
主动容错副本存储系统的可靠性分析模型
2021-04-20 14:07罗金飞李炳超
计算机应用 2021年4期
李 静,罗金飞,李炳超
(1.中国民航大学计算机科学与技术学院,天津 300300;2.南开大学计算机学院,天津 300350)
0 引言
虽然单个硬盘发生故障的概率比较小,但是随着存储系统规模的不断增大,硬盘故障甚至是并发故障的发生频率越来越高[1]。据统计,硬盘故障是数据中心最主要的故障源,在一个Petabyte 级别的文件系统中每天都会有硬盘故障的发生[2]。另外,作为硬盘的载体——服务器,也会因为一些组件,如网卡、内存、CPU、主板和电源等的故障而崩溃,从而导致所有挂载在它上面的硬盘不可访问[3]。硬盘故障会导致存储系统服务性能的降级,甚至会导致用户数据的丢失和服务的中断,给企业和用户带来无法避免和估计的损失。
传统的存储系统普遍采用副本或纠删码机制保障数据的安全,硬盘故障发生之后,系统可利用其他可用硬盘上的冗余数据恢复故障数据,从而避免数据的丢失,这是一种典型的“被动容错”机制。随着硬件故障发生频率的不断增加,被动容错机制只能通过不断增加冗余来保证系统的高可靠性,这无疑增加了构建和维护系统的成本。硬盘故障预测[4-9]通过对系统中硬盘健康状态的实时监测,在硬盘故障发生之前发出警报,提醒用户迁移危险数据,从而避免或减少硬盘故障带来的损失,这是一种“主动容错”的思想。目前已有很多存储系统[5-6,10-11]采用了这种基于硬盘故障预测的主动容错方式。
对主动容错存储系统的可靠性评价,可以用来评估不同预测模型、数据散布策略以及不同系统参数对系统可靠性的影响,有助于构造出高可靠和可用性的存储系统。然而,硬盘故障预测技术的引入令存储系统产生了根本性变化——系统运行由“正常—故障修复”两种状态之间的转换,变为“正常—预警处理—故障修复”三个状态之间的转换,对主动容错存储系统的可靠性分析变得非常复杂,目前仅有少量研究关注此领域。
现有研究存在一些缺陷,不能准确、细致地评价主动容错存储系统的可靠性水平:①忽略了节点故障对系统可靠性的影响。随着系统规模的增大,节点故障的发生频率越来越高,节点故障会导致所有挂载硬盘的失效,对系统可靠性的影响不容忽视。②没有考虑数据散布方式对可靠性的影响。数据散布方式影响到系统在并发故障下的容错能力,对系统可靠性有重要影响。本文拟克服上述缺陷,研究主动容错存储系统的可靠性。
由于硬盘价格持续降低,以及良好的并行处理能力,副本冗余技术成为存储系统普遍采用的容错机制[12-13]。在基于副本冗余机制的存储系统中,一个节点只保存有一个副本,如果有硬盘发生故障,需要跨节点进行数据的重构,会大量消耗网络的带宽,甚至在业务高峰时引起连锁反应,造成性能的抖动。
本文作者在前期工作[14]中,针对采用RAID-5(Redundant Array of Inexpensive Disk)和RAID-6 机制的主动容错存储系统,提出了两个可靠性状态转换模型。本文扩展此项工作到采用副本冗余机制的主动容错存储系统,与前期工作[14]相比,本文主要新增了两个创新点:①增加考虑节点故障和修复对系统可靠性的影响;②分析副本冗余机制下的系统可靠性水平。
具体来说,本文针对采用被动/主动容错二副本和三副本容错机制的存储系统,提出四个可靠性状态转换模型,并据此设计了蒙特卡洛仿真算法模拟系统的运行,统计存储系统在一定运行周期内发生数据丢失的期望次数,从而量化评价主动容错副本存储系统的可靠性水平。本文采用韦布分布函数模拟硬盘故障和修复事件的时间分布,综合评价了主动容错机制、节点故障、节点故障修复、硬盘故障以及硬盘故障修复等因素对存储系统可靠性的影响。利用本文提出的可靠性分析模型,系统管理者可以方便地比较不同冗余机制下的系统可靠性差异,定量评价硬盘故障预测模型对系统可靠性的提升效果,权衡比较不同系统参数对系统可靠性的影响,从而帮助系统管理者搭建出满足特定可靠性需求的存储系统。
1 背景知识
1.1 相关研究
可靠性一直是存储系统相关研究领域重点关注的问题之一,该领域的研究者[2,15]通常基于硬盘故障服从指数分布的假设,使用Markov 模型构建系统可靠性分析模型,研究大规模存储系统的可靠性水平。然而,研究者通过大量实验证明[16-18],相对于指数分布,Weibull分布函数能够更好地模拟硬盘故障事件。Weibull函数可以模拟随运行时间而不断升高、保持不变、或者降低的设备故障发生率,本文使用Weibull 分布函数模拟节点和硬盘故障事件。
对于副本存储系统,有一些国内外研究关注它们的可靠性。文献[19]使用概率分析方法估计系统的可靠性,然而因为忽略了故障重构时间而没有真实反映系统的可靠性水平;Epstein 等[20]使用仿真和统计分析相结合的方法评估了分布式云存储系统的可靠性,并关注网络带宽和并发故障对系统可靠性的影响;Wang 等[21]提出一个可靠性分析模型,通过合并副本丢失的概率来研究基于分块散布的多副本系统的可靠性水平。
