
基于粗糙集的多类人群异常行为识别算法
2021-05-29 08:17彭月平蒋镕圻
科学技术与工程 2021年11期
彭月平, 蒋镕圻, 徐 蕾
(武警工程大学信息工程学院,西安 710086)
基于视频行为识别作为时变视频数据分类问题,可根据数据特征提取角度分为两大类,一是基于人工设计特征的识别方法,二是基于机器学习的方法。前者是通过人工设计合适的特征量来提取特征值,以构建合适匹配模型;后者注重如何设计网络对行为特征进行自适应学习,即基于样本数据分析结果创建某种模型,一些学者将基于深度学习思想的卷积神经网络等算法模型开始应用在行为识别上,使得深度学习算法在行为识别领域占据一定的优势[1],然而人群行为复杂性使得这些学习训练方法需要处理大量数据以获取网络参数,样本选择会直接影响参数估计的准确性,导致训练不足或过拟合。因此,不少学者仍在寻求最合适的视频特征计算方式以求重大突破。
基于人工设计特征的行为识别方法大致可概括为基于局部特征和基于全局特征这两类。基于局部特征方法是通过时空兴趣点或区域检测等方式提取局部特征,实现行为识别,一般选择对光照、遮挡不敏感的特征作为特征描述符[2-4]。部分学者将Harris角点检测扩展至时空区域,检测时空维度上变化显著的点[2],但该方法要求时空兴趣点需满足在时空尺度上均显著变化的条件,而实际应用中符合要求的兴趣点较为稀疏;因此有学者设计出Hessian时空兴趣点检测器,通过检测尺度不变兴趣点提取局部特征[3];一些学者还发现密集采样能在不同时空尺度上将视频分割为密集小块后再提取特征,具有比时空兴趣点更优的效果,在目标遮挡等复杂环境下鲁棒性较强[4]。而基于全局特征方法是将运动目标视为整体,通过前景提取、运动目标检测和跟踪处理后,再构建包含整体信息的全局特征进行识别[5-10]。在光流直方图基础上,实现了多尺度光流直方图,在保留光流特性的同时增加时空域信息[7];一些学者还利用加速度特征与阈值对比来判断人群是否发生异常行为[8],以及利用社会力模型的最小化相互作用力来检测扩散、定向移动等典型异常行为[9],均取得良好的效果。基于人工设计特征的行为识别方法需要人工设计合适的特征量来提取特征值,通过局部或全局特征分析空间上的行为来检测异常行为,虽然提取的特征包含丰富的行为信息,但受人工主观因素影响较大,且对光照、遮挡等因素较为敏感,缺乏在时间角度的行为变化信息[10]。因此,在人群异常行为识别时,如何选取有效的时空域特征对异常行为识别的效果有着关键影响。
粗糙集是一种刻画不确定性的数学理论,以分类机制为基础,通过知识库近似刻画问题的决策规则,无需依赖于先验信息,通过在不可区分关系的基础上引入上下近似等概念来刻画知识的不确定性和度量属性的重要性,对不确定数据进行分析处理,从原始数据集中获取规则并完成分类,适合从庞杂数据中挖掘有用信息[11-12]。针对现有基于人工设计特征的大多数行为识别方法只针对单一类人群异常行为,缺少多类异常行为分类研究,以及受人工影响较大等问题。本文以粗糙集分类理论为基础,利用粗糙集分类不依赖先验信息的独特优势,研究四散、群殴、同方向加速跑,以及突然聚集四类中低密度人群异常行为特征及其分类,提出并实现基于粗糙集的多类人群异常行为识别算法,并通过同类方法的对比实验来验证所提算法的优越性和有效性。
1 人群异常行为的特征分析与提取
