
网络入侵检测场景下的特征选择方法对比研究
2021-05-06 03:06杨喜敏
河南科学 2021年3期
田 野, 唐 菀, 杨喜敏, 张 艳
(中南民族大学计算机科学学院,武汉 430074)
5G和物联网(Internet of Things,IoT)的发展使得互联网规模呈现大幅增长,随之而来的网络安全问题也愈发突出. 零日漏洞、挖矿木马等攻击活动愈发活跃[1-2],仅在2017年每月对于物联网设备的攻击数就高达5200次,这给人们网络工作与生活带来了极大威胁. 入侵检测系统(Intrusion Detection System,IDS)作为一种积极主动的网络安全防护技术,一直以来都是保卫网络安全的重要手段[3]. 但是,随着黑客攻击手段的不断升级以及网络飞速发展带来的海量网络数据流量,传统的IDS已远远不能满足当前网络安全需求[4-5].
近年来,机器学习的快速发展给网络入侵检测带来了新的发展契机,基于机器学习的网络入侵检测系统拥有传统IDS难以企及的检测速度以及检测精度,并且对于未知攻击的检测能力得到大幅度的提高. 但是由于网络流量的快速增长,如果不对检测流量的特征规模进行缩减,那么即使是基于机器学习的检测系统也将难以保证检测的速度. 因此,采用适当的特征选择算法来缩减流量特征规模对于提高网络入侵检测系统性能来说具有重要意义[6-7].
特征选择作为一项数据预处理手段早已发展多年,它对提高机器学习模型的性能起到了重要作用. 然而,面对众多的特征选择算法,如mRMR[8]、马尔科夫毯[9]、卡方检验、互信息、梯度下降树[10]、随机森林[11]、CART决策树[12]、最小二乘法[13]等,如何选择适合于应用场景下的算法以及所选特征选择算法是否能够有效缩减特征规模以去除冗余特征,且不会影响入侵检测系统的性能,这些问题都缺乏相关的文献来做参考. 为此,本文设计一种以入侵检测系统性能保证为目标的特征选择算法评估方案,以对比分析各类常用的特征选择算法,从而能够为用户在网络入侵检测场景下选择更为适合的入侵检测特征选择算法提供依据.
1 特征选择算法
根据选择过程和学习器的不同组合方式,特征选择算法种类可分为过滤式、封装式、嵌入式和集成式4种[14].
过滤式特征选择算法和学习算法是两个相互独立的过程,特征选择是学习算法的预处理过程,学习算法用来对特征选择结果进行验证. 根据其特征选择框架的不同,过滤式特征选择算法又可以分为基于特征排序的和基于搜索策略的两种算法[14]. 本文选用基于特征排序的过滤式特征选择算法,采用的特征评价标准有卡方检验(CHI2)和互信息(MI)两种.
封装式特征选择算法方法结合了特征选择过程和学习过程,学习器根据其在特征子集上的预测准确率来评价所选特征,并采用搜索策略调整子集,最终获得近似最优子集[14]. 本文选择的是基于递归特征消除的特征选择算法,学习器选用逻辑回归法(LS)和偏最小二乘法(Partial Least Squares,PLS)两种.
嵌入式特征选择算法综合了过滤式和封装式的优势[14],特征选择过程包含在学习算法当中,当算法训练完成时就可以得到对应的特征子集. 本文选用的嵌入式的特征选择算法为基于L1和L2正则项的最小二乘回归方法(LS_LI)和决策树(OT).
集成式特征选择算法借鉴了集成学习思想,通过训练多个特征选择方法,并整合所有特征选择方法的结果,以此来获得比单个特征选择方法更好的效果[14]. 本文所选用的集成式特征选择算法为梯度下降树算法(GSOT)和随机森林算法(RF).
2 算法评估方案
本文对各类特征选择算法进行评估的主要思路为:选取不同类别的常用特征选择算法,将选取的特征选择算法应用于几个不同的数据集,然后将处理后的数据集用于同一个模型训练和检测并记录模型的F1分数以及特征选择算法的时间消耗,通过从选择效果和时间消耗两个层面来评估各特征选择算法的差异,最后在所选特征选择算法中选出最通用的特征选择算法. 综上,本文的评估方案包括3个方面:①评价指标;②网络入侵数据集;③基于机器学习的检测模型. 整个评估方案的流程如图1所示.

