
融合光谱与纹理特征的龙井茶等级无损识别
2021-03-27 03:33陆江明范婷婷穆青爽康志龙
现代食品科技 2021年3期
陆江明,范婷婷,穆青爽,康志龙
(河北工业大学电子信息工程学院,天津 300401)
龙井茶是中国十大传统名茶之一,其中含有多种有益于人类健康的营养素和药用成分,香气浓郁,口感醇厚,受到各地消费者青睐[1]。然而龙井茶分级混乱,质量价格不一,严重影响了消费者的购买热情和龙井茶的市场竞争力。因此,研究一种无损、高效且准确的龙井茶等级鉴定方法具有重要意义。
目前,龙井茶等级鉴定主要基于专家的感官评价[2],感官评估容易受到主观因素的影响。高效液相色谱法、气相色谱法和质谱法通常用于实验室中分析茶叶的质量[3,4],但测试具有破坏性,且操作复杂耗时。电子舌、电子鼻[5]等分析方法容易受到环境条件(如温度和湿度)的影响,导致传感器漂移[6]。近年来已经报道了许多与光谱相关的无损检测方法,其中高光谱成像技术引起了人们很大关注,它可以快速检测样品品质与成分含量[7-11]。高光谱成像技术结合传统成像和光谱技术,能够同时获取图像和光谱信息。到目前为止,高光谱成像技术在茶叶种类和等级识别上得到了一定发展[12],但研究大多是基于光谱信息,有关图像信息(如纹理特征)利用的报道较少。如MISHRA[13]等人利用光谱信息实现了对六种不同商品茶分类;GE[14]等人研究了五种外观相似的乌龙茶的识别;蒋帆[15]和LI[16]等研究了三个等级龙井茶和铁观音茶的识别,但是三个等级无法满足实际的需求;于英杰[17]等人利用光谱信息实现了五个等级的铁观音茶的识别,但是由于没有结合到图像信息,故而准确率较低。
本研究旨在融合高光谱图像的光谱、纹理特征,结合机器学习算法,建立多等级龙井茶判别模型,为提高龙井茶等级识别水平提供可靠的理论基础和技术支持。
1 材料与方法
1.1 材料
购买六个等级的龙井茶,均来自杭州茶厂有限公司,符合官方龙井分级标准(DSBB33X02-95)。如图1 所示,分别为特级龙井、一级龙井、二级龙井、三级龙井、四级龙井、五级龙井。每个等级茶叶分为480个样本,共2880 个样本,每个样本5 g。放在直径为3.5 cm、深度为1 cm 的黑色圆形塑料容器中。各等级按照3:1 分为训练集和预测集,最终训练集包含2160个样本,预测集包含720 个样本。

图1 龙井茶样本Fig.1 Samples of Longjing tea
1.2 高光谱图像采集
