-11-08
中国知识产权(2018年2期)2018-03-03
中国知识产权(2017年4期)2017-04-17
小学教学参考(综合)(2017年3期)2017-03-28
青年文学家(2016年14期)2016-04-29
读者·校园版(2015年19期)2015-05-14
