
基于改进YOLO v3的自然场景下冬枣果实识别方法
2021-06-09 09:48刘天真滕桂法苑迎春刘智国
农业机械学报 2021年5期
刘天真 滕桂法 苑迎春 刘 博 刘智国
(1.河北农业大学信息科学与技术学院, 保定 071001; 2.保定学院信息工程学院, 保定 071000;3.河北省农业大数据重点实验室,保定 071001; 4.石家庄学院计算机科学与工程学院, 石家庄 050035)
0 引言
随着果园机械化、信息化管理的推进,果实识别作为机械化采摘、果实产量预测等果园精细化管理的关键技术,已成为近年来的研究热点[1]。河北省是枣种植主产区,冬枣是河北省优势枣种之一,其种植面积大、产量高,具有重要的经济价值[2-3]。冬枣园果实密集、枝叶遮挡严重、环境复杂,为实现冬枣的机械化采摘,冬枣果实的精准识别与检测至关重要。
近年来,针对枣类果实的识别检测问题,许多学者基于传统机器视觉技术进行了研究[4-6],其中针对灵武长枣采用的基于最大熵彩色图像分割方法和基于几何特征的图像分割算法获得了较高的准确率。利用传统机器视觉技术对苹果、柑橘等常见果实进行识别检测[7-10]多数采用基于果实颜色和纹理等特征的图像分割改进方法,其识别准确率高,但检测速度不足。
传统机器视觉方法在自然场景下的鲁棒性、实时性较差,难以满足果园信息化管理和机械化采摘的要求。卷积神经网络在目标检测方面体现出强大的优势。卷积神经网络方法分为两类:一类基于区域建议方法,采用先生成建议框、再分类的two-stage检测模型,以RCNN[11-13]系列模型为代表,其检测精度高,泛化能力强,但检测时间较长,不能满足实时性需求[14-15];另一类用单一的卷积网络直接获得预测目标位置和分类的端到端的one-stage检测模型,以YOLO[16-18]系列模型为代表,因其具有检测实时性、高精度等优势而得到广泛应用。研究学者针对深度模型进行了一系列研究[19-23],针对自然场景下的水果果实,采用改进的YOLO系列模型进行自动化识别,获得了较高的可靠性和检测效率。
然而,在自然光线变化、枝叶遮挡或果实密集、果实不同成熟期等实际情况下,需要对卷积神经网络作进一步改进,以便较好地解决实际问题、提升果实检测效率。与苹果、柑橘、芒果等果实相比,冬枣果实果型小、产量大,成熟期集中,冬枣果树枝叶较密[24]、果实重叠、枝叶对果实遮挡严重,并且不同成熟期冬枣果实混杂、果实颜色差异明显[25],这些均增加了识别的难度。本文利用YOLO v3模型在目标检测方面的优势,针对冬枣果实的特征引入注意力模块(SE)对YOLO v3进行改进,并选择最优阈值对冬枣进行检测,分别采用不同复杂情况的冬枣数据集来验证本文模型的有效性。
1 冬枣果实检测模型
1.1 YOLO v3模型
YOLO v3是对深度卷积神经网络YOLO的改进,利用多尺度检测和残差网络实现目标检测,在目标检测方面具有实时性、泛化能力强、精度高等优势[13],是目前最先进的目标检测方法之一,能够从图像中快速分类检测目标。
YOLO v3模型包括Darknet层和YOLO层两部分,Darknet是YOLO v3的特征提取层,YOLO层是目标检测层。模型采用尺寸为416×416×3的图像作为输入,利用Darknet层提取图像特征,得到3个尺寸(52×52×256、26×26×512、13×13×1 024)的特征图,在YOLO层中进行检测。每个网格检测出B个目标检测框及其置信度c,即产生5个预测值(x,y,w,h,c),其中(x,y)是目标坐标,(w,h)是目标检测框的宽度和高度,最后通过设置置信度阈值对预测结果进行取舍。
1.2 改进的YOLO v3模型
