
机器学习在故障检测与诊断领域应用综述
2021-04-02 02:13翟嘉琪杨希祥程玉强
计算机测量与控制 2021年3期
翟嘉琪,杨希祥,程玉强,李 亮
(国防科技大学 空天科学学院,长沙 410005)
0 引言
随着科技的发展和制造工艺的进步,设备或系统的复杂度不断增加,在使用过程中的任何异常或故障不仅直接影响产品的使用,而且还可能造成严重的安全事故。经过长期的实践和经验,要使设备或系统能够安全、可靠、有效地运行,必须要对其进行故障检测与诊断。实践证明,坚持开展设备状态监测,有效地实施故障检测与诊断技术可以早期发现故障,避免重大安全事故的发生,保障设备系统正常运行。
1967年,美国国家宇航局(NASA)就开始关注故障诊断相关研究,创立了MFPG(美国机械故障预防小组),标志着故障诊断技术的诞生,随后欧洲的发达国家和日本也开展了故障检测与诊断技术的研究。随着故障检测与诊断技术所产生经济效益和安全价值不断增加,越来越多的研究人员投入其中,并得以迅速发展。目前已成功应用于航天、军事、核能、电力、化工、冶金等行业。
故障检测与诊断的终极目标是尽可能迅速准确地检测出故障,并及时对检测出的故障做出判断,最后依据诊断结果采取相应的措施,一般评价指标有以下几个部分:1)实时性:在发生故障时,应迅速对故障的发生进行检测和判断;2)故障的误报率、漏报率和错报率:误报指的是未发生故障却报出故障;漏报指的是发生故障却未报出故障;错报发生故障,但报出的故障信息与实际故障不一致;3)灵敏度和鲁棒性,灵敏度指的是对故障信号感应的灵敏程度,鲁棒性是指在干扰、噪声、建模等误差情况下稳定完成故障诊断任务的能力;4)故障定位能力:是指故障诊断系统区分不同故障的能力;5)准确性:对故障大小进行正确判断的程度。
早期的故障检测与诊断主要依赖于专家或技术人员的决策,然而专业人员容易受到压力、疲劳、心理因素、自身知识水平、技能等影响,做出与实际状态相差较大的分析,从而产生错误的判断。随着传感器、无线通信、移动终端、计算机等的发展,基于模型的故障诊断方法最先发展起来,这种方法需要针对待测对象建立精确的数学模型,需要完整认识待测对象的深层知识,不依赖于历史数据或已知的故障数据,因此可以诊断出未知的故障。随着技术的不断进步,待测对象不断复杂化、大型化、非线性化、系统化,建立精确的数学模型难度越来越大,各设备之间存在的耦合,使得模型难度也会成指数增加。基于信号处理的方法不需要精确的数学模型,回避了基于模型的故障诊断方法的难点,而是基于待测对象的信号模型,分析测得的信号数据提取特征信号值,根据特征值是否异常来判断待测对象是否发生故障,该方法基本不依赖于待测对象的模型,既适用于线性系统又可适用非线性系统,但是它只是对待测对象的信号数据进行分析,对系统高维信号之间的耦合性和关联度挖掘不够,没有更加深入地利用待测对象的深层信息。
随着传感器技术、计算机技术、工艺技术和网络技术的迅猛发展,人类对知识的认识、管理和应用水平的提高,使得设备或系统数据的获取、存储、传输、加工、分析和利用得到了有效提升,其中机器学习具有快速处理大量数据、分析提取有效信息等优点,已被越来越多地应用于故障检测与诊断技术(fault detection and diagnosis,FDD)中来[1]。
鉴于机器学习技术的发展日新月异,国内基于机器学习应用于故障检测与诊断技术的相关研究仍处于起步阶段,缺乏对基于机器学习的故障检测与诊断方法的系统介绍,与当前基于深度学习或某一确定方法的故障诊断综述性文章相比,本文系统地从机器学习在故障检测与诊断领域的应用中的基本概念、国内外现状、算法模型分类比较、关键技术及未来发展等若干层次对当前的相关研究进行说明,为进一步深入研究和拓展故障检测和诊断的机器学习算法模型奠定了基础。
1 基于机器学习的故障检测与诊断的基本概念及分类
1.1 机器学习
