
融合语义信息的视频摘要生成
2021-04-13 01:59滑蕊吴心筱赵文天
北京航空航天大学学报 2021年3期
滑蕊,吴心筱,赵文天
(北京理工大学 计算机学院,北京100081)
随着视频拍摄、存储技术和网络传输的飞速发展,互联网上的视频数据呈爆炸性增长[1]。但由于生活节奏越来越快,观众在没有确定视频是否符合他们的期望前,不会轻易花太多时间观看完整视频,观众更期望可以通过视频预告等形式对视频内容产生大致的了解。视频摘要任务从原始视频中提取具有代表性和多样性的简短摘要,使观看者在不观看完整视频的情况下,快速掌握视频的主要内容。
早期的视频摘要方法[2-3]是基于无监督学习的,使用诸如外观或运动特征等底层视觉信息和聚类方法来提取视频摘要。近年来,深度神经网络[4-8]被用于视频摘要任务中,其主要致力于学习更具表示能力的视觉特征。这些方法将视频摘要任务建模为视频镜头子集的挑选,通过使用长短期记忆(Long Short-Term Memory,LSTM)单元来实现视频摘要的生成。
随着计算机视觉与自然语言处理的融合发展,视频文本描述等许多跨模态任务引起了研究人员的广泛关注。所以自然而然联想到通过添加文本内容到视频摘要任务中,利用语义信息对视觉任务进行监督从而获取视频摘要,部分近期研究[9-11]也开始研究视频摘要中包含的语义信息。文献[9]使用了视频主题或视频标题来提供视觉上下文信息,以标识原始视频包含的重要语义信息。文献[10-11]结合了自然语言处理领域中常用的一些方法,将语义信息添加到视频摘要中。但这些工作提出的框架相对简单,没有对语义信息进行充分利用。
本文提出一种融合语义信息的视频摘要生成模型,与现有的视频摘要方法不同,该模型在训练时,增加文本监督信息,从原始视频镜头中挑选出具有语义信息的镜头。首先,利用卷积网络提取视频特征并获得每帧对应的帧级重要性分数。其次,利用文本监督信息学习视觉-语义嵌入空间,将视觉特征和文本特征投影到嵌入空间中,通过计算跨域数据之间的相似性并使其靠近,从而使视觉特征可以学习更多的语义信息。本文还使用视频文本描述生成模块生成视频对应的文本摘要,并通过与文本标注真值进行比较来优化视频的帧级重要性分数。该模块在测试时仍可用,可以为测试视频生成对应的文本摘要。在测试时,现有的视频摘要方法只能获得视频摘要,而本文模型在获得具有语义信息的视频摘要的同时,还可以获得相应的文本摘要,可以更加直观地反映视频内容。
本文的主要贡献如下:
1)提出了一种融合语义信息的视频摘要生成模型,通过学习视觉-语义嵌入空间丰富视觉特征的语义信息,以确保视频摘要最大限度地保留原始视频的语义信息。
2)本文模型能同时生成视频摘要与文本摘要。这对于目前互联网视频的短片预告与推荐具有很强的现实意义。
3)在2个公开视频摘要数据集SumMe和TVSum上,相比现有先进方法,本文模型F-score指标分别提高了0.5%和1.6%。