近年来,有学者使用基于蒙特卡洛的仿真方法模拟存储系统的运行,进而分析存储系统的可靠性:Hall等[22]使用基于事件驱动的仿真方法预测大型存储系统设计和部署的可靠性;Zhang等[3]使用仿真方法分析了采用纠删码冗余机制的数据中心的可靠性水平,并比较了水平和垂直两种数据散布方式对系统可靠性的影响。然而,前述工作都只是针对被动容错存储系统展开的可靠性研究。
对于主动容错存储系统,目前只有少量研究关注它们的可靠性水平。Eckart等[23]设计了Markov可靠性模型分析主动容错技术对单个硬盘、RAID-1 系统和RAID-5 系统平均数据丢失时间(Mean Time Between Data Loss,MTTDL)的影响;Li等[9,24]拓展了Eckart 等[23]的工作,为主动容错RAID-6、二副本和三副本系统设计了Markov 可靠性分析模型。然而,这些工作都基于硬盘故障符合指数分布的假设,并没有真实刻画主动容错存储系统的可靠性水平。
李静等[14,25]的后续工作中,采用更符合实际情况的韦布分布函数模拟硬盘故障事件,使用蒙特卡洛仿真方法和组合数学分析方法为主动容错RAID-5、RAID-6、二副本和三副本系统设计了可靠性分析模型。然而,当前现有的评价模型都没有考虑节点故障对系统可靠性的影响,节点上的任何组件或软件的故障都会导致节点故障,节点故障会引起所有挂载硬盘的集体失效,其发生频率及对系统可靠性的影响不容忽视。本文拟面向被动/主动容错二副本和三副本存储系统,综合评价节点故障、硬盘故障对系统可靠性的影响。
1.2 系统框架
当前存储系统普遍采用分层的系统框架,如图1 所示,机房中放置了多个机架,每个机架上放置了多个节点(存储服务器),每个节点上配备了多块硬盘以存储业务数据。同一机架内部的节点通过机架顶部的交换机进行通信,不同机架的节点之间通过网络核心交换机进行通信。
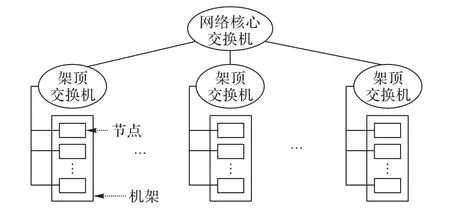
图1 存储系统架构Fig.1 Storage system architecture
在采用副本冗余机制的存储系统中,用户数据首先被分成很多数据块(data chunks),然后每个数据块都被复制一定数量的副本(二副本系统中有两块副本,三副本系统中有三块副本),最后这些副本在系统的不同节点之间散布(而不是存放在同一个节点上),从而提高数据在节点故障时的存活概率。通常情况下,一个数据块的副本首先被管理节点分配到某些存储节点(存储服务器)上,然后存储节点再选择一块内部硬盘存放其中一个副本。为了保障数据安全和系统可靠性,存储系统一般会遵循两个数据散布的原则:①一个节点至多只存放某个数据块的一个副本;②一个数据块的所有副本至少要被散布到两个不同的机架上。
二副本系统:每个用户数据都被复制两次,这两个数据副本必须存放在两个不同的机架上。如果由节点故障或硬盘故障导致的数据损坏位于同一个机架上,这些故障不会导致系统发生数据丢失事件。
三副本系统:每个用户数据都被复制了三份,这三个数据副本被散布到三个不同节点上,其中有两个节点位于同一个机架上,另外一个节点位于其他机架上。这种数据散布方式有两个优点:①如果某个机架由于电源等设备的故障而失效,系统可以使用其他机架上的存活副本修复发生的故障,能够提高数据的存活概率;②如果某个存储节点发生了节点或硬盘故障,系统可以使用相同机架上的存活副本修复故障,这个操作使用的是机架内部的网络带宽,不会对珍贵的机架之间的核心网络通信产生影响。
1.3 故障模式
存储系统主要存在三种类型的设备故障:①节点故障。由于服务器的网卡、内存、CPU、主板和电源等组件的故障(或软件故障)而导致的节点崩溃,使得该节点挂载的所有硬盘都无法访问。②硬盘个体故障。由于磁头损坏、芯片信息丢失、电路板问题等原因导致的硬盘上所有数据都无法访问。③硬盘潜在扇区错误。一般是由介质故障或磁头划伤等原因造成的硬盘部分二进制位无法读出。存储系统后台通常运行着“硬盘清洗”进程,周期性地检测并修复硬盘潜在扇区错误,文献[25]中的图10 显示硬盘潜在扇区错误对副本系统的可靠性影响不大,因此本文只关注前两种类型的设备故障,即节点故障和硬盘个体故障。
设备故障根据其持续时间和危害程度可分为临时故障和永久性故障两类:①临时故障。由网络断开、重启或维护等原因造成的设备(节点或硬盘)暂时不可访问,这种故障只需经过多次尝试,就可以恢复正常,不会造成系统的数据丢失,只对系统的可用性产生一定影响。②永久性故障。由于软件故障、组件故障、磁道损坏等原因造成的设备永远不能被访问,这种故障只能通过更换设备进行恢复,不仅会降低系统的可用性,还可能会导致系统发生数据丢失,降低系统的可靠性。因为只有永久性故障会对系统的可靠性产生影响,所以本文只关注设备的永久性故障。
