
深度自编码与改进损失函数在极端不均衡故障诊断中的应用
2021-05-29 01:21段敏霞董增寿
科学技术与工程 2021年11期
段敏霞,刘 鑫,董增寿
(太原科技大学电子信息工程学院,太原 030024)
滚动轴承是旋转机械的重要部件,其健康状况直接影响着机械的运转[1],因此针对轴承的故障诊断的研究十分必要。机械故障诊断的研究大多基于振动信号[2-4]。智能诊断是在海量数据中自动提取特征,并根据特征获得诊断结果。它包括特征提取、特征约简和特征分类[5]3个步骤。传统的智能诊断是在基于样本均衡下建立一个模型[6-7]。但在实际应用环境中,类别分布不均衡,故障数据往往小于正常数据[6-9]。传统的分类器在故障诊断中往往偏向于大多数的类,不能准确地识别少数类的故障,尤其是在数据分布极不均衡的情况下[10]。Zhang等[11]结合了快速阅读聚类算法和故障诊断决策树。该方法能在旋转机械数据非均衡的情况下更准确地识别不同类型的故障。针对高炉故障数据非均衡的问题,Liu等[12]提出了一种新的支持向量机(support vector machine,SVM)算法。通过添加未标记样本达到平衡样本的目的,最后采用二叉树多类分类方法准确识别各种故障。上述方法是浅层模型下的故障诊断。但其样本和计算单元有限,难以表示复杂函数。它可以处理简单的分类问题,但很难处理复杂的分类问题[13]。
随着大数据时代的到来,越来越多的学者选择深度学习来处理数据不均衡问题。Mao 等[14]采用生成式对抗网络(generative adversarial networks,GaN)扩展样本容量,将快速傅里叶变换得到的频谱数据输入到叠加式去噪自编码器中,得到良好的分类结果。Zhao等[15]将拉普拉斯正则化项加入到深度自编码器的目标函数中。将采集到的信号输入到构造好的深度拉普拉斯自编码器(deep Laplace autoencoder,DLapAE)进行特征提取,然后输入到BP(back propagation)分类器进行分类。该方法在平衡和非平衡数据集上都取得了良好的分类效果。