1 相关工作
1.1 视频摘要
视频摘要方法可以分为早期的传统方法和近期的深度学习方法。传统方法一般利用机器学习,提取底层视觉特征,并利用聚类方法提取视频摘要。深度学习方法则利用神经网络获得更高级的视觉特征以指导视频摘要生成。Zhao等[6]对LSTM网络进行了改进,利用分层结构的自适应LSTM 网络提取视频摘要。Sharghi等[12]则在此基础上结合行列式点过程(Determinantal Point Process,DPP)优化了视频镜头子集的选择问题。针对递归神经网络占用资源过大、结构复杂不适合处理长视频等问题,Rochan等[13]使用全卷积模型代替递归神经网络,仅通过卷积网络对视频帧进行评价挑选也可以生成优质的视频摘要。
近年来,深度学习无监督视频摘要生成因其不需要依赖人工标注,引起了研究人员的关注。文献[14-16]中认为好的视频摘要能重建原始视频,采用生成式对抗网络(Generative Adversarial Networks,GAN)指导视频摘要的生成,生成器用于生成视觉特征,判别器度量摘要视频和原始视频之间的相似度,以此优化网络。在文献[17-18]中,强化学习被应用于无监督视频摘要,通过设计不同的奖励函数实现无监督视频摘要。但这些方法没有考虑视频内容的语义信息,仅通过无监督方法无法生成具有丰富语义信息的视频摘要,很难满足人们对准确反映视频内容的视频摘要的需求。
1.2 视频文本描述
视频文本描述(Video Captioning)旨在为视频生成对应的文本描述,最常用的模型为编码器-解码器(encoder-decoder)。该模型使用卷积神经网络(Convolutional Neural Network,CNN)或循环神经网络(Recurrent Neural Network,RNN)对视频进行编码获得视觉特征,然后使用语言模型对其进行解码获得文本描述。本文采用encoder-decoder模型,训练时最大化生成人工标注的概率指导包含语义信息的视频摘要生成,测试时使用该模块生成相应的文本摘要。
2 融合语义信息的视频摘要生成模型
本文提出了一种融合语义信息的视频摘要生成模型,如图1所示,该模型可分为3个模块:帧级分数加权模块、视觉-语义嵌入模块和视频文本描述生成模块。
在本节中,首先介绍视频摘要生成网络;其次将介绍网络的训练过程;最后展示了测试过程中如何同时生成视频摘要和文本摘要。
2.1 模型介绍
2.1.1 帧级分数加权模块
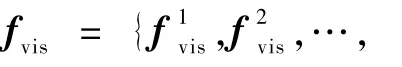
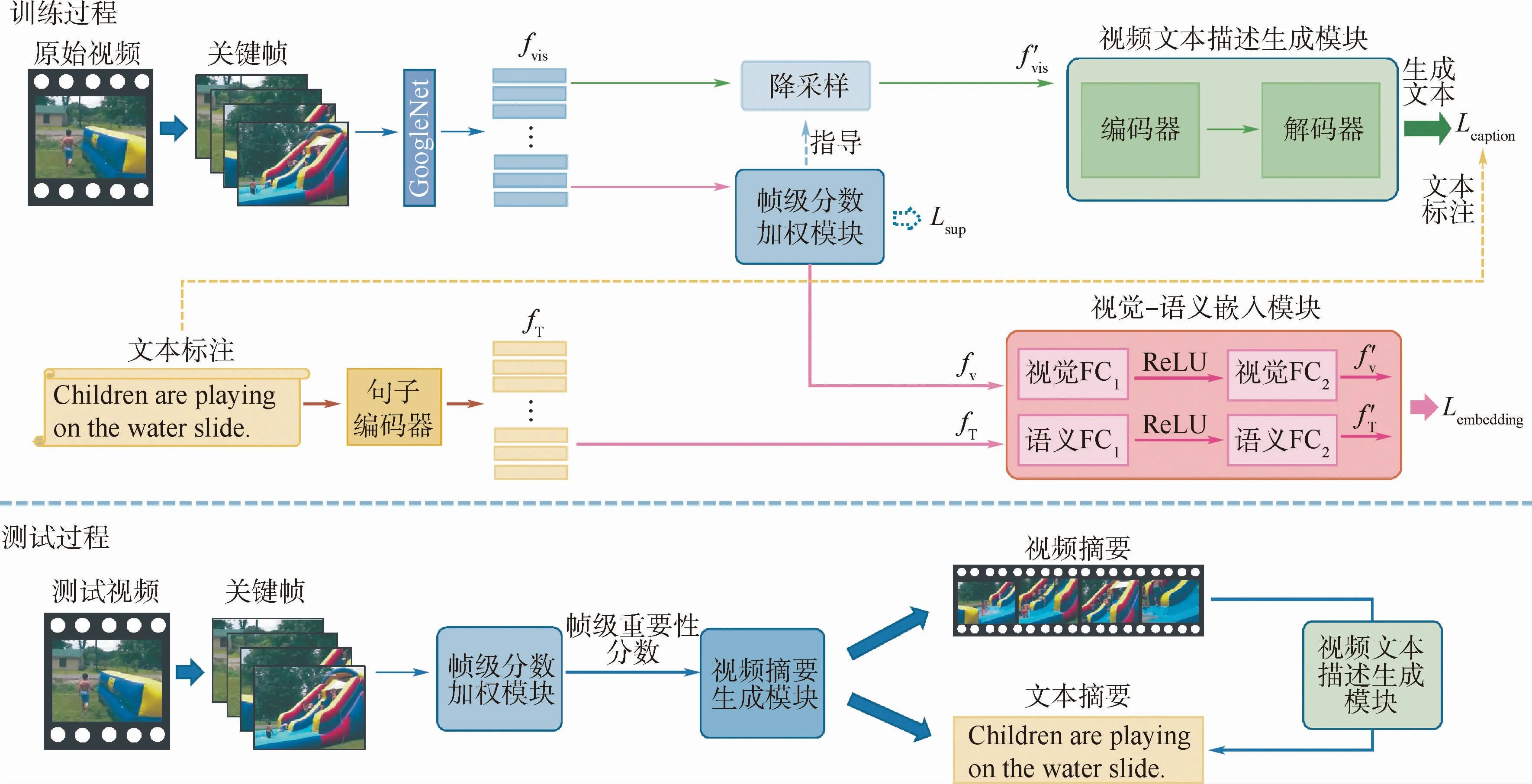
图1 融合语义信息的视频摘要生成流程Fig.1 Flowchart of video summarization by learning semantic information
