
大数据环境下多维传感器数据融合算法研究
2021-04-08 01:55杜春晖李亚杰张连连
现代电子技术 2021年7期
葛 宇,杜春晖,李亚杰,张连连
(河北建筑工程学院 电气工程学院,河北 张家口 075000)
0 引 言
随着各种物联网智能设备、各种传感器的普及,云计算硬件性价比的提升、运算与运行速度的提升及存储成本的降低,数据存储、清洗、挖掘及分析等数据处理手段的优化,特别是分布式系统基础架构Hadoop 的出现,Hadoop分布式文件系统(Hadoop Distributed File System,HDFS)的诞生,MapReduce 的成熟,Spark、Storm、Impala等各种技术进入人们视野,为海量数据存储、海量数据并行计算提供了支撑,新技术的发展为大数据带来了曙光[1-4]。
随着数据采集终端设备各种传感器的数量剧增,由多维传感器产生的数据规模急剧膨胀,包括金融、交通、能源、零售、电信、餐饮等各行业累积的数据量迅速增多,数据类型也越来越丰富、复杂,传统的数据管理系统、数据处理模式已无法满足新业务的需求[5-7]。如:来自大量传感器的多维数据;来自智能终端拍照、拍视频多媒体数据;微博、微信数据;科学研究多结构数据等,积累了海量数据。Twitter 平均每天发布超过5 000 万条消息,Google 平均每天需要处理将近30 PB 的数据,全球网民一天在Facebook 上总共花费234 亿分钟,移动互联网要处理的数据高达44 PB,全球每秒平均发送近300 万封电子邮件,平均每天上传3 万个小时的视频至YouTube,互联网每天产生的数据总量,足以刻满6.5 亿张DVD[8-9]。
以电子邮件为例,如果一分钟读一篇邮件,那么一天产生的邮件足够一个人昼夜不停地阅览6 年,由此可见数据量之大,前所未有。这些包罗万象的、海量的数据,不仅仅数据量大,而且种类繁多,既包括结构化的数据库系统数据,更多的是非结构化的报表、图片、视频、图像及音频数据,这些海量数据可能是多余的数据、割裂的数据、片面的数据,数据来源广、维度多、类型杂。需要进行数据融合技术如数据的组合、整合及聚合等方法更全面、客观地反映客观事物,以辅助人们正确决策[10-14]。
1 数据融合原理及基本步骤