上述方法并未解决故障诊断的多分类任务中可能发生的极端失衡的问题。充其量,它们只能解决80%的不平衡问题,并且会在极端不平衡的情况下降低性能。基于此,现提出一种基于深度自编码器(deep auto-encoder,DAE)和加权损失函数的极端不均衡故障诊断模型,加权损失函数的权重系数由样本数量控制。样本数目越多的类别对应的权重系数就越小,反之,样本数目越少的类别,对应的权重系数越大,使得模型在训练时更专注于数量较少的样本。通过在凯斯西储大学和西安交通大学的两个极端不均衡数据集上的实验表明,该方法可以提高模型的诊断精度。
1 原理
1.1 DAE原理
自编码器(auto-encoder,AE)是Rumelhart于1986年提出来的一种单隐层神经网络[16]。AE由编码部分和解码部分组成。编码器通过无监督的方式提取数据的特征信息,解码器通过提取的特征信息尽可能地还原输入信息,使得输出与输入一致。目标函数是输入和输出的均方误差。
AE是一种利用反向传播算法使得输出值等于输入值的神经网络。它先将输入压缩成潜在空间表征,然后通过这种表征来重构输出。简单来说可以分为两部分:输入到隐藏层的编码过程和隐藏层到输出的解码过程。AE结构如图1所示。
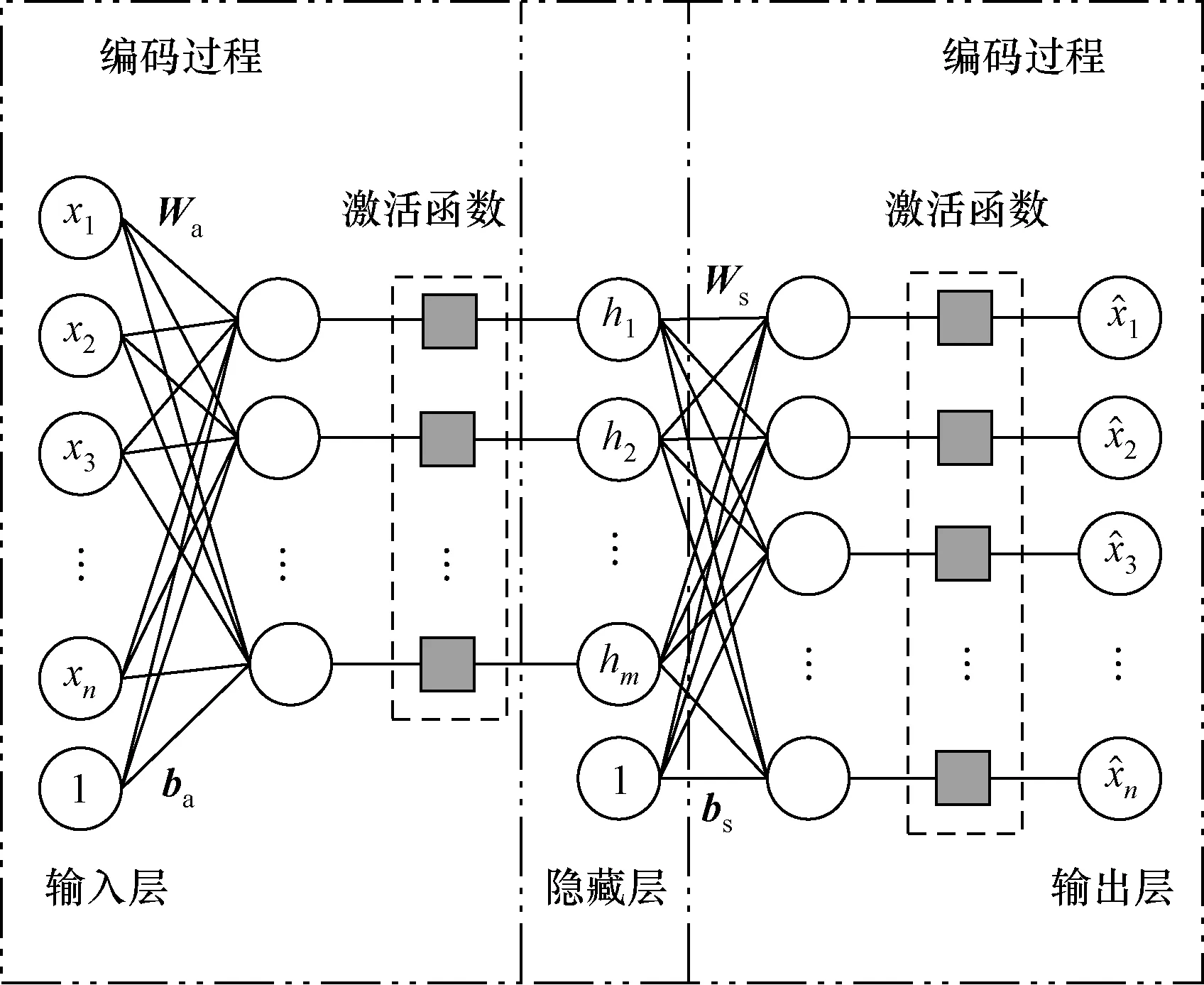
图1 AE的结构图Fig.1 The structure of AE

H=σa(WaX+ba)
(1)
(2)
(3)
式中:Wa∈Rn×m、Ws∈Rm×n、ba∈Rm、bs∈Rn为需要优化求解的权值和偏置,a和s分别为编码过程和解码过程;σa(·)、σs(·)为激活函数;L()为自编码器的损失函数。
AE只有简单的矩阵乘法和矩阵加法运算,激活函数也是较为简单的求导函数,因此利用链式法则可以较为容易地得到梯度。AE的权值和偏置的更新利用反向传播算法就可以得到。
DAE是由多个AE堆叠而成,是深度神经网络中的一种。主要是用来实现深度学习的无监督预训练的,其无监督预训练过程如图2所示。经过深度编码器后,加入SoftMax对故障类型进行分类。在加入分类器之前,网络使用贪心算法来训练网络参数,不需要标签,属于无监督训练。加入分类器后,需要添加少量标签数据对权重和偏置进行微调,以达到更好的分类精度。该网络的每一层都属于浅层网络,可以防止网络陷入局部最优。

图2 DAE的结构图Fig.2 The structure of DAE
1.2 加权损失函数
交叉熵损失函数(cross entropy loss, CE)可以用来衡量两种概率分布的差异。交叉熵损失越小,真实概率分布与预测概率分布的差值越小。首先,引入交叉熵的表达式为