对检测冬枣果实分析可知,自然场景受光线、遮挡等因素干扰,冬枣果实情况复杂。针对YOLO v3模型对因受部分遮挡和受光线影响而使冬枣果实错检、漏检和置信度较低情况,可以通过增强感受野,加强有效特征提取的方法有效提高检测效果。
SE Net(Squeeze and excitation networks)[26]是基于加权特征图思想提出的一种网络结构,其核心是SE结构,如图1所示。
SE结构主要由挤压(Squeeze)和激发(Excitation)两个操作组成,Squeeze操作先将输入的特征图做全局平均池化(Global average pooling)[27]计算,得到特征通道的全局分布特征,去除特征通道中的空间分布特征,也赋予网络全局感受野,然后进入3层的全连接网络,该网络的隐含层为ReLU激活函数,输入层和输出层神经元数相同。Excitation操作为Sigmoid激活函数计算。输入的特征图经过Squeeze和Excitation处理后输出一个向量,向量中的元素作为原输入特征图的各层权值,该值用于衡量其重要程度。最后Scale操作将输出向量与原输入特征图相乘,得到施加权值后的特征图,来强化有效特征,弱化低效或无效特征,使提取的特征具有更强的指向性,从而提高检测结果。
鉴于SE Net在通道方向上的特征校正能力,本文提出一种将其嵌入YOLO v3的模型结构,为了区分其他嵌入SE Net的YOLO v3模型[28-29],本文称为YOLO v3-SE模型,模型结构如图2所示。
YOLO v3模型网络深度为102层,其中Darknet特征提取层是准确检测目标的关键,包含75层。YOLO v3-SE是在YOLO v3模型的第37、52层分别输出Scale3、Scale2两个尺寸的特征图后嵌入SE结构,使Darknet增至77层,SE结构作为YOLO v3-SE模型的第38、54层。YOLO v3 和YOLO v3-SE模型的网络结构及各层参数对比如图3所示。
YOLO v3-SE为提升模型对高分辨率图像的处理能力,采用512×512×3作为输入图像尺寸,两个SE层分别将前一层输出的尺寸为64×64×256、32×32×512的特征图作为输入,全局平均池化后得到尺寸为1×1×256、1×1×512的特征图,经过全连接网络后仍为1×1×256、1×1×512,再由Sigmoid激活函数处理后得到1×1×256和1×1×512的权值,将权值与原输入特征图相乘,得到输出特征图为64×64×256、32×32×512。
YOLO v3模型的第85、95层为route[18]层,用于将浅层特征与深层特征上采样后进行拼接融合,这种多尺度融合预测的思想使网络性能更强。本文模型沿用route层结构,route层信息如表1所示。

表1 route层信息
嵌入SE结构后,YOLO v3-SE模型在第87层为route层,将第86层(32×32×256)与第54层(32×32×512)连接,构成尺寸为32×32×768的特征图。同样,第97层route层得到的特征图尺寸为64×64×384。
2 模型训练与阈值选取
2.1 数据集制作
本文图像采集地点分别为河北省沧州市的沧县红枣树教育基地和南顾屯村冬枣园,采集日期集中在2019年8月底至10月初,分别在晴天及阴天、白天和傍晚进行采集。实验选用佳能数码相机、手机等设备,采集了大量冬枣果实图像,作为冬枣图像数据集。从图像中选取不同光线、不同遮挡情况、不同成熟期混杂的冬枣图像1 000幅作为冬枣果实检测实验所用数据集,并使用图像标注工具LableImg对冬枣目标进行标注,得到VOC格式的xml文件。在标注时采取人工可观测的冬枣果实全标注方式,即图像中所有遮挡情况的冬枣果实均按可见大小来标注,按人眼观测结果进行识别。