机器学习是一门多领域交叉学科,涉及计算机科学(人工智能、理论计算机科学)、数学(概率和数理统计、信息科学、控制理论)、心理学(人类问题求解和记忆模型)、生物学/遗传学(遗传算法、神经网络),专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自己的性能,图一是机器学习的简单模型。环境提供外界信息,类似教师的角色;学习环节处理环境提供的信息,相当于各种学习算法,以便改善知识库中的知识;知识库以某种知识表示存储信息;执行环节利用知识库中的知识来完成某种任务,并把执行情况回送至学习环节。从数学的角度上看,机器学习是对于输入X,尝试寻找能输出预期y的f函数。机器学习问题也可以理解为求最优解,在求解最优参数时,往往没有闭式解即明确答案,因此我们需要比较各种机器学习模型在同一个问题上的优劣性,最终得到最合适的模型[2]。

图1 机器学习模型
基于学习形式的不同,通常可将机器学习算法分为有监督学习、无监督学习以及强化学习三类:
1)有监督学习(Supervised Learning):用已知某种或某些特性的样本作为训练集,以建立一个数学模型,再用已建立的模型来预测并输出未知样本。当输出为离散的,学习任务为分类任务;当输出为连续的,学习任务为回归任务。监督学习主要被用于解决分类和回归的问题。常见的算法有:决策树、人工神经网络算法、支持向量机、朴素贝叶斯、K近邻、逻辑回归、随机森林。
2)无监督学习(Unsupervised Learning):没有对训练样本的信息进行标记,其目标是通过对无标记样本的学习来发现数据内在的联系和规律,为后续的数据分析进一步提供依据。无监督学习便于压缩数据存储、减少计算量、提升算法速度,还可以避免正负样本偏移引起的分类错误问题,主要用于经济预测、异常检测、数据挖掘、图像处理、模式识别等领域,常见的算法有:聚类算法、降维算法,主成分分析。
3)强化学习(Reinforcement Learning):该算法描述的是一个与环境交互的学习过程,把环境的反馈作为输入,通过学习则能达到其目标的最优动作。强化学习的组成部分:reward(奖励)、agent(智能体)、environment(环境)、state(状态)、action(行为),强化学习的目的为选择action用以最大化所有未来的reward的总和。常见的算法有:TD(λ)算法、Q-learning算法,Sarsa算法。
1.2 故障检测和诊断技术
随着生产制造技术的快速发展,许多设备和系统的结构已变得越来越复杂,由于各种复杂性和运行因素(自身磨损、外部环境)的影响,设备的性能和系统的状态会随着使用时间增加而逐渐退化,若不及时进行状态监测和故障诊断,必将发生故障,而一旦出现故障,最终可能会导致严重的安全事故。为提高设备或系统的安全性和可靠性,故障检测与诊断技术(fault detection and diagnosis,FDD)应运而生。故障检测与诊断技术包括故障检测、故障分离和故障识别、故障决策,能够判断设备或系统状态是否正常、故障发生的时间和位置,确定故障的类型,并在分离出故障后确定故障大小和特性,给出发生故障后的解决措施。
故障检测主要判断设备或系统是否发生了故障和指明发生故障的时间。故障检测主要起监控作用,当故障发生时,系统或设备的输出参数便会偏离正常的目标参数,甚至超出给定的阈值范围。故障检测技术利用这些提取到的故障数据或者处理后的故障数据进行故障检测,这些故障数据信息包含过程故障或系统故障的特征,所以可以用来检测系统的运行过程是否发生故障,然后根据故障发生情况确定故障发生的时间。清华大学教授周东华从故障诊断的角度分析,提出了定性分析方法和定量分析方法,前者分为图论方法、专家系统方法以及定性仿真,后者可分为基于解析模型的方法和基于数据驱动的方法[3]如图2。
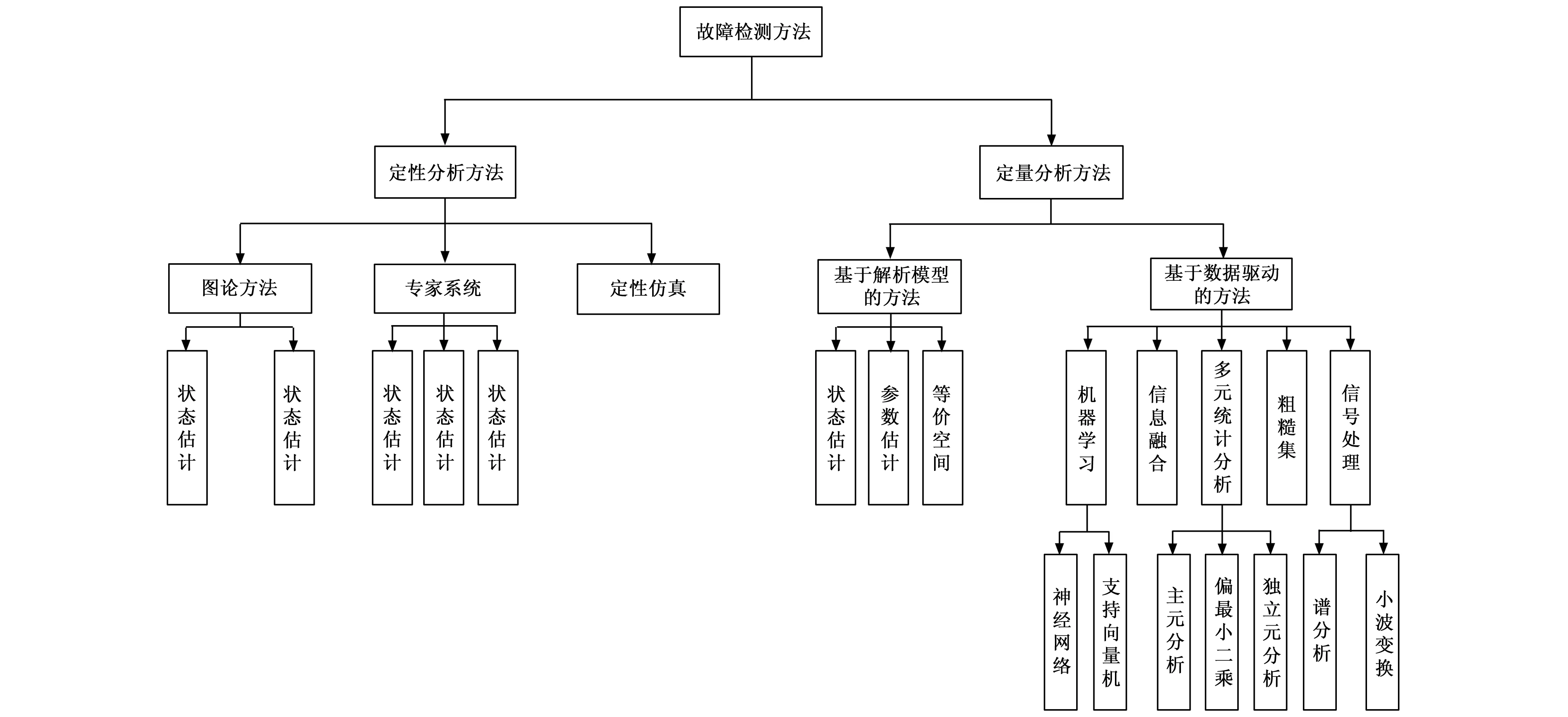
图2 故障检测分类
故障诊断是指当设备或系统出现故障时,依据其实际的状态及表征参数的变化判断是否发生故障,若发生故障,就确定故障的位置、大小、时刻、原因等信息。故障诊断的最终目标是尽可能迅速地、准确地去检测出故障,并对该故障作出分离和判断,最终依据诊断结果给出需要采取的相应措施[4]。
根据采用的特征描述和决策方法的差异,故障诊断方法可以划分成基于知识的方法、基于解析模型的方法、基于信号处理的方法3种[5],如图3。
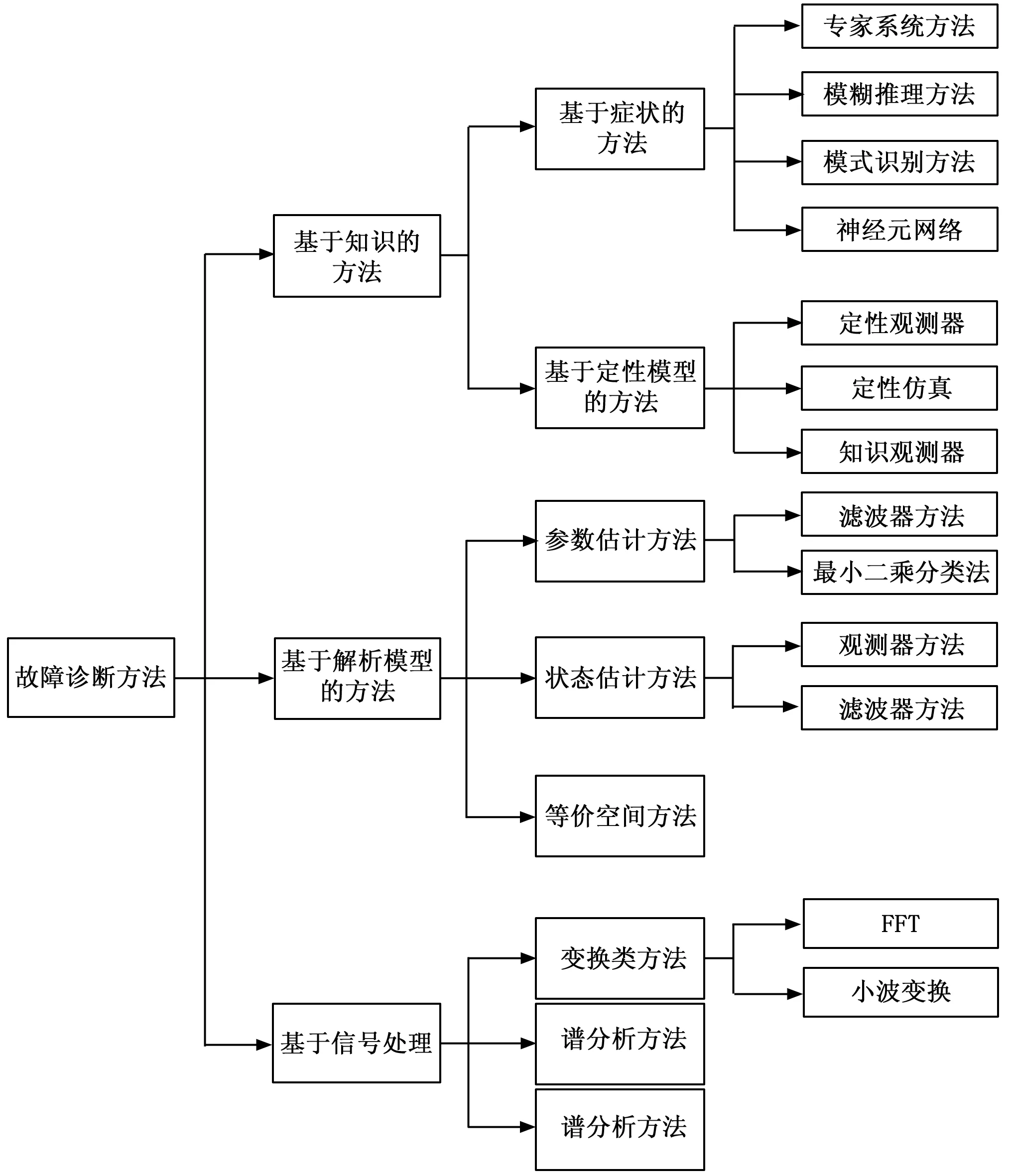
图3 故障诊断分类
2 机器学习算法在故障检测方法中的应用与发展