当节点或硬盘故障发生之后,某些数据的部分(而非全部)副本会因此而丢失,为了维持系统数据冗余度的一致性,系统会启动一个重构过程,利用其他存活副本修复(重构)出丢失的副本。为了维持系统规模和全局的数据均衡,新设备替换故障设备加入系统并被散布上数据。在故障修复期间,如果又有其他设备(节点或硬盘)发生故障,一些数据块可能会丢失更多的副本,直至不可恢复的数据丢失事件发生。如果数据块的所有副本全部丢失,重构过程已经不能再重构出这些由并发设备故障导致的损坏数据,本文研究认为系统发生了数据丢失事件。
1.4 主动容错技术
现代硬盘内部基本上都实现了SMART(Self-Monitoring,Analysis and Reporting Technology),具有“自我监测、分析和报告”功能,如果某些属性的当前值超过预先设定的阈值,硬盘会自动发出警告信息,提醒用户对硬盘采取措施,避免硬盘故障导致的数据丢失损失。但是,这种简单阈值法的预报精度不高,不能满足用户对系统可靠性的需求。于是,国内外研究者开始尝试使用机器学习方法创建硬盘故障预测模型[4-9],有一些方法,比如Li 等[4]的工作创建的基于决策树的硬盘故障预测模型,取得了令人满意的预测性能。
在主动容错存储系统中,系统后台运行着一个硬盘故障预测模型,对工作中的硬盘进行实时监测,并周期性地输出硬盘个体的“健康”情况,系统会对“健康”状态差(即将发生故障)的硬盘启动预警修复过程,把危险数据提前迁移到健康硬盘上。目前还没有相关文献研究节点故障预测,所以本文只关注基于硬盘故障预测的主动容错存储系统的可靠性。
2 系统状态转移模型
本章为被动/主动容错二副本和三副本系统提出了状态转移模型,分析系统在主动容错机制、节点和硬盘故障以及故障修复等事件下的状态转换过程,为系统可靠性评价模型的设计提供依据。如果某个数据块的所有副本都因为设备故障而发生了损坏(丢失),系统的修复过程已无法再重构出该数据块,本文研究认为此时系统发生了数据丢失事件。
假设系统中包含r个机架,每个机架上放置了n个节点,每个节点上配置了d块硬盘,系统中共包含rn个节点和rnd块硬盘。
2.1 被动容错二副本系统
对于二副本存储系统,根据副本系统数据的散布原则,用户数据块的两个副本散布在位于不同机架的两个硬盘上,称这种位于不同机架上的两个硬盘为一个“复制对”。对于系统中的一个硬盘D,其他机架上的任意一个硬盘都可以和D构成一个“复制对”,共有(r-1)nd个包含D的“复制对”。假设系统中每个硬盘的容量为4 TB,每个数据块的大小为1 MB,那么在完全均匀和随机的散布下,只要(r-1)nd<(4 TB/1 MB),即系统包含的硬盘数量不超过4×106时,位于不同机架的任意两个硬盘上都至少存储了一个数据块的两个副本。因此,如果系统中的两个机架同时出现了设备(节点或硬盘)故障,这些并发故障就会导致系统发生数据丢失事件。
图2 的状态转换模型描述了被动容错二副本系统在设备故障和故障修复等事件影响下的状态转换逻辑,系统共有三种主要状态:状态1 表示系统处于完全健康的状态,所有设备都在正常运行,没有任何设备出现故障;状态2 表示系统处于降级模式,某一个机架由于硬盘或节点故障出现了数据损坏,其他机架上并没有出现设备故障,系统不会发生数据丢失,只是可用性受到一定影响;状态3 表示系统进入数据丢失模式,此时系统发生了永久性数据丢失事件,无法再为用户继续提供服务。

图2 被动容错二副本系统状态转换模型Fig.2 State transition model for 2-way replication system with passive fault tolerance
系统开始运行时处于状态1,如果某个机架上发生了设备(硬件或节点)故障事件,系统进入状态2(降级模式),由于所有数据块的副本都存放在两个不同机架上,所以此时系统不会发生数据丢失事件。
系统进入状态2 之后,会立刻启动故障重构过程,利用其他设备上的存活副本重新构造故障导致的损坏数据,此时系统有两种状态转移可能:①如果所有故障都被及时修复完成,全部数据块均恢复至拥有两个副本的正常状态,系统转入状态1;②在现有的故障设备修复完成之前,其他机架上又发生了硬盘或节点故障,导致系统中至少一个数据块的全部副本都发生了损坏,数据丢失事件发生,系统进入状态3。
系统进入状态3 之后,无法再继续为用户提供正常服务,不能再向其他状态转换。
2.2 被动容错三副本系统