图1 评估方案流程Fig.1 Processing flow of proposed evaluation scheme
2.1 评价指标
本文评价指标的选取从效果和时间消耗两个维度进行.
1)效果维度评价指标
特征选择常用的性能指标有准确率Accuracy、F1指标、Hamming Loss指标和多目标指标等[15].
Accuracy 反映了被分类器正确判定分类的样本总数,一般用于没有特别需要的数据集. Accuracy 的定义如下:

其中:TP(True Positives)表示检测模型预测结果与标签结果一致,都是正常流量的样本数量;TN(True Negatives)表示检测模型预测结果与标签结果一致,都是异常流量的样本数量;| Data |表示总样本数.
F1值同时兼顾了模型的Precision和Recall,能够更加客观地反映模型效果的好坏. 其定义如下:

其中:FP(False Positive)和FN(False Negatives)分别表示检测模型预测结果是正常流量但标签是异常流量的样本数量和检测模型预测结果是异常流量但标签是正常流量的样本数量.
Hamming Loss用于考察样本在单个标记上的误分类情况. 其定义如下:
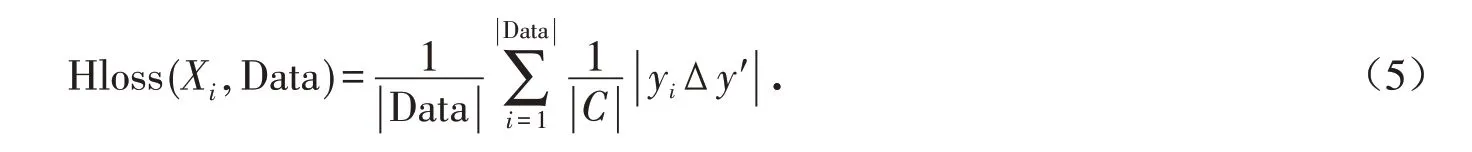
其中:yi和y′分别表示第i个样本的正确类标签和分类器预测的标签;Δ 用来表示两个量之间的差异,如果两者相等则为1,否则为0;C为标签类别的数目. 本文所选择的性能指标为F1指标.
2)时间维度评价指标
在时间维度方面,相关的时间开销有两方面,一是特征选择算法所用时间,另外一个是模型训练所用时间,本文所关注的是特征选择算法所用时间.
多目标指标用于同时评价特征选择的选择效果以及特征选择的花费代价,其公式如下:

其中:Accuracy可以根据需要替换为其他分类指标,例如F1或是Hamming Loss等其他指标;Cost代表特征选择的时间开销代价,可以根据需要替换为 |Xi|,| Xi|表示个体Xi所包含的特征数,用来衡量特征选择后的特征规模对于分类器性能的影响.
本文借用了多目标评价的思想,将特征选择算法的时间消耗也纳入到特征选择算法的评价范围,同时也考虑了特征规模对于分类器性能的影响. 最后,本文采用的评价公式如下:

2.2 数据集的选择依据
通常,网络流量数据集可分为以下3种:
1)基于分组包的数据集——根据使用协议或网络的不同,包中数据项也会有所不同. 此类数据集通常从防火墙抓取[16].
2)基于流的数据集——包含关于网络连接的元信息,通常从交换机抓取. 这类数据集的特征数较少[16].
3)其他数据集——既不是完全基于包也不是完全基于流的数据集. 在这类数据集中,既会包含包的数据特征,也会包含一些主机端的信息,例如:登录次数、是否root登录或登录失败原因等等. 这类数据集的数据特征方面没有通用的模式,不同的数据集可能会包含不同的数据特征[16].
在特征较少的数据集上采用特征选择往往并不能有效缩减数据集的规模,因此,需要选择有较多特征数的数据集,同时,也要考虑数据集的通用性和公开性.
2.3 网络入侵检测模型的选择
常用的机器学习模型有多层感知机(Multi-Layer Perceptron,MLP)[17-19]、卷积神经网络(Convolutional Neural Networks,CNN)、递归神经网络(Recurrent Neural Networks,RNN)等. CNN 具备很强的空间特征学习能力,通过使用一维的CNN可以提取到流量中各层的时序特征;RNN通过隐藏的状态单元将之前时刻的信息传递至当前时刻. 利用RNN 可以提取流量的时序特征;MLP 能够通过隐藏层层数和各层结点个数的增加,拟合任意复杂的非线性函数[20]. 由于本文重点基于模型检测数据来评估特征选择算法的效果,也并未考虑数据包的时间特性,并且着重于判断特征选择算法选出特征之间关联关系的强弱,所以在实验部分采用了自建的多层感知机模型用于数据集效果的检验.
3 实验与分析
3.1 数据集
为了能够更好地验证特征选择结果的通用性,本文实验采用KDD CUP99、NSL-KDD、Kyoto 2006+等3 个公开的入侵检测数据集,其中混合了包和主机端的数据项. KDD CUP99数据集取自于小型的模拟网络,是网络入侵检测研究邻域最经典的数据集,包含DoS、Probe、R2L、U2R攻击类型的数据流;NSL-KDD数据集是KDD CUP99 数据集的改进,它消除了冗余记录,使得分类器不会偏向更频繁的记录,包含了DoS、Privilege Escalation以及Probing等类型攻击;Kyoto 2006+数据集取自于真实网络环境下的蜜罐(HoneyPot),主要包含了Backscater、DoS、Exploits以及Port Scans等攻击类型[14]. 对于KDD CUP99数据集,由于其原始数据集数据量庞大,达到了4 898 431条,本文对这些数据项进行了间距为10的采样,最终将采样结果的70%用作训练集,30%用作测试集;对NSL-KDD数据集,本文直接使用划分好的KDDTrain+训练集和KDDTest+训练集;对Kyoto 2006+数据集,由于其原始数据量较大,达到了1 223 899条,本文同样对其进行了采样,采样间距为3,训练集和测试集的划分方式同KDD CUP99.
3.2 检测模型
本文在基于sklearn包搭建了一个多层感知机模型. 模型一共由4层组成:第一层为输入层,节点数为特征数;第二层和第三层为隐藏层(经过6次实验,发现在本实验中隐藏层的节点数为120时,总体训练时间和训练结果最好);第四层为输出层,节点数为类别数.
3.3 实验结果与分析
实验流程包括数据预处理、特征选择以及模型的训练和检测三个阶段.
在数据预处理阶段,KDD CUP99数据集和NSL-KDD数据集的标签标明了具体的攻击类型,本文这些标签类型映射为5类,分别为:Normal、DoS、Probe、R2L以及U2R. Kyoto 2006+数据集的标签有3种:1代表正常流量,-1代表已知攻击类型的流量,-2代表未知攻击类型的流量. 本文将-2和-1类型的标签统一映射为-1,代表攻击流量. 对数据集中的离散数据采用One-Hot编码,归一化采用Min-Max的方式.
在特征选择阶段中,本文对特征选择算法选择的特征数进行了比例控制,控制比例分别为10%、30%、50%、70%以及100%. 对于决策树、随机森林、梯度下降树这类基于基尼系数的特征选择算法,由于其选择特征数的不可控性,所以并未对其进行比例控制,经过前期实验发现,DT、GBDT、RF 这几类算法所选择出的特征数基本在总特征数的10%,所以本文仅将这些算法在10%特征数的水平上和其他特征选择算法进行对比.
3.3.1 特征选择算法效果比较 首先根据采用不同特征选择算法进行预处理的模型在不同数据集上的F1分数来判断模型表现,并以此来检测数据集特征项的冗余程度. 从图2的结果可以看出:
1)随着特征数数量的不断增加,模型的F1值基本上也呈现不断上升的趋势;
2)在低比例特征数的情况下,基于基尼指数的嵌入式和集成式特征选择算法的效果会比其他类型的特征选择算法效果好,其中以RF算法表现最为稳定,在三个数据集上其模型F1分数相较于不进行特征选择的模型结果差异均在2.5%以内;
3)在本文所选中的特征选择算法中,PLS的效果表现最差,其模型F1分数在KDD CUP99和NSL-KDD数据集上相较于不进行特征选择的模型结果相差13.14%,在Kyoto 2006+上只比不进行特征选择的结果高3.80%. 其中LS_L1的表现最优,其模型F1分数在KDD CUP99和NSL-KDD数据上相较于不进行特征选择的模型结果只低了1.5%,在Kyoto 2006+数据集上比不进行特征选择的结果高10.97%;
4)当特征数比例达到总特征数的50%时,在KDD CUP99和NSL KDD两个数据集上,F1的均值相对于全特征情况而言差距在0.6%,在Kyoto 2006+数据集上,F1均值相较于全特征情况而言高出2.4%,从整体而言,选取50%特征数的效果相较于选取30%特征数高出一倍.
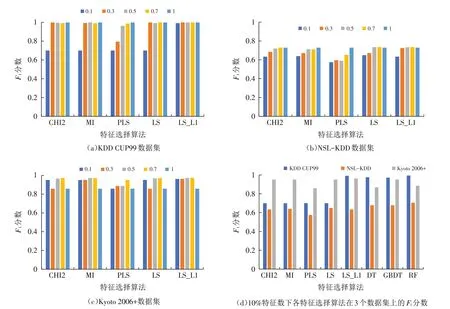
图2 基于特征选择算法的模型在KDD CUP99、NSL-KDD和Kyoto 2006+数据集上F1分数Fig.2 F1 scores of detection models based on different feature selections on KDD CUP99,NSL-KDD,and Kyoto 2006+datasets
3.3.2 特征选择算法时间开销比较 在各特征选择算法时间消耗方面,PLS、LS这类基于封装式的算法存在递归特征消除,导致时间开销很大(图3),它们所消耗的时间均值占到了特征选择算法总时间消耗均值的33.82%和58.80%. 其他类别的特征选择算法在时间消耗方面基本都处于较低的水平,时间消耗均值占比均在5%以下,其中以LS的时间消耗最大,CHI2的时间消耗最低.
3.3.3 相似度分析 图4给出各特征选择算法在3个数据集上选择50%特征数下的特征相似度矩阵,图5展示了选择50%特征数下使用不同特征选择算法的模型在3个数据集上的F1分数,但这里的基于DT、GBDT和RF的特征选择算法的特征数比例都是10%. 从图5可以看出,CHI2和MI以及LS和LS_L1的模型F1得分很接近,差距都在1%以内,并且它们所选出的特征相似度也很高,在0.8%左右. 特别是对于DT、GBDT以及RF这三类算法虽然只选取10%的特征,但是它们的模型F1得分均值在0.856 5,与均值最高的LS_L1 相比只有5%左右,这也直接反映了基于DT、GBDT和RF的特征选择算法对核心特征的提取能力以及核心特征在分类时所起的重要性,这三者和LS_L1的差距则表明了如需要进一步提升检测准确度还需要深入挖掘更多特征之间的关联性.
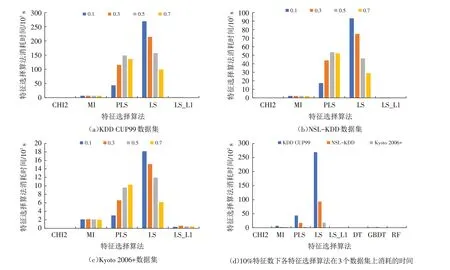
图3 特征选择算法在KDD CUP99、NSL-KDD和Kyoto 2006+上所消耗的时间Fig.3 Time consumed of feature selection methods on KDD CUP99,NSL-KDD,and Kyoto 2006+datasets