人群异常行为限于特定的场合,一般涉及人数较多,而且不同的人群异常行为都具有鲜明的变化特征可供参考[13]。如四散异常行为在发生四散行为之前,场景内的目标一直在进行无规律的走动,当出现异常时,人群会因惊慌而朝着四面八方散开,此时人群目标的运动量突然加剧,且目标之间的平均距离会不断拉大,即人群目标的动能和势能均发生明显变化。而群殴异常行为在发生前可能会有预兆,即一群人正向某一方向聚集或已聚在某一处,而后开始大打出手,伴随着较为激烈的肢体运动,相邻帧的同一像素点的运动速度和方向可能会发生明显变化,因此可引入帧间混乱程度这一特征量来加以区分。同向加速跑动异常行为在发生时除了具备人数多的特点外,还需要满足人群由无规则行走转为开始加速往同一方向跑的特性,运动速度会突然提高,且其运动方向一致,可采用方向混乱熵来判断该行为。突聚异常行为首先满足人群密度较大的特点,当场景内出现异常时,人群目标开始朝着某一处集中,此时目标之间的平均距离不断缩小,可通过距离势能区别于四散和同向加速跑行为,而它和群殴行为在距离势能上具有一定的相似性,但其运动强度比群殴行为平缓,可采用帧间混乱程度来区分这两类异常行为。
在分析四散、群殴、同方向加速跑,以及突然聚集四类中低密度人群异常行为独有特点的基础上,选用人数、帧平均加速度、矩形框间的距离势能、方向混乱熵,以及帧间混乱程度来分别描述人群数量、目标运动的剧烈程度、个体位置分布、方向变化及相对位置信息,采用矩形框圈定前景图像中的单个运动目标,并通过改进LK(Lucas-Kanade)光流模型计算矩形框的光流特征,从而完成这五个特征值的提取。下面介绍五个特征量的提取过程。
1.1 人数估计
传统方法多是采用像素数与人数的线性关系来估算人数,存在较大的误差。而本文采用大小可变的矩形框圈定运动目标,根据框数与人数的线性关系获取人数估计值,矩形框的个数即为目标人数[14]。具体设置如下:矩形框的长度h未超过预设的阈值T1,判为非人类目标,计数器不变;若框的宽度w未超过阈值T2,则计数器加1;若宽度w超过T2且为T2的N倍时,判定人数为N,计数器A=A+[w/T2];再通过最小二乘法对框数y与人数x进行线性拟合,修正后输出人数的估计值。
1.2 帧平均加速度
当场景中运动目标的速度或方向突然发生变化时,多是由于人群中出现了异常情况,例如突然从缓慢行走转为快速奔跑或是突然转变方向。在物理学中我们通常采用加速度来体现速度的整体变化,它不仅是速度大小变化的数值体现,还是能表明方向变化的矢量。帧平均加速度[15]是根据光流信息计算相邻帧中同一矩形框内的同一特征点的运动速度和方向,得到速度矩阵,进而获取加速度矩阵,再对加速度非零的特征点求平均值而计算出“帧平均加速度”。
由光流法可知,目标运动产生的位移是由相邻两帧中矩形框的欧式距离来表示的。假设对于相邻帧图像中同一矩形框内的同一运动特征点,坐标分别表示为(xi,yi)和(xj,yj),则产生的位移是 Δx=xj-xi,Δy=yj-yi,一般情况下用一帧来代替单位时间,随即可得出Δx和Δy分别为该时刻特征点在X和Y方向上的速度分量,速度的大小可|v|以通过求两者平方和的算术平方根得到。设当前运动特征点的速度与X轴所成的夹角为α,当|v|>0时,则方向角α为
(1)
当|v|=0时,说明该特征点没有运动,则α=-∞。


(2)
式(2)中:ɑt(pi)为当前帧某一运动特征点的加速度;n为运动特征点的个数。
1.3 矩形框间的距离势能
采用矩形框圈定单个运动目标,框之间的相对距离间接代表运动目标之间的相对分布。因此将不同矩形框之间的欧式距离称为距离势能(D),用于描述场景内目标之间的远近程度。若距离势能较小,表示该场景中的运动目标较为密集,反之则比较分散。具体表达式为
(3)
式(3)中:dE(i,j)为两个矩形框之间的欧式距离;n为矩形框个数;φ是修正因子;一般取常量。
1.4 方向混乱熵