机器学习的目标是通过某种机器学习算法得到输入输出间的关系,并能够利用这种关系对给定的输入尽可能准确的给出系统未知的输出。而故障检测与诊断的目标就是利用测试数据(传感器、文字、语音、视频等)来寻求测试数据和故障之间的联系,因此可以认为故障检测与诊断本质上也是一个机器学习问题。随着技术的不断进步,当前工业过程可以获得大量的状态数据,而机器学习正好能通过算法模型对这些数据进行处理,从而实时检测整个过程中设备或系统的故障状态,并能够基于数据对设备或系统进行故障诊断。故障检测是故障诊断的前提,前者用来确定系统是否发生了故障以及发生故障的时间,而后者是在检测出故障之后,确定故障的类型或者位置。机器学习在故障检测领域的应用主要包括主元分析(PCA)、随机森林等。
2.1 主元分析法(PCA)
在实际故障检测中,通常会选择能够反映研究对象的变量来进行观测,而在系统结构日益复杂变量信息过多时,会增加研究对象的复杂性。
PCA是将获得的待测对象到的高维历史数据组成一个矩阵,进行一系列矩阵运算后确定若干正交向量(向量个数远小于维数),历史数据在这些正交向量上的投影反映数据变化最大的几个方向,舍去数据变化较小的方向,由此可将高维数据降维表示。主元分析用于故障检测的主要思想是把在正常过程中获得的数据,最大限度地保持原有信息不受损失,将这些数据高度相关的过程变量投影到低维空间中,获得能够表述系统内部关系的几个主要成分,即主元模型。即把多个不同的相关量换成少量几个独立的变量,并对这几个独立变量进行统计检验分析,进而判断系统是否偏离正常工况[6]。用这些数据来判定实际研究对象中T2统计量、残差空间的SPE统计量等是否超过已设定的过程监控指标,从而判断系统是否发生故障。
PCA已经成功应用于化工过程、半导体过程、机械过程、废水处理、核工业过程、空气检测处理等[7];余莎莎等提出了基于PCA模型的故障检测方法,根据平方预测误差和其阈值大小的比较,利用该方法已成功建立了空调系统故障检测模型,用来判断系统是否发生故障[8];周福娜等基于PCA的故障检测方法通过分析检测数据和主元模型之间的差异来判断系统是否出现故障[9]。
PCA对数据降维处理有着绝佳的优势,但是仍存在两个问题:1)线性分解方法压缩和提取不充分;2)线性方法的结果不可靠,在较小的主元中可能含有重要的非线性信息,导致重要信息的丢失,因此可以结合其他方法进行优化。为了克服传统主元分析因模式复合现象而无法进行多故障诊断和诊断结果难以解释的不足,周福娜等提出了指定元分析(DCA)的方法,建立了多故障诊断理论的空间投影框架,这种方法可以将检测出的异常转化为观测数据在故障子空间上的投影能量的显著性检测问题,这种方法能够有效解决指定模式非正交情况下的多故障诊断问题[10];梁艳等针对实际化工过程会受到不同程度非高斯扰动影响的问题,提出一种基于广义互熵主元分析的故障检测方法,并将其应用于天纳森-伊斯曼过程进行故障检测,与传统PCA方法对比后,该方法在处理非高斯的故障检测方面表现出良好的性能,有较低的误报率和漏报率[11];Lv等提出使用聚类原则对研究对象划分成子空间,使用贝叶斯方法融合子空间的信息进行决策,在青霉素发酵过程中验证该方法,并与多向主元分析(MPCA)进行对比,有效提高故障检测正确率[12]。
2.2 随机森林方法
美国科学院院士 Breiman等人在2001年提出随机森林算法[13],这种算法将集成了分类与回归决策树(classification and regression tree,CART)。随机森林是Bagging的一个扩展变体,而Bagging是并行式集成学习方法最著名的代表,给定包含m个样本的数据集,随机取一个样本放入采样集中,再将其放入初始数据集,使得下次采样仍能被选中,经m次取样后得到m个采样集,初始训练集中有的在采样集中多次出现,有的从未出现,采样出T个含m个训练样本的采样集,基于每个采样集训练一个基学习器,再结合这些基学习器,使用简单投票法对分类任务进行预测输出,使用简单平均法对回归任务进行预测输出。随机森林以决策树为基学习器构建Bagging集成,传统决策树在选择划分属性是在当前节点的属性集合(d个)中选择一个最优属性;在RF中,先从决策树中的每个节点的属性集合中随机选择一个包含k个属性的子集,再从子集中选择一个最优属性用于划分,其中k控制了随机性的 引入程度。随机森林由于其算法简单、容易实现、计算量小、处理高维度数据以及分类速度快等特点,被用于故障检测中。