图4 特征选择算法在不同数据集上所选特征的相似度矩阵Fig.4 Similarity Matrixes of features chosen by feature selection algorithm on different datasets

图5 选取总特征50%特征数下模型的F1分数Fig.5 F1 Scores of detection models with 50%of total feature number selected
3.3.4 结果分析 经过本文的实验分析发现,基于L1正则项的最小二乘回归特征选择算法LS_L1的鲁棒性最强,时间消耗也处于较低状态,在一般流量特征网络入侵检测数据集的预处理阶段可以作为首选特征选择算法;另外基于随机森林(RF)的特征选择算法在选取小规模特征数的情况下表现最为稳定,模型的F1分数相较于全特征的情况差异在1.9%左右,高于DT和GBDT. 在最佳特征数比例方面,在选取特征数比例占总比例达到50%的情况时,整体的结果表现相较于选取特征比例在30%时有1倍的效果提升. 当特征数达到70%时,相较于50%的特征数的情况结果提升只有0.3%左右,因此可知一般选取50%的特征数即可.
4 结论
通过实验发现,在网络入侵检测环境下,基于L1和L2正则项的最小二乘回归特征选择算法(LS_L1)能够适用于大部分场景. 本文通过选取不同类别下常用的特性选择算法在3个常用的入侵检测数据集上进行了特征选择,并且使用相同MLP模型用于衡量各特征选择算法之间的差异. 通过对比分析MLP模型的F1分数以及特征选择算法消耗的时间可知,LS_L1在选取50%的特征数的情况下能够达到与全特征情况下相差1.5%左右的成绩,在所有评测的特征选择算法中效果最好,某些特征选择算法选择的特征相似度比例较高的情况下,模型的F1分数却相差较大. 未来将对特征选择算法所选特征的可解释性以及特征之间的关联做深入的研究,并通过整合不同的特征选择算法来进一步提高特征选择的鲁棒性.
猜你喜欢
玩具世界(2022年2期)2022-06-15
福州大学学报(自然科学版)(2022年1期)2022-01-21
四川大学学报(自然科学版)(2021年6期)2021-12-27
房地产导刊(2021年8期)2021-10-13
计算机应用(2020年12期)2020-12-31
出版人(2020年4期)2020-11-14
小型微型计算机系统(2018年5期)2018-07-04
计算机应用(2017年3期)2017-05-24
电子制作(2017年23期)2017-02-02
电子制作(2017年23期)2017-02-02