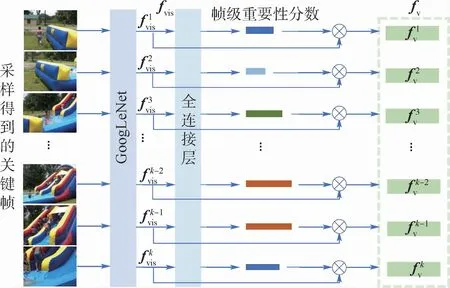
图2 帧级分数加权模块框架Fig.2 Framework of frame-level score weighting module

2.1.2 视觉-语义嵌入模块
本文为数据集中每个视频都提供了3~6句简明的文本标注。使用词嵌入表示文本中出现的单词,之后利用LSTM 网络处理词向量从而获得句子向量,该特征用fT表示。获得视频的视觉特征和文本特征表示后,将视觉特征和文本特征投射到一个公共的嵌入空间中,通过使文本特征和视觉特征相互靠近,丰富视觉特征中的语义信息。该模块共有2个网络分支,分别负责对视觉特征与文本特征进行处理,由于视觉特征fV与文本特征fT维度并不相同,通过2个具有非线性层的2层全连接网络分别对fV与fT进行映射,使特征达到相同维度。将每个视频的视觉和文字特征表示映射到嵌入空间中,分别用f′V和f′T表示,以使用各种度量标准来衡量投影的视觉和文本特征之间的相似性。本文中为了使2种特征彼此靠近,使用均方误差损失函数:
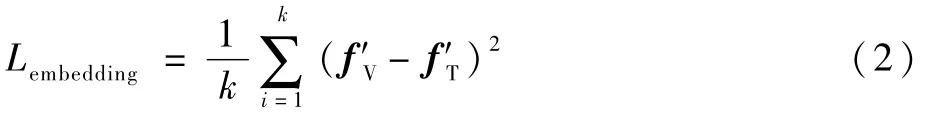
2.1.3 视频文本描述生成模块
本文使用encoder-decoder模型生成视频文本描述生成模块,视频文本描述生成模块可以最直观地展示网络是否拥有选择具有最丰富语义信息的镜头以生成视频摘要的能力。从原始视频关键帧中提取出的视觉特征fvis,将经过降采样操作后降维成f′vis后送入视频文本描述生成模块,降采样操作是通过帧级分数加权模块得到每帧对应的分数后,从中挑选出分数最高的前N帧所对应的视觉特征,按时序顺序排列后组成f′vis。
降采样操作必不可少,因为原始视频帧序列过长,且镜头变换丰富,包含较多的冗余信息,故将整个视频直接输入视频文本描述生成模块后编码器对视觉内容的编码能力会大大降低。降采样操作可以通过帧级重要性分数选择最具代表性的视觉特征,同时也可通过损失项的反馈调整帧级重要性分数,从而不断选择更好的关键帧用于文本生成,是十分必要的。
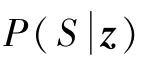

2.2 网络训练
本文使用Adam优化器训练模型,通过使用Adam逐渐降低损失项,以逐步更新网络的参数。
2.2.1 预训练
由于TVSum 和SumMe中包含的数据量很少,仅通过训练小样本数据无法达到文本生成的实验目的,因此利用现有的大型视频文本描述数据集对视频文本描述生成模块进行预训练。MSRVTT数据集[19]包含了10 000个视频片段,每个视频都标注了20条英文句子,视频平均时长约为10 s,视频内容采集自网络,包含各种类型的拍摄内容。实验证明,通过使用MSR-VTT对模型进行预训练确实可以有效缓解由样本不足引起的问题。
2.2.2 稀疏约束