Iftikhar Ahmad等提出了一种基于数据的电力电缆系统的故障诊断系统,利用小波分析和倒谱分析得到特征变量,比较了k-近邻、k-NN,ANN、随机森林、分类回归树(CART)以及增强型CART等6种方法[14];Sanghyuk Lee利用相似性度量和随机森林算法对航空系统进行故障检测,使用距离信息设计了相似性度量,通过随机森林算法技进行相似性度量权重计算,并提供数据优先级,[15];Jong Oh 等使用随机森林分析了神经元数据集,并衡量了数据中每个输入变量之间的相对重要性,可以极大地减少变量的数量,保留原始数据的可识别性[16];Quiroz J C提出一种基于随机森林算法的LS-PMSM(直线启动永磁同步电机)故障检测方法,基于随机森林算法得到电机的特征数据的特征重要性排序,使得输入模型的特征数量降低,并将其与决策树、朴素贝叶斯分类器、逻辑回归、以及支持向量机等进行比较,随机森林的进度更高,可将该方法应用于工业生产过程的状态监测[17]。
随机森林方法可以对故障进行有效的检测,但是没有考虑到数据之间的自相关和互相关关系,大量的耦合特性会影响随机森林模型的精确度,同时,由于随机森林方法至少需要两类数据进行训练,现有单类随机森林方法采用原始投票多数方法检测故障,没有构建相应的统计量,因此当数据量有限,且变量之间存在耦合时,单类随机森林方法无法很好实现及时、有效的故障检测,因此需要对随机森林算法进行改进和优化。Mariela Cerrada提出基于遗传算法的特征获取与随机森林模型相结合的齿轮故障检测方法,利用遗传算法从振动信号中提取时间、频率和时域的特征子集,将其应用于随机森林的训练,直到随机森林模型的性能达到最佳[18];针对单棵决策树模型分类方法精度不高,容易出现过拟合等问题,郝姜伟等提出使用组合单决策树来提高计算精度的随机森林算法,并将其应用于飞机发动机故障检测中[19];曹玉苹等提出一种新的基于动态单类随机森林的故障检测方法,这种方法针对高维化工过程中存在的非线性和动态特性,根据正常状态下的过程数据的反分布产生离群点数据,同时利用典型变量分析方法对正常数据进行相关性分析,利用典型变量空间数据(正常数据和离群点数据在典型变量空间的投影)训练随机森林[20];陈宇韬等提出一种基于极端森林的故障检测方法,该方法利用pearson相关性分析去掉线性相关性较弱和非主要特征的变量,使得样本维度降低,利用最大信息系数获得主要特征参数的相关系数,消除冗余变量提高故障检测精度,已成功应用于大型风电机组发电机的故障检测,结构说明该方法具有更低的漏报率、误报率和更好的实时性[21]。
3 机器学习算法在故障诊断领域的应用与发展
故障诊断技术发展至今,已经提出了较多的方法,从开始的基于解析模型方法到现在的基于机器学习方法,在不需要太多的先验知识以及系统精确解析模型的情况下完成系统的故障诊断,机器学习拥有很广泛的应用空间,其在故障诊断领域的应用主要包括决策树、神经网络和支持向量机等。
3.1 基于决策树的故障诊断方法
决策树是一种基本的分类与回归方法,一般的,一颗决策树包含根节点(一个)、内部节点(n个)和叶节点(m个),叶节点对应于事件的决策结果(m个),内部节点对应于一个属性测试(n个);根节点包含的样本全集根据属性测试的结果被划分到节点中,从根节点至每个叶结点的路径对应了一个判定测试序列。决策树的构造是一个递归的过程,有3种情形会导致递归返回:(1)当前结点包含的样本全属于同一类别,这时直接将该节点标记为叶节点,并设为相应的类别(无需划分);(2)当前属性集为空,或是所有样本在所有属性上取值相同,这时将该节点标记为叶节点,并将其类别设为该节点所含样本最多的类别(无法划分);(3)当前结点包含的样本集合为空,这时也将该节点标记为叶节点,并将其类别设为父节点中所含样本最多的类(不能划分)。
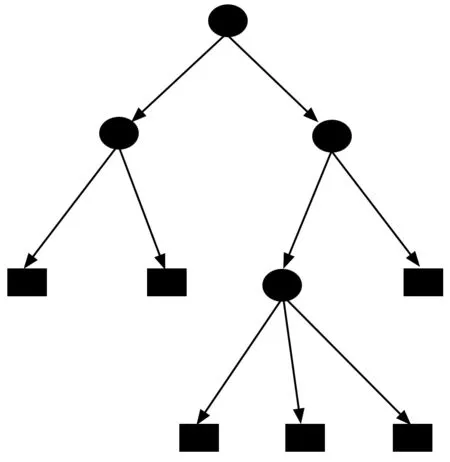
图4 决策树结构