对于三副本存储系统,每个数据块都拥有三个副本,分别存放在三个不同的硬盘上,其中两个硬盘位于某个机架的两个不同节点上,第三个硬盘位于另外一个机架上,本文称这样的组合为一个“副本集合”。对于系统中的任意硬盘D,有两种构成“副本集合”的方式:从D所在机架的其他节点上选取一个硬盘,再从其他机架选取另一个硬盘,可以组成(n-1)d×(r-1)nd个“副本集合”;从其他机架的不同节点上选取两个硬盘,可以组成个“副本集合”。合并两种方式,对于系统中的任意一个硬盘,总共包含在1)n(n-1)d2个“副本集合”中。假设硬盘容量为4 TB,数据块大小为1 MB,那么对于(r=900,n=10,d=4)的三副本系统(硬盘数量为36 000),任意一个“副本集合”的硬盘上都至少保存有一个数据块的所有副本(单个硬盘上的数据块数量多于它所在的“副本集合”个数)。
因此,对于系统规模不超过36 000 块硬盘的三副本系统发生数据丢失事件的条件是:至少两个机架发生了设备(硬盘或节点)故障,其中一个机架至少有两个节点发生数据损坏,这些故障设备构成了一个(或多个)“副本集合”,导致某个(或某些)数据块的全部副本都被损坏。如果硬盘上的数据块数量(用c表示每个硬盘上的数据块数量)少于它所在的“副本集合”个数(用rep表示包含给定硬盘的“副本集合”数量),当一个“副本集合”的三个硬盘同时发生故障时,系统以的概率发生数据丢失。
图3 状态转换模型描述了被动容错三副本存储系统在设备(硬盘或节点)故障和故障修复等事件下的状态转换逻辑,其中,模型共包含五种主要状态:状态1 是完全健康状态,系统中的所有设备都在正常运行;状态2 是降级模式,系统中的某一个机架上出现了设备故障;状态3 也是降级模式,至少两个机架上都有一个节点出现了数据损坏,系统处于故障边缘;状态4 也为降级模式,某一个机架上的至少两个节点上都有数据损坏,系统处于故障边缘;状态5 是数据丢失状态,此时已有数据块发生了永久性丢失,系统不能再提供正常服务。
系统开始运行时处于状态1,系统中所有数据都处于具有三个副本的正常状态,如果某个硬盘或节点发生故障,系统转入状态2。
系统进入状态2 之后,会马上启动故障修复进程重构损坏的数据,此时有三种状态转移可能:①如果故障可以被及时修复完成,系统返回到状态1;②在第一个故障修复完成之前,其他机架上又有硬盘或节点故障发生,系统转入状态3;③在第一个故障修复完成之前,损坏机架上的其他节点又发生了设备(节点或硬盘)故障,系统转入状态4。
系统处于状态3 时,由于每个机架上最多只有一个节点发生损坏,这些故障设备没有构成“副本集合”,不会导致数据丢失,系统会针对新发生的故障再启动一个修复进程,有两种状态转移可能:①如果某个(或其他)机架上的故障全部修复完成,只剩一个机架上有损坏数据,系统返回状态2;②如果在两个机架上的故障修复完成之前,损坏机架上又有其他节点(或其他节点上的硬盘)发生了故障,这些故障设备构成了一个或多个“副本集合”,系统发生数据丢失事件,进入状态5。
系统处于状态4 时,系统中只有一个机架发生损坏,故障设备没有构成“副本集合”,不会导致数据丢失,系统会立即再启动一个修复过程重构损坏数据,会有两种状态转移可能:①如果某个(或某些)故障修复完成,机架上只剩一个节点有数据损坏,系统返回状态2;②如果在两个不同节点(或不同节点上的硬盘)故障修复完成之前,又有其他机架上发生节点(或硬盘)故障,这些故障设备构成了“副本集合”,造成数据丢失,系统转入状态5。
系统进入状态5 之后,无法再继续为用户提供正常服务,不能再向其他状态转换。
2.3 主动容错二副本系统
由于预测性能(不能达到100%的预测准确率)和预警修复能力(不能及时处理完所有的预警)的限制,主动容错机制并不能完全避免硬盘故障的发生,再加上存在节点故障的风险,存储系统还需要采取一定的被动容错机制以保证系统的可靠性,所以主动容错存储系统的状态转换逻辑比较复杂。图4 描述了采用二副本冗余机制的主动容错存储系统在硬盘故障预警、硬盘故障、节点故障,以及预警处理和故障修复等事件下的状态转换逻辑。其中:“发生预警”表示系统中有硬盘被故障预测模型检测出即将发生故障,“预警处理”表示系统对预警硬盘采取的备份迁移操作。

图4 主动容错二副本系统状态转换模型Fig.4 State transition model for 2-way replication system with proactive fault tolerance
主动容错二副本系统有6 个主要状态节点:状态1,所有设备都在健康正常运行,没有发生任何预警和故障;状态2,某个机架上的硬盘被预测出即将发生故障;状态3,某个机架上发生了设备(节点或硬盘)故障;状态4,多个机架出现了硬盘故障预警;状态5,某个机架上发生了设备故障,同时其他机架的硬盘被检测出存在潜在故障;状态6,某个(或某些)数据块的所有副本都发生了损坏,系统发生了数据丢失事件。系统存在下述几种状态转换情况:
1)系统开始运行时处于状态1,系统中的所有设备都在健康运行,此时系统有两种状态转移可能:①如果预测模型发出预警,某个机架上的硬盘被检测出即将发生故障,系统转入状态2;②如果某个机架上发生了设备故障,系统转入状态3。
2)系统出现故障预警进入状态2 之后,会立即启动预警处理进程,把预警硬盘上的数据迁移备份到其他健康硬盘上。从状态2 出发,系统有四种状态转移可能:①预警处理过程及时完成,在预警硬盘真正发生故障之前就把危险数据迁移到了其他健康硬盘上,系统返回到健康状态1;②预警处理完成之前,预警硬盘发生了故障,造成部分数据损坏,或预警机架上其他设备(节点或硬盘)发生了故障,系统进入状态3;③当前预警处理完成之前,其他机架也出现故障预警,系统进入状态4;④在预警处理完成之前,其他机架发生了设备故障,系统进入状态5。
3)系统进入状态3 之后,立即启动故障修复进程,利用其他健康盘上的存活副本对损坏的数据进行重构。从状态3 出发,系统有三种状态转移可能:①故障修复完成,系统中的所有数据块都恢复至拥有两个副本,所有设备都在健康运行,系统返回状态1;②故障修复完成之前,其他机架出现故障预警,系统进入状态5;③故障修复完成之前,其他机架发生设备故障,导致系统中至少有一个数据块的所有副本全部损坏,系统进入状态6。
4)系统处于状态4 时,系统中运行着多个预警处理进程,对危险数据进行备份。从状态4 出发,系统有两种状态转移可能:①某些预警处理进程成功完成,系统中只剩下一个机架上有危险数据没有备份完,系统返回到状态2;②某个预警硬盘在备份完成之前发生了故障,预警处理失败,或者其他设备又发生了故障,系统进入状态5。
5)系统处于状态5 时,系统中同时运行着故障修复进程和预警处理进程,对故障设备进行修复并备份危险数据。从状态5 出发,系统有三种状态转移可能:①故障修复过程完成,通过其他存活副本将损坏的数据重构完成,系统返回到状态4;②预警处理过程完成,消除了预警硬盘发生故障的危险,系统返回到状态3;③在预警处理过程完成之前,预警硬盘就发生了故障,或者其他(与故障机架不同的)机架又发生了设备故障,这些并发的故障造成了数据丢失,系统进入状态6。
6)系统进入状态6 之后,因为有数据发生了永久性丢失,系统已无法再为用户提供服务,所以不能再向其他状态转移。
2.4 主动容错三副本系统
主动容错三副本系统的可靠性状态转换逻辑非常复杂,无法完整地显示在一个逻辑图中,另外,主动容错三副本系统的状态转换逻辑与上述二副本系统的转换逻辑类似,所以,本文仅把发生数据丢失过程中的关键状态节点列出,如图5所示。

图5 主动容错三副本系统状态转换模型Fig.5 State transition model for 3-way replication system with proactive fault tolerance
状态1表示系统处于完全健康运行状态;状态2表示系统中出现了部分设备故障及(或)硬盘故障预警,这些故障设备还没有对系统的可靠性造成威胁,此时系统进入降级模式,启动故障修复及(或)预警处理进程,对故障及(或)预警硬盘进行修复。
在两种情况下,系统会进入状态3:①两个机架上都有一个节点由于设备故障出现数据损坏;②某个机架上的两个节点都出现了数据损坏。此时系统进入濒临数据丢失的状态,只要某些特定位置的设备发生故障,系统就会发生数据丢失事件:①如果两个损坏机架上再有一个节点出现数据损坏;②其他机架上的某个节点出现数据损坏。这样,系统中的这些并发故障设备构成了一个或多个“副本集合”,导致数据丢失事件的发生。
3 仿真程序
根据上述提出的系统可靠性状态转换逻辑,本文设计了蒙特卡洛仿真算法,模拟主动容错存储系统的运行,并评价系统在一定运行周期内(比如,10 a)发生数据丢失的期望次数。
仿真算法模拟了6 个事件:①节点故障事件,潜在存在于每个服务器节点上,发生时间根据节点故障的时间分布函数随机生成;②节点故障修复完成事件,在节点故障修复进程完成时触发,修复过程的处理时间根据节点故障修复的时间分布函数随机生成;③硬盘故障事件,潜在存在于每个硬盘上,发生时间根据硬盘故障的时间分布函数随机生成;④硬盘故障修复完成事件,在硬盘故障修复进程完成时触发,修复过程的处理时间根据硬盘故障修复的时间分布函数随机生成;⑤硬盘故障预警事件,在故障预测模型检测到系统中有即将发生的硬盘故障时触发,发生时间根据硬盘故障的发生时间和故障预测模型的性能指标——提前预测时间(Time In Advance,TIA)生成;⑥硬盘故障预警处理完成事件,在预警硬盘上的数据全部迁移备份完成时触发,预警处理过程的时间根据硬盘故障预警处理的时间分布函数生成。