为了充分利用SumMe和TVSum数据集提供的帧级重要性分数标注,本文还为网络添加了稀疏约束。稀疏约束的计算是利用在训练阶段关键帧计算获得的帧级重要性分数si,与数据集中提供的用户标注的帧级重要性分数^si进行交叉熵损失计算:
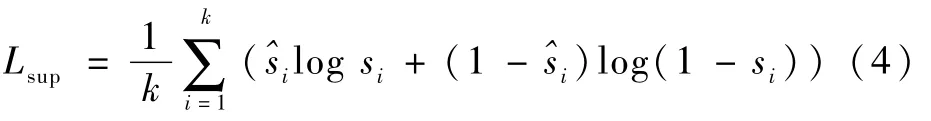
当利用稀疏约束时,训练网络的总损失函数为
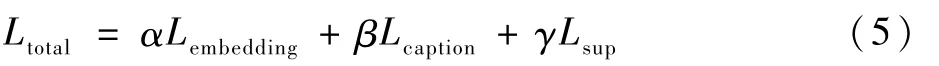
式中:α、β、γ均为需要人工调节的超参数,当不使用稀疏约束时,γ为0。
2.3 视频摘要生成与文本摘要生成
测试时,模型不使用文本标注和句子编码器,只使用训练时得到的视频文本描述生成模块来生成视频摘要和文本摘要。
对于视频分割,本文使用Potapov等[20]提出的KTS技术分割出不重叠的镜头。对于镜头重要性分数的计算,则是通过将镜头中包含的关键帧的帧级重要性分数求平均得到的。为了生成视频摘要,本文通过最大化镜头总分来选择镜头,同时确保视频摘要长度不超过视频长度的15%,实际上,选择满足条件的镜头这一问题等价于0/1背包问题,也称为NP困难(Non-deterministic Ploynomial Hard)问题。
在获得视频摘要后,本文将视频摘要中的帧级重要性分数排名前N的视觉特征,按时间顺序送入训练过程中获得的视频文本描述生成模块,来获得相应的文本摘要。
3 实验结果与分析
3.1 实验设置
3.1.1 数据集
本文在SumMe[21]和TVSum[22]数据集上评估模型。SumMe由25个用户视频组成,涵盖了各种主题,例如假期和体育。SumMe中的每个视频时长在1~6 min之间,并由15~18个人提供标注。TVSum包含50个视频,其中包括新闻、纪录片等主题。每个视频时长从2~10 min不等。与SumMe类似,TVSum中的每个视频都有20个标注,用于提供帧级重要性评分。
3.1.2 文本标注
上述2个数据集仅提供视频和帧级重要性分数,无法对视频长期语义进行建模。为此,为数据集TVSum和SumMe提供了文本标注,为2个数据集每个视频提供相互独立的3~6个简短的句子,以描述视频的主要内容。
3.1.3 评价指标
使用文献[23]中的方法对视频摘要进行评价,即通过度量模型生成的视频摘要与人工选择的视频摘要间的一致性来评估机器所生成摘要的性能。假设A为机器生成的摘要,B为人工选择的摘要,DA为A的持续时间,DB为B的持续时间,DAB为AB重复部分的持续时间,则精度P和召回率R分别定义为

用于评估视频摘要的F-score定义为
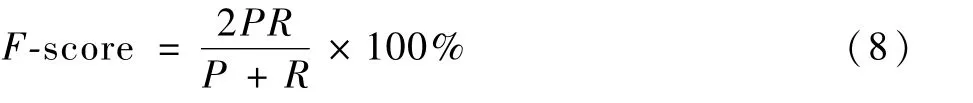
文本摘要通过图像描述任务中常用的3个指标来进行评价,分别为BLEU1、ROUGE-L和CIDEr。BLEU1用于判断句子生成的准确性,ROUGE-L用于计算句子生成的召回率,CIDEr则体现的是生成句子与人工共识的匹配度,以上指标越高证明句子生成效果越好。