将标注的冬枣果实数据集划分为训练集、测试集、验证集,按8∶1∶1进行随机分配,分别包括800、100、100幅图像,包含冬枣果实目标分别为8 586、1 327、1 288个。
2.2 运行条件
模型训练和测试均在同一台计算机进行,硬件配置为Inter Core i7-8700K CPU@3.70 GHz,GeForce GTX 1080Ti GPU,16 GB运行内存,软件环境为64位Windows 10系统,TensorFlow深度学习框架。
训练时批处理集尺寸(Batchsize)为8个样本,初始学习率(Learning rate)为0.001,权值衰减(Decay)为0.9。为防止过拟合,设置在训练100轮时没有产生损失值下降即结束训练。训练时使用K-means聚类计算当前数据集的锚点预训练值。
2.3 训练损失值对比
采用相同训练集、验证集和测试集分别在YOLO v3-SE和YOLO v3两模型上进行训练,对比迭代损失值变化曲线,如图4所示。
由图4可以看出,两模型在前6 000次迭代拟合速度快,损失值迅速变小,然后缓慢下降,最终稳定在最小值,模型训练完成。其中,YOLO v3经过6.2 h、32 720次迭代稳定在极值,YOLO v3-SE模型经4.7 h、24 800次迭代稳定在极值。可见,YOLO v3-SE模型比YOLO v3模型收敛速度更快,损失值更小,说明本文模型训练的效率更高。
2.4 评估指标及阈值
选取准确率P、召回率R、平均检测精度(mAP)以及调和平均数F作为评价指标。
在使用模型进行实际检测时,需要设置置信度阈值来对检测目标进行取舍。因此,在模型检测时,置信度阈值选取比较关键。
在训练结束后设置不同置信度阈值得到多组评估指标,对比结果见图5。由于F是综合P、R的评估指标,选取F为主要参考值。由图5可见,阈值为0.55时,F取得最大值86.19%,此时mAP维持在较高值82.01%,而P为88.71%,R为83.80%,也处于较高水平,说明模型性能最优。所以最终选取置信度阈值0.55作为模型检测实验所用参数。
3 结果与分析
3.1 检测总体效果对比
对YOLO v3-SE和YOLO v3模型在相同训练集和验证集上分别进行训练,并在相同测试集上进行检测,得到各评估指标、检测结果的置信度以及检测速度等。在检测效果图中,统一用黄框表示假负例FN,即应检出而未检出的目标冬枣果实,蓝框表示假正例FP,即错检的目标冬枣果实。
3.1.1评估指标对比
通过训练和测试,YOLO v3-SE和YOLO v3两模型的PR曲线如图6所示,评估指标如表2所示。
从图6可以看出,YOLO v3-SE的PR曲线覆盖范围更大,说明mAP更大,P、R也比YOLO v3有明显提升。从表2可以看出,YOLO v3-SE和YOLO v3两模型的P均处于较高水平,而YOLO v3-SE的R为83.80%,比YOLO v3模型的R,提升了4.36个百分点,mAP从YOLO v3的77.23%提升到YOLO v3-SE的82.01%,提升了4.78个百分点,F从YOLO v3的83.81%提升到YOLO v3-SE的86.19%,提升了2.38个百分点。可见本文模型的mAP和F都有明显提升,比YOLO v3检测效果更好。

表2 YOLO v3-SE和YOLO v3模型检测结果的评估指标对比
3.1.2置信度对比
在模型检测中,对比两模型对3幅图像的检测效果,如图7所示,3幅图像从左到右依次记为P1、P2、P3,相应置信度对比如表3所示。