实验采用的高光谱成像系统主要由光谱仪(Imspector N17,Spectral Imaging Ltd,Oulu,Finland),CCD 像机(Zelos-258GV,Kappa Optronics GmbH,Germany),聚光灯,移动平台和计算机等部件组成。采用线扫描模式采集高光谱反射图像。成像系统光谱分辨率为3.2 nm,光谱范围为900~1700 nm,属于近红外光谱(Near Infrared,NIR)。与可见近红外光谱(Visible Near Infrared,VNIR)相比,NIR 可以提供更丰富的化学信息(如OH、CH 及NH 等化学键组成的分子结构信息)[18]。为获得清晰且不失真图像,将茶叶样品放在高光谱成像系统移动平台中间,镜头和样本之间距离设为32 mm,平台移动速率设为16.8 mm/s,曝光时间设为20 ms,最终得到256 个波段下的高维数据立方体。
1.3 光谱数据预处理
图像采集易受到照明强度、探测器灵敏度及光学器件投射特性等因素影响,因此本研究对采集的高光谱图像进行黑白校正。在相同实验条件下,分别采集接近全反射的白帧图像和接近零反射的黑帧图像。高光谱图像的各个像素点反射率通过式(1)来校正:

式中,IR是校准的反射率,Iraw是原始图像反射强度,Idark是黑帧图像反射强度,Iwhite是白帧图像反射强度,i 和j 是空间坐标,k 是图像的波长。
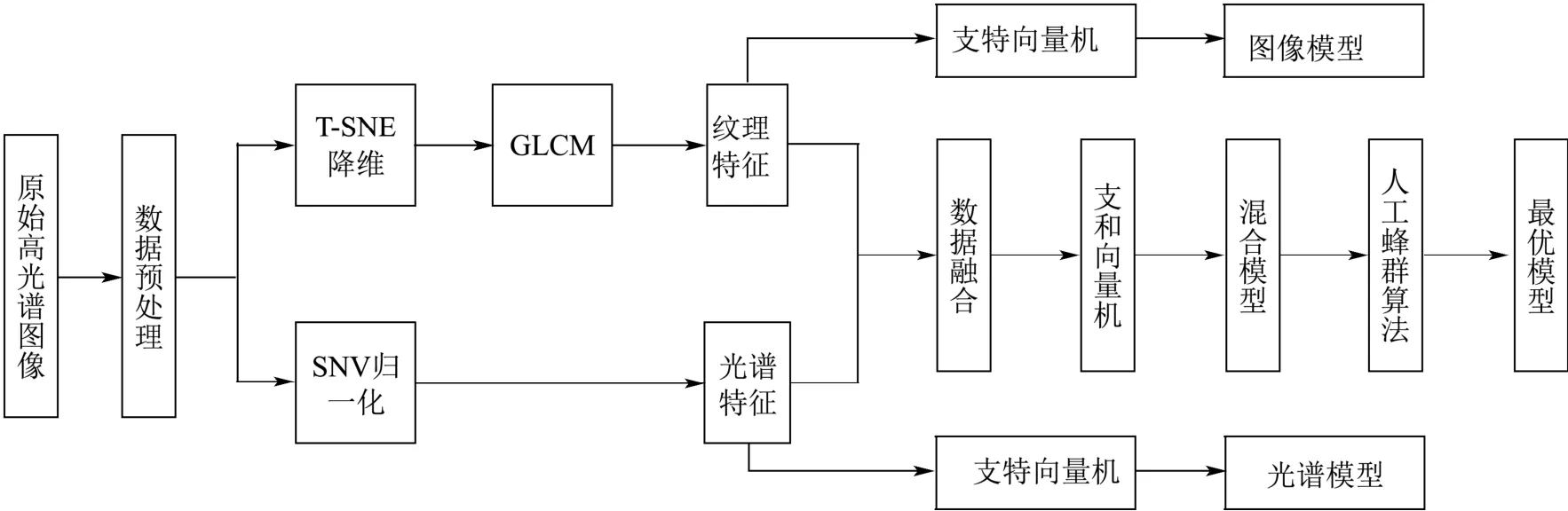
图2 龙井茶叶等级识别模型构建流程图Fig.2 Flow chart of Longjing tea class identification model construction
1.4 纹理特征提取
近距离高光谱图像不仅有更高分辨率,还包含了更多有关样本物理特征的纹理信息[19]。灰度共生矩阵(Gray-Level Co-Occurrence Matrix,GLCM)是纹理描述最简单的方法之一,已经被广泛应用在近距离高光谱图像领域[20,21]。相关文献表明,GLCM 能够很好地提取特征图像中茶叶纹理特征[22]。每个样本数据对应256 个波段的图像,若对所有图像进行纹理特征提取,计算复杂,且图像之间的相关性会影响识别模型精度[23]。为获取茶叶样本最具代表性的数据,减少不必要的运算,需要对高光谱数据降维。相关研究表明,T-SNE 算法对茶样本数据降维优于其他方法[13]。
1.5 龙井茶叶等级判别模型构建
1.5.1 支持向量机分类