将多维传感器产生的数据进行数据融合,能够产生比单一信息源更精确、更完全、更可靠的数据。数据融合分为预处理和数据融合两步。
1.1 预处理
1)外部校正,去除外部地形、天气、气压、风速等外部噪声引起的对结果数据的影响,外部校正的目的主要在于去除外部随机因素对测量数据结果一致性的影响。
2)内部校正,去除由于各个传感器灵敏度、分辨率等自身参数差异引起的对结果数据的影响,内部校正的目的主要在于消除由不同传感器得到的数据差异。
1.2 数据融合
根据不同的数据融合目的及数据融合所处层次,选择恰当的数据融合算法,将提取的特征或多维数据进行合成,得到比单一传感器更准确的表示或估计。
1.3 数据融合的一般步骤
数据融合一般包括以下6 个步骤:连接多源数据库获取数据、对所获数据进行研究与理解、对数据进行清洗和梳理、数据转换与建立结构、多维数据组合、建立分析数据集。数据融合的一般步骤如图1 所示。
2 数据融合分类
根据数据融合前后数据的信息含量进行分类,可将数据融合分为有损融合和无损融合。无损融合中去除冗余数据,所有数据细节均被保留。有损融合则通过减少存储数据量、降低数据分辨率等方式,压缩数据量减少传输量,但前提是融合后的数据保留所需的全部信息。
根据数据融合的操作对象级别从高到低分为:决策级融合、特征级融合及数据级融合。
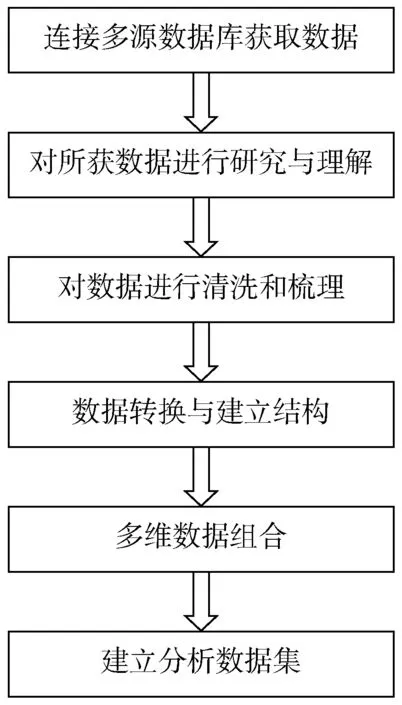
图1 数据融合的一般步骤
1)数据级融合
操作对象是最前端的数据,对传感器采集到的原始数据进行处理,是最底层的融合。在图像目标识别时,该级别的融合是对原始图像像素进行融合。该融合处理的数据量特别大,数据处理代价高,处理时间长,实时性及抗干扰性差。由于处理的是传感器的一手数据,由于传感器采集数据的不稳定性、不确定性,要求该数据融合具有一定的纠错能力。
常用的数据级数据融合方法有:小波变换法、代数法、坎斯-托马斯变换(Kauth-Thomas Transformation,K-T)等。
2)特征级的数据融合
特征级数据融合面向监测对象特征的融合,从传感器采集到的原始数据中提取特征信息,用以反映事物的属性,以便进行综合分析和处理,是数据融合的中间环节。
特征级数据融合一般流程为:首先对数据进行预处理,然后对数据进行特征提取,再对特征提取后的数据进行特征级融合,最后对融合后的数据属性进行说明。特征级数据融合的一般流程如图2 所示。