(4)
式(4)中:p(xi)为真实样本标签;q(xi)为预测概率。
交叉熵损失函数的前提是类别间分布均衡,当面对极端不均衡样本时,交叉熵损失函数就不再适用。基于此提出了一种加权损失函数(weighted loss function, WF),使其更适用极端不均衡样本集。类别间的不平衡性导致大类别损失占据比例较大,从而控制了整个梯度传播方向而使模型忽略对小类别样本的学习[18]。在交叉熵损失函数前加入一个控制权重的系数w+,在多分类任务中,假设最多数类样本的数量为N,其他少数类样本的数量为Mj(j为其余少数类的样本),则wj+=N/Mj,其取值范围大于1,样本数最多的那一类对应的权重系数为1。某一类的样本数量越多,则权重系数越小。[1-q(xi)]γ控制难易分类样本的权重。加权损失函数的数学表达式为
γ≥0
(5)
1.3 本文算法流程
本文方法的流程如图3所示,具体步骤如下:
(1)提取轴承数据的小波包能量。
(2)初始化DAE的网络结构。
(3)训练第一层AE,将训练好的隐藏层作为第2个AE的输入,重复该操作,直到第n层AE训练完成。
(4)所有AE均训练完成后,将其堆叠形成DAE,在DAE最后一个隐藏层后添加SoftMax分类器。
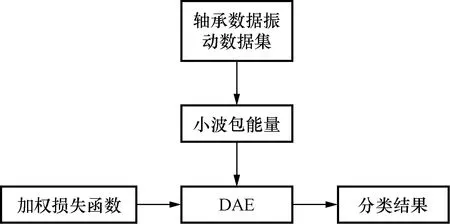
图3 本文算法流程图Fig.3 The flow chart of the proposed method
(5)最后通过标签数据对DAE网络进行有监督微调。
2 利用该方法进行故障诊断
由于恶劣的工作环境,轴承会遭受不同程度和类型的损坏,并造成巨大的经济损失。通过不同类型的轴承数据,以验证该模型在极端不平衡数据集上的有效性。
2.1 小波包能量提取
不同于小波分析,小波包在全频率上对信号进行多层分解,提高了信号的频率分辨率。由于系统出现故障时会对各频带信号的能量有较大影响,且不同的故障对各频带内信号的能量影响也不同[19],根据不同频带内能量的分布情况可以诊断出发生故障的类型。因此可以对故障信号进行小波包分解得到各频带的小波包能量,以此来进行故障诊断。用小波包分解对故障信号进行能量特征提取的步骤如下:
(1)对故障信号进行小波包分解,选取的小波基为db3,分解层数为4。
(2)分解后每个节点的小波包能量可由式(6)求得,并归一化。
(6)