3.1.4 实验细节
使用在ImageNet上预训练的GoogLeNet作为获取视频特征的网络模型,每个视频以2 fps(fps为帧/s)的帧率对关键帧进行采样。每帧图像特征维度为1 024,句子特征维度为512,在视觉语义视频嵌入空间中将共同被映射为256维的向量。描述生成模型的编码器和解码器为单层LSTM 网络,隐藏层维度设置为512。在大型视频文本描述数据集MSR-VTT上预训练视频文本描述生成模块,对其中每个视频都均匀采样40帧,所以框架中降采样参数N也设置为40。在联合训练中,为了实现在预训练模型上的微调,学习率设置为0.0001。将2个数据集分别进行训练测试,其中每个数据集中80%的视频用于训练,其余用于测试。
3.1.5 对比方法
选择了6种最新的视频摘要模型与本文模型进行比较:vsLSTM[4]、dppLSTM[4]、SUM-GANsup[5]、DRDSNsup[17]、SASUMsup[11]、CSNetsup[24]。vsLSTM 是 一种利用LSTM 的视频摘要生成模型,也是较为基础的一种模型。dppLSTM 同样是一种利用LSTM的视频摘要生成模型,它通过使用DPP来选择内容多样化的关键帧。SUM-GANsup是一种利用VAE和GAN的视频摘要生成模型。DR-DSNsup是一种无标签的强化学习视频摘要生成模型。SASUMsup是一个同样融合语义参与视频摘要模型。CSNetsup是另一种利用VAE和GAN的视频摘要生成模型。上述视频摘要模型均为有监督模型。
3.2 定量结果与分析
首先介绍本文方法的2种不同设置。
本文方法(无监督):本文提出的融合语义信息的视频摘要生成模型,没有任何稀疏性约束。
本文方法(有监督):由人工标注的视频摘要Lsup监督的融合语义信息的视频摘要生成模型。
如表1所示,与最先进的方法相比,本文模型具有更好的性能。本文无监督方法仅使用提供的带标注的文本描述,其结果几乎与其他带有人工标注的视频摘要的有监督方法相当。本文有监督方法在所有数据集中的表现优于所有引用的方法,F-score指标较目前效果最好的CSNetsup方法在2个数据集上分别提高了0.5%和1.6%,这证明融合语义信息的视频摘要确实能够生成更高质量的视频摘要。
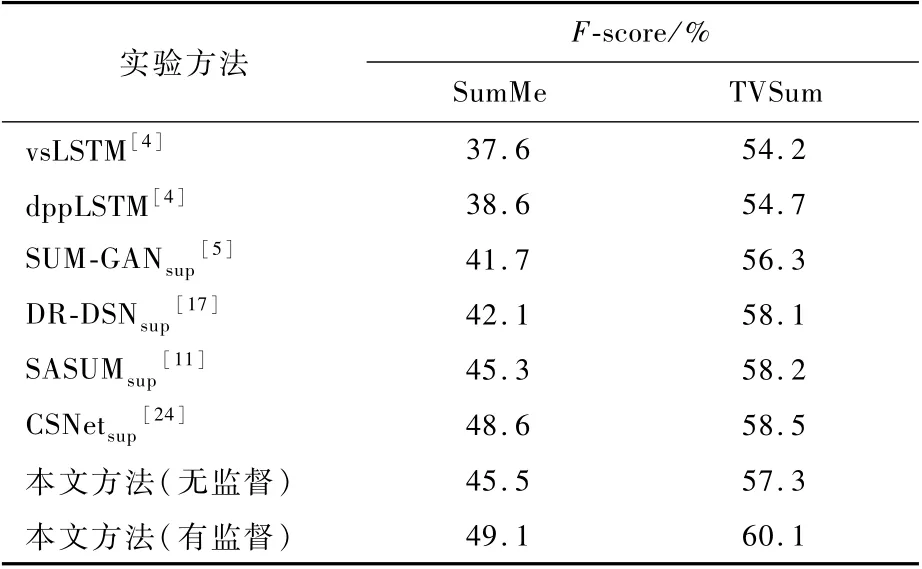
表1 与6个最新方法之间的F-score比较Table 1 Performance comparison(F-score)between our frameworks and six state-ofthe-art methods