决策树可以进行自学,不需要任何专家知识,可以根据设备自行生成决策系统。决策树算法是以实例为基础的归纳学习算法,以表达的知识简单直观、高推理效率、易于提取显示规则、计算量相对较小、可以显示重要决策属性和较高的分类准确率等优点而得到广泛的应用。董明提出了一种利用属于模式识别范畴的决策树C4.5法进行油浸式电力变压器故障诊断的方法,实现了变压器故障由粗到细的逐级划分,有利于提高诊断的准确性[22];Wang D提出了基于集成决策树电网故障诊断方法,使用属性选择机制将大量的电力信号属性组成子集,每个子集都是经过训练的单独决策树,和多个决策树模型一起投票 进行电网故障诊断,结果很好地表明该方法有较高的稳定性和准确性[23];王小乐等提出了一种基于决策树的在轨卫星故障诊断知识挖掘方法,能够提高知识的准确率同时降低误警率[24];Huang等针对燃料电池发动机的故障诊断,提出一种结合了C4.5决策树和故障诊断专家系统的诊断方法,原始数据在经过数据预处理和特征选择后,导入训练集,将规则存储在知识库,对故障进行分类,实现燃料电池的故障诊断[25];Feng等提出一种基于决策树的变压器绝缘故障诊断新的方法,不仅具有快速的归纳学习能力和分类速度,而且能有效压缩数据和内存[26]。
决策树算法在信息增益进行选择时,可能出现的偏向问题,会对取值较多的属性有所偏向,在某些特殊的情况下,通过其确定出的信息使用价值并不高,因此可以与其他算法结合,实现更好的故障诊断。刘伟等提出一种基于决策树与模糊推理脉冲神经网络的输出电网故障诊断方法,结果表明该方法在单类型和多类型故障信息丢失时,依然能够正确诊断出故障元件[27];王同辉等针对某型号的变流器在工作过程中出现逆变过流故障的原因进行分析,提出了一种基于EOVW指数和决策树相结合的系统诊断方案,利用小波分析算法提取变流器的输出电压、电流等信号特征,基于决策树的数据挖掘思维和分类功能,实现了对变流器逆变过流故障的识别和有效定位[28];Sumana De等基于案例推理方法设计,采用决策树和雅克卡相似度方法,决策树用于将案例存储到案例库库中,Jaccard相似度算法计算新案例和存储案例之间的相似度,将案例聚类成决策树,有利于与提高汽车故障诊断效率[29]。
3.2 基于支持向量机的故障诊断方法
支持向量机(Support Vector Machine)是一种基于统计学习理论的有监督学习方法,在1995年由前苏联教授Cortes和 Vapnik提出,由于在分类任务中的卓越性能,很快成为机器学习的主流技术。与传统学习方法不同,支持向量机通过寻求最小结构化风险来提高学习机的泛化能力,实现经验风险和置信范围的最小化,在统计样本量较小的情况下,达到良好统计规律目的,主要用于分类和回归问题。例如,训练样本中有两类标识过的样本点,根据支持向量机算法建立训练模型,模型可以将实心点和空心点代表两类样本,H代表最优分类线,H1和H2与H平行,且同时经过距离最优分类线最近的点,分类间隔指的是H1和H2之间的距离。对于高维数据集(N),则需要N-1维的对象对数据进行分隔,这个对象就是超平面,从概念上说,支持向量是那些离分隔超平面最近的数据点,它们决定了最优分类超平面的位置。支持向量机算法的目标就是最大化支持向量到分隔面的距离,求解最优超平面(能够将样本数据准确地分开,同时使得分类间隔最大)。由于支持向量机方法在小样本、高维模式识别以及非线性问题中所表现出的优异性能在故障检测与诊断领域引起了广泛研究。
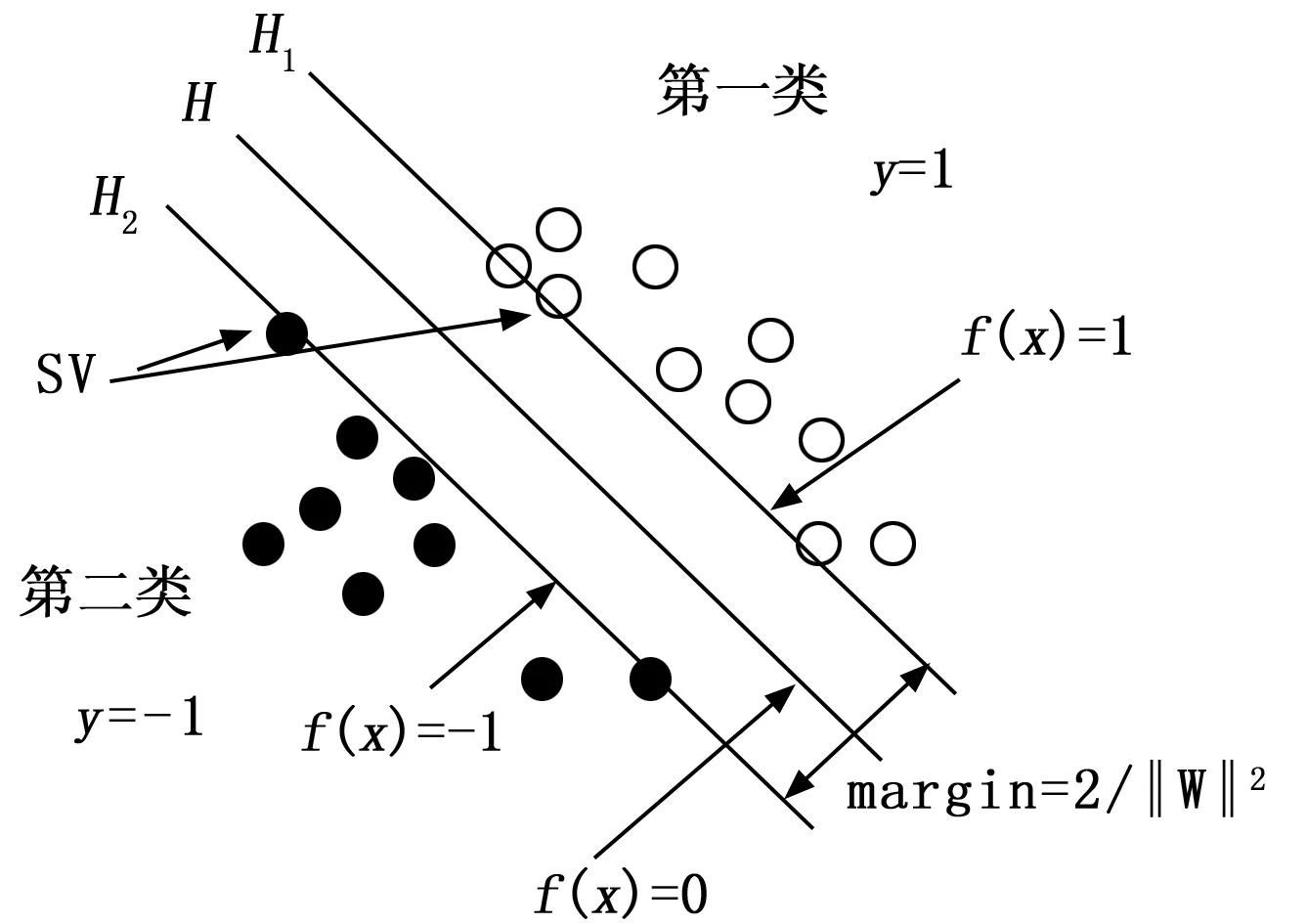
图5 支持向量机最优超平面
Poyhonen S等将支持向量机算法应用于在电机故障诊断,成功将电机健康功率谱和故障功率分类,识别出故障[30];Gao JunFeng等将SVM用于往复式泵阀门故障诊断中,能够识别和诊断故障阀门的故障类型和位置,与BP神经网络相比,SVM在机械故障检测中具有更大优势[31];肖健华分析了支持向量机模式分类的原理,指出最优分类面上的样本相对于两类误判而言是等概率的而非等风险的,提出了诊断可信度函数,并在特征空间中,对最优分类面进行重新设计[32];胡寿松根据SVM能在训练样本很小的情况下达到分类推广的作用,将其作为残差分类器得到故障检测与诊断信息[33]。