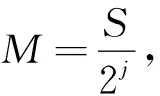
2.2 案例1:凯斯西储大学滚动轴承故障诊断
2.2.1 数据的描述
研究数据来自凯斯西储大学[20]。将经过处理的故障轴承加载到测试电动机上,并在电动机功率为2.2 kW的条件下收集信号。采样频率为 48 kHz。轴承的不同直径分别为0.177 8 mm(轻微故障水平),0.355 6 mm(中等故障水平)和 0.533 4 mm(严重故障水平)。使用测试台,获得了以下信息:①正常运行条件(N);②外圈故障(OR);③内圈故障(IR);④球故障(B)。表1详细列出了这4个数据集。每个样本包含1 024个数据点。表1 列出了不平衡数据集的分配比率。随机选取了50% 作为测试数据。对于不平衡数据集,通过减少故障状态的数量使得正常状况的样本数量要远多于故障状况的样本数量。
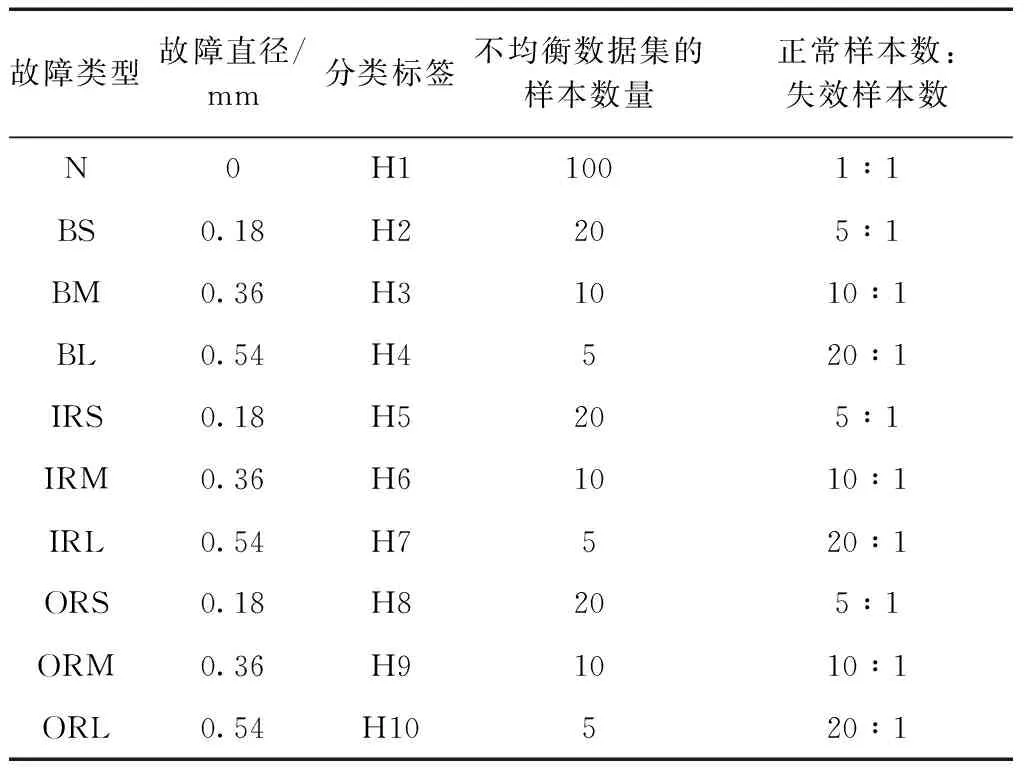
表1 数据集的描述Table 1 Description of the dataset
2.2.2 测试结果
设置最大迭代次数为1 000。数据按5:5的比例分为训练集和测试集。为了客观准确评价模型的性能,采用准确率(Acc)、精确率(P)、召回率(Re)、调和平均(F1)这4个评价指标,3个指标的公式根据二分类的混淆矩阵(表2)可得到。

表2 二分类混淆矩阵Table 2 Binary confusion matrix
(7)
(8)
(9)
(10)
针对多分类问题,在计算其中一类的评价指标时将其他类视为反例。不同故障类型的评价指标如表3所示。可以看到即使在极端不均衡样本集下,该模型仍然可以达到较高的诊断精度,对样本数极少的BL、IRL、ORL这三种故障,该模型能较为准确地预测出这几种故障。

表3 测试集的评价指标Table 3 Evaluation index of test set
为了得到更准确的结果,减少随机性的影响,对不均衡数据集UB进行10次测试,同时选取多种方法与之比较:SVM,小波包分析和BP神经网络(wavelet packet decomposition and BP neural network,WBP)[21],交叉熵损失函数的深度自编码器(cross entropy loss-deep auto-encoder,CE-DAE)。