事件⑤和事件⑥模拟主动容错机制在系统中的运行,事件⑤发生之后,系统立即启动预警处理进程,把危险硬盘上的数据迁移备份到其他健康硬盘上。事件①或③发生时,算法根据系统的冗余机制检测是否发生数据丢失事件:a)如果没有发生数据丢失,系统立即启动故障修复进程,利用其他健康设备上的存活数据重构故障数据;b)如果发生了数据丢失,为了维持系统规模,系统添加新的设备和数据,并为新设备生成未来的潜在故障事件。事件②、④或⑥发生时,表示故障或预警已经被修复完成,系统中加入新的设备替换故障(或危险)设备,并为新设备生成未来的潜在故障事件。
仿真算法维护了一个最小堆,用以保存当前还没有发生的未来事件,这些事件根据发生时间的先后顺序插入最小堆,最小堆顶部的事件为最先要发生的事件。系统中事件的发生时间不断累积,直到超过预设的运行周期,仿真程序的一次运行结束,统计系统运行期间数据丢失的发生次数作为仿真结果。程序开始时,根据节点故障和硬盘故障的时间分布函数,分别为系统中的每个节点和硬盘生成一个未来的故障事件,并且根据硬盘故障预测模型的预测准确率(Failure Detection Rate,FDR)为潜在的硬盘故障生成预警事件,这些事件都根据发生时间的先后顺序插入最小堆。程序运行期间,最小堆顶部的事件被弹出,模拟该事件的发生,系统根据发生事件的类型作出相应操作。
4 实验和结果分析
本章呈现了仿真程序的实验结果,并分析了主动容错机制和不同系统参数对系统可靠性的影响。
4.1 实验准备
1)系统规模:对于用户来说,主要关心不同存储系统在相同用户数据容量下的可靠性差异,所以考虑如下的系统规模:对于二副本存储系统,系统共包含200 个机架,每个机架上部署了10个节点,每个节点挂载了4个硬盘,假设硬盘的容量是4 TB,系统总共可以存储16 000 TB的用户数据;对于三副本系统,系统包含300 个机架,每个机架上部署了10 个节点,每个节点挂载了4 个硬盘,假设硬盘的容量是4 TB,系统也可以存储16 000 TB的用户数据。
2)硬盘故障和故障修复:很多前人的研究都假设硬盘故障时间服从指数分布,这个假设被Schroeder 等[16]推翻了,他们发现韦布分布函数能够很好地模拟硬盘故障的发生。
硬盘发生故障之后,系统启动故障重构过程,利用其他存活硬盘上的副本恢复损坏的数据,并把重构出的数据散布到系统其他健康硬盘上,同时增加新硬盘到系统,维持系统规模。通过对大量领域数据的分析,Elerath 等[18]发现韦布分布函数可以很好地拟合硬盘故障和故障修复过程的时间分布,因此,本文使用韦布分布函数模拟硬盘故障和硬盘故障修复事件在云存储系统中的发生。Elerath等[18]从大量领域数据中分析得出三种型号硬盘的故障和修复过程的韦布分布参数,本文选择文献[18]表3 中A 型号SATA 硬盘的故障和修复过程的参数,详细信息见表1。
3)节点故障和故障修复:文献[13]报道称在Yahoo!集群中每个月大约有0.8%的节点会发生(永久或临时)故障,相对临时节点故障,永久性节点故障发生的频率小很多,因此,本文使用0.8%的年平均故障率(平均故障时间为(24 ×30 × 12)/0.8%=1 080 000 h),模拟生成副本系统中永久性节点故障。本文使用形状参数为1、生命特征参数为1 080 000的韦布分布函数模拟节点故障。形状参数为1 时,韦布分布函数退化为指数分布。
节点故障发生之后,节点上挂载的所有硬盘都将不能被访问,系统会对每个掉线的硬盘启动一个重构过程,利用其他存活硬盘上的副本恢复损坏的数据,为了维持系统规模,系统管理员会添加新的节点到系统,并会向新的设备上迁移数据以实现系统的负载均衡。故障设备上的数据总量除以可用修复带宽,得到重构过程的运行时间,假设系统为每个故障(包括节点故障和硬盘故障)修复事件分配的带宽一致,节点故障的修复时间为硬盘故障修复时间的4倍(每个节点上挂载4块硬盘)。
4)硬盘故障预警和预警处理:当前已经有大量工作在研究硬盘故障预测模型,Li 等[4]的工作中提出的基于决策树的硬盘故障预测模型,可以达到95%的预测准确率和近360 h的提前预测时间。本文设置硬盘故障预测模型的预测准确率FDR为80%,平均提前预警时间TIA为320 h,即在硬盘故障发生前平均320 h触发预警事件。当设置FDR=0,主动容错存储系统退化为被动容错系统。
硬盘故障预警事件发生之后,系统会立即启动预警处理过程,把预警硬盘上的危险数据提前备份到其他健康的硬盘上。假设系统为预警处理分配与故障修复一致的带宽,预警处理的完成时间与硬盘故障修复的时间相同,本文研究使用上述硬盘故障修复参数设置预警处理完成事件。
表1 列出了本文实验的主要参数设置,如果没有特殊说明,本文仿真实验默认使用如表1 的参数值。其中,符号r表示系统内机架的数量,n表示每个机架上的节点数量,d表示每个节点上硬盘的数量。韦布分布函数W(α,β,γ),形状参数用α表示,生命特征参数用β表示,位置参数用γ表示,当α=1时,韦布分布函数退化为指数分布。被动容错系统的参数FDR设置为0。