接下来分析本文方法2种不同设置产生的实验结果。本文有监督方法的性能优于本文无监督方法2.8% ~3.6%。显然,这是因为本文有监督方法使用数据集提供的帧级重要性分数作为监督,因此相比于本文无监督方法生成的摘要,本文有监督方法生成的摘要与人工选择的视频摘要更具有一致性。
本文有监督方法在SumMe和TVSum上的表现分别为49.1%和60.1%,之所以在2个数据集上的性能具有较大差异,是因为SumMe的视频内容变化缓慢且场景中的对象很少,而在TVSum中场景是多变的。丰富多样的镜头可能会在视频摘要生成过程中占据更大的优势,如果整个视频都是过于相似的镜头,则会对镜头挑选的边界更加模糊,从而导致生成的视频摘要评分较低。
表2展示了在本文有监督方法中,不同评估标准下在SumMe和TVSum数据集上生成视频摘要的性能。可以看出文本摘要可以一定程度上描述视频内容,之后也会在3.4.2节中定性展示文本生成的效果。不过由于视频摘要任务数据集数据量过小,文本摘要性能受到了很大影响,容易生成结构较为单一的短句。

表2 不同数据集生成的文本摘要评测Table 2 Evaluation of text summaries generated by different datasets
3.3 消融实验
为了验证视频摘要模型中的视觉-语义嵌入模块和视频文本描述生成模块,本文在TVSum数据集上进行消融实验,通过分别从模型中排除不同模块来展示每个模块对网络性能的贡献。此外,如果不使用这2个模块中的任何一个,则该问题将归结为最基本的视频汇总问题,即损失函数只能使用Lsup。为了保持实验参数的一致性,本文将采用有监督方法来进行消融实验,以确保Lsup可用。从表3数据中可以看出,应用不同模块时F-score分数将逐渐增加,当2个模块同时应用时达到实验的最优结果。这证明本文提出的2个模块确实能够指导具有语义信息的关键帧获得更高的帧级重要性分数,从而生成更优质的视频摘要。

表3 TVSum 数据集上的消融实验结果Table 3 Results of ablation experiment on TVSum
3.4 定性结果与分析
3.4.1 视频摘要示例
选择用TVSum数据集中一则“宠物美容”相关新闻视频来展示视频摘要的生成情况。图3(a)展示了原始视频内容,可以看到原始视频除宠物美容相关镜头外,还包含新闻片头片尾、采访路人等画面。图3还分别展示了本文无监督方法、本文有监督方法、本文有监督方法但不含视频文本描述生成模块、本文有监督方法但不含视觉-语义嵌入模块4种设置下,从原始视频中挑选的视频摘要情况。图中浅色条形图表示人工标注的帧级重要性分数,深色条形图表示该设置下挑选的视频摘要。
从图3(b)~(e)可以看出,每种设置都能够很好地生成针对整个视频的视频摘要,挑选的视频摘要覆盖了人工标注的峰值,能够反映出原始视频是一则与宠物相关的视频,这表明本文模型可以从视频中提取出语义丰富的视频镜头,生成优质的视频摘要。