为了弥补支持向量机算法在故障检测与诊断中的不足,会将其与其他算法进行结合优化改进,提高其在故障诊断中的精度和效率。Li等在了解了多尺度动态熵仅考虑低频分量中的故障信息,可能会丢弃隐藏在高频分量中的故障信息,提出了一种基于分层动态熵和支持向量机的滚动轴承故障诊断方法,可以有效提取高、低频分量中的故障信息[34];Zhou等针对现有模型在少量训练样本可用时的故障识别准确率不高,提出了基于集合经验模态分解、加权置换熵和改进支持向量机集成分类器相集合的故障诊断方法,该方法可以有效检测轴承故障[35];阮婉莹等则是针对滚动轴承故障振动信号特点(非平稳性、低信噪比),而变分模态分解排列熵可以将非平稳信号分解转化成若干平稳模态分量,经过粒子群算法优化的支持向量机在小样本、非线性和高维模式识别问题中优势明显提高,因此提出了基于变分模态分解排列熵和粒子群优化支持向量机的故障诊断方法,提高了滚动轴承故障诊断准确率[36];Gangsar针对某些电机工作条件下,存在数据或信息有限的问题,因此提出了基于小波包变换与SVM相结合的故障诊断方法,同时考虑了不同小波的影响,成功用于检测和隔离感应电动机的各种故障[37];Liu等根据不同的数据来源,分别通过KNN检测异常值以及KNN识别边界点两种方法来定义支持向量机中的分类超平面,用于解决故障检测中的计算负担、不平衡数据与异常数据的问题,并对高速列车的制动系统进行故障诊断[38];何庆飞等提出了一种基于灰色理论和支持向量机的液压泵故障诊断和寿命预测的方法,在了解基于支持向量机算法所建立的模型精度较低等缺陷后,利用灰色累加生成操作对原始数据进行处理以增强数据的规律性,使用最小最终误差预测准则来确定嵌入维数和相关参数,使用支持向量机进行预测,最终利用灰色累减生成操作对预测数据进行还原,得到预测结果,灰色支持向量机预测性能与灰色模型、单一支持向量机模型相比最优[39]。
3.3 基于神经网络的故障诊断方法
现代设备日趋大型化、复杂化、自动化和连续化,在设备或系统工作过程中采集的数据通常具有维度高数据大(在每个采样的时间点可能会得到几十或上百个维度)、时间序列鲜明以及数据集不平衡等3个特点。神经网络具有自学习能力、非线性映射能力、对任意函数逼近能力、并行计算能力和容错能力,正好可以基于这些数据进行故障诊断。神经网络用语故障诊断的步骤通常如下:
1)通过信号监测与分析,抽取反映被测对象的特征参数作为网络的输入;
2)对被测对象的状态进行编码;
3)进行网络设计,确定网络层数和各层神经元数;
4)用各种状态数据组成训练样本,输入网络,进行训练,确定个单元的连接权值;
5)把待测队长的特征参数作为网络的输入,根据输出确定待测对象的状态类别。
本文主要介绍两种方法:卷积神经网络(convolutional neural networks,CNN)和递归神经网络(recurrent neural networks,RNN)。
3.3.1 基于卷积神经网络的故障检测与诊断
卷积神经网络(CNN)是有一种监督学习方法,最初由Yann Lecun 于1994年提出,并首次将其用于手写数字识别[40],也是第一批能使用反向传播有效训练的网络之一。该模型是一种特殊的多层感知器或前馈神经网络,通常包含输入层、卷积层、池化层、全连接层和输出层,卷积层通过将输入数据通过核函数进行卷积输出特征映射;池化层主要是通过池化函数对该层的输入进行调整,减少模型的可训练参数,提高统计效率并且减少对参数的存储需求;全连接层通过整合所有的局部特征进而得到全局特征,用于后续分类。CNN网络的训练类似于传统的人工神经网络训练方法,采用BP算法将误差逐层反向传递,使用梯度下降法调整各层之间的参数。CNN可对输入进行提取,得到局部特征并逐层组合抽象生成高层特征,可有效实现故障诊断与识别[41]。其能够避免对图像、语言等大量复杂信号的前期处理工作,输入的直接是原始数据,并从中学习到不同层级的特征,近年来卷积神经网络在多个领域都得到应用,如语音识别、人脸识别、通用物体识别、运动分析甚至脑电波分析方面等。
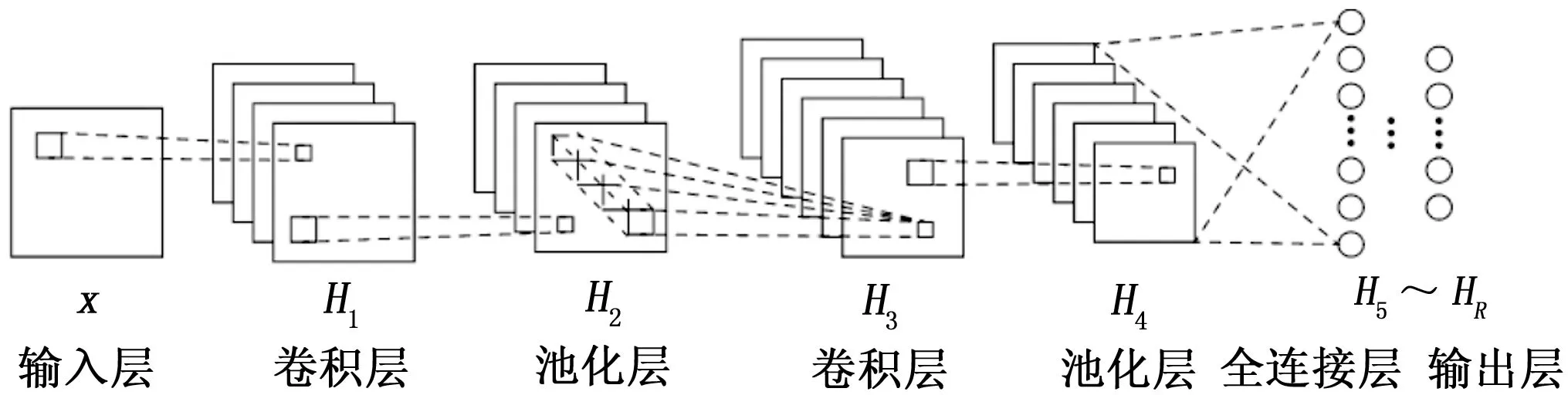
图6 卷积神经网络结构图