方向混乱熵用于描述场景内目标运动方向的离散程度,当运动目标的方向差异越大,则方向熵越大,反之则越小[16]。在计算帧平均加速度时已经获取了矩形框中每个运动特征点的方向,将方向分为8个级别,统计每个级别中特征点的个数,所含特征点数最多的级别即为该矩形框的方向。
则某一帧图像中第i个矩形框的方向概率为
(4)
式(4)中:h(i)为框中属于该方向级别的特征点数目;n为该矩形框中特征点总数。熵值表示事件发生概率的不确定性,因此定义目标运动的方向混乱熵为
(5)
1.5 帧间混乱程度
鉴于从视频监控的角度,群殴行为和一些正常行为(如多人交叉行走)在人数、距离势能这类特征上没有明显的区分,因而引入帧间混乱程度。首先获取矩形框内特征点所对应的方向级别,而后计算相邻帧中同一特征点的方向差与速度差的乘积,最后取均值作为帧间混乱程度(f)的体现,具体表达式为
(6)
式(6)中:n为第k帧图像中运动特征点的总数;v(i,k)为该帧中第i个特征点的光流速度;D(i,k)为相邻帧中特征点i的方向级别差。
2 基于粗糙集的人群异常行为识别算法设计
识别的异常行为主要分为四类:四散、同方向加速跑、群殴和突然聚集,将异常行为发生前的行为,以及这四类异常行为以外的行为均视为正常行为。异常行为识别部分包括特征提取、粗糙集获取决策规则和利用决策规则完成测试分类三个部分。以MATLAB R2017a为实验平台,数据来源于某高校操场外侧监控视频集,速率为25帧/s,分辨率为1 920×1 080,选取含有四散、同方向加速跑、群殴和突然聚集四类异常行为,以及其他正常行为,时长约106 s(共2 649帧)的视频集作为实验数据,每类行为视频时长约20 s,含有500帧左右的视频图像,并将五类行为数据集按照2:1的比例随机分为训练样本集和测试样本集。
2.1 特征的有效性分析
在计算特征量的过程中,噪声干扰会导致个别帧的某些特征值出现跳变,进而造成行为误判,因此从四散、同方向加速跑、群殴、突然聚集,以及正常这五类行为的训练样本集选取不低于100帧视频图像进行计算,结合相邻帧的信息补偿,对每类行为的视频帧提取前文所提到的五个特征值,然后再求取每个特征的平均值,更有效地提取每个特征量,从而提高行为识别的准确性。表1所示为求取平均值后的样本数据。
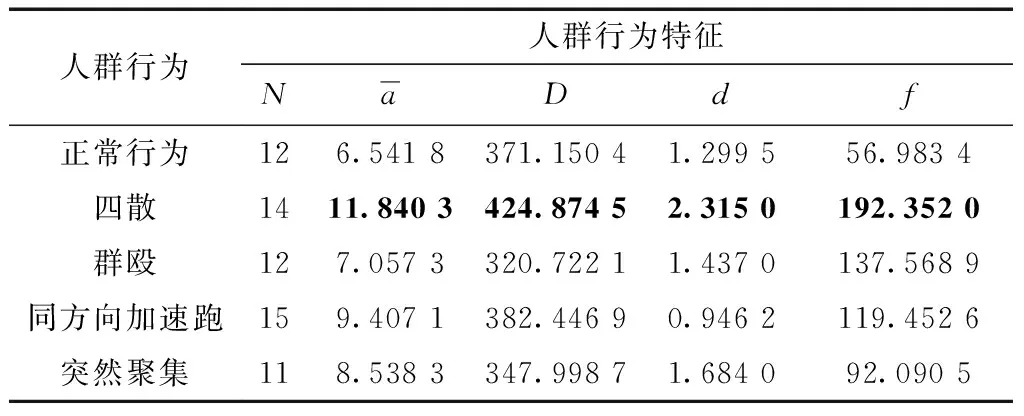
表1 特征量样本数据表Table 1 Sample data table of characteristic quantities
对表1进行横向分析,可得到如下结论。
(1)就四散行为而言,除人数特征量外其他四个特征量的值都较大,这是因为当出现四散行为时,人们朝着不同方向跑开,人与人之间的距离拉大,且运动强度增大。
(2)对于群殴行为,帧平均加速度和矩形框的距离势能这两个特征值没有明显增大,显然监控摄像头近大远小的透视效应,导致无法明确界定它和正常行为,但其方向混乱熵和帧间混乱程度这两个特征量较大。
(3)同方向加速跑行为最明显的不同之处在于其人群趋于同向运动,因而方向混乱熵的值较小。
(4)至于突聚行为,与四散行为相似,方向混乱熵、帧间混乱程度都较大,但人与人之间的距离不断缩小,则矩形框间的距离势能也相应较小。
对表1进行纵向分析,可得到如下结论。
(1) 四散和突然聚集这两类行为具有明显的相似性,唯一的不同在于人与人之间距离的变化情况,因而可以根据矩形框间的距离势能来加以区分,前者的距离势能值远远大于其他四类行为,后者则相反,比其他行为的值要小得多。