在化学计量学领域,有多种方法可以对光谱特征进行分类,但是在图像处理领域,支持向量机(support vector machine,SVM)在融合光谱和纹理信息的分类上有更好的性能[24]。支持向量机是一种基于统计学习维数理论和结构风险最小化原理的监督学习模型[25],可以进行分类和回归分析。通过核函数将输入空间映射到高维空间来构造最优分类平面,从而准确分离不同的类别。相关研究表明,使用径向基函数(radial basis function,RBF)作为核函数可以将非线性样本映射到更高维度的空间,以处理样本数据和类别之间的非线性关系[26]。
1.5.2 参数优化
为解决SVM 参数在寻优过程中易陷入局部最优解的问题,引入人工蜂群(Artificial Bee Colony,ABC)算法,通过ABC 算法可获得SVM 模型惩罚因子C和核函数宽度g的最佳组合[27]。实验中参数寻优问题可转化为蜜蜂寻找好的蜜源问题,将C和g作为蜜源位置,分类正确率作为适应度,利用ABC 算法寻找适应度最高的蜜源位置。优化算法步骤如下[28]:
(1)初始化相关参数。设置最大迭代次数,蜂群大小,蜜源数量,蜜源最大循环次数及C和g的范围。
(2)随机选择一个初始蜜源,进行邻域搜索,获取新的蜜源,并更新当前蜜源的相关信息。
(3)计算每个蜜源的适应度值,根据适应度值计算更新蜜源的概率,并据此更新每个蜜源。
(4)如果达到蜜源最大循环次数后的蜜源尚未更新,则会随机生成一个新的蜜源。
(5)迭代到最大次数后,操作终止,输出最佳蜜源位置,即最佳C和g的组合。
(6)将ABC 算法获得的最优参数C和g代入SVM 模型进行训练。
1.5.3 识别模型构建
数据融合方法包括数据级融合、特征级融合及决策级融合。由于很难确定两类数据对最终结果的影响权重,而两类数据都来自于高光谱图像,且原始数据保留所有信息,因此本研究采用数据级融合方法。基于光谱特征、纹理特征及融合特征,分别建立龙井茶等级识别模型,识别模型流程如图2 所示。光谱模型、图像模型及混合模型中,SVM 均采用默认参数,根据各模型的相对识别率来验证数据融合的作用,并得到性能相对较好的混合模型。然后应用ABC 算法,迭代优化混合模型SVM 参数,得到最优模型。
1.5.4 模型评估指标
模型的性能根据正确率和Kappa系数两个参数评估。正确率计算如式(2)所示:

其中,n1是预测正确的测试集样本数,n2是测试集样本总数。
Kappa系数计算基于混淆矩阵,如式(3)所示:

其中,p0是每一类正确分类样本数量之和与样本总数的比值,即总体样本精度。
假设每一类真实样本个数分别为a1,a2,…,ac,而预测结果每一类样本个数为b1,b2,…,bc,总样本个数为n,则有式(4):