从表3可以看出,YOLO v3-SE模型在3幅图像上的正确检出目标分别为17、19、10个,而YOLO v3模型正确检出目标为15、15、6个,YOLO v3-SE模型检测目标的置信度是1的情况明显更多,绝大多数置信度在0.9以上。从图7可以看出,YOLO v3-SE模型在比YOLO v3模型多检出的目标冬枣果实的置信度也在较高水平。对照表3和图7来看,YOLO v3-SE模型在对应检测框的置信度比YOLO v3模型更高,并且从YOLO v3模型未检出、YOLO v3-SE模型检出的目标来看,置信度也较高,说明本文模型对检测目标的置信度有一定加强作用,使检测效果更好,检测能力更强。

表3 图7中检测结果的置信度对比
3.1.3检测速度对比
实验选取单幅图像和批量图像两种方式对比检测速度。检测时间通常指从待检测图像读入至检测结果输出所用的时间。在批量检测速度的实验中,记录两模型分别对101幅600像素×600像素的图像检测所用时间,再分别减去各自在第1幅图像所用检测时间,这是因为第1幅图像检测时需要载入权重模型而导致耗时较长。
在模型中嵌入其他结构往往使检测速度降低。对比两模型对两种不同尺寸的单幅和批量图像检测速度,结果如表4所示。

表4 两模型图像检测速度对比
由表4可见,在中等尺寸和大尺寸图像的检测上,YOLO v3-SE模型与YOLO v3模型耗时相差很小,而批量检测时,YOLO v3-SE模型的检测速度与YOLO v3模型相差在毫秒级。
从检测速度对比看,无论是单幅图像,还是批量图像,YOLO v3-SE模型与YOLO v3模型差异不明显。
3.2 自然场景检测实验
为检验YOLO v3-SE模型在自然场景下的适应性和有效性,根据实际条件进一步检测模型的效率。以自然场景下拍摄的光线不足、密集遮挡和成熟期混杂等复杂情况下的冬枣果实图像各50幅,分别组成测试集进行检测,与YOLO v3模型对比,利用P、R、mAP和F评估本文模型的性能。
3.2.1光线不足情况下的检测效果对比
为避免密集遮挡对实验的影响,选取50幅逆光、阴天或傍晚等光线不足情况下的非密集冬枣果实图像组成测试集,共包含270个冬枣果实目标,使用YOLO v3-SE和YOLO v3模型进行检测,评估指标如表5所示,检测效果如图8所示。
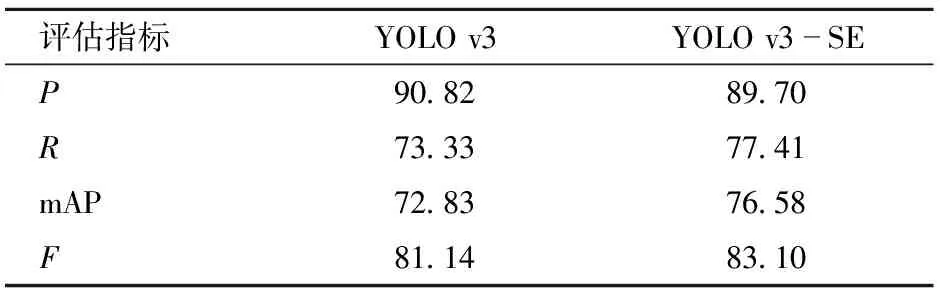
表5 光线不足情况下的冬枣果实测试集评估结果
从表5中可以看出,YOLO v3-SE模型的mAP比YOLO v3模型高3.75个百分点,YOLO v3-SE模型的F比YOLO v3模型高1.96个百分点。YOLO v3-SE模型的R提升明显,比YOLO v3高4.08个百分点。两模型检测结果均保持较高的准确率,但YOLO v3-SE模型在R、mAP和F指标上明显高于YOLO v3模型,检测效果更好。
图8分别选取光线不足情况中的逆光和阴暗两组图像进行对比,其中左图为逆光情况,右图为阴暗情况。从图中可以看出,光线不足时,数码设备拍摄的图像质量明显下降,导致被检测目标的边缘不清晰、颜色失真、纹理特征缺失,为检测带来阻碍。受此影响YOLO v3模型漏检率较高。综合来看,本文模型比YOLO v3模型的检测效果有明显提升。
3.2.2密集遮挡情况下的检测效果对比
实验选取50幅冬枣果实密集度较高、遮挡较严重、光线充足的图像组成测试集,共包含1 028个冬枣果实目标,使用YOLO v3-SE和YOLO v3两模型进行检测,实验结果如表6所示,检测效果对比如图9所示。

表6 密集冬枣果实测试集评估结果