(2) 就帧平均加速度这一特征值而言,群殴行为的数值要比其他三类异常行为略小,这是因为摄像头的透视效应会造成距离摄像头较远的人群目标在单位时间内位移变化不明显,从而使得帧平均加速度与正常行为较为接近。
(3) 从方向混乱熵来看,正常行为与同方向加速跑行为的这一特征值略小于其他行为,是由于其他三类异常行为在发生时会出现人群混乱情况,运动方向不一致,而同向加速跑是人群朝着同一方向逃散。
(4) 四种人群异常行为的帧间混乱程度均较大。它是由方向级别变化和速度变化值共同决定的,四散行为的人群运动方向混乱且速度变大,所以帧间混乱程度略大。而突聚行为虽然帧平均加速度变化不大,但运动方向较为混乱;同方向加速跑行为中方向一致,但加速度变化较大,因而它们的帧间混乱程度较小。
(5) 对于人数来说,正常情况下正常与异常行为的人数应该一致,但实际应用中摄像头是固定的,难免会出现运动目标进入监控视角的盲区或者刚好出现在摄像头的拍摄范围内,如果仅凭人数发生变化就判定异常过于武断。本文是研究人群异常行为,不考虑单个目标的异常行为,故设定8人以上为人群。当目标人数超过8人时,通过对其他四个特征量的计算来进一步判定行为类别。
图1所示为不同行为的同一特征量的数值对比,直观反映了五个特征量在描述不同人群行为时具有一定的差异性,从而验证了所提取特征的有效性。
2.2 粗糙集的数据处理
一般情况下所获取的原始数据存在一些冗余数据或是数据缺失等情况,需要在精简信息的同时准确而快速地分类。粗糙集数据处理步骤如图2所示。
将训练集中提取出的五个特征值组成粗糙集的初始信息表,如表2所示。鉴于样本数量较多,仅显示其中一部分数据。
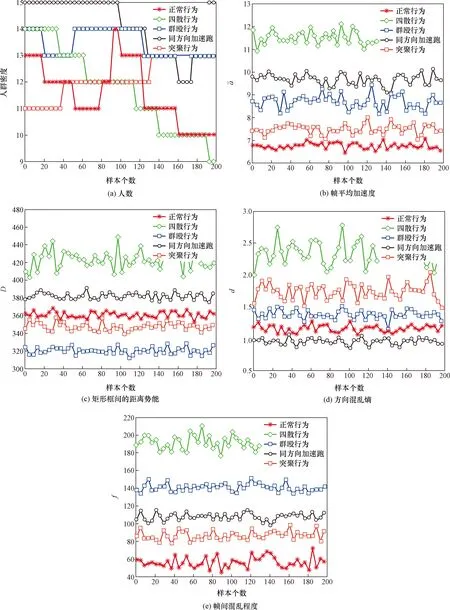
图1 不同人群行为的特征量对比示意图Fig.1 Comparative schematic diagram of the characteristics of the behavior of different groups of people
由于提取出的特征量均是连续型数值,而在粗糙集理论中信息表的属性值必须为离散型,且为了所提炼出更为精简的决策规则,还需将离散的属性值抽象到更高层次,因此在进行粗糙集分类训练前需要先作离散化处理。连续属性离散化可归纳为利用断点集寻找尽可能少且保持信息系统原貌的最优解,以减少复杂性,使得生成适应性更好的决策规则。通过去除冗余断点,简化决策表,提高决策表的分类能力。具体步骤为:首先计算信息表中各条件属性的重要性并由小至大依次排序,而后计算对每个连续属性进行离散化的断点,组成一个候选断点集B并初始化;再将决策表中与属性ai的断点cj相邻的两个属性值中较小的改为较大值,如果并未引起决策表的冲突,则令B=B/Cj,并更新决策表,反之则不更新;对该属性的每个断点执行完再处理下一属性,直至输出最终的断点集B。获取的断点情况如表3所示。

图2 粗糙集数据处理流程Fig.2 Rough set data processing flow

表3 各属性的断点选取情况表Table 3 Breakpoint selection of each attribute
对决策表进行约简的目的在于剔除冗余的属性或者属性值,在保证不影响决策表整体效果的前提下,寻找决策表中可区分属性的最小子集以及每条规则中属性的最小组合。在决策表的信息约简中,大多数方法是通过重要度函数的定义来作为启发式信息,在核属性的基础上逐步增加必要属性,直至获得相对简洁的决策规则为止[17]。采用的是贪心算法,以获取的核属性为基础,根据粒关系包含度矩阵添加非核属性进行约简,再剔除属性值相同的对象,从而获取相应的决策规则[18]。该方法利用属性重要度进行约简,降低了计算复杂度,一定程度上也提高了处理效率。