表1 实验参数设置Tab.1 Experimental parameter setting
对每组参数,仿真程序迭代运行100 次,最后统计所有迭代运行结果的平均值作为本组参数的实验结果。
4.2 模型比较
Li 等[25]针对主动容错RAID 系统和副本系统设计了数学模型和蒙特卡洛仿真模型,评价系统在硬盘故障和潜在扇区错误(不包含节点故障)等事件下的可靠性水平。为了验证节点故障对副本存储系统可靠性的影响,本文选用Li 等[25]的蒙特卡洛仿真模型与本文模型做实验对比。对于没有考虑节点故障的旧蒙特卡洛仿真模型,除了表1 中的参数设置外,使用文献[18]的表3中硬盘A的潜在扇区错误和磁盘清洗参数。
图6 呈现了本文所提的新评价模型和文献[25]中的旧仿真模型,对被动/主动容错二副本和三副本系统可靠性的评价结果。
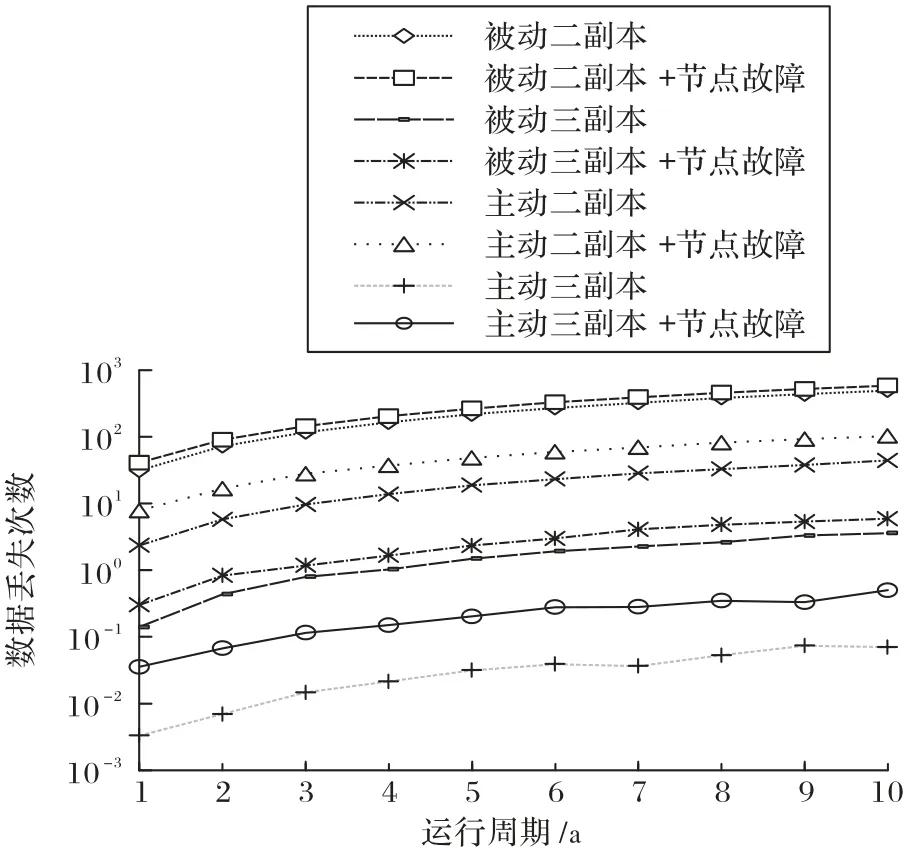
图6 节点故障对副本系统可靠性的影响Fig.6 Impact of node failure on reliability of replication systems
“被动二副本”“被动三副本”“主动二副本”和“主动三副本”线段上的结果由不包含节点故障的旧仿真模型[24]评价得出,“被动二副本+节点故障”“被动三副本+节点故障”“主动二副本+节点故障”和“主动三副本+节点故障”线段上的结果由本文提出的可靠性分析模型评价得出。
从图6 可看出:①随着运行周期的增长,副本存储系统的可靠性在不断降低(数据丢失次数在增加),相对于被动容错系统,主动容错副本存储系统的可靠性水平的降低速度缓慢一些;②节点故障对副本存储系统的可靠性有很大影响,尤其是在主动容错存储系统中,因为主动容错机制可以消除部分硬盘故障的危害,节点故障对系统可靠性的影响更为突出(二副本系统的数据丢失概率增大2 倍左右,三副本系统的数据丢失概率增大6 倍左右)。本实验结果表明,在研究存储系统可靠性时,不能忽略节点故障对系统可靠性的影响。
4.3 敏感性分析
利用本文提出的可靠性分析模型,系统管理者可以方便地了解主动容错机制以及其他系统参数对系统全局可靠性的影响,有利于构建和维护具有高可靠性的存储系统。实验将演示如何使用本文提出的可靠性分析模型评价不同系统参数对系统全局可靠性的影响。
4.3.1 节点故障的敏感性
本节实验分析了随着节点年故障率的变化,存储系统可靠性的变化情况。本实验设置节点的年故障率分别为0.4%、0.6%、0.8%、1.0%、1.2%、1.4%和1.6%,其他参数使用表1中的设置,结果如图7所示。
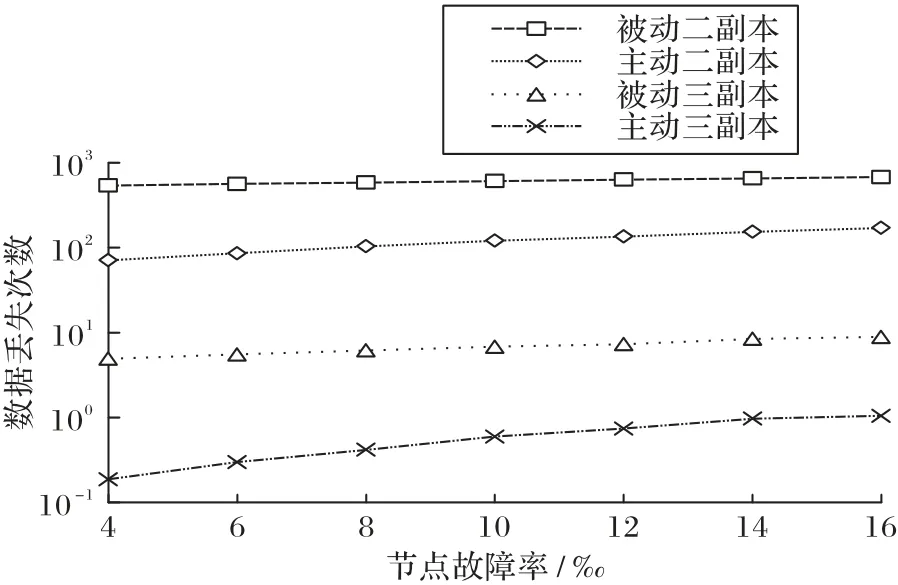
图7 存储系统在不同节点故障率下的可靠性Fig.7 Reliability of storage systems under different node failure rates
从图7 可看出:①随着节点故障发生频率的增大,四个系统的可靠性都存在降低的趋势(数据丢失次数增加);②相对于被动容错系统,主动容错系统可靠性受节点故障率的影响更大,主要原因是主动容错机制消除了大部分(80%)硬盘故障的危害,节点故障对数据丢失事件的“贡献”(影响)更为突出;③相对于二副本系统,三副本系统的可靠性对节点故障率敏感性更大,主要是因为三副本系统需要更多的并发设备故障导致数据丢失,所以受节点故障率的影响更大。
4.3.2 硬盘故障的敏感性
本节实验分析随着硬盘故障频率的变化,存储系统可靠性的变化情况。本实验通过调整硬盘故障分布函数的β参数(特征寿命)改变硬盘的故障时间,如图8所示。

图8 存储系统在不同硬盘特征寿命下的可靠性Fig.8 Reliability of storage systems under different characteristic lives of disk
从图8 可看出:①随着硬盘个体可靠性的增强(生命特征时间的增长),四个系统的可靠性水平都得到了提升;②相对于二副本系统,三副本系统受硬盘故障时间的影响更大,主要是因为三副本系统需要更多的并发硬盘故障导致数据丢失事件的发生;③即使采用故障频率高两倍的硬盘(特征寿命为原来的50%),主动容错系统(FDR=80%)也可以达到与被动容错系统相近或更高的可靠性水平,验证了主动容错机制对系统可靠性提升的效果。
4.3.3 修复带宽的敏感性
存储设备(节点或硬盘)发生故障之后,系统会启动故障修复过程重新构造受损的数据块,为了维持用户正常服务的质量,系统只会将一部分的可用带宽分配给故障修复过程,修复带宽的多少决定了故障修复时间的长短。故障修复时间越长,在故障修复期间再次发生设备故障的概率就越大,系统发生数据丢失的危险也就越大。