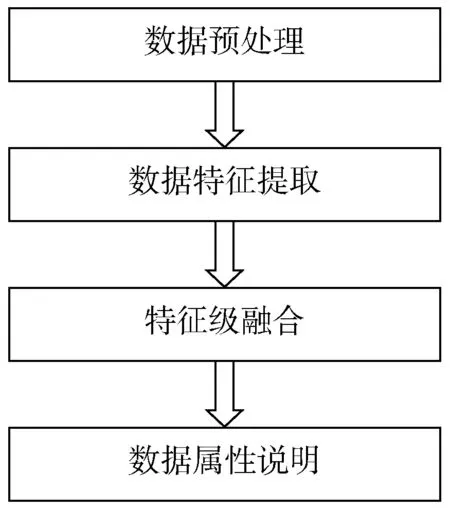
图2 特征级数据融合的一般步骤
3)决策级数据融合
在底层两级数据融合的基础上,对数据进行特征提取、数据分类及逻辑运算,为管理者决策提供辅助。所需的决策是最高级的数据融合。该级别数据融合的特点是容错性、实时性好,当一个或几个传感器失效时,仍能做出决策。
决策级数据融合一般流程为:对数据进行预处理,然后对数据进行特征提取,再对特征进行属性说明,对属性进行融合,最后对融合属性进行说明。决策级数据融合的一般流程如图3 所示。
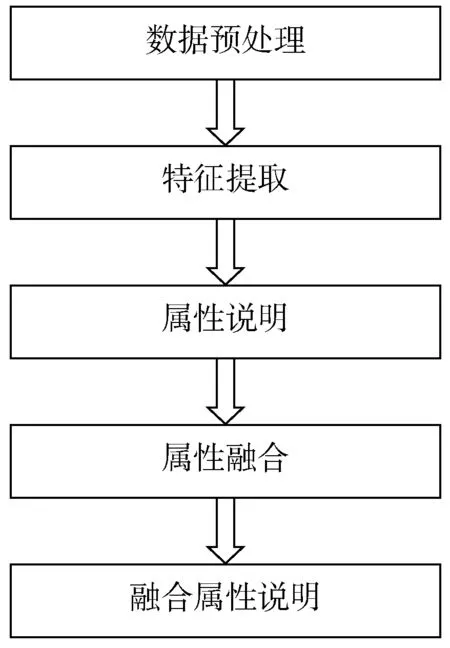
图3 决策级数据融合的一般步骤
3 基于深度置信网络的数据融合算法
深度置信网络(Deep Belief Network,DBN)与传统的神经网络类似,是在观察数据和标签之间的联合分布基础之上的概率生成模型。网络中存在隐含层,隐含层间的神经元采用全连接,隐含层内的神经元之间没有形成连接。最上面两层中包括标签神经元,两层之间为无向连接,称其为联合记忆层。除了联合记忆层之外,其余各层为有向连接,自上而下为生成模型,自下而上为判定模型。DBN 是机器学习的神经网络,模型通过训练得到各个神经元之间的权值,从而让整个网络得到最大概率的训练数据。DBN 的使用范围广、网络扩展性强,是常用的学习算法之一,经常用于语言识别、图像识别等领域,可用于监督学习与非监督学习。
3.1 DBN 结构
DBN 结构如图4 所示。DBN 最上层为联合记忆层,下面是隐含层,隐含层下是受限玻尔兹曼机(Restricted Boltzmann Machine,RBM),RBM 是1986 年由斯摩棱斯基发明的基于数据集学习概率分布的神经网络模型。训练DBN 是一层一层进行训练的,在每一层中,采用数据向量推断隐含层,然后再把这一隐含层作为下一层的数据向量。训练RBM 的过程,实际上是寻找最佳权值的过程。
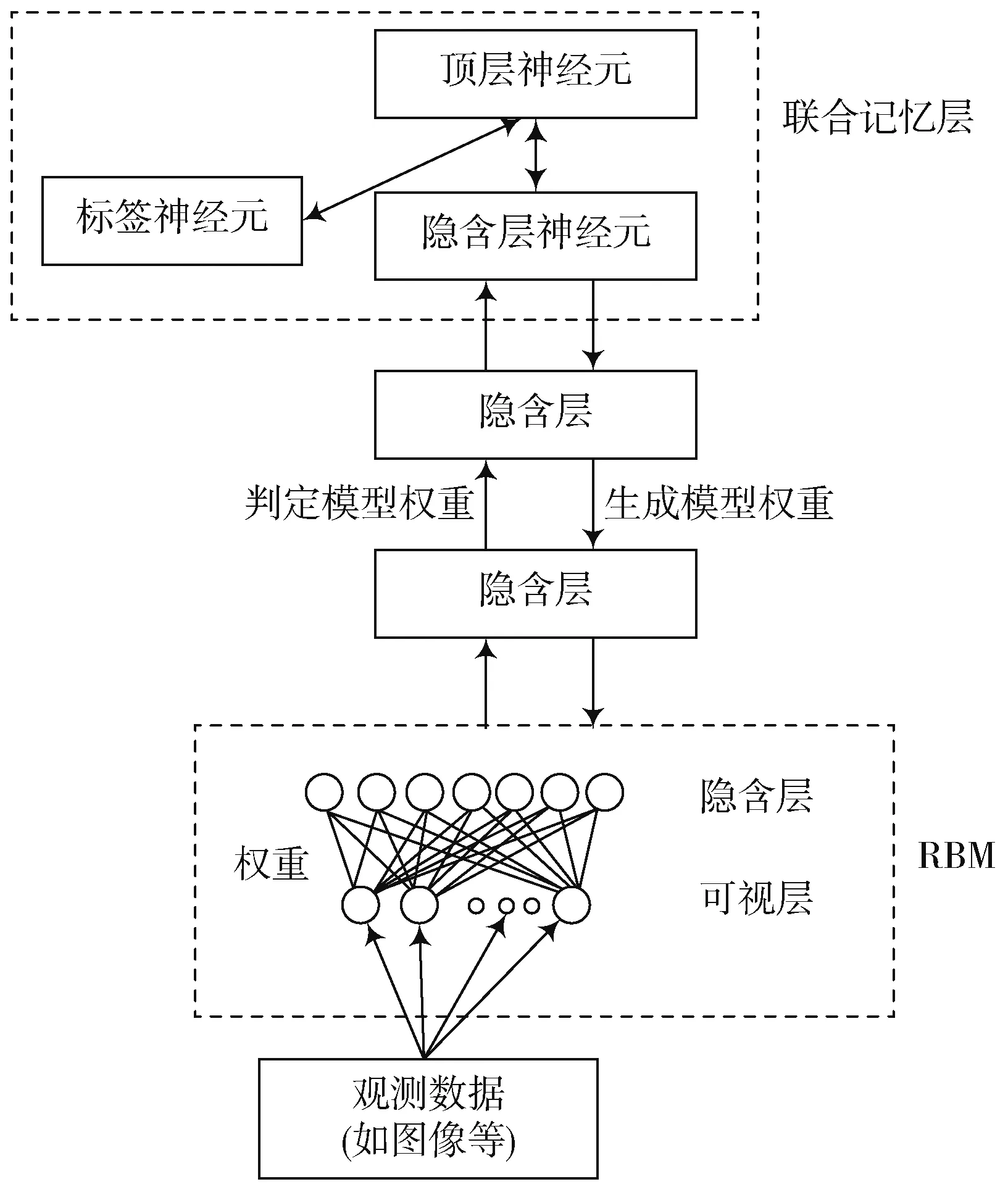
图4 DBN 结构
3.2 DBN 训练过程