表4 高校操场监控视频的部分决策规则表Table 4 Part of the decision-making rules for the surveillance video of college playgrounds
2.3 基于粗糙集的人群异常行为识别算法
同一行为在不同场景中可能具有不同意义,例如同方加速行为发生在天安门广场前会被认为是异常行为,而在马拉松比赛中属于正常行为,因此需要针对场景的不同,定义正常行为和异常行为。将四散、群殴、突聚,以及同方向加速跑这四类以外的行为定义为正常。识别视频中的人群异常行为,需要以人群行为建模为基础,本文采用粗糙集处理后的决策规则作为模板对包括正常行为在内的五种人群行为进行训练学习。具体流程如图3所示。
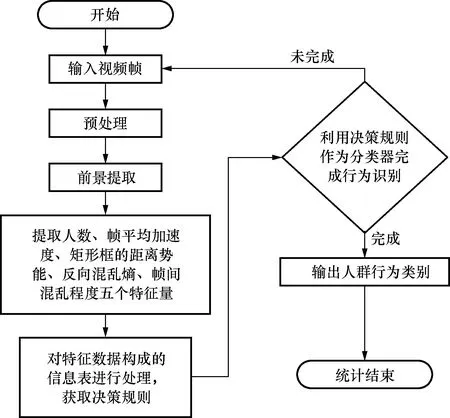
图3 本文算法流程图Fig.3 Flow chart of algorithm in this paper
算法实现的具体步骤描述如下:
(1)将视频分为样本集和测试集并截成帧图像,采用随机共振级联双边滤波的方法对图像进行预处理,减少噪声等环境因素的影响。
(2)利用改进的GMMs算法提取图像中的运动目标,得到前景图像。
(3)对前景图像进一步作形态学处理,去除干扰像素并填补孔洞。

(5)离散化处理所提取的特征值并构成粗糙集系统的初始信息表,而后通过约简去除冗余属性和属性值,获取简洁的决策规则。
(6)返回步骤(1),跳过步骤(5),通过训练好的决策规则对测试集中的正常人群行为、四散、群殴和同方向加速跑和突然聚集行为进行区分。
(7)对出现的异常行为立刻预警。
3 算法实验与结果分析
在MATLAB R2017a的实验环境下,首先提取人群行为特征,而后对五类人群行为进行建模,并将特征数据作为粗糙集系统的输入,通过数据处理和属性约简获取决策规则,最后对实验视频集中的测试样本集进行识别。并以覆盖率(C)、准确率(A)两个指标对人群异常行为的识别能力进行评价。覆盖率和准确率计算公式为
(7)
(8)
式中:S1是测试集中能够被决策规则识别的样本数;S2是测试集中被正确识别的样本数;S3表示被测试的样本总数。
随机选取五类行为测试样本集进行识别测试,其中:正常行为样本帧数为80,四散行为样本帧数为125,同方向加速跑行为样本帧数为98,群殴行为样本帧数为85,突聚行为样本帧数为100。表5所示为本文所提算法对五类人群行为的识别结果。由表5可知,该算法对包括正常行为在内的五种人群行为具有较高的识别能力,群殴和突然聚集行为的识别覆盖率和准确率相对其他三类行为而言较低,因为摄像头视角中两者相似,某些时刻的特征值相差不大,导致在利用决策规则对样本分类时,容易出现误判。

表5 人群行为识别的实验数据结果Table 5 Experimental data results of crowd behavior recognition
目前应用比较广泛分类算法有反向(back pro-pagation,BP)神经网络[20]、K近邻算法[21]和随机森林法[22]等。BP神经网络是一种按照误差逆向传播算法训练的多层前馈神经网络,主要优点是具有很强的非线性映射能力和柔性的网络结构,但存在学习速度慢、网络层数和神经元个数选择困难等问题。K近邻算法是在特征空间中,若一个样本附近的K个最近(即特征空间中最邻近)样本的大多数属于某一个类别,则该样本也属于这个类别,主要优点是准确性高,对异常值和噪声有较高的容忍度,缺点是计算量较大。随机森林法是利用多个决策树对样本数据进行训练并预测的一种分类器,其输出类别是由个别树输出类别的众数而定,主要优点是准确度较高、灵活简单等优点,其主要缺点是当决策树个数很多时,训练需要的空间和时间会比较大。