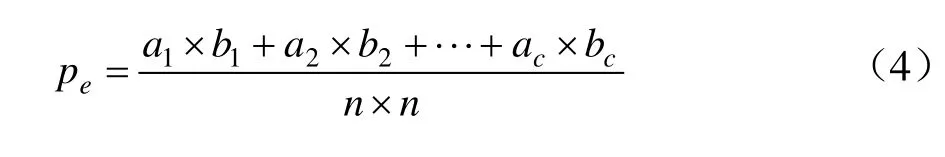
2 结果与讨论
2.1 光谱数据处理与分析
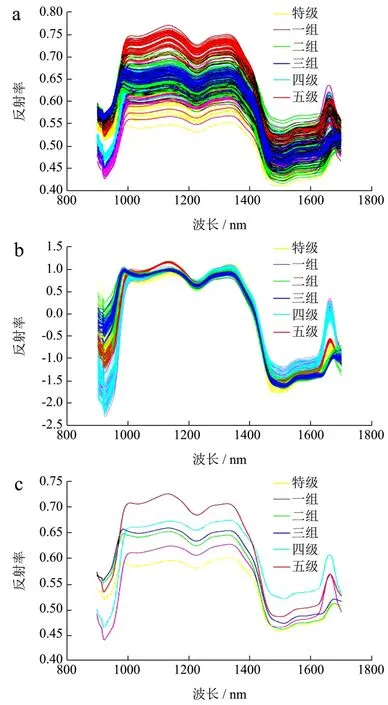
图3 原始光谱、SNV 预处理光谱和平均光谱Fig.3 Raw spectra, SNV preprocessed spectra and mean spectra
使用ENVI 5.3 分析软件,选取龙井茶样本感兴趣区域(Region of Interest,ROI),然后将数据导入MATLAB R 2018b 软件中进行处理与分析。
为了提高模型鲁棒性,每个样本选取100×100 像素区域作为ROI,以ROI 的平均反射光强作为茶叶等级分类的特征参数,即原始光谱数据,如图3a 所示。通常辐射校正足以消除光谱数据中照明不均匀的影响,但是当茶叶样品表面不均匀时,光散射会导致加和乘性效应[18]。本研究采用标准正态变量变换(Standard Normal Variate,SNV)对光谱进行归一化处理[29],结果如图3b 所示,减小了由光散射引起的基线偏移。六个等级龙井茶样本的平均光谱如图3c所示。根据相关研究,1093~1121 nm 处光谱反射率与茶黄素含量相关[30],1131、1654 和1666 nm 处光谱反射率与茶多酚含量相关[31],1361 nm 处光谱反射率与水分含量相关[30],1480、1690 nm 处光谱反射率分别与NH、CH 基团相关[32]。不同等级茶叶成分差异导致对光的吸收度不同,因而呈现不同的光谱特性。因此,可以依据光谱特性建立龙井茶等级识别模型。
2.2 纹理特征提取与分析
纹理是图像特征研究的重点,各特征图像之间的相关性会导致较低的识别精度。本研究采用T-SNE 算法降维,相关程序由MATLAB 实现。前两个特征波长处的高光谱数据如图4 所示(特征波长由映射得到,并不代表具体某个波长),横轴代表第一个维度光谱特性,纵轴代表第二个维度光谱特性。二级龙井和三级龙井在同一簇中,说明二者具有更相似的光谱特征,该结论可通过图3 所示的光谱特性曲线验证。这表明通过T-SNE 算法进行特征波长提取,可以保留从高维空间向低维空间转换时的数据结构。

图4 T-SNE 降维结果可视化Fig.4 Visualization of T-SNE feature extraction