SVM是采用小波包变换提取振动数据的小波包能量,并采用SVM识别不同类型故障;WBPM是采用BP神经网络对小波分解系数进行故障诊断;CE-DAE是采用基于传统的交叉熵损失函数的DAE模型进行故障诊断。不同方法的评价指标如表4所示。对比不同的评价指标,可以发现本文提出的加权损失函数的深度自编码器(weighted loss function-deep auto-encoder, WF-DAE)模型的诊断结果最好。诊断结果的准确率及召回率都远高于其他方法。
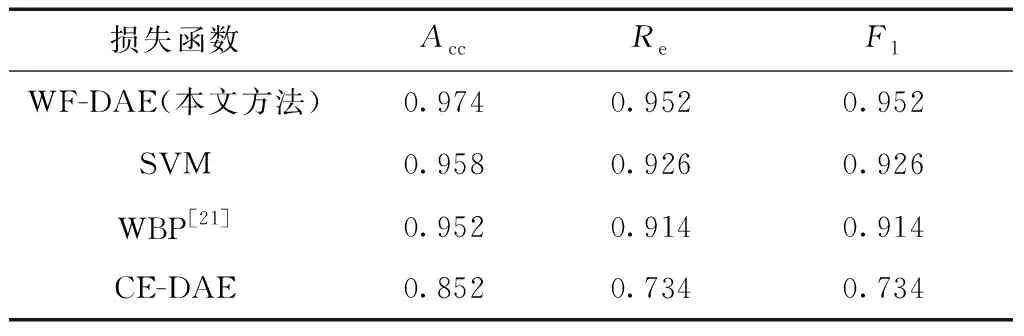
表4 不同诊断方法的比较结果Table 4 Comparison results of different diagnostic methods
采用混淆矩阵来观察4种方法对不同故障类型的分类准确率。4种方法的混淆矩阵如图4所示,可以发现较之其他3种方法,WF-DAE模型对各种故障诊断精度都较高,这是因为其他3种方法都没考虑到类别不均衡的情况,在训练过程模型会过度向大类别样本拟合,而本文方法在训练过程中会增加小类别样本的权重,不会使得模型偏向大类别样本。从而提高各类别故障的诊断精度。

图4 不同方法的混淆矩阵Fig.4 Confusion matrix of different methods
2.3 案例2:西安交通大学-浙江长兴昇阳科技有限公司(SY)数据集的故障诊断
2.3.1 数据的描述
在实际的工业环境中,轴承并不是突然损坏的,而是有一个生命周期。具体来说,它可以分为以下4个周期:正常阶段(N),早期故障(E),故障发展阶段(FD)和故障(F)。该数据集由西安交通大学机械工程学院雷亚国教授团队联合浙江长兴昇阳科技有限公司提供[22]。每个周期包括不同的样本数,每个样本有32 768个数据点。极端不均衡样本数据集的分布如表5所示。采样周期为1 min。采样频率为25.6 kHz。
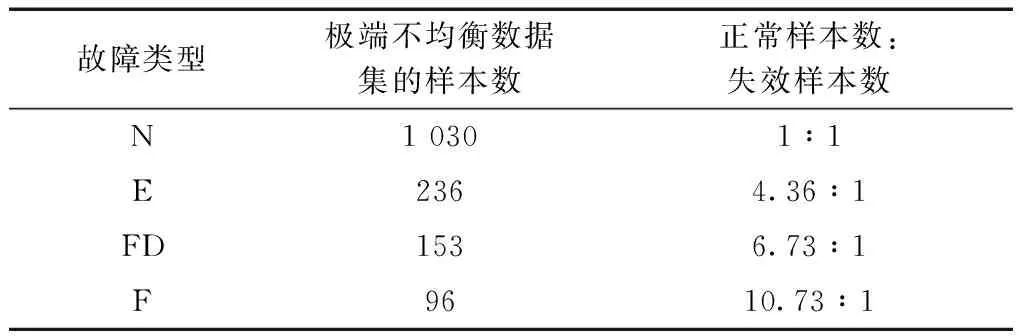
表5 极端非均衡的数据集Table 5 Extremely unbalanced dataset
图5所示为轴承全寿命的理论峰度指数图。从曲线的峰值变化来看,随着时间的推移,幅值也发生变化。当时间达到1 064 min时,轴承首次出现峰值,说明轴承已进入早期故障阶段。随着时间推移,峰值已经发生明显变化,说明轴承已经完全损坏。