采用BP神经网络、随机森林法和K近邻算法,以及本文所提算法对上述实验集数据进行处理,并进行对比分析,结果如图4、图5所示。可知:无论是覆盖率和准确率,五类人群行为随着样本数增加,覆盖率和准确率也随之增大;在相同的样本数情况下,除突然聚集行为外,对于其他四类人群行为,本文所提算法的覆盖率和准确率均高于BP神经网络、随机森林法和K近邻算法,即:与BP神经网络、随机森林法和K近邻算法相比,本文所提算法的识别效果更优。

图4 不同分类方法识别覆盖率结果对比Fig.4 Comparison of recognition coverage results of different classification methods
为了比较不同分类算法的运行速度和效率,以本次实验测试样本集数据为基础,在MATLAB R2017a的实验环境下,选取五类行为的单个样本帧数据进行测试,并比较BP神经网络、随机森林法和K近邻算法,以及本文所提算法的所耗时间,结果表明:对于相同样本帧数据,BP神经网络和K近邻算法所耗时间较大,而本文所提算法和随机森林法所耗时间较小,与其他分类算法比较,本文所提算法具有较好的识别速度和效率。
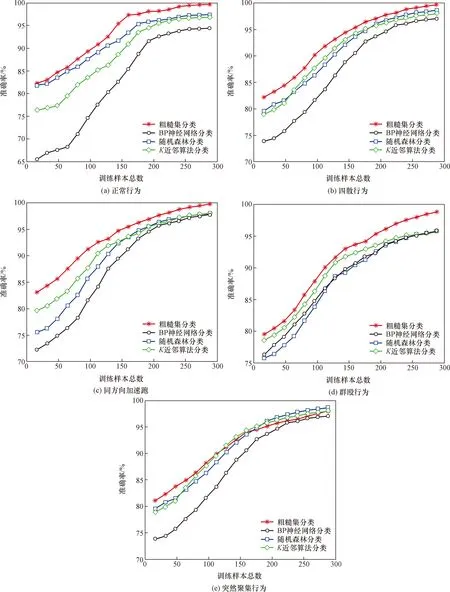
图5 不同分类方法识别准确率结果对比Fig.5 Comparison of recognition accuracy results of different classification methods
需要指出的是:本文所提算法虽然计算量小,空间复杂度低,识别速度较快,对训练样本数量的依赖度也较低,但它是以人工设计特征为基础,特征提取的效果会对识别结果产生直接影响,往往会导致无法准确区分特征值差异不明显的异常行为,例如突然聚集和群殴行为,因而需要寻求能够适应场景动态变化的人群运动特征。
4 结论
为减少人工主观因素的影响,以粗糙集分类理论为基础,利用粗糙集分类不依赖先验信息的独特优势,设计并实现了一种基于粗糙集的多类人群异常行为识别算法。该算法提取能够表征人群目标运动信息的人数、帧平均加速度、矩形框距离势能、方向混乱熵,以及帧间混乱程度五个特征量,再根据粗糙集决策规则对正常、四散、同向加速、突然聚集以及群殴五类人群行为进行分类,并以识别的覆盖率和准确率为衡量指标,比较不同分类方法对相同实验数据的识别效果,进一步验证了通过粗糙集对提取的特征进行分析和约简,能够减少冗余特征对行为分类的干扰,有助于提升识别精度。该算法具有计算量小,空间复杂度低,识别速度较快,对训练样本数量的依赖度较低,不足之处在于场景适应性不强,仅适用于中密度人群场景中的异常行为识别,对于因人群密度过高而产生严重遮挡的情况存在一定的局限性。
猜你喜欢
舰船科学技术(2022年20期)2022-11-28
计算机应用(2022年2期)2022-03-01
科教导刊·电子版(2021年6期)2021-05-06
计算机应用(2021年4期)2021-04-20
计算机应用(2021年1期)2021-01-21
恋爱婚姻家庭(2020年27期)2020-10-09
计算机与数字工程(2019年8期)2019-09-03
百花洲(2018年1期)2018-02-07
瞭望东方周刊(2017年45期)2017-12-08
现代计算机(2016年17期)2016-02-28