从表6来看,YOLO v3-SE模型的mAP比YOLO v3高2.38个百分点,YOLO v3-SE的F比YOLO v3高1.75个百分点。图9中左图为果实密集多枝叶遮挡,右图为果实密集多重叠情况,由于选取图像光线充足,冬枣果实边界清晰,两模型检测准确率均较高。但由于枝叶茂盛,对果实遮挡严重,以及果实密集重叠,甚至出现冬枣果实不同部位的遮挡,冬枣果实与枝叶颜色相差不大,会出现错检和漏检情况。图中YOLO v3出现的错检和漏检情况明显多于YOLO v3-SE,无论是冬枣果实多重叠还是多遮挡情况,本文模型的检测效果均优于YOLO v3模型。
3.2.3不同成熟期冬枣的检测效果对比
分别选取50幅以白熟期、脆熟期和完熟期3个不同时期的冬枣果实图像组成3个测试集,分别包含冬枣果实目标数量为532、333、400个,使用YOLO v3-SE和YOLO v3模型检测,各评估指标如表7所示,检测效果如图10所示。
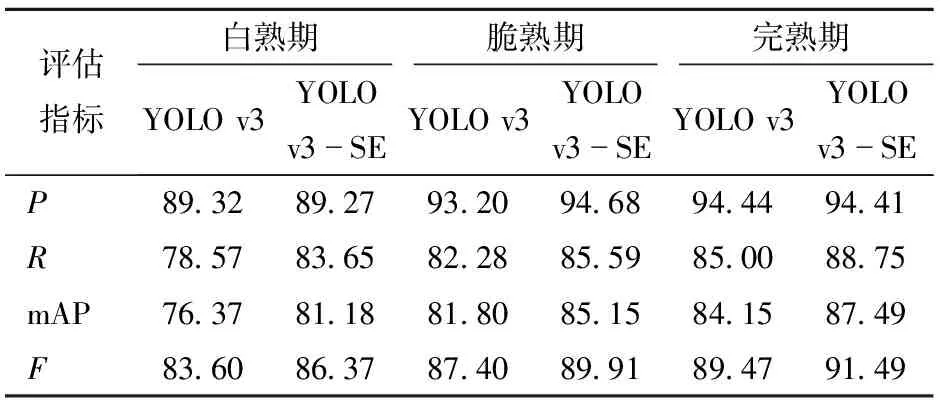
表7 不同成熟期的冬枣果实测试集的评估结果
从表7可以看出,YOLO v3-SE模型的mAP在3个成熟期的测试结果比YOLO v3分别高3.34~4.81个百分点。不同成熟期YOLO v3-SE模型的R比YOLO v3高3~5个百分点,YOLO v3-SE的F也比YOLO v3高2.02~2.77个百分点。
图10为以3个成熟期为主的测试图像对比,从左至右为白熟期、脆熟期、完熟期。从图中可以看出,在光线充足情况下,脆熟期冬枣果实部分变红、完熟期为全红色,颜色纹理特征明显,在光线充足情况下与周围环境对比清晰。而由于白熟期冬枣果实颜色为青绿色,重叠或遮挡时会呈现出与树叶较接近的颜色和形状,在标注时要做到人眼准确、全面地观测也较困难,所以会导致误检、漏检。综合3个成熟期的检测效果,YOLO v3模型的mAP和F明显低于YOLO v3-SE模型,YOLO v3-SE模型检测效果更好。
4 结论
(1)提出了基于YOLO v3-SE模型的自然场景下冬枣果实识别方法。实验表明,YOLO v3-SE模型检测精度高、速度快,在自然场景下对复杂因素的抗干扰能力强,模型的平均检测精度达82.01%,综合评价指标F达86.19%,对单幅图像和批量图像的检测速度与YOLO v3模型无明显差异。
(2)通过在YOLO v3中嵌入SE Net,增强了特征图的特征表达能力,与YOLO v3模型相比,YOLO v3-SE的召回率提升了4.36个百分点,mAP提升了4.78个百分点,F提升了2.38个百分点。
(3)通过对比阈值对评估指标的影响,选取0.55作为本文模型检测的置信度阈值,以保证模型性能最优。
(4)与YOLO v3相比,在光线不足、密集遮挡和冬枣不同成熟期等多种情况下本文模型检测效果均有不同程度的提升,其中,在光线不足和密集遮挡情况下mAP分别提升了3.75、2.38个百分点,F分别提升1.96、1.75个百分点,在白熟期、脆熟期和完熟期为主的情况下mAP分别提升了3.34~4.81个百分点,F提升了2.02~2.77个百分点,从而验证了本文模型的有效性。
猜你喜欢
电子技术与软件工程(2022年15期)2022-11-11
小型微型计算机系统(2022年4期)2022-05-09
房地产导刊(2020年9期)2020-10-28
农产品市场周刊(2020年23期)2020-01-25
电子制作(2019年10期)2019-06-17
中国计算机报(2017年47期)2018-01-12
电影文学(2016年23期)2017-02-13
中国科技纵横(2016年20期)2016-12-28
现代园艺(2016年13期)2016-09-02
营销界(2015年25期)2015-08-21