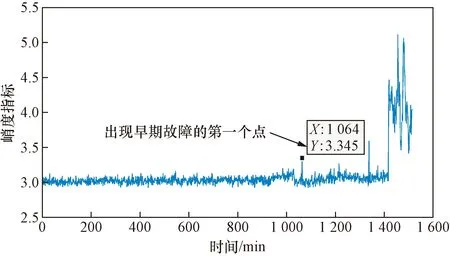
图5 轴承全寿命理论峰度指数Fig.5 Theoretical kurtosis index of the full life of the bearing
2.3.2 测试结果
采用本文模型对不均衡数据集进行故障诊断,模型的评价指标如表6所示,可以发现,即使样本数量极少,如故障发展阶段(FD)和故障阶段(F),它的评价指标依旧保持在92% 及以上。可见该模型适用于极端不均衡数据集。
采用本文方法与其他方法做比较,分别测试10次以减少随机性的影响,10次结果的平均值如表7所示。可以发现本文方法的各项评价指标都高于其他3种方法。由此可得知本文方法更适用于极端不均衡故障诊断。

表6 测试集的评价指标Table 6 Evaluation index of test set
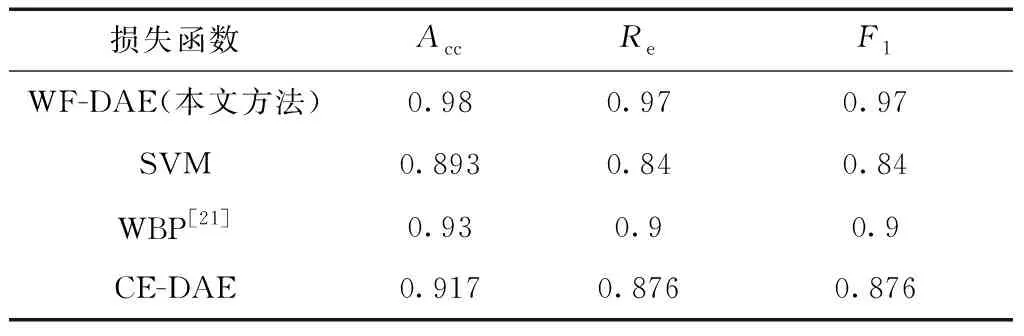
表7 不同诊断方法的比较结果Table 7 Comparison results of different diagnostic methods
3 结论
提出了一种基于DAE和加权损失函数的非均衡故障诊断模型。加权损失函数可以提高模型在不均衡样本下的诊断精度。从两种不同的轴承数据集的实验结果可以得到如下结论:与传统交叉熵损失函数相比,提出的加权损失函数在极端不均衡数据集下的各项评价指标都更高。由此可见加权损失函数更适用于极端不均衡数据集。
但仍存在一些不足,该模型在极端不均衡数据集下的诊断精度并未达到99% 及以上,今后的工作将着重研究生成模型在极端不均衡故障诊断中的应用。
猜你喜欢
哈尔滨轴承(2022年2期)2022-07-22
哈尔滨轴承(2022年1期)2022-05-23
一重技术(2021年5期)2022-01-18
成都信息工程大学学报(2021年1期)2021-07-22
防爆电机(2021年3期)2021-07-21
计算机测量与控制(2020年12期)2021-01-07
热力发电(2019年5期)2019-06-06
电子制作(2018年10期)2018-08-04
北京航空航天大学学报(2016年6期)2016-11-16
汽车电器(2014年5期)2014-02-28