同时对比图3(b)与图3(c),发现本文有监督方法相较于无监督方法表现更好。由于稀疏约束的加入,相比于无监督方法只注重于挑选具有代表性的视频,本文有监督方法提取的视频镜头覆盖范围更广、彼此间隔更分明,生成的视频摘要富含语义信息的同时还具有镜头多样性。
在图3(c)~(e)几种有监督设置中,利用全部模块的设置表现最佳。在缺失部分模块的情况下,虽然摘要的代表性与多样性依然较好,但还是容易挑选与语义信息不相关的镜头。如图3(d)与图3(e)中,2种设置下的模型都将新闻的片头画面挑选为视频摘要,而应用全部模块的有监督方法挑选的摘要几乎不含这些无关镜头,这也正与3.3节中的消融实验结果相对应。
关于视频摘要的定性结果展示视频可前往https://github.com/huarui1996/vsc进行观看,后续更多相关数据也会在此开源。
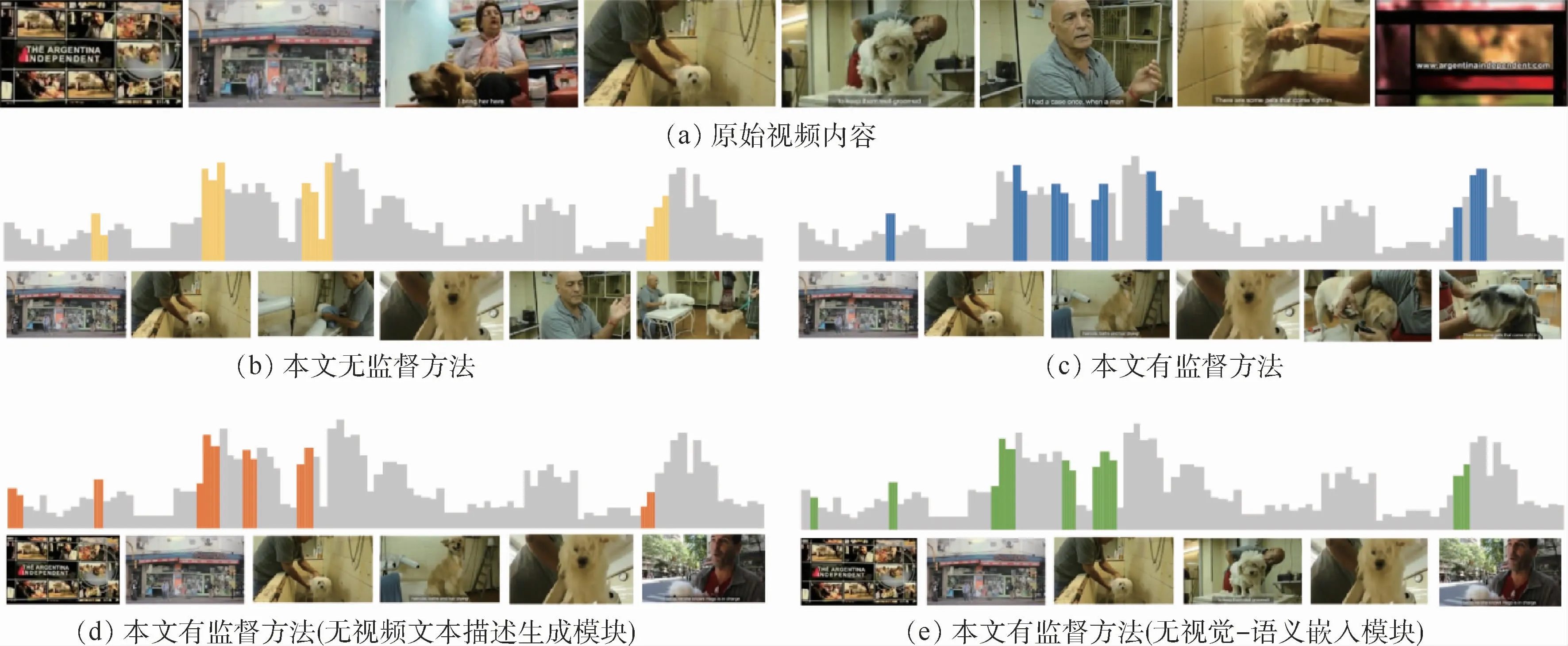
图3 TVSum数据集中生成视频摘要的示例Fig.3 Examples of video summarization in TVSum
3.4.2 视频文本摘要对应

图4 TVSum数据集中生成文本摘要的示例Fig.4 Examples of text summarization in TVSum
图4展示了在TVSum数据集中,对名为Yi4Ij-2NM7U4的视频同时生成的文本摘要和视频摘要的内容对应,同时还展示了3个不同用户对原始视频添加的文本标注。可以看出,虽然本文模型生成句子的结构较为简单,但是可以描述出视频主要内容。
4 结 论
1)本文提出了一种融合语义信息的视频摘要生成模型,该模型通过帧级分数加权模块、视觉-语义嵌入模块和视频文本描述生成模块3个模块,使得视觉特征包含丰富的语义信息,可以同时生成具有语义信息的视频摘要以及相应的文本摘要。
2)实验结果表明,由本文模型生成视频摘要能够展示出原始视频中重要的语义内容,同时文本摘要可以简明地对视频内容进行描述。
在未来的工作中,将利用多模态信息实现视频摘要生成任务,并根据不同用户的需求生成不同主题的视频摘要。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
成都信息工程大学学报(2022年3期)2022-07-21
中学生数理化(高中版.高考理化)(2022年5期)2022-06-01
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
初中生世界·七年级(2019年5期)2019-06-22
当代陕西(2019年10期)2019-06-03
中学生数理化·高一版(2016年6期)2016-05-14
长江学术(2016年4期)2016-03-11
长江学术(2015年1期)2015-02-27
阅读(中年级)(2009年11期)2009-04-14