以特级龙井茶样本数据为例,通过T-SNE 算法,将256 个波段下的高光谱数据映射为4 个特征波长下的数据,并得到图5 所示的四个特征图像。选取11×11矩形像素区域为基准窗口,在四个方向(0°,45°,90°和135°)移动,分别构建GLCM。每个方向上的GLCM 提取对比度、相关性、能量、均匀性、平均值、方差、熵、聚类突出度、聚类阴影、同质性、总和平均值、总和方差及总和熵共13 个特征参数,共提取208 个纹理特征(4 个采集方向×4 个特征图像×13个特征参数)。

图5 特级龙井特征图像Fig.5 Premium Longjing tea feature image
2.3 识别模型建立与分析
光谱特征数据、纹理特征数据、融合特征数据和对应等级标签,分别用作SVM 输入,预测等级标签作为输出,得到光谱模型、图像模型和混合模型。各模型中SVM 的惩罚因子C 和核函数宽度g 为默认值,相关程序通过MATLAB 实现。
识别结果如图6 所示,混淆矩阵对角线元素表示等级识别正确的样本,非对角线元素表示分类错误的样本。混淆矩阵对角线元素值越高,表示正确预测的数量越多。由图6a 可知,光谱模型预测集识别率为91.12%,错误主要集中在二、三级龙井茶识别,因为二者具有更为相似的光谱特性;由图6b 可知,图像模型预测集识别率为75.42%,错误更多集中在四、五级龙井茶识别;由图6c 可知,混合模型预测集识别率为95.14%,优于其他两个模型,这表明通过结合光谱和纹理特征,可以提高龙井茶识别模型精度。为了进一步提高混合模型精度,引入ABC 算法优化SVM 参数,建立最优模型。通过多次测试,按照如下设置初始化ABC 算法中参数时,该模型可实现较好的分类和泛化能力。蜂群大小为10,最大迭代次数为150,蜜源数量为5,蜜源最大循环次数为100,C 和的g 搜索范围为[0.01,200]。经过ABC 算法优化后,得到的最佳C 和g 分别为52.36 和0.15,然后将其代入SVM 模型进行训练。图6d 为最优模型识别结果,预测集识别率可达98.61%,对各级龙井茶基本识别准确。表1 为每个模型对各级龙井茶的识别率。
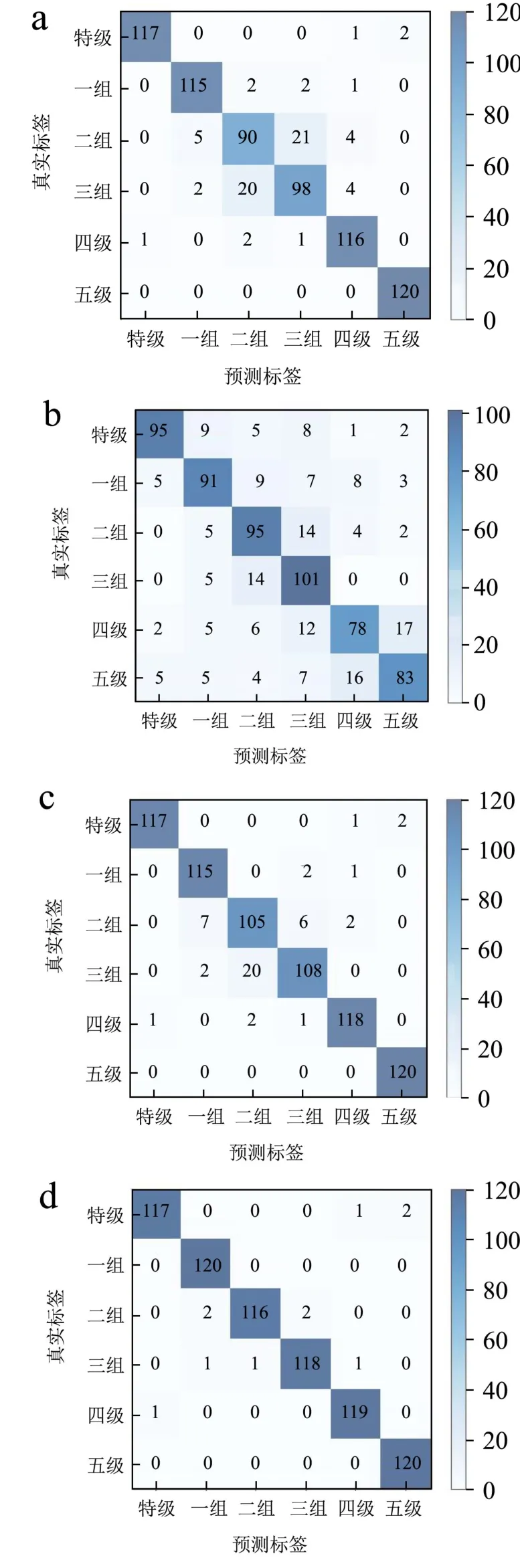
图6 各模型识别结果Fig.6 Recognition results of each model
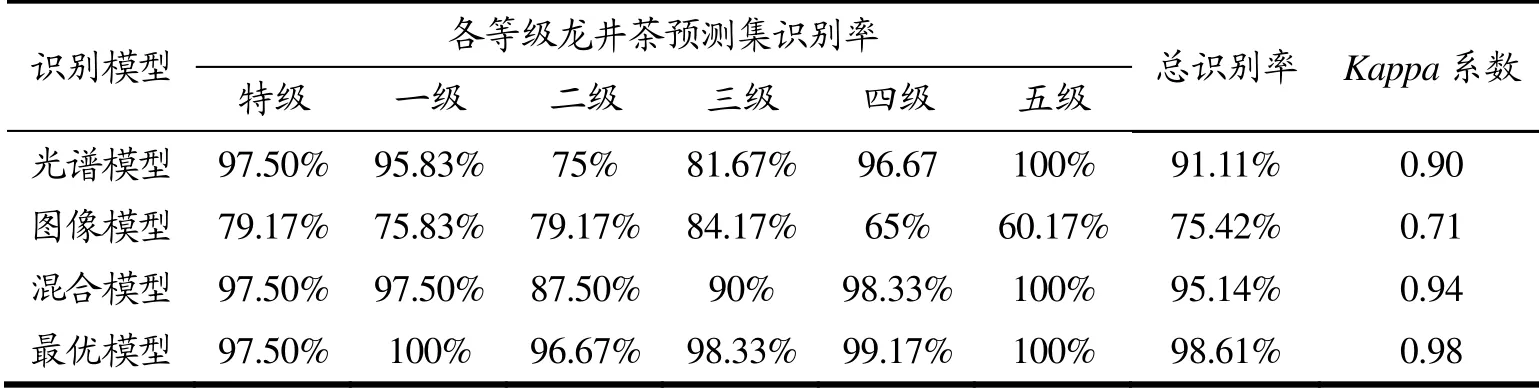
表1 各模型预测集识别率Table 1 The recognition rate of each model to the prediction set
2.4 识别模型性能验证