为了验证修复带宽对系统可靠性的影响,本实验通过调节故障修复分布函数的β参数改变硬盘故障和节点故障的修复时间,实验比较了存储系统在不同故障修复时间下的可靠性水平,结果如图9 所示。本文假设系统为所有故障修复过程分配一样的修复带宽,所以节点故障修复的时间是硬盘故障修复时间的4倍(每个节点上挂载4块硬盘)。

图9 存储系统在不同故障修复时间下的可靠性Fig.9 Reliability of storage systems under different failure repair time
从图9 可看出:①正如上述分析所示,随着重构时间的增长,四个系统的可靠性都呈现出不同程度的降低趋势;②相对于二副本系统,三副本存储系统只有在更多的设备故障下才会发生数据丢失,所以对重构时间具有更强的敏感性;③即使将修复带宽降低66%,主动容错存储系统也可以达到或超越传统被动容错系统的可靠性水平,这表明在主动容错机制的帮助下,存储系统可以节省对网络资源的消耗。
4.3.4 故障预测准确率的敏感性
为了定量评价主动容错机制对存储系统可靠性的提升效果,本实验比较了存储系统在不同故障预测准确率下的可靠性水平。实验结果如图10所示。
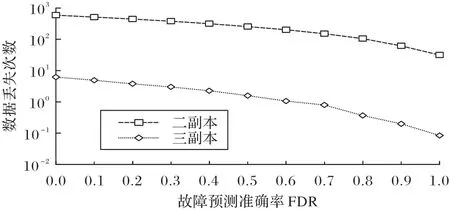
图10 存储系统在不同故障检测率下的可靠性Fig.10 Reliability of storage systems under different failure detection rates
从图10 中可以清楚地看出:①故障预测模型的准确率越高,主动容错机制可以消除越多的潜在硬盘故障,存储系统的可靠性越强;②对于二副本系统,当故障预测模型的准确率达到50%时,系统的可靠性提升了1 倍(数据丢失数量降低了50%);③对于三副本系统,当准确率达到50%时,系统的数据丢失次数减少了75%(可靠性提升了3 倍),这表明与二副本系统相比,三副本系统对预测模型性能更敏感;④当FDR=100%时,主动容错机制几乎可以消除所有的潜在硬盘故障(取决于TIA),系统的数据丢失只会由节点故障所导致,二副本存储系统的数据丢失量降低近95%,三副本存储系统的数据丢失量降低了97%。
4.3.5 系统规模的敏感性
本节实验分析了随着系统有效存储容量的变化,存储系统可靠性的变化情况。假设每个硬盘的容量都是4 TB,通过调整系统内机架的数量,从而改变系统的存储容量,比如,设置二副本系统的机架数r=300,三副本系统的机架数r=450,使得四个系统中的有效存储容量都是24 000 TB。结果如图11所示。

图11 存储系统在不同存储容量下的可靠性Fig.11 Reliability of storage systems under different storage capacities
从图11 中可以看出:随着系统有效容量的增大,四个存储系统的可靠性呈现出了相近的降低趋势:系统有效规模每增大一倍,存储系统的数据丢失数量将增加近两倍。系统容量的扩大,需要增加存储设备(包括节点服务器和硬盘),在相同容错能力下,可能发生故障的设备增多了,导致系统发生更多的数据丢失事件。
5 结语
本文针对采用副本冗余机制的存储系统提出了系统可靠性转移模型,分析了在主动容错机制、节点故障、硬盘故障以及故障修复事件下的系统状态转换逻辑,并根据这些状态转换逻辑、采用蒙特卡洛仿真算法构建了存储系统的可靠性分析模型,评估系统在一定运行周期内发生数据丢失的期望次数。本文采用更接近实际的韦布分布函数模拟硬盘故障和故障修复事件的时间分布,定量评价了主动容错机制、节点故障、节点故障修复、硬盘故障、硬盘故障修复对副本系统可靠性的影响。
另外,本文利用仿真程序验证了节点故障对云存储系统可靠性的影响,并分析了主动容错机制和其他系统参数对系统可靠性的影响。利用本文提出的可靠性分析模型,系统管理者在构建或维护系统时,可以灵活方便地评估不同系统参数对系统可用性和可靠性的影响,从而有助于高可靠存储系统的搭建和维护。
本文研究使用Weibull分布函数模拟故障修复的时间,没有细致考虑副本数据块的分发方式以及故障恢复机制对修复时间的影响。在未来的研究中,本文作者计划根据副本数据块在系统中的散布方式、可用的网络修复带宽以及并发的故障数量计算故障修复的时间,更真实准确地评价主动容错存储系统的可靠性。
猜你喜欢
农业装备与车辆工程(2022年7期)2022-10-31
风能(2020年11期)2020-04-19
发明与创新·大科技(2019年12期)2019-03-17
传播与制作(2018年9期)2018-11-15
中国计算机报(2018年13期)2018-05-23
中国知识产权(2018年3期)2018-04-13
电子竞技(2009年13期)2009-09-28
劳动保护(2009年5期)2009-09-24
电子竞技(2009年14期)2009-09-07
电子竞技(2009年4期)2009-03-02