DBN 算法训练过程如下,首先训练第一个RBM,固定第一个RBM 的权重、偏移量,并将其隐形神经元的状态作为第二个RBM 的输入。然后训练第二个RBM,并将第二个RBM 与第一个RBM 堆叠。接下来,对其进行多次循环训练,连同代表标签的神经元一起训练,响应的神经元打开设置为1,否则设置为0。DBN 的训练过程如图5 所示。
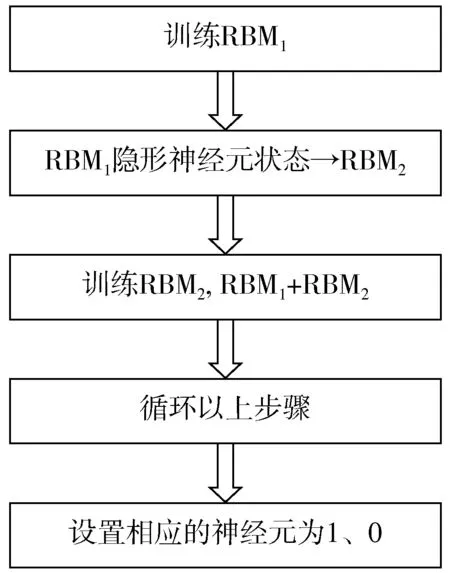
图5 DBN 训练过程
3.3 实验数据
实验中采用Matlab Deep Learn Toolbox 对收集的随机数据进行数据融合,实验初始化DBN 参数,并训练DBN 网络,实验的主要参数如表1 所示。程序运行结果如图6 所示。
实验中,隐含层层数为100 层,节点数量为100 个,权重矩阵为784×100 的矩阵,学习速率为2,动量为0.5,样本数为100,迭代1 次。通过Matlab Deep Learn Toolbox 得到平均重建误差为65.779 8。各个时段耗费时间图如图7 所示,各个时段耗时参数表如表2 所示。
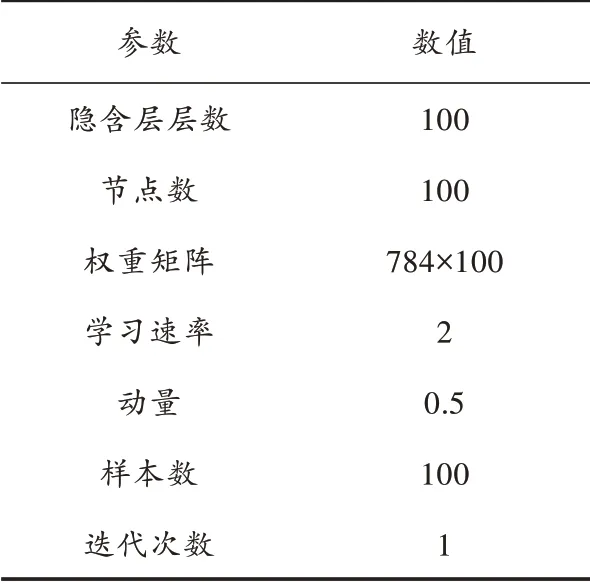
表1 实验主要参数表

图6 程序运行结果
图7 各时段耗费时间图
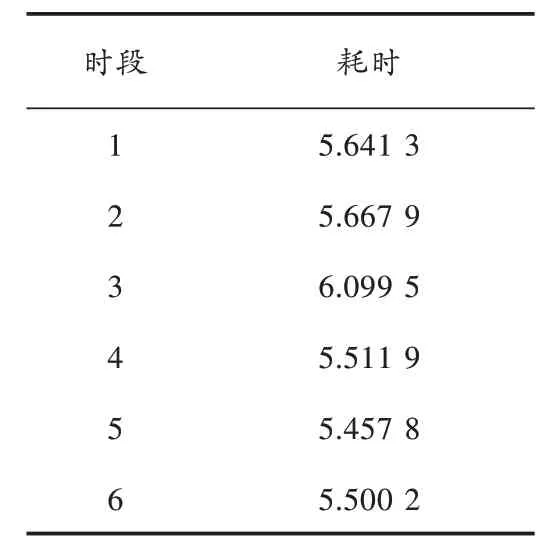
表2 各个时段耗时参数表
4 结 语
本文在大数据背景下,论述了多维传感器数据融合原理及基本步骤,并分析了数据融合的分类及常用数据融合方法。随后重点阐述了DBN 算法的结构及训练过程,并通过DBN 算法对随机采集的多维传感器数据集进行实验,通过实验对算法的有效性进行了验证,对算法进行了评估。
猜你喜欢
自然杂志(2021年6期)2021-12-23
纺织科学研究(2021年9期)2021-10-14
北京大学学报(自然科学版)(2021年3期)2021-07-16
东北师大学报(自然科学版)(2021年1期)2021-03-27
电脑爱好者(2020年19期)2020-10-20
电子制作(2019年13期)2020-01-14
中学生数理化·七年级数学人教版(2019年6期)2019-06-25
现代装饰(2018年5期)2018-05-26
电源技术(2015年5期)2015-08-22
弹箭与制导学报(2015年1期)2015-03-11