应用ABC 算法优化的SVM 混合模型(即最优模型),对龙井茶高光谱图像的每个像素点进行可视化识别,用不同的颜色表示每个像素不同的预测值,形成图7 所示的识别预测图。图7a、7b 分别为来自杭州茶厂有限公司龙井茶的灰度图像及识别结果,从上到下依次为,特级龙井、一级龙井、二级龙井、三级龙井、四级龙井、五级龙井。由图可知,该模型基本完成了对每个样本像素点的识别,样本边缘处的错误分类主要是实验所用黑色塑料容器引起的。为了进一步验证该模型的泛化能力,以来自杭州狮峰茶叶有限公司的6 个等级龙井茶为实验对象,按照上述流程,进行实验。图7c、7d 分别为该品牌龙井茶的灰度图像及可视化识别结果。由图可知,该模型仍能够基本实现对不同等级龙井茶像素点的识别,具有较好的泛化能力与应用价值。

图7 龙井茶识别预测图Fig.7 Prediction map of Longjing tea recognizing
3 结论
本研究利用高光谱成像技术,结合SNV、T-SNE、GLCM 等算法,基于光谱特征、纹理特征以及融合特征,分别建立龙井茶等级快速无损识别的SVM 模型。结果显示,光谱模型预测集识别率为91.11%,其中对二、三级龙井茶识别错误较多,因为二者具有更相似的光谱曲线;图像模型预测集识别率为75.42%,但对二、三级龙井茶的识别率优于光谱模型;混合模型预测集识别率为95.14%,优于其他两个模型。结果表明,高光谱图像的光谱和空间域生成互补信息,对该信息的协同处理可以提高分类模型的正确率。当前研究中龙井茶识别大多基于光谱信息,缺乏对高光谱图像信息的应用。为了进一步提高识别精度,本研究引入ABC 算法,优化SVM 混合模型参数。当C和g分别为52.36 和0.15 时,得到最优模型,预测集识别率可达98.61%。最优模型能够基本实现对龙井茶样本每个像素点的识别,且具有一定的泛化能力。本研究为改进龙井茶等级评估技术提供了一种可靠的方法和技术指导。
猜你喜欢
林业与生态(2022年5期)2022-05-23
计算机工程(2020年3期)2020-03-19
文化交流(2019年10期)2019-11-22
中国听力语言康复科学杂志(2019年3期)2019-06-24
中国交通信息化(2018年3期)2018-06-13
高中生·天天向上(2018年1期)2018-04-14
学苑创造·B版(2015年12期)2016-06-23
中国交通信息化(2016年2期)2016-06-06
茶博览(2015年5期)2015-01-03
中国茶叶加工(2014年3期)2014-02-27