基于CNN算法的优越性,即使仍处于探索阶段,但是已经有很多研究人员将CNN成功应用于故障诊断中。魏东等首次提出了采用具有两个分类器的CNN网络结构,这样就有两个输出序列,该方法只用了一个网络结构就实现了对两种非独立分类问题的分类,因此就可以解决两个故障诊断选项中的非独立分类问题[42];Olivier Janssens等则采用卷积神经网络的方法从数据中自动学习用于轴承故障检测的特征,实现齿轮箱的故障检测与分类问题,与基于随机森林分类器的故障诊断准确率相比,有明显提高[43];而zhi等人针对基于齿轮箱的振动信号对故障的敏感,提出了一种基于CNN算法的齿轮箱故障识别和分类的实现方法,通过振动对信号进行预处理,使得能量在频谱峰值处保持其形状,与专家经验系统等传统的故障诊断方法相比,具有可靠性高以及分辨率高等优点[44];Appana 等提出了一种基于声发射 分析的轴承诊断方法,利用 CNN 自动提取包络谱中的滚动轴承缺陷特征信息,实现故障诊断[45];曾雪琼等使用小波变换、变换、短时傅里叶变换3种时频方法,将故障信号转换成时频谱图作为 CNN的输入,通过分析时频图实现变速箱的智能故障诊断[46]。程诚等利用卷积神经网络在识别位移、缩放以及其他形式扭曲不变性的二维图形的优势,提出了一种结合雷达图和CNN分类算法的故障诊断算法,该算法利用雷达图对数据进行可视化表示并将其转换为二维图像数据,建立合适的卷积神经网络模型,使其能够根据雷达图提供的信息进行故障诊断,该方法已经成功应用于工业过程[47];Jing等提出了一种能够自适应地从原始数据中学习特征并发现新的故障敏感特征的特征自动提取方法,卷积神经网络能够直接学习振动信号的频率数据(原始数据、频谱数据以及组合时频数据)从而提取特征参数,该方法已经成功对某型号的齿轮箱进行了故障诊断,与其他诊断方法相比,CNN有更高的诊断精度[48];张伟为了检测轴承故障,直接利用卷积神经网络处理时域振动信号,通过分析振动信号的特点,提出了一种卷积神经网络框架WDCNN模型,构造了第一层大卷积核以及多层小卷积核的WDCNN模型,在CWRU数据库上的识别率可以达到100%[49];Guo Xiaojie等提出了一种基于改进算法的分层学习速率自适应深度卷积神经网络,并将其应用于轴承故障诊断和严重程度判定中,根据测试设备的轴承故障数据样本对神经网络进行多次训练,最终表明该方法在故障模式识别和故障规模评价方面有着很好的效果[50]。
3.3.2 循环神经网络(RNN)
循环神经网络是从大脑皮层中关于记忆的神经回路和循环反馈系统研究中获得的灵感。一般的神经网络中,虽然层与层之间的节点是有连接的,但同一层内部的节点不连通。RNN具有一个循环结构,使得网络在某时刻k的输出不仅与k时刻的输入有关,还和k时刻以前的输出有关,这使得RNN有一定的记忆力,能够获取多个时间步以前的信息。RNN与处理序列和列表类数据密切相关,能够挖掘数据中的时序信息,具有充分利用语义信息的深度表达能力,在语言模型和文本生成、机器翻译、语音识别、生成图像描述和时频标记等方面有出色的应用,但是不能很好的处理长时依赖的问题。目前应用于故障诊断领域的有Elman、长短期记忆(LSTM)和门控循环单元(GRU)3种循环神经网络,其中作为RNN变体结构的LSTM和GRU的应用最多,这些变体网络可以帮助解决 RNN 中零点梯度的消失问题。
RNN能够提高故障诊断效率,同时改善了现有神经网络故障诊断方法,使其能够适用于复杂设备或系统的实时故障诊断,具有收敛速度快、精度高、稳定性好、扩展性好等优势。Azzam I等提出了一种无线传感器网络动态模型及其在传感器节点故障检测的方法,基于 RNN算法模型对传感器、传感器节点的动力学以及传感器的内部连接耦合性进行建模,神经网络的输入包括传感器模型的先前输出以及相邻传感器的当前和先前输出,神经网络输出和拓扑结构(基于反向传播型)在一般非线性传感器模型的基础上进行改进,并与卡尔曼滤波方法进行比较,该方法有着更高的检测诊断效率[51];Talebi等采用两种RNN分别识别一般未知的执行器和传感器故障,在非线性系统的状态和传感器不确定性较大或含有干扰的情况下,根据修改的反向传播方案更新神经网络的权重,考虑了地球低轨道卫星姿控系统中用于姿态确定和控制的磁力矩型制动器和磁强计型传感器,并在姿控系统的故障诊断中验证了该方法的有效性和准确性[52];Piotr等研究了基于循环神经网络和混沌工程进行鲁棒性故障检测的问题,提出的方法中的主要部分是由复杂的动态神经单元组成的局部循环网络,可获得混沌行为,采用全局和局部优化方法的双相策略,为了提高效率,混沌工程与退火算法相结合,同时提出了残差评价的递归量化分析,并在对模拟工业数据的建模任务中对该方法进行了验证[53];Yuan等提出了一种基于长短期记忆神经网络在复杂操作、混合故障和强噪声的情况下获得诊断和预测的方法,并通过3种不同的RNN变体(简单的RNN,LSTM,GRU)对NASA提供的飞机涡轮发动机健康监测数据集进行测试,结果证明LSTM在故障诊断和剩余使用寿命的效果最好[54];循环神经网络(RNN)能够很好地处理序列数据以及可变序列数据的能力,被广泛应用于数据识别等方面,但RNN存在梯度弥散或梯度爆炸问题导致无法解决长期依赖问题,而LSTM可以通过防过拟合、小批量组合、自适应学习率等优化技术建立长时依赖模型,许寅使用LSTM对航天器的实测数据进行学习和预测,可以实现航天器在轨状态的高精度的中长期预测[55];牛哲文等提出一种风功率预测模型,该模型以风电场风功率历史数据以及风速、风向等数值天气预报数据作为输入对风功率进行预测,考虑到风功率预测中输入数据的波动性和不确定性,在传统门控循环单元(GRU)神经网络的基础上融合卷积神经网络(CNN),以提高模型对原始数据的特征提取和降维能力,并引入dropout技术减少模型中的过拟合现象,结果表明在短期风功率预测精度和运算速度方面要优于LSTM[56]。
4 结束语
机器学习已经成为当前技术发展热点,并由于其良好的自学习、识别、分类能力,在故障检测与诊断技术中受到了越来越多的关注。本文系统介绍了机器学习和故障检测以及故障诊断的概念、分类,深入了解了基于机器学习的故障检测与故障诊断方法。重点介绍了基于PCA和随机森林的故障检测方法,给出了两种方法的基本思路以及国内外的研究现状;基于机器学习的故障诊断方法主要包括决策树、支持向量机以及神经网络,将重点放在最近比较新的CNN和RNN在故障诊断中的应用,给出了这几种方法的研究现状。通过对相关文献的梳理总结,机器学习在机故障检测和诊断领域仍有如下几个方面需要研究:
1)目前在故障检测与诊断领域应用的机器学习方法还是根据设备或系统的历史故障数据进行训练,必须要将故障数据累积到一定量才能进行分析,但是故障数据的完整收集难以实现,如何根据有限的故障数据进行故障分析预测将会是今后发展的一个重要趋势;
2)目前的方法大多是基于大量的离线数据进行分析,数据采集过程随着先进仪器设备的发展也会越来越容易,如何对海量数据进行压缩、提取等数据预处理技术,以及在线实时数据分析的技术方法的发展,将直接影响到后续基于数据的故障检测与诊断;
3)机器学习算法的运用现状还仅仅局限于材料试件与局部构件,设备的复杂度、精细度以及设备间的耦合,距离实现重大设备或系统整体的故障检测和诊断还有较大的差距,这是未来机器学习算法需要突破的一个重大难点;
4)机器学习模型多种多样,每种模型都有自己的优缺点,同时机器学习又具有良好的学习能力,这是实现智能故障诊断的一个有力武器。如何能够实现机器学习各模型间的有效结合,扬长避短,可能是未来研究的一个方向;
5)由于信号处理方法可以诊断针对采集到的原始收据进行分析,基于分析模型的方法可以涵盖系统的各种机理知识、数据知识和经验知识,而机器学习则可以实现故障诊断的自学习,因此可以对这3种方法的方法进一步融合,如何使得三者相互支持、相互补充将会成为一个有意义的研究方向。
猜你喜欢
汽车实用技术(2022年16期)2022-08-31
舰船科学技术(2022年11期)2022-07-15
汽车实用技术(2022年9期)2022-05-20
新高考·高一数学(2022年3期)2022-04-28
科学与信息化(2019年28期)2019-10-21
科学与财富(2016年32期)2017-03-04
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
决策与信息·下旬刊(2013年1期)2013-03-11